很长一段时间以来,我没有写过任何文章,我想是时候写在那里了,它是如何从Yandex和MIPT“机器学习和数据分析”的著名专业培训中获得的数据科学知识派上用场的。诚然,公平地讲,应该指出的是,知识还没有完全获得-专业还没有完成:)但是,已经有可能解决简单的实际业务问题。还是有必要?这个问题将在几段中得到回答。
因此,今天,在本文中,我将向亲爱的读者介绍我参加公开比赛的初次经历。我想马上指出,我比赛的目的不是获得任何奖项。唯一的愿望是在现实世界中试一试:)是的,此外,碰巧的是,竞赛主题实际上与所学课程的材料不相交。这增加了一些复杂性,但是由此带来的竞争变得更加有趣和有价值。
按照传统,我将指定谁可能对该文章感兴趣。首先,如果您已经完成了上述专业的前两个课程,并且想尝试解决实际问题,但又害羞又担心它可能无法解决,您会被嘲笑,等等。阅读这篇文章后,我希望这种恐惧会消除。其次,也许您正在解决一个类似的问题,根本不知道从哪里进入。正如真实的数据输入者所说的,这是一个现成的,朴实的基线:)
在这里,我们应该已经概述了研究计划,但是我们将稍作讨论,并尝试回答第一段中的问题-数据搜索初学者是否应该尝试参加此类比赛。关于这一点,意见不一。我个人认为是必要的!让我解释一下原因。原因有很多,我不会列出所有内容,而是指出最重要的原因。首先,此类竞赛有助于在实践中巩固理论知识。其次,在我的实践中,几乎总是在接近战斗的条件下获得的经验,极大地激发了进一步的发展。第三,这是最重要的事情-在比赛中,您有机会与其他参与者进行特殊的聊天交流,您甚至不必交流,您只需阅读人们写的东西,这通常会导致有趣的想法。研究中还需要进行哪些其他更改;以及b)有信心验证自己的想法,尤其是在聊天中表达时。必须谨慎地利用这些优势,以免产生无所不知的感觉...
现在介绍一下我如何决定参加。在比赛开始前几天,我就了解了比赛。第一个念头是“好吧,如果我一个月前知道比赛的话,我会做好准备的,但是我会研究一些可能对进行研究有用的其他材料,否则,如果没有准备,我可能无法在截止日期前完成……” “实际上,如果目标不是奖励,而是参与,那可能行不通,尤其是因为95%的案例的参与者说俄语,再加上特别的讨论讨论,组织者将举办一些网络研讨会。最后,将有可能看到各种规模和规模的实时数据科学家……”。如您所料,第二个想法赢了,而且没有白费。实际上,经过几天的努力,我获得了宝贵的经验,尽管很简单,但这是一项非常艰巨的任务。因此,如果您正在征服数据科学的高潮并看到即将到来的竞争,那么可以用您的母语,在聊天中获得支持,您将有空闲时间-不要犹豫很长时间-尝试,并祝愿力量伴随您!积极地说,我们继续进行任务和研究计划。
匹配名称
我们不会拷问自己,也不会提出问题的描述,但会提供比赛组织者网站的原始文本。
一个任务
在寻找新客户时,SIBUR必须处理来自各种来源的数百万新公司的信息。同时,这些公司的名称可能具有不同的拼写,包含缩写或错误,并且隶属于SIBUR已知的公司。
为了更有效地处理有关潜在客户的信息,SIBUR需要知道两个名称是否相关(即属于同一公司或关联公司)。
在这种情况下,SIBUR将能够使用有关公司本身或关联公司的已知信息,不会重复拨打公司电话,也不会浪费时间在无关紧要的公司或竞争对手的子公司上。
训练样本包含来自不同来源(包括自定义名称)和标记的成对名称。
标记部分是通过手工获得的,部分是通过算法获得的。此外,标记可能包含错误。您将构建一个二进制模型,该模型预测两个名称是否相关。此任务中使用的度量标准为F1。
在此任务中,有可能甚至有必要使用开放数据源来丰富数据集或查找对识别关联公司重要的其他信息。
有关任务的其他信息
发现我以获取更多信息
, . , : , , Sibur Digital, , Sibur international GMBH , “ International GMBH” .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source , . — . .
, - – . , , - , , , .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
, , , .. crowdsource
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source
open source , . — . .
, - – . , , - , , , .
数据
train.csv-训练集
test.csv-测试集
sample_submission.csv-正确格式的解决方案示例
命名baseline.ipynb-代码
baseline_submission.csv-基本解决方案
请注意,竞赛的组织者照顾了年轻一代并发布了该问题的基本解决方案, f1质量约为0.1。这是我第一次参加比赛,也是我第一次看到这件事:)
因此,在熟悉任务本身及其解决方案的要求之后,我们继续进行解决方案计划。
解决问题的计划
设置技术手段
让我们加载库
让我们编写辅助函数
数据预处理
… -. !
50 & Drop it smart.
