LightGBM通过添加一种自动对象选择以及侧重于使用大梯度进行增强的示例来扩展了“梯度增强”算法。这可以导致学习的急剧加速和更好的预测性能。因此,当使用表格数据处理回归和分类预测建模问题时,LightGBM已成为机器学习竞赛的实际算法。在本教程中,您将学习如何为分类和回归设计轻梯度增强机器集成。完成本教程后,您将知道:
- 光梯度增强机(LightGBM)是随机梯度增强集成的高效开源实现。
- 如何使用scikit-learn API开发用于分类和回归的LightGBM集成体。
- 如何调查LightGBM模型的超参数对其性能的影响。

本教程分为三个部分。
- LightBLM算法。
- 适用于LightGBM的Scikit-Learn API。
-用于分类的LightGBM合奏。
-用于回归的LightGBM合奏。 - LightGBM超参数。
-研究树木数量。
-探索树的深度。
-学习率的研究。
-研究助推器的类型。
LightBLM算法
梯度提升是指一类可用于分类问题或预测回归建模的集成机器学习算法。
集成是根据决策树模型构建的。每次将一棵树添加到集合中,并对其进行训练以纠正先前模型产生的预测误差。这是一种称为Boosting的集成机器学习模型。
使用任何任意的微分损失函数和梯度下降优化算法对模型进行训练。这将方法命名为“梯度增强”,因为在训练模型时,像神经网络一样,损失梯度被最小化。有关梯度增强的更多信息,请参见教程:“对ML梯度提升算法的简要介绍。”
LightGBM是梯度提升的开源实现,旨在提高效率,甚至可能比其他实现更高效。
因此,LightGBM是一个开源项目,软件库和机器学习算法。也就是说,该项目与Extreme Gradient Boosting或XGBoost技术非常相似。
LightGBM已由Golin,K.等人描述。有关更多信息,请参见2017年题为“ LightGBM:高效梯度提升决策树”的文章。该实现引入了两个关键思想:GOSS和EFB。
梯度单向采样(GOSS)是“梯度增强”的一种改进,重点是那些导致较大梯度的教程,从而加快了学习速度并降低了该方法的计算复杂性。
使用GOSS,我们可以排除大部分具有小梯度的数据实例,而仅使用其余数据实例来估计信息增益。我们认为,由于具有较大梯度的数据实例在计算信息增益中起着更重要的作用,因此GOSS可以在数据量较小的情况下获得相当准确的信息增益估计。
排他特征捆绑或EFB是一种组合稀疏(大多数为零)的互斥特征的方法,例如以单一编码方式编码的分类输入变量。因此,这是一种自动特征选择。
...我们打包互斥特征(即它们很少同时采用非零值)以减少特征数量。
这两个更改一起可以将算法的训练时间加快多达20倍。因此,通过添加GOSS和EFB,可以将LightGBM视为梯度增强决策树(GBDT)。
我们将新的GBDT实现称为GOSS和EFB LightGBM。我们在几个公开的数据集上进行的实验表明,LightGBM将传统GBDT的学习过程加快了20倍以上,达到了几乎相同的准确性。
适用于LightGBM的Scikit-Learn API
可以将LightGBM安装为独立库,并可以使用scikit-learn API开发LightGBM模型。
