任务
给定:一个基于OpenWRT(并且它基于BuildRoot)的项目,其中一个附加存储库已作为提要连接。任务:将另一个存储库与主存储库合并。
背景
我们制造路由器,有一天,我们希望使客户能够将其应用程序包含在固件中。为了不遭受SDK的分配,工具链和随之而来的困难,我们决定将整个项目放在私有存储库中的github上。仓库结构:
/target //
/toolchain // gcc, musl
/feeds //
/package //
...
决定将我们自己开发的一些应用程序从主存储库移至其他存储库,以防止任何人窥探。我们做了所有的事情,将其放在github上,它变得很好。
自那时以来,桥下流了很多水……
客户端已经离开了很长一段时间,该存储库已从github上删除,让客户端访问该存储库的想法很烂。但是,该项目中还有两个存储库。与git相关的所有脚本/应用程序都不得不变得复杂,以至于无法使用这种结构。简而言之,这是技术债务。例如,为了确保发行版的可重现性,您需要使用第二个存储库中的哈希表将文件secondary.version提交到主存储库。当然,脚本可以做到这一点,而且并不是很困难。但是,有许多这样的脚本,而且它们都比可能要复杂的多。通常,我是自愿决定将辅助存储库合并回主存储库。同时,设定了主要条件-保持释放的可重复性。
一旦设置了这样的条件,那么琐碎的合并方法(例如分别从辅助节点提交所有内容,然后从上方进行两个独立树的合并提交)将不起作用。您必须打开引擎盖并使手变脏。
Git数据结构
首先,git存储库是什么样的?这是一个对象数据库。对象分为三种类型:Blob,树和提交。所有对象均通过其内容的sha1哈希进行寻址。愚蠢的是,blob是没有任何其他属性的数据。树是链接到树和Blob的排序列表,形式为“ <right> <type> <hash> <name>”(其中<type>是blob或tree)。因此,树就像文件系统中的目录,而blob就像文件。提交包含作者和提交者的名称,创建和添加的日期,注释,树形哈希以及到父提交的任意数量(通常是一两个)链接。这些指向父提交的链接将对象库转换为非循环图(在外国人中,称为DAG)。详细阅读在这里:
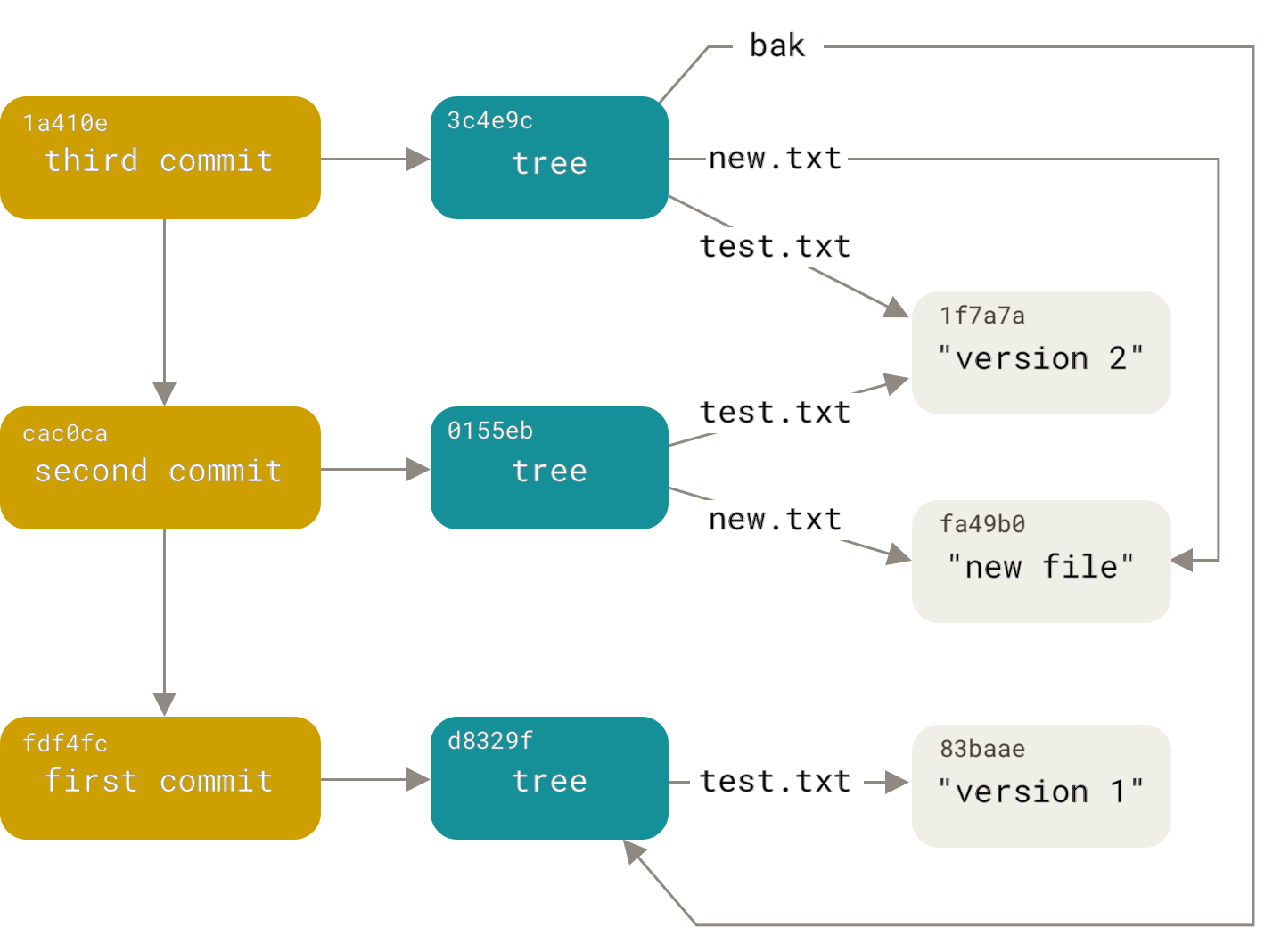
因此,我们的任务被转换为构建新的有向图的任务,并重复了旧有的图。但是,用其他存储库中的提交替换了secondary.version文件的提交后,

开发过程就远非经典的gitflow了。我们将所有内容都提交给主服务器,并尝试不要同时破坏它。我们从那里开始建造。如有必要,我们将建立稳定分支,然后将其合并回主分支。因此,存储库图看起来像是用藤蔓编织的红杉的裸露树干。
分析
任务自然分为两个阶段:分析和综合。因为对于综合来说,显然很必要从将辅助存储库分配给所有标签和分支的那一刻开始,从第二个存储库插入提交,然后在分析阶段,您需要找到插入辅助提交以及这些提交本身的位置。因此,您需要构建一个简化的图,其中的节点将是更改了secondary.version文件的主图的提交(关键提交)。此外,如果此git的节点引用父节点,那么在新图中,需要引用后代。我创建一个命名元组:
node = namedtuple(‘Node’, [‘primary_commit’, ‘secondary_commit’, ‘children’])
必要的保留
, . , .
我把它放在字典里:
master_tip = repo.commit(‘master’)
commit_map = {master_tip : node(master_tip, get_sec_commit(master_tip), [])}我把所有更改了secondary.version的提交都放在那里:
for c in repo.iter_commits(all=True, path=’secondary.verion’) :
commit_map[c] = node(c, get_sec_commit(c), [])我建立了一个简单的递归算法:
def build_dag(commit, commit_map, node):
for p in commit.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
build_dag(p, commit_map, commit_map[p])
else :
build_dag(p, commit_map, node)也就是说,我将关键结延伸到了过去,并将它们与新父母联系起来。
我运行它并... RuntimeError最大递归深度超出
怎么发生的?提交过多吗?git log和wc知道答案。自拆分以来,提交总数约为20,000,而影响secondary.version的提交总数约为700。已知的配方是,需要非递归版本。
def build_dag(master_tip, commit_map, master_node):
to_process = [(master_tip, master_node)]
while len(to_process) > 0:
c, node = to_process.pop()
for p in c.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
to_process.append(p, commit_map[p])
else :
to_process.append(p, node)(而且您说过,只有通过面试才需要所有这些算法!)我
启动了它,并且...起作用了。一分钟,五,二十分钟……不,你不能花那么长时间。我停下。显然,每个提交和每个路径都会处理多次。树上有几个树枝?原来,树上有40个分支,因此,仅来自主设备的不同路径。而且有很多途径可以导致大部分关键提交。由于我没有数千年的存储空间,因此我需要更改算法,以便每次提交仅被处理一次。为此,我添加了一个集合,在其中标记每个已处理的提交。但是有一个小问题:使用这种方法,由于具有不同关键提交的不同路径可以通过相同的提交,因此某些链接将丢失,并且只有第一个更进一步。为了解决这个问题,我用字典替换了集合,其中的键是提交,值是可到达的键提交的列表:
def build_dag(master_tip, commit_map, master_node):
processed_commits = {}
to_process = [(master_tip, master_node, [])]
while len(to_process) > 0:
c, node, path = to_process.pop()
p_node = commit_map.get(c)
if p_node :
commit_map[p].children.append(p_node)
for path_c in path :
if all(p_node.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(p_node)
path = []
node = p_node
processed_cmmts[c] = []
for p in c.parents :
if p != root_commit and and p not in processed_cmmts :
newpath = path.copy()
newpath.append(c)
to_process.append((p, node, newpath,))
else :
p_node = commit_map.get(p)
if p_node is None :
p_nodes = processed_cmmts.get(p, [])
else :
p_nodes = [p_node]
for pn in p_nodes :
node.children.append(pn)
if all(pn.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[c]) :
processed_cmmts[c].append(pn)
for path_c in path :
if all(pn.trunk_commit != nc.trunk_commit
for nc in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(pn)由于这种无时无刻的内存交换时间,图形在30秒内建立。
合成
现在,我有了一个commit_map,其中的关键节点通过子链接链接到图形。为方便起见,我将其转换为成对的序列(祖先,后代)。必须确保该顺序,以确保节点作为子代出现的所有对都位于节点作为祖先出现的任何对之前。然后,您只需要遍历此列表,并首先从主存储库提交提交,然后再从其他存储库提交。在这里,我们必须记住,提交包含到树的链接,这是文件系统的状态。由于附加存储库在package /目录中包含附加子目录,则必须为所有提交创建新的树。在第一个版本中,我只是将blob写入文件,并要求git在工作目录上建立索引。但是,这种方法不是很有效。仍然有20,000次提交,每个都需要再次提交。因此,性能至关重要。对GitPython内部进行的一些研究使我想到了gitdb.LooseObjectDB类,该类直接公开了git存储库对象。使用它,可以将一个存储库中的Blob和树(以及其他任何对象)直接写入到另一个存储库中。git对象数据库的一个奇妙特性是任何对象的地址都是其数据的哈希。因此,即使在不同的存储库中,相同的Blob也将具有相同的地址。
secondary_paths = set()
ldb = gitdb.LooseObjectDB(os.path.join(repo.git_dir, 'objects'))
while len(pc_pairs) > 0:
parent, child = pc_pairs.pop()
for c in all_but_last(repo.iter_commits('{}..{}'.format(
parent.trunk_commit, child.trunk_commit), reverse = True)) :