让我们计算Levenshtein距离
计算标准化的Levenshtein距离
可视化功能
比较每对文本中的文字并生成大量功能
将文本中的文字与石化和建筑行业排名前50位的控股品牌的名称中的文字进行比较。让我们获得第二大功能。Second CHIT
准备数据以输入模型
建立和训练模型
比赛结果
信息来源
现在我们已经熟悉了研究计划,让我们继续执行它。
设置技术手段
加载库
实际上,这里的一切都很简单,首先我们将安装缺少的库
安装库以确定国家列表,然后从文本中删除它们
pip install pycountry
安装一个库,用于确定文本中的单词彼此之间以及不同列表中的单词之间的Levenshtein距离
pip install strsimpy
我们将在该库的帮助下安装该库,并将俄文本翻译成拉丁文
pip install cyrtranslit
拉库
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import pycountry
import re
from tqdm import tqdm
tqdm.pandas()
from strsimpy.levenshtein import Levenshtein
from strsimpy.normalized_levenshtein import NormalizedLevenshtein
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import seaborn as sns
sns.set()
sns.set_style("whitegrid")
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import StratifiedShuffleSplit
from scipy.sparse import csr_matrix
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report, f1_score
# import googletrans
# from googletrans import Translator
import cyrtranslit让我们编写辅助功能
最好在一行中指定函数,而不要复制大量代码。我们将几乎总是这样做。
我不会说函数中的代码质量很好。在某些地方,绝对应该对其进行优化,但是为了快速进行研究,仅计算的准确性就足够了。
所以第一个函数将文本转换为小写
编码
# convert text to lowercase
def lower_str(data,column):
data[column] = data[column].str.lower()以下四个功能有助于可视化所研究特征的空间及其通过目标标签-0或1分离对象的能力。
编码
# statistic table for analyse float values (it needs to make histogramms and boxplots)
def data_statistics(data,analyse,title_print):
data0 = data[data['target']==0][analyse]
data1 = data[data['target']==1][analyse]
data_describe = pd.DataFrame()
data_describe['target_0'] = data0.describe()
data_describe['target_1'] = data1.describe()
data_describe = data_describe.T
if title_print == 'yes':
print ('\033[1m' + ' ',analyse,'\033[m')
elif title_print == 'no':
None
return data_describe
# histogramms for float values
def hist_fz(data,data_describe,analyse,size):
print ()
print ('\033[1m' + 'Information about',analyse,'\033[m')
print ()
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
min_data = data_describe['min'].min()
max_data = data_describe['max'].max()
data0_mean = data_describe.loc['target_0']['mean']
data0_median = data_describe.loc['target_0']['50%']
data0_min = data_describe.loc['target_0']['min']
data0_max = data_describe.loc['target_0']['max']
data0_count = data_describe.loc['target_0']['count']
data1_mean = data_describe.loc['target_1']['mean']
data1_median = data_describe.loc['target_1']['50%']
data1_min = data_describe.loc['target_1']['min']
data1_max = data_describe.loc['target_1']['max']
data1_count = data_describe.loc['target_1']['count']
print ('\033[4m' + 'Analyse'+ '\033[m','No duplicates')
figure(figsize=size)
sns.distplot(data_0,color='darkgreen',kde = False)
plt.scatter(data0_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data0_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data0_count,
' Min:', round(data0_min,2),
' Max:', round(data0_max,2),
' Mean:', round(data0_mean,2),
' Median:', round(data0_median,2))
print ()
print ('\033[4m' + 'Analyse'+ '\033[m','Duplicates')
figure(figsize=size)
sns.distplot(data_1,color='darkred',kde = False)
plt.scatter(data1_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data1_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data_1.count(),
' Min:', round(data1_min,2),
' Max:', round(data1_max,2),
' Mean:', round(data1_mean,2),
' Median:', round(data1_median,2))
# draw boxplot
def boxplot(data,analyse,size):
print ('\033[4m' + 'Analyse'+ '\033[m','All pairs')
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
figure(figsize=size)
sns.boxplot(x=analyse,y='target',data=data,orient='h',
showmeans=True,
meanprops={"marker":"o",
"markerfacecolor":"dimgray",
"markeredgecolor":"black",
"markersize":"14"},
palette=['palegreen', 'salmon'])
plt.ylabel('target', size=14)
plt.xlabel(analyse, size=14)
plt.show()
# draw graph for analyse two choosing features for predict traget label
def two_features(data,analyse1,analyse2,size):
fig = plt.subplots(figsize=size)
x0 = data[data['target']==0][analyse1]
y0 = data[data['target']==0][analyse2]
x1 = data[data['target']==1][analyse1]
y1 = data[data['target']==1][analyse2]
plt.scatter(x0,y0,c='green',marker='.')
plt.scatter(x1,y1,c='black',marker='+')
plt.xlabel(analyse1)
plt.ylabel(analyse2)
title = [analyse1,analyse2]
plt.title(title)
plt.show()第五个功能旨在生成算法的猜测和错误表,也称为共轭表。
换句话说,在形成预测向量之后,我们需要将预测与目标标签进行比较。比较的结果应该是培训样本中每对公司的共轭表。在每个对的共轭表中,将确定预测样本与训练样本匹配的结果。匹配分类的接受方式如下:“真阳性”,“假阳性”,“真阴性”或“假阴性”。这些数据对于分析算法的操作以及决定改进模型和特征空间非常重要。
编码
def contingency_table(X,features,probability_level,tridx,cvidx,model):
tr_predict_proba = model.predict_proba(X.iloc[tridx][features].values)
cv_predict_proba = model.predict_proba(X.iloc[cvidx][features].values)
tr_predict_target = (tr_predict_proba[:, 1] > probability_level).astype(np.int)
cv_predict_target = (cv_predict_proba[:, 1] > probability_level).astype(np.int)
X_tr = X.iloc[tridx]
X_cv = X.iloc[cvidx]
X_tr['predict_proba'] = tr_predict_proba[:,1]
X_cv['predict_proba'] = cv_predict_proba[:,1]
X_tr['predict_target'] = tr_predict_target
X_cv['predict_target'] = cv_predict_target
# make true positive column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false positive column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make true negative column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false negative column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
return X_tr,X_cv第六功能被设计成形成共轭矩阵。不要与耦合表混淆。尽管一个接一个。您自己将进一步看到一切
编码
def matrix_confusion(X):
list_matrix = ['True_Positive','False_Positive','True_Negative','False_Negative']
tr_pos = X[list_matrix].sum().loc['True_Positive']
f_pos = X[list_matrix].sum().loc['False_Positive']
tr_neg = X[list_matrix].sum().loc['True_Negative']
f_neg = X[list_matrix].sum().loc['False_Negative']
matrix_confusion = pd.DataFrame()
matrix_confusion['0_algorythm'] = np.array([tr_neg,f_neg]).T
matrix_confusion['1_algorythm'] = np.array([f_pos,tr_pos]).T
matrix_confusion = matrix_confusion.rename(index={0: '0_target', 1: '1_target'})
return matrix_confusion第七项功能旨在可视化算法操作的报告,其中包括共轭矩阵,度量精度,召回率,f1的值
编码
def report_score(tr_matrix_confusion,
cv_matrix_confusion,
data,tridx,cvidx,
X_tr,X_cv):
# print some imporatant information
print ('\033[1m'+'Matrix confusion on train data'+'\033[m')
display(tr_matrix_confusion)
print ()
print(classification_report(data.iloc[tridx]["target"].values, X_tr['predict_target']))
print ('******************************************************')
print ()
print ()
print ('\033[1m'+'Matrix confusion on test(cv) data'+'\033[m')
display(cv_matrix_confusion)
print ()
print(classification_report(data.iloc[cvidx]["target"].values, X_cv['predict_target']))
print ('******************************************************')使用第八和第九个函数,我们根据每个研究特征的系数“信息增益”的值来分析Light GBM中所用模型的特征效用
编码
def table_gain_coef(model,features,start,stop):
data_gain = pd.DataFrame()
data_gain['Features'] = features
data_gain['Gain'] = model.booster_.feature_importance(importance_type='gain')
return data_gain.sort_values('Gain', ascending=False)[start:stop]
def gain_hist(df,size,start,stop):
fig, ax = plt.subplots(figsize=(size))
x = (df.sort_values('Gain', ascending=False)['Features'][start:stop])
y = (df.sort_values('Gain', ascending=False)['Gain'][start:stop])
plt.bar(x,y)
plt.xlabel('Features')
plt.ylabel('Gain')
plt.xticks(rotation=90)
plt.show()需要第十个功能来形成每对公司的匹配词数量的数组。
此函数还可用于形成不匹配单词的数组。
编码
def compair_metrics(data):
duplicate_count = []
duplicate_sum = []
for i in range(len(data)):
count=len(data[i])
duplicate_count.append(count)
if count <= 0:
duplicate_sum.append(0)
elif count > 0:
temp_sum = 0
for j in range(len(data[i])):
temp_sum +=len(data[i][j])
duplicate_sum.append(temp_sum)
return duplicate_count,duplicate_sum 第十一函数将俄语文本音译为拉丁字母
编码
def transliterate(data):
text_transliterate = []
for i in range(data.shape[0]):
temp_list = list(data[i:i+1])
temp_str = ''.join(temp_list)
result = cyrtranslit.to_latin(temp_str,'ru')
text_transliterate.append(result)
.