第一步是安装LightGBM库。在大多数平台上,可以使用pip包管理器来完成;例如:
sudo pip install lightgbm您可以像这样检查安装和版本:
# check lightgbm version
import lightgbm
print(lightgbm.__version__)该脚本将显示已安装的LightGBM的版本。您的版本应该相同或更高。如果不是,请更新LightGBM。如果您需要针对开发环境的特定说明,请参阅教程:LightGBM安装指南。
尽管我们使用通过scikit-learn包装器类的方法LGBMRegressor和LGBMClassifier,但LightGBM库具有其自己的API 。这将使整个scikit-learn机器学习库可用于数据准备和模型评估。
这两个模型以相同的方式工作,并使用相同的参数来影响如何创建决策树并将其添加到集合中。建立模型时,会使用随机性。这意味着算法每次在相同数据上运行时,都会创建一个略有不同的模型。
当将机器学习算法与随机学习算法一起使用时,建议通过在多次运行或交叉验证的重复过程中平均其性能来评估它们。在拟合最终模型时,可能需要增加树的数量,直到模型的方差随着重复的估计而减小,或者要训练几个最终模型并平均其预测。让我们看一下为分类和回归设计LightGBM集合。
LightGBM集成分类
在本节中,我们将研究如何将LightGBM用于分类任务。首先,我们可以使用make_classification()函数创建具有1000个示例和20个输入功能的综合二进制分类问题。请参阅下面的整个示例。
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# summarize the dataset运行示例将创建一个数据集,并总结输入和输出组件的形状。
(1000, 20) (1000,)然后,我们可以在该数据集上评估LightGBM算法。我们将使用具有3个重复且k为10的重复分层k倍交叉验证对模型进行评估。我们将报告所有重复和折叠的模型准确性的均值和标准差。
# evaluate lightgbm algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))运行示例将显示模型的均值和标准差的准确性。
注意:由于算法或估计过程的随机性,或者数值精度的不同,您的结果可能会有所不同。多次尝试该示例,然后比较平均结果。
在这种情况下,我们可以看到具有默认超参数的LightGBM集成在此测试数据集上实现了约92.5%的分类精度。
Accuracy: 0.925 (0.031)我们还可以将LightGBM模型用作最终模型,并进行分类预测。首先,LightGBM集合适合所有可用数据,其次,您可以调用预报()函数对新数据进行预测。下面的示例在我们的二进制分类数据集中展示了这一点。
# make predictions using lightgbm for classification
from sklearn.datasets import make_classification