newparents = [new_commits.get(p, p) for p in c.parents]
new_commits[c] = commit_primary(repo, newparents, c, secondary_paths)
newparents = [new_commits.get(p, p) for p in child.trunk_commit.parents]
c = secrepo.commit(child.src_commit)
sc_message = 'secondary commits {}..{} <devonly>'.format(
parent.src_commit, child.src_commit)
scm_details = '\n'.join(
'{}: {}'.format(i.hexsha[:8], textwrap.shorten(i.message, width = 70))
for i in secrepo.iter_commits(
'{}..{}'.format(parent.src_commit, child.src_commit), reverse = True))
sc_message = '\n\n'.join((sc_message, scm_details))
new_commits[child.trunk_commit] = commit_secondary(
repo, newparents, c, secondary_paths, ldb, sc_message)提交功能本身:
def commit_primary(repo, parents, c, secondary_paths) :
head_tree = parents[0].tree
repo.index.reset(parents[0])
repo.git.read_tree(c.tree)
for p in secondary_paths :
# primary commits don't change secondary paths, so we'll just read secondary
# paths into index
tree = head_tree.join(p)
repo.git.read_tree('--prefix', p, tree)
return repo.index.commit(c.message, author=c.author, committer=c.committer
, parent_commits = parents
, author_date=git_author_date(c)
, commit_date=git_commit_date(c))
def commit_secondary(repo, parents, sec_commit, sec_paths, ldb, message):
repo.index.reset(parents[0])
if len(sec_paths) > 0 :
repo.index.remove(sec_paths, r=True, force = True, ignore_unmatch = True)
for o in sec_commit.tree.traverse() :
if not ldb.has_object(o.binsha) :
ldb.store(gitdb.IStream(o.type, o.size, o.data_stream))
if o.path.find(os.sep) < 0 and o.type == 'tree': # a package root
repo.git.read_tree('--prefix', path, tree)
sec_paths.add(p)
return repo.index.commit(message, author=sec_commit.author
, committer=sec_commit.committer
, parent_commits=parents
, author_date=git_author_date(sec_commit)
, commit_date=git_commit_date(sec_commit))
如您所见,辅助存储库中的提交已批量添加。首先,我确保添加了单个提交,但是(突然!)事实证明,有时新的密钥提交包含辅助存储库的先前版本(换句话说,该版本已回滚)。在这种情况下,iter_commit方法将通过并返回一个空列表。结果,存储库不正确。因此,我只需要提交当前版本。
all_but_last生成器的外观历史很有趣。我省略了描述,但它确实符合您的期望。起初只是一个挑战
repo.iter_commits('{}..{}^'.format(parent.trunk_commit, child.trunk_commit), reverse = True)总的来说,一切都很好。整个脚本可容纳300行,运行大约6个小时。道德:GitPython可以很方便地使用存储库处理各种很酷的事情,但是最好及时处理技术债务