, , , . , ,
<spoiler title="">
<source lang="python">def rename_agg_columns(id_client,data,rename):
columns = [id_client]
for lev_0 in data.columns.levels[0]:
if lev_0 != id_client:
for lev_1 in data.columns.levels[1][:-1]:
columns.append(rename % (lev_0, lev_1))
data.columns = columns
return datareturn text_transliterate需要第
13和第14个函数来查看和生成Levenshtein距离表和其他重要指标。
这通常是一张什么样的表,其中的度量标准是什么,以及它是如何形成的?让我们看一下如何逐步形成表格:
- 步骤1.让我们定义所需的数据。结对ID,文本整理-两列,持有名称列表(前50名石化和建筑公司)。
- 步骤2.在第1列的每个单词中的每个对中,从持有人姓名列表中测量Levenshtein与每个单词的距离,以及每个单词的长度以及距离与长度的比率。
- 3. , 0.4, id , .
- 4. , 0.4, .
- 5. , ID , — . id ( id ). .
- 步骤6.将结果表与研究表粘合在一起。
一个重要特征:
草草编写代码会导致计算花费很长时间
编码
def dist_name_to_top_list_view(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
words1 = []
words2 = []
top_words = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist1
df['levenstein_dist_w2_top_w'] = dist2
df['length_w1_top_w'] = len(word1)
df['length_w2_top_w'] = len(word2)
df['length_top_w'] = len(top_word)
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
display(data)
print ('Words:', word1,word2,top_word)
print ('Levenstein distance:',dist1,dist2)
print ('Length of word:',len(word1),len(word2),len(top_word))
print ('Ratio (distance/length word):',ratio1,ratio2)
def dist_name_to_top_list_make(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
dist_w1 = []
dist_w2 = []
length_w1 = []
length_w2 = []
length_top_w = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
dist_w1.append(dist1)
dist_w2.append(dist2)
length_w1.append(float(len(word1)))
length_w2.append(float(len(word2)))
length_top_w.append(float(len(top_word)))
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist_w1
df['levenstein_dist_w2_top_w'] = dist_w2
df['length_w1_top_w'] = length_w1
df['length_w2_top_w'] = length_w2
df['length_top_w'] = length_top_w
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
return data数据预处理
根据我的经验,从广义上讲,数据预处理需要花费更多时间。让我们去吧。
载入资料
这里的一切都很简单。让我们加载数据,并将目标名称为“ is_duplicate”的列名称替换为“ target”。这是为了使函数易于使用-其中一些函数是早期研究的一部分,并且使用带有目标标签的列名称作为“目标”。
编码
# DOWNLOAD DATA
text_train = pd.read_csv('train.csv')
text_test = pd.read_csv('test.csv')
# RENAME DATA
text_train = text_train.rename(columns={"is_duplicate": "target"})让我们看一下数据
数据已加载。让我们看看总共有多少个对象以及它们是如何平衡的。
编码
# ANALYSE BALANCE OF DATA
target_1 = text_train[text_train['target']==1]['target'].count()
target_0 = text_train[text_train['target']==0]['target'].count()
print ('There are', text_train.shape[0], 'objects')
print ('There are', target_1, 'objects with target 1')
print ('There are', target_0, 'objects with target 0')
print ('Balance is', round(100*target_1/target_0,2),'%')表№1“标记的平衡”

有很多对象-接近50万个,它们根本不平衡。也就是说,在近50万个对象中,总共不到4000个对象的目标标签为1(小于1%)
。让我们看一下标记为0的前五个对象和标记为1的前五个对象。
编码
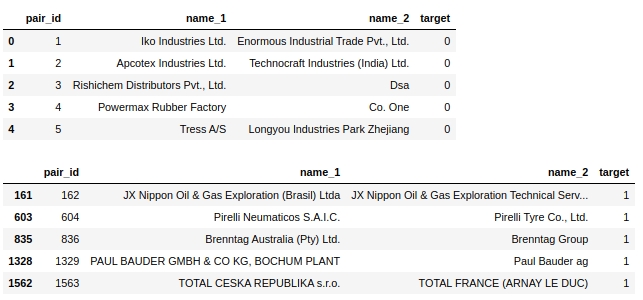
display(text_train[text_train['target']==0].head(5))
display(text_train[text_train['target']==1].head(5))表2“类0的前5个对象”,表3“类1的前5个对象”:
一些简单的步骤立即表明了自己的意思:将文本带到一个寄存器中,删除任何停用词(例如“ ltd”),删除国家/地区,同时删除地理名称对象。
实际上,在此任务中可以解决类似的问题-您进行一些预处理,确保它可以正常工作,运行模型,查看质量,并有选择地分析模型错误的对象。这就是我进行研究的方式。但是在文章本身中,给出了最终的解决方案,并且不了解每次预处理后的算法质量,在本文结尾处,我们将进行最终分析。否则,文章的大小将难以描述:)
让我们复制
老实说,我不知道为什么要这么做,但是出于某种原因,我总是这样做。我这次也会做
编码
baseline_train = text_train.copy()
baseline_test = text_test.copy()让我们将所有字符从文本转换为小写
编码
# convert text to lowercase
columns = ['name_1','name_2']
for column in columns:
lower_str(baseline_train,column)
for column in columns:
lower_str(baseline_test,column)删除国家名称
应当指出,比赛的组织者是伟大的伙伴!在完成任务的同时,他们给笔记本电脑提供了一个非常简单的基线,其中提供了基线,包括下面的代码。
编码
# drop any names of countries
countries = [country.name.lower() for country in pycountry.countries]
for country in tqdm(countries):
baseline_train.replace(re.compile(country), "", inplace=True)
baseline_test.replace(re.compile(country), "", inplace=True)删除标志和特殊字符
编码
# drop punctuation marks
baseline_train.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_test.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_train.replace(re.compile(r"[^\w\s]"), "", inplace=True)
baseline_test.replace(re.compile(r"[^\w\s]"), "", inplace=True)删除号码
第一次尝试直接从额头上的文本中删除数字,极大地破坏了模型的质量。我将在此处提供代码,但实际上并未使用。
还要注意,到目前为止,我们已经直接在提供给我们的列上执行了转换。现在让我们为每个预处理创建新列。会有更多的列,但是如果在预处理的某个阶段发生故障,那没关系,您不需要从一开始就做任何事情,因为我们将在预处理的每个阶段都有列。