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808]
yhat = model.predict([row])
print('Predicted Class: %d' % yhat[0])运行示例将为整个数据集训练一个LightGBM集成模型,然后使用它来预测新的数据行,就像在应用程序中使用该模型一样。
Predicted Class: 1既然我们熟悉使用LightGBM进行分类,那么让我们看一下回归API。
LightGBM回归乐团
在本节中,我们将研究如何将LightGBM用于回归问题。首先,我们可以使用make_regression()函数
创建具有1000个示例和20个输入要素的综合回归问题。请参阅下面的整个示例。
# test regression dataset
from sklearn.datasets import make_regression
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# summarize the dataset
print(X.shape, y.shape)运行示例将创建一个数据集并总结输入和输出组件。
(1000, 20) (1000,)其次,我们可以在该数据集上评估LightGBM算法。
与上一部分一样,我们将通过重复的k倍交叉验证对模型进行评估,该交叉验证具有三个重复且k等于10。我们将报告所有重复和交叉验证组中模型的平均绝对误差(MAE)。 scikit-learn库使MAE变为负数,从而使其最大化而不是最小化。这意味着较大的负MAE会更好,理想模型的MAE为0。完整示例如下所示。
# evaluate lightgbm ensemble for regression
from numpy import mean
from numpy import std
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# evaluate the model
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))运行示例将报告模型的均值和标准差。
注意:由于算法或估计过程的随机性,或者数值精度的不同,您的结果可能会有所不同。考虑多次运行该示例并比较平均值。在这种情况下,我们看到具有默认超参数的LightGBM集合达到了大约60的MAE。
MAE: -60.004 (2.887)我们还可以将LightGBM模型用作最终模型,并对回归进行预测。首先,对LightGBM集合进行所有可用数据的训练,然后可以调用predict()函数来预测新数据。下面的示例在我们的回归数据集中展示了这一点。
# gradient lightgbm for making predictions for regression
from sklearn.datasets import make_regression