破坏质量的代码。你需要更精致
# # first: make dictionary of frequency every word
# list_words = baseline_train['name_1'].to_string(index=False).split() +\
# baseline_train['name_2'].to_string(index=False).split()
# freq_words = {}
# for w in list_words:
# freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame of frequency words
# df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
# df_freq.columns = ['word','frequency']
# df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
# df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
# df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
# # third: make drop list of digits
# string = df_freq_agg['word'].to_string(index=False)
# digits = [int(digit) for digit in string.split() if digit.isdigit()]
# digits = set(digits)
# digits = list(digits)
# # drop the digits
# baseline_train['name_1_no_digits'] =\
# baseline_train['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_train['name_2_no_digits'] =\
# baseline_train['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_1_no_digits'] =\
# baseline_test['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_2_no_digits'] =\
# baseline_test['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))让我们删除...第一个停用词列表。手动!
现在建议在公司名称的单词列表中定义和删除停用词。
我们是根据对培训样本的手动审核编制的清单。从逻辑上讲,应使用以下方法自动编译此类列表:
- 首先,使用前10个(20,50,100)经常出现的单词。
- 第二,使用不同语言的标准停用词库。例如,以各种语言(LLC,PJSC,CJSC,Ltd,gmbh,inc等)指定组织的组织和法律形式
- 第三,编译不同语言的地名列表是有意义的
我们将返回第一个选项,以自动编译最常用的单词列表,但现在我们正在研究手动预处理。
编码
# drop some stop-words
drop_list = ["ltd.", "co.", "inc.", "b.v.", "s.c.r.l.", "gmbh", "pvt.",
'retail','usa','asia','ceska republika','limited','tradig','llc','group',
'international','plc','retail','tire','mills','chemical','korea','brasil',
'holding','vietnam','tyre','venezuela','polska','americas','industrial','taiwan',
'europe','america','north','czech republic','retailers','retails',
'mexicana','corporation','corp','ltd','co','toronto','nederland','shanghai','gmb','pacific',
'industries','industrias',
'inc', 'ltda', '', '', '', '', '', '', '', '', 'ceska republika', 'ltda',
'sibur', 'enterprises', 'electronics', 'products', 'distribution', 'logistics', 'development',
'technologies', 'pvt', 'technologies', 'comercio', 'industria', 'trading', 'internacionais',
'bank', 'sports',
'express','east', 'west', 'south', 'north', 'factory', 'transportes', 'trade', 'banco',
'management', 'engineering', 'investments', 'enterprise', 'city', 'national', 'express', 'tech',
'auto', 'transporte', 'technology', 'and', 'central', 'american',
'logistica','global','exportacao', 'ceska republika', 'vancouver', 'deutschland',
'sro','rus','chemicals','private','distributors','tyres','industry','services','italia','beijing',
'','company','the','und']
baseline_train['name_1_non_stop_words'] =\
baseline_train['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_non_stop_words'] =\
baseline_train['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_non_stop_words'] =\
baseline_test['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_non_stop_words'] =\
baseline_test['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))让我们选择性地检查我们的停用词是否已从文本中删除。
编码
baseline_train[baseline_train.name_1_non_stop_words.str.contains("factory")].head(3)表4“对代码的选择性检查以删除停用词”

一切似乎正常。删除所有用空格分隔的停用词。我们想要的。继续。
让我们将俄语文本音译为拉丁字母
我为此使用了自己编写的函数和cyrtranslit库。似乎有效。手动检查。
编码
# transliteration to latin
baseline_train['name_1_transliterated'] = transliterate(baseline_train['name_1_non_stop_words'])
baseline_train['name_2_transliterated'] = transliterate(baseline_train['name_2_non_stop_words'])
baseline_test['name_1_transliterated'] = transliterate(baseline_test['name_1_non_stop_words'])
baseline_test['name_2_transliterated'] = transliterate(baseline_test['name_2_non_stop_words'])让我们看一下ID为353150的一对。其中,第二列(“ name_2”)的单词为“ Michelin”,经过预处理,该单词已经像“ mishlen”这样写了(请参阅“ name_2_transliterated”列)。并非完全正确,但显然更好。
编码
pair_id = 353150
baseline_train[baseline_train['pair_id']==353150]表5“对音译代码的选择性验证”

让我们开始自动编译前50个最常用的单词列表,并巧妙地将其删除。第一志
标题有点棘手。让我们来看看我们在这里要做什么。
首先,我们将第一列和第二列中的文本组合成一个数组,并为每个唯一单词计数其出现的次数。
其次,让我们选择这些单词的前50个。而且似乎可以删除它们,但不能删除。这些词可能包含馆藏名称('total','knauf','shell',...),但这是非常重要的信息,不会丢失,因为我们将进一步使用它。因此,我们将尝试作弊(禁止)技巧。首先,在对培训样本进行仔细,选择性的研究的基础上,我们将编制一份经常遇到的馆藏名称列表。清单将不完整,否则将根本不公平:)尽管,因为我们没有追逐奖金,所以为什么不呢?然后,我们将比较前50个常用词的数组与馆藏名称列表,并从列表中删除与馆藏名称匹配的单词。
第二个停用词列表现已完成。您可以从文本中删除单词。
但在此之前,我想对控股名称作弊清单作一小段评论。我们根据观察结果汇总了所有股份的名称,这一事实使我们的生活变得更加轻松。但是实际上,我们可以用其他方式来编译这样的列表。例如,您可以对石化,建筑,汽车和其他行业的最大公司进行评级,将它们合并在一起,然后从中获取股份的名称。但是出于研究目的,我们将自己限制在一种简单的方法上。比赛中禁止这种方法!此外,竞赛的组织者,奖位候选人的工作也要检查禁止使用的技术。小心!
编码
list_top_companies = ['arlanxeo', 'basf', 'bayer', 'bdp', 'bosch', 'brenntag', 'contitech',
'daewoo', 'dow', 'dupont', 'evonik', 'exxon', 'exxonmobil', 'freudenberg',
'goodyear', 'goter', 'henkel', 'hp', 'hyundai', 'isover', 'itochu', 'kia', 'knauf',
'kraton', 'kumho', 'lusocopla', 'michelin', 'paul bauder', 'pirelli', 'ravago',
'rehau', 'reliance', 'sabic', 'sanyo', 'shell', 'sherwinwilliams', 'sojitz',
'soprema', 'steico', 'strabag', 'sumitomo', 'synthomer', 'synthos',
'total', 'trelleborg', 'trinseo', 'yokohama']
# drop top 50 common words (NAME 1 & NAME 2) exept names of top companies
# first: make dictionary of frequency every word
list_words = baseline_train['name_1_transliterated'].to_string(index=False).split() +\
baseline_train['name_2_transliterated'].to_string(index=False).split()
freq_words = {}
for w in list_words:
freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame
df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
df_freq.columns = ['word','frequency']
df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
drop_list = list(set(df_freq_agg[0:50]['word'].to_string(index=False).split()) - set(list_top_companies))
# # check list of top 50 common words
# print (drop_list)
# drop the top 50 words
baseline_train['name_1_finish'] =\
baseline_train['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_finish'] =\
baseline_train['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_finish'] =\
baseline_test['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_finish'] =\
baseline_test['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
这是我们进行数据预处理的地方。让我们开始生成新功能,并从视觉上评估它们是否可以将对象分隔为0或1。
特征生成和分析
让我们计算Levenshtein距离
让我们使用strsimpy库,并在每对中(在所有预处理之后)计算从第一列的公司名称到第二列的公司名称之间的Levenshtein距离。
编码
# create feature with LEVENSTAIN DISTANCE
levenshtein = Levenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["levenstein"] = baseline_train.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)
baseline_test["levenstein"] = baseline_test.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)让我们计算归一化的Levenshtein距离
一切都与上面相同,只是我们将计算归一化的距离。
扰流板头
# create feature with NORMALIZATION LEVENSTAIN DISTANCE
normalized_levenshtein = NormalizedLevenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["norm_levenstein"] = baseline_train.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)
baseline_test["norm_levenstein"] = baseline_test.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)我们数了一下,现在我们形象化了
可视化功能
让我们看一下特质“列文斯坦”的分布
编码
data = baseline_train
analyse = 'levenstein'
size = (12,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)图#1“直方图和带有胡须的盒子,用于评估特征的重要性”
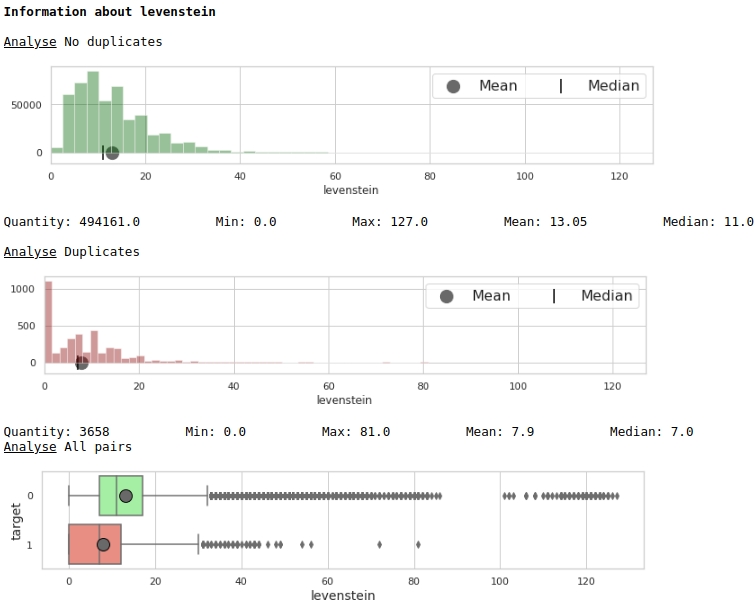
乍一看,度量可以标记数据。显然不是很好,但是可以使用。
让我们看看特征“ norm_levenstein”的分布
扰流板头
data = baseline_train
analyse = 'norm_levenstein'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)图№2“直方图和留着胡子的盒子,用于评估符号的重要性”

已经更好了。现在,让我们看一下这两个组合功能如何将空间分为对象0和1。
编码
data = baseline_train
analyse1 = 'levenstein'
analyse2 = 'norm_levenstein'
size = (14,6)
two_features(data,analyse1,analyse2,size)图形3“散点图”
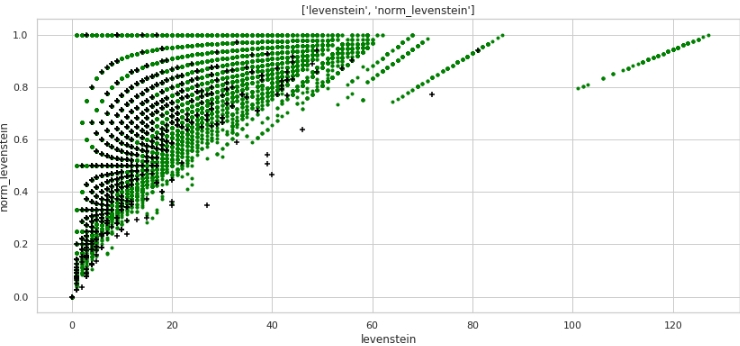
获得了很好的标记。因此,我们对数据进行如此多的预处理并非没有道理:)
每个人都可以理解水平-指标“ levenstein”的值和垂直-指标“ norm_levenstein”的值,绿色和黑色点分别是对象0和1。让我们继续。
让我们比较每对文字中的单词并生成一大堆特征
下面我们将比较公司名称中的单词。让我们创建以下功能:
- 在每对的#1和#2列中重复的单词列表
- 不可重复的单词列表
基于这些单词列表,让我们创建输入到训练模型中的功能:
- 重复字数
- 非重复字数
- 字符总和,重复单词
- 字符总数,不能重复的单词
- 重复单词的平均长度