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.20543991,-0.97049844,-0.81403429,-0.23842689,-0.60704084,-0.48541492,0.53113006,2.01834338,-0.90745243,-1.85859731,-1.02334791,-0.6877744,0.60984819,-0.70630121,-1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,-0.11154792]
yhat = model.predict([row])
print('Prediction: %d' % yhat[0]) 运行示例将在整个数据集上训练LightGBM集成模型,然后使用它来预测新的数据行,就像在应用程序中使用该模型一样。
Prediction: 52现在,我们已经熟悉了使用scikit-learn API评估和应用LightGBM集成体,让我们来看一下模型的设置。
LightGBM超参数
在本节中,我们将仔细研究一些对LightGBM集合很重要的超参数及其对模型性能的影响。LightGBM有很多超参数要看,这里我们看树的数量及其深度,学习率和增强类型。有关调整LightGBM超参数的一般提示,请参阅文档:调整LightGBM参数。
检查树木数量
LightGBM集成算法的一个重要超参数是集成中使用的决策树数。回想一下,决策树被顺序地添加到模型中,以尝试纠正和改进先前树做出的预测。该规则通常有效:树木越多越好。可以使用n_estimators参数指定树的数量,该参数的默认值为100。下面的示例检查从10到5000的树数量的影响。
# explore lightgbm number of trees effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
trees = [10, 50, 100, 500, 1000, 5000]
for n in trees:
models[str(n)] = LGBMClassifier(n_estimators=n)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()首先运行示例将显示每个决策树数量的平均精度。
注意:由于算法或估计过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行该示例并比较平均结果。
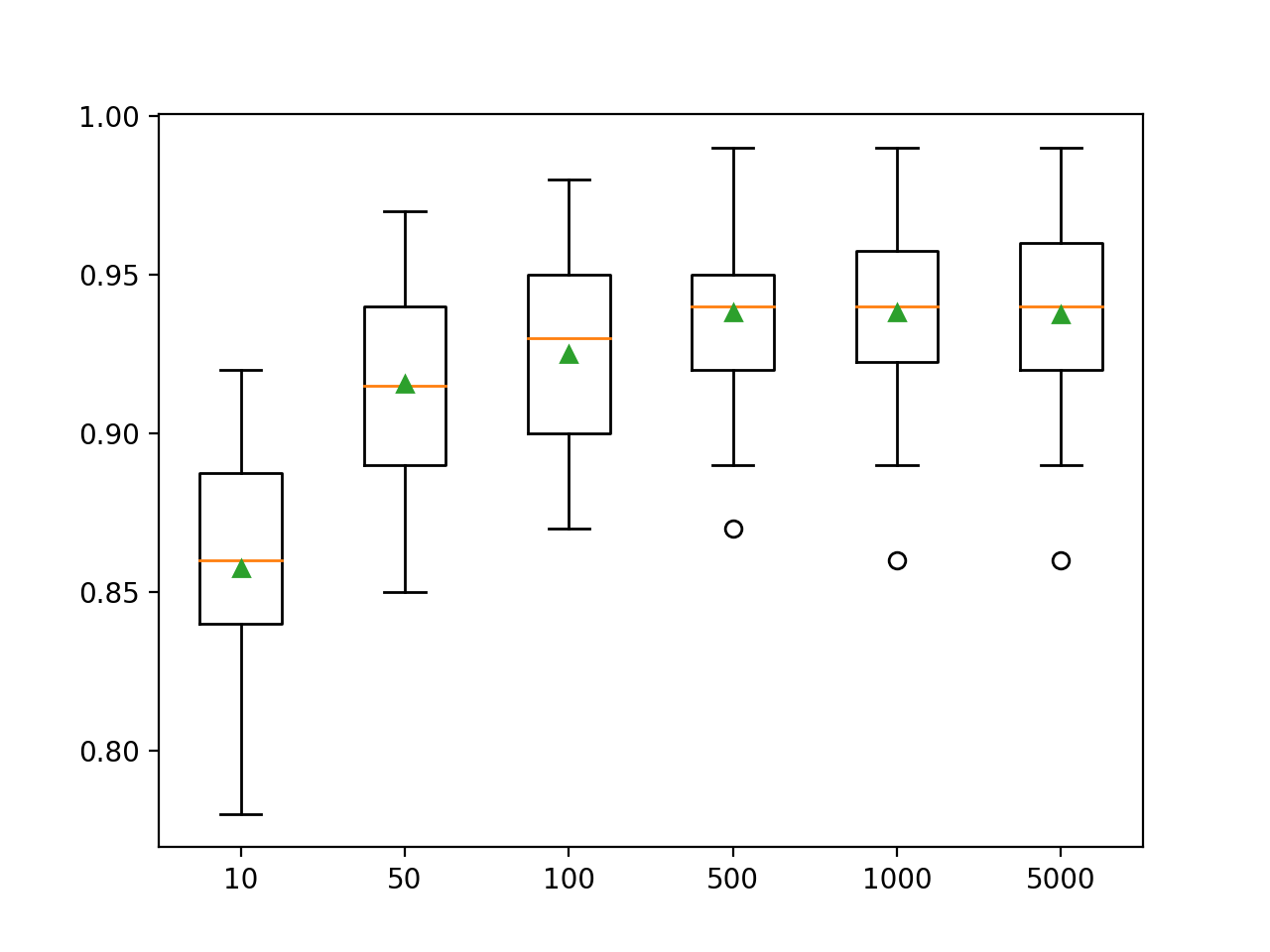
在这里,我们看到此数据集的性能提高到大约500棵树,此后看起来似乎很稳定。
>10 0.857 (0.033)
>50 0.916 (0.032)
>100 0.925 (0.031)
>500 0.938 (0.026)
>1000 0.938 (0.028)
>5000 0.937 (0.028)创建箱须图以分配每个配置数量的树的准确性得分。总体上,模型的性能和整体规模都有增加的趋势。
检查一棵树的深度