- 不重复单词的平均长度
- 重复数与非重复数之比
这里的代码可能不是很友好,因为它还是匆忙编写的。但这有效,但将用于快速研究。
编码
# make some information about duplicates and differences for TRAIN
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_train.shape[0]):
list1 = list(baseline_train[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_train[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TRAIN
baseline_train['duplicate'] = duplicates
baseline_train['difference'] = difference
baseline_train['duplicate_count'] = duplicate_count
baseline_train['duplicate_sum'] = duplicate_sum
baseline_train['duplicate_mean'] = baseline_train['duplicate_sum'] / baseline_train['duplicate_count']
baseline_train['duplicate_mean'] = baseline_train['duplicate_mean'].fillna(0)
baseline_train['dif_count'] = dif_count
baseline_train['dif_sum'] = dif_sum
baseline_train['dif_mean'] = baseline_train['dif_sum'] / baseline_train['dif_count']
baseline_train['dif_mean'] = baseline_train['dif_mean'].fillna(0)
baseline_train['ratio_duplicate/dif_count'] = baseline_train['duplicate_count'] / baseline_train['dif_count']
# make some information about duplicates and differences for TEST
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_test.shape[0]):
list1 = list(baseline_test[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_test[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TEST
baseline_test['duplicate'] = duplicates
baseline_test['difference'] = difference
baseline_test['duplicate_count'] = duplicate_count
baseline_test['duplicate_sum'] = duplicate_sum
baseline_test['duplicate_mean'] = baseline_test['duplicate_sum'] / baseline_test['duplicate_count']
baseline_test['duplicate_mean'] = baseline_test['duplicate_mean'].fillna(0)
baseline_test['dif_count'] = dif_count
baseline_test['dif_sum'] = dif_sum
baseline_test['dif_mean'] = baseline_test['dif_sum'] / baseline_test['dif_count']
baseline_test['dif_mean'] = baseline_test['dif_mean'].fillna(0)
baseline_test['ratio_duplicate/dif_count'] = baseline_test['duplicate_count'] / baseline_test['dif_count']
我们形象化了一些迹象。
编码
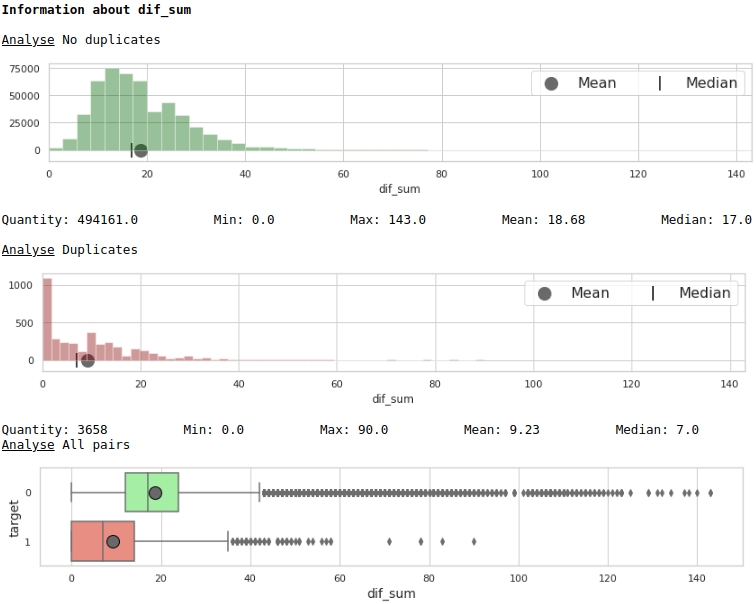
data = baseline_train
analyse = 'dif_sum'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)图4“直方图和带有小胡子的盒子,用于评估符号的重要性”
编码
data = baseline_train
analyse1 = 'duplicate_mean'
analyse2 = 'dif_mean'
size = (14,6)
two_features(data,analyse1,analyse2,size)图№5“散点图”
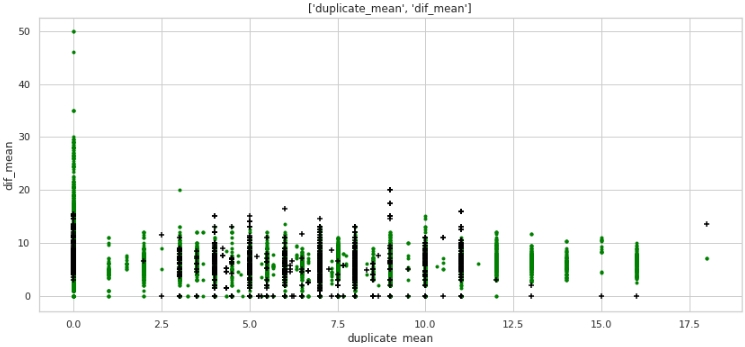
什么都不是,但是标记。请注意,许多目标标签为1的公司在文本中重复项为零,并且许多公司名称中重复项(平均超过12个单词)都属于目标标签为0
的公司。让我们看一下表格数据,为查询做准备在第一种情况下:公司名称中的重复项为零,但公司相同。
编码
baseline_train[
baseline_train['duplicate_mean']==0][
baseline_train['target']==1].drop(
['duplicate', 'difference',
'name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated'],axis=1)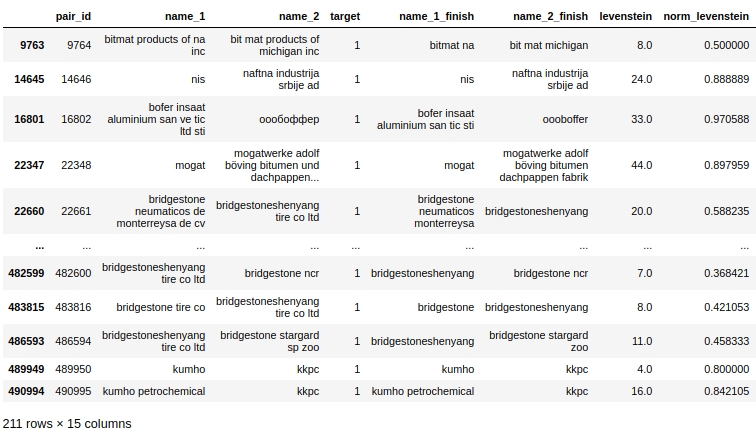
显然,我们的处理中存在系统错误。我们没有考虑到单词的拼写不仅可以有错误,而且可以简单地组合在一起,或者相反,在不需要的情况下可以分别拼写。例如,对#9764。在第一列“ bitmat”中的第二列“ bit mat”中,现在这不是两倍,但是公司是相同的。或另一个示例,配对#482600“ bridgestoneshenyang”和“ bridgestone”。
可以做什么。对我而言,第一件事不是直接在额头上进行比较,而是使用Levenshtein指标。但是在这里,伏击也在等待着我们:“普利司通沉阳”和“普利司通”之间的距离将不小。也许将词法化解救出来,但是再次不清楚如何对公司名称进行词法化。或者,您可以使用Tamimoto系数,但让我们暂时让更多有经验的同志继续前进。
让我们将文字中的单词与石化,建筑和其他行业中排名前50位的控股品牌名称中的单词进行比较。让我们获得第二大功能。第二个CHIT
实际上,有两种违反比赛规则的行为:
- -, , «duplicate_name_company»
- -, . , .
竞争规则均禁止使用这两种技术。您可以绕过禁令。为此,您需要不从训练样本的选择性视图中手动而是自动地从外部源编译持有名称的列表。但是随后,首先,馆藏的列表将变得很大,在工作中提议的单词的比较将花费非常多的时间,其次,仍然需要编译此列表:)因此,为了简化研究,我们将检查模型的质量将提高多少。这些迹象。展望未来-质量在不断提高!
使用第一种方法,一切似乎都很清楚,但是第二种方法需要说明。
因此,让我们确定具有公司名称的第一列每一行中每个单词到顶级石化公司列表中(不仅是)的每个单词之间的Levenshtein距离。
如果Levenshtein距离与单词长度的比率小于或等于0.4,则我们确定Levenshtein距离与顶级公司列表中所选单词的距离与第二列中每个单词的比率-第二公司的名称。
如果第二个系数(排名靠前的公司的距离与字长的比率)小于或等于0.4,则我们在表中固定以下值:
- Levenshtein从排名第一的公司的单词到排名最佳的公司的单词的距离
- Levenshtein从第二大公司列表中的一个单词到顶级公司列表中的一个单词的距离
- 列表1中单词的长度
- 清单2中单词的长度
- 最佳公司列表中的单词长度
- 列表1中单词长度与距离的比率
- 列表2中单词的长度与距离的比率
一行中可以有多个匹配项,让我们选择最小的匹配项(聚合函数)。
我想再次提请您注意以下事实,即所提出的用于生成特征的方法会占用大量资源,并且在从外部来源获取列表的情况下,将需要更改用于编译度量的代码。
编码
# create information about duplicate name of petrochemical companies from top list
list_top_companies = list_top_companies
dp_train = []
for i in list(baseline_train['duplicate']):
dp_train.append(''.join(list(set(i) & set(list_top_companies))))
dp_test = []
for i in list(baseline_test['duplicate']):
dp_test.append(''.join(list(set(i) & set(list_top_companies))))
baseline_train['duplicate_name_company'] = dp_train
baseline_test['duplicate_name_company'] = dp_test
# replace name duplicate to number
baseline_train['duplicate_name_company'] =\
baseline_train['duplicate_name_company'].replace('',0,regex=True)
baseline_train.loc[baseline_train['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
baseline_test['duplicate_name_company'] =\
baseline_test['duplicate_name_company'].replace('',0,regex=True)
baseline_test.loc[baseline_test['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
# create some important feature about similar words in the data and names of top companies for TRAIN
# (levenstein distance, length of word, ratio distance to length)
baseline_train = dist_name_to_top_list_make(baseline_train,
'name_1_finish','name_2_finish',list_top_companies)
# create some important feature about similar words in the data and names of top companies for TEST
# (levenstein distance, length of word, ratio distance to length)
baseline_test = dist_name_to_top_list_make(baseline_test,
'name_1_finish','name_2_finish',list_top_companies)
让我们通过图表的棱镜来看一下功能的有用性
编码
data = baseline_train
analyse = 'levenstein_dist_w1_top_w_min'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)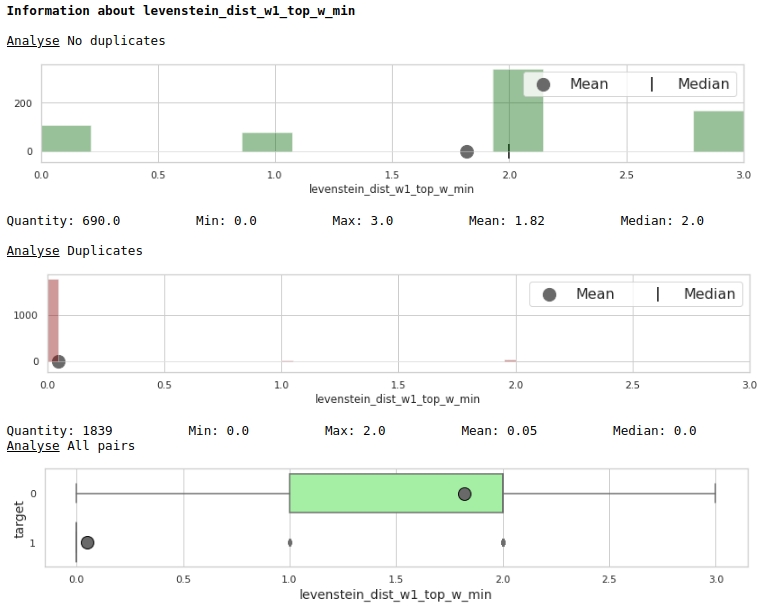
很好。
准备要提交给模型的数据
我们有一张大桌子,不需要所有数据进行分析。让我们看一下表列的名称。
编码
baseline_train.columns
让我们选择将要分析的那些列。
让我们修复种子以提高结果的可重复性。
编码
# fix some parameters
features = ['levenstein','norm_levenstein',
'duplicate_count','duplicate_sum','duplicate_mean',
'dif_count','dif_sum','dif_mean','ratio_duplicate/dif_count',
'duplicate_name_company',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min'
]
seed = 42在最终对所有可用数据进行模型训练并发送解决方案进行验证之前,测试模型是有意义的。为此,我们将训练集分为有条件训练和有条件测试。我们将评估其质量,如果适合我们,我们会将解决方案发送给竞争对手。
编码
# provides train/test indices to split data in train/test sets
split = StratifiedShuffleSplit(n_splits=1, train_size=0.8, random_state=seed)
tridx, cvidx = list(split.split(baseline_train[features],
baseline_train["target"]))[0]
print ('Split baseline data train',baseline_train.shape[0])
print (' - new train data:',tridx.shape[0])
print (' - new test data:',cvidx.shape[0])建立和训练模型
我们将使用Light GBM库中的决策树作为模型。
过多调整参数没有意义。我们看一下代码。
编码
# learning Light GBM Classificier
seed = 50
params = {'n_estimators': 1,
'objective': 'binary',
'max_depth': 40,
'min_child_samples': 5,
'learning_rate': 1,
# 'reg_lambda': 0.75,
# 'subsample': 0.75,
# 'colsample_bytree': 0.4,
# 'min_split_gain': 0.02,
# 'min_child_weight': 40,
'random_state': seed}
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train.iloc[tridx][features].values,
baseline_train.iloc[tridx]["target"].values)该模型已经过调整和培训。现在让我们看一下结果。
编码
# make predict proba and predict target
probability_level = 0.99
X = baseline_train
tridx = tridx
cvidx = cvidx
model = model
X_tr, X_cv = contingency_table(X,features,probability_level,tridx,cvidx,model)
train_matrix_confusion = matrix_confusion(X_tr)
cv_matrix_confusion = matrix_confusion(X_cv)
report_score(train_matrix_confusion,
cv_matrix_confusion,
baseline_train,
tridx,cvidx,
X_tr,X_cv)
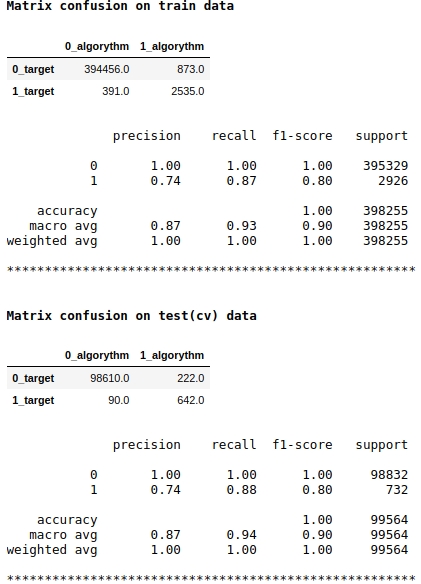
请注意,我们将f1质量指标用作模型得分。这意味着有必要调节将对象分配给类别1或0的概率级别。我们选择了0.99的级别,即,如果概率等于或大于0.99,则将对象分配给类别1,低于0.99的对象-归类为0。这很重要-您可以大大提高速度如此棘手的简单技巧。
质量似乎还不错。在有条件的测试样本中,该算法在定义222个0类对象时出错,而在90个属于0类的对象上出错,并将它们分配给1类(请参见矩阵对测试(cv)数据的混淆)。
让我们看看哪些标志最重要,哪些不是。
编码
start = 0
stop = 50
size = (12,6)
tg = table_gain_coef(model,features,start,stop)
gain_hist(tg,size,start,stop)
display(tg)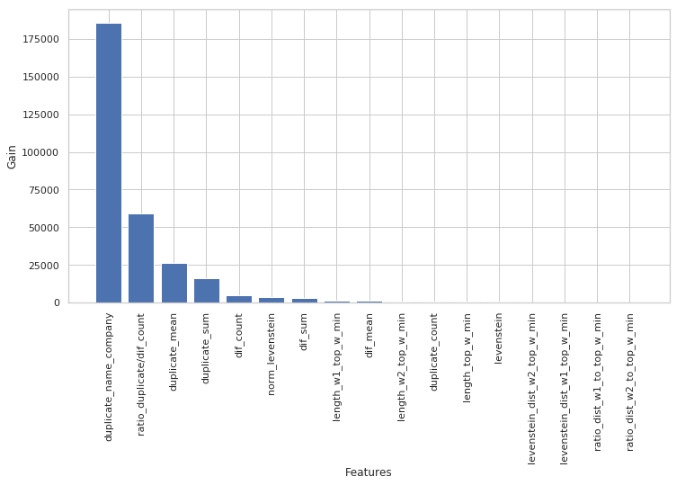
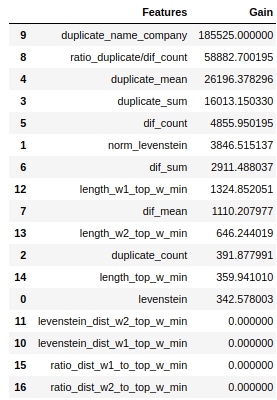
请注意,我们使用“ gain”参数而非“ split”参数来评估功能的重要性。这很重要,因为在非常简化的版本中,第一个参数表示特征对熵降低的贡献,而第二个参数指示特征用于标记空间的次数。
乍一看,我们已经使用了很长时间的功能“ levenstein_dist_w1_top_w_min”根本没有提供任何信息-其贡献为0。但这只是乍一看。它的含义几乎完全与“ duplicate_name_company”属性重复。如果删除“ duplicate_name_company”并保留“ levenstein_dist_w1_top_w_min”,则第二个功能将取代第一个功能,并且质量不会改变。已检查!