更改添加到集合中的每棵树的深度是用于梯度增强的另一个重要的超参数。树的深度决定了每棵树在训练数据集中的专业程度:它的一般性或训练性。首选的树不能是太浅和太宽(例如AdaBoost),也不要太深和专门(例如引导聚合)。
渐变增强通常适用于中等深度的树,平衡训练和通用性。树的深度由max_depth参数控制,默认值为未定义值,因为管理树的复杂性的默认机制是使用有限数量的节点。
有两种主要方法可以控制树的复杂度:通过最大树深度和最大数量的树终端节点(叶)。我们正在这里检查叶子的数量,因此需要通过指定num_leaves参数来增加数量以支持更深的树。下面我们检查从1到10的树深度及其对模型性能的影响。
# explore lightgbm tree depth effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for i in range(1,11):
models[str(i)] = LGBMClassifier(max_depth=i, num_leaves=2**i)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()首先运行示例将显示每个调整的树深度的平均精度。
注意:由于算法或估计过程的随机性,或者数值精度的不同,您的结果可能会有所不同。考虑多次运行该示例并比较平均值。
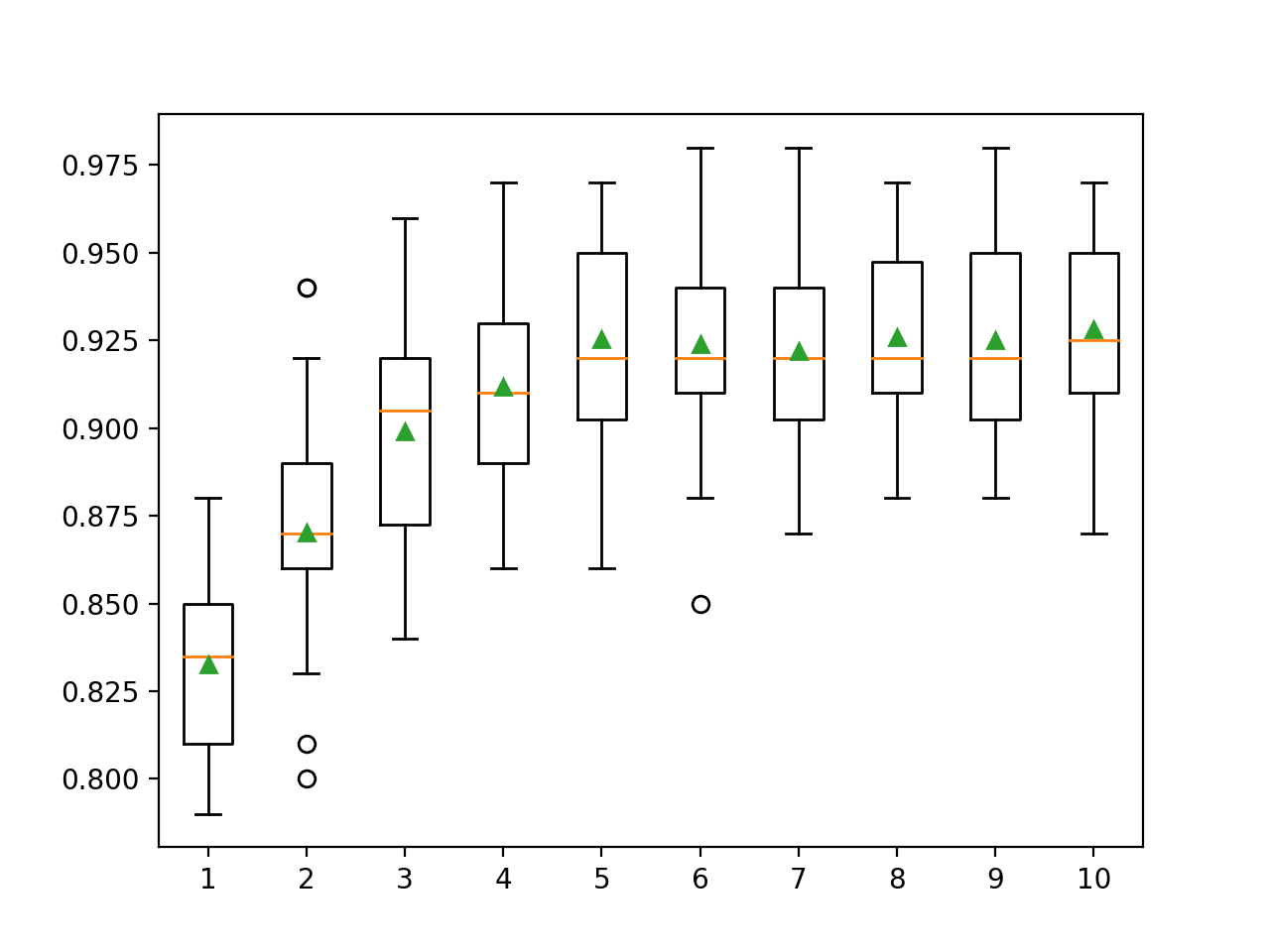
在这里我们可以看到,性能随着树深度的增加而提高,树深度可能达到10级。探索更深的树木将是有趣的。
>1 0.833 (0.028)
>2 0.870 (0.033)
>3 0.899 (0.032)
>4 0.912 (0.026)
>5 0.925 (0.031)
>6 0.924 (0.029)
>7 0.922 (0.027)
>8 0.926 (0.027)
>9 0.925 (0.028)
>10 0.928 (0.029)生成矩形须图以分配每个已配置树深度的准确性得分。通常,模型性能会随着树深度增加到五个级别而增加,此后性能仍然相当平坦。
学习率研究
学习率控制着每个模型对集合预测的贡献程度。较低的速度可能需要集成中的更多决策树。可以使用learning_rate参数控制学习率,默认情况下为0.1。以下检查学习率并比较值从0.0001到1.0的效果。
# explore lightgbm learning rate effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
rates = [0.0001, 0.001, 0.01, 0.1, 1.0]
for r in rates:
key = '%.4f' % r
models[key] = LGBMClassifier(learning_rate=r)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()首先运行示例将显示每个配置的学习率的平均准确性。
注意:由于算法或估计过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行该示例并比较平均值。