通常,这样的标志很方便,特别是当您具有数百个功能并且模型具有一堆铃铛和5000次迭代时,您可以批量删除功能,并观察这种不狡猾的动作带来的质量提高。在我们的情况下,删除功能不会影响质量。
让我们看一下配合表。首先,让我们看一下“假阳性”对象,即我们算法确定为相同的对象并将它们分配给类别1,但实际上它们属于类别0。
编码
X_cv[X_cv['False_Positive']==1][0:50].drop(['name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated', 'duplicate', 'difference',
'levenstein',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min',
'True_Positive','True_Negative','False_Negative'],axis=1)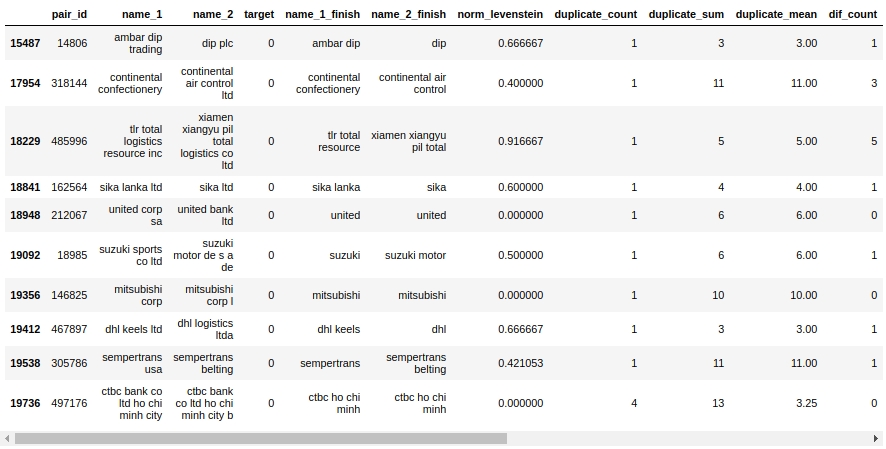
是的 这里,人不会立即确定0或1。例如,对#146825“ Mitsubishi corp”和“ Mitsubishi corp l”。眼睛说这是同一回事,但样本显示这是不同的公司。谁相信?
假设您可以立即挤出-我们挤出了。我们会将剩下的工作留给有经验的同志:)
让我们将数据上传到组织者的网站上,并找出对工作质量的评估。
比赛结果
编码
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train[features].values,
baseline_train["target"].values)
sample_sub = pd.read_csv('sample_submission.csv', index_col="pair_id")
sample_sub['is_duplicate'] = (model.predict_proba(
baseline_test[features].values)[:, 1] > probability_level).astype(np.int)
sample_sub.to_csv('baseline_submission.csv')
因此,考虑到禁止的方法,我们的速度为:0.5999
如果不使用该方法,质量将介于0.3到0.4之间。为了准确起见,有必要重新启动模型,但是我有点太懒了:)
让我们更好地总结一下所获得的经验。
首先,如您所见,我们已经获得了可重现的代码和相当充分的文件结构。由于我很少的经验,我曾经填补了很多坎precisely,正是因为我匆忙完成了工作,只是为了获得或多或少的令人愉悦的速度。结果,该文件被证明是一个星期后打开它已经很恐怖了-没有什么是那么清楚了。因此,我的信息是立即编写代码并使文件可读,这样一年后您就可以返回数据,首先查看结构,了解所采取的步骤,然后可以轻松地分解每个步骤。当然,如果您是初学者,则在第一次尝试时文件不会很漂亮,代码会中断,会有拐杖,但是如果您在研究过程中定期重写代码,然后经过5-7次重写时间,您自己会惊讶于代码的清洁程度,甚至发现错误并提高了速度。不要忘记这些功能,它使文件非常易于阅读。
其次,在每次处理数据后,检查是否一切都按计划进行。为此,您需要能够过滤熊猫中的表格。这项工作有很多过滤功能,可用于健康检查:)
第三,在分类任务中,始终总是彻头彻尾地同时形成表格和共轭矩阵。从表中,您可以轻松找到算法错误的对象。首先,请尝试注意那些被称为系统错误的错误,它们需要花费更少的精力进行修复,并提供更多的结果。然后,当您找出系统错误时,请转至特殊情况。通过错误矩阵,您将看到算法在哪里犯了更多错误:在类0或1中。您将从此处挖掘错误。例如,我注意到我的树很好地定义了类1,但是在类0上犯了很多错误,也就是说,树经常“说”该对象属于类1,而实际上是0。我假设它可能是与将对象分类为0或1的概率级别相关联。我的级别固定为0.9。将对象分配给1类的可能性级别增加到0.99,这使得对1类对象的选择更加困难和不确定-我们的速度已得到显着提高。
再次,我将指出参加比赛的目的不是为了获得奖品,而是为了获得经验。考虑到比赛开始之前,我不知道如何在机器学习中处理文本,因此,几天之内,我得到了一个简单但仍有效的模型,那么我们可以说达到了目标。另外,对于数据科学领域的任何新手武士来说,我认为获得经验而不是奖励是很重要的,或者经验是奖励。因此,不要害怕参加比赛,加油,每个人都是海狸!
在本文发表时,竞争尚未结束。根据比赛的结果,在本文的评论中,我将介绍最大公平速度,改善模型质量的方法和功能。
而且您是一位亲爱的读者,如果您现在就如何提高速度有想法,请在评论中写下。做好事:)