在这里,我们看到较高的学习率导致此数据集的性能更好。我们期望在整体中添加更多树以降低学习率将进一步提高性能。
>0.0001 0.800 (0.038)
>0.0010 0.811 (0.035)
>0.0100 0.859 (0.035)
>0.1000 0.925 (0.031)
>1.0000 0.928 (0.025)创建一个小胡子框,以分配每个配置的学习率的准确性得分。通常,随着学习率的提高,模型性能会提高,最高可达1.0

促进类型研究
LightGBM的独特之处在于它支持许多称为Boost类型的Boosting算法。boosting类型是使用boosting_type参数指定的,并使用字符串来确定类型。可能的值:
- 'gbdt':梯度增强决策树(GDBT);
- 'dart':辍学的概念输入到了MART中,我们得到了DART;
- 'goss':渐变单向获取(GOSS)。
默认值为GDBT,这是经典的梯度增强算法。
DART在2015年的一篇题为《DART:辍学满足多个加性回归树》的文章中进行了描述,顾名思义,DART将深度学习的辍学概念添加到了多个加性回归树(MART)算法中,该算法是梯度增强决策树的前身。
该算法的名称很多,包括Gradient TreeBoost,Boosted Trees和Multiple Additive Regression Trees and Trees(MART)。我们使用后一个名称来指代该算法。
向GOSS介绍了LightGBM和lightbgm库。这种方法旨在仅使用那些导致较大误差梯度的实例来更新模型并删除其余实例。
...我们排除了大部分具有小梯度的数据实例,仅使用其余部分来估计信息的增加。
在LightGBM下面,使用三种关键的增强方法在综合分类数据集上进行训练。
# explore lightgbm boosting type effect on performance
from numpy import arange
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
types = ['gbdt', 'dart', 'goss']
for t in types:
models[t] = LGBMClassifier(boosting_type=t)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()首先运行示例将显示每种已配置提升类型的平均准确度。
注意:由于算法或估计过程的随机性,或者数值精度的不同,您的结果可能会有所不同。考虑多次运行该示例并比较平均值。
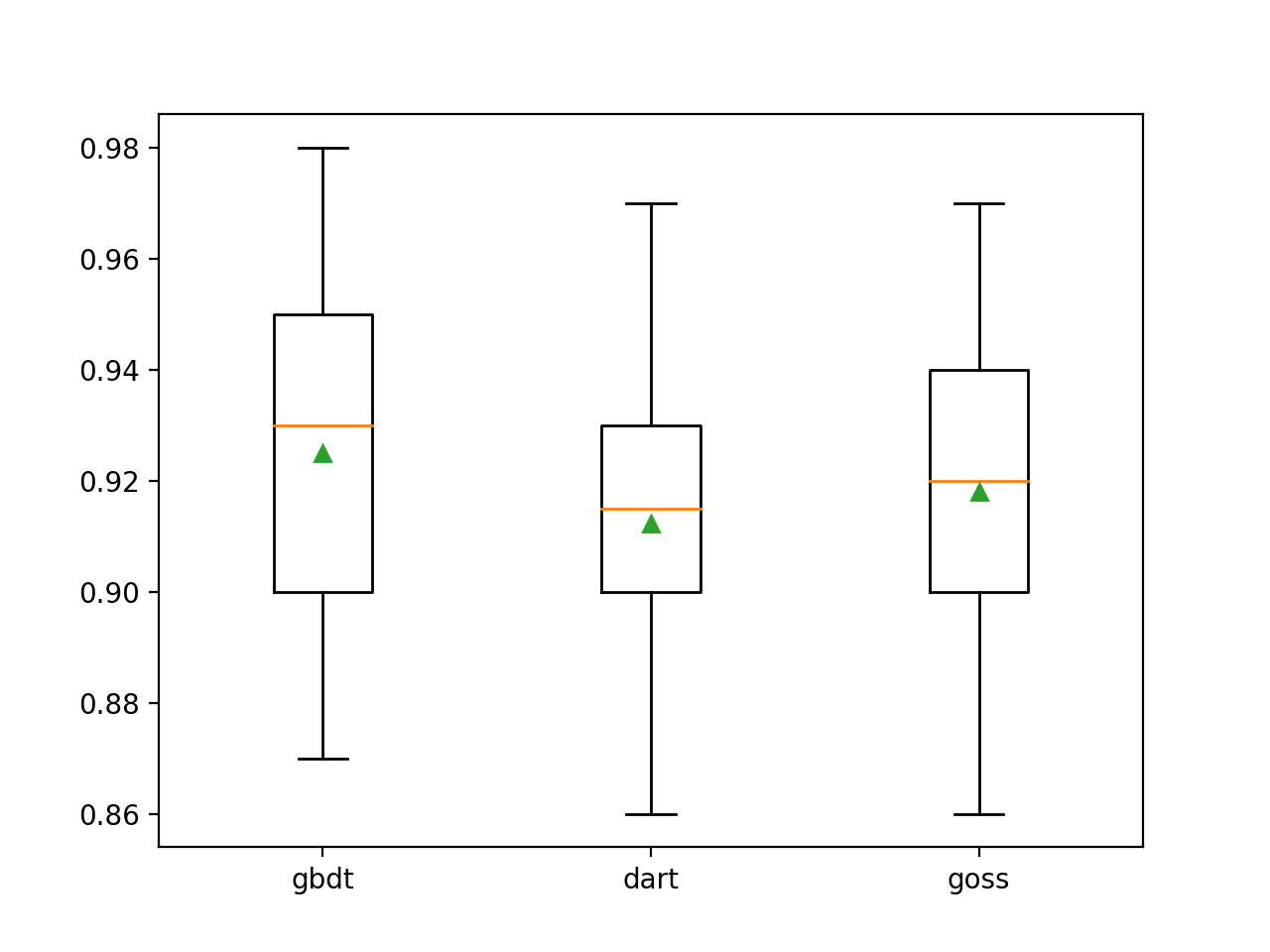
我们可以看到默认的boost方法比其他两个评估方法的性能更好。
>gbdt 0.925 (0.031)
>dart 0.912 (0.028)
>goss 0.918 (0.027)创建了箱须图以分配每种配置的扩增方法的准确度估计值,从而可以直接比较这些方法。

更多课程