
聊天机器人现已广泛应用于各个业务领域。例如,银行可以使用它们来优化其联络中心的工作,立即回答受欢迎的客户问题并向他们提供参考信息。对于客户而言,聊天机器人也是一种便捷的工具:在聊天中编写问题比通过致电联系中心等待答案要容易得多。
在其他领域,聊天机器人也证明了自己的能力:在医学上,聊天机器人可以采访患者,将症状传达给专家,并安排与医生的约会以建立诊断。在物流公司中,聊天机器人将帮助您确定交货日期,更改地址并选择方便的接送点。在大型在线商店中,聊天机器人已部分接管了订单的维护工作,而在汽车共享服务领域,聊天机器人最多可完成90%的操作员任务。但是,聊天机器人尚无法解决投诉。负面反馈和有争议的情况仍然落在操作员和专家的肩膀上。
因此,大多数成长中的企业已经在积极使用聊天机器人与客户合作。但是,实现聊天机器人的好处通常各不相同:在某些公司中,自动化程度达到90%,在其他公司中,自动化程度仅为30%至40%。它取决于什么?这个指标对企业有多好?有没有办法提高聊天机器人自动化水平?本文将解决可以帮助您理解这一问题的问题。
标杆管理
如今,几乎每个业务领域都有自己的竞争环境。许多公司使用类似的业务方法。因此,如果竞争公司在其活动中使用聊天机器人,则最好将它们进行比较。标杆管理是一个很好的比较工具。
在我们的案例中,聊天机器人基准测试将涉及秘密研究,以便将竞争对手的聊天机器人的功能与您自己的聊天机器人的功能进行比较。让我们考虑使用银行聊天机器人为例的情况。
假设一家银行开发了一个聊天机器人,以优化联络中心的运营并降低其维护成本。要进行基准测试,有必要分析其他银行并找出其竞争对手中功能最强大的聊天机器人。
有必要形成一个验证问题列表(至少50个问题,分为几个主题):
- 有关银行服务的问题,例如:“您的存款利率是多少?”,“如何重新发行卡?”。等等
- 参考信息,例如:“当前汇率是多少?”,“如何获得信用休假?”。等等
- 客户的理解水平。(机器人抵制打字错误,错误,口语表达能力),例如:“我正在弹出卡,我在做什么?”,“给手机充值”等。
- 关于抽象主题的对话,例如:“开个玩笑”,“自我隔离时该怎么办?” 等等
注意:这些问题主题仅作为示例提供,可以扩展或更改。
这些是您应该问您的聊天机器人以及竞争对手的聊天机器人的问题。写下问题后,可以使用3个结果选项(取决于结果,记下相应的分数):
- 机器人无法识别客户的问题(0分);
- 机器人识别出客户的问题,但仅在澄清问题后(0.5分);
- 机器人在第一次尝试时就认出了该问题(1分)。
如果聊天机器人将客户转移给话务员,则该问题也被认为无法识别(0分)。
接下来,对每个聊天机器人的得分总数进行汇总,然后计算每个主题上正确识别的问题所占的比例(低-小于40%,中-从40%到80%,高-大于80%),并编制最终评分。结果可以表的形式显示:
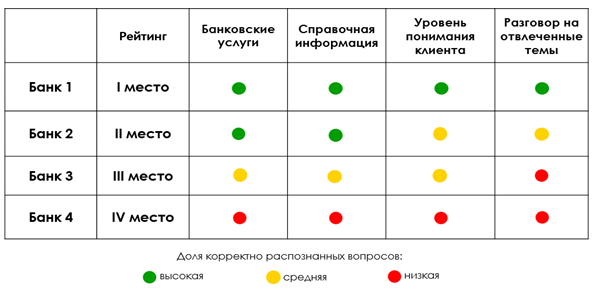
假设根据基准测试结果,该银行的聊天机器人排名第二。可以得出什么结论?结果也不是最好的,但也不是最坏的。根据表格,我们可以说出它不是最强的方面:首先,需要改进算法以正确识别客户的问题(聊天机器人并不总是能理解客户的包含错误和错别字的问题),也不总是支持抽象主题的对话。 ...与排名第一的聊天机器人相比,可以看到更详细的区别。
排名第三的聊天机器人表现得更糟:首先,它需要对银行服务和参考信息的知识库进行认真的修订;其次,对于与客户就抽象主题进行对话的培训不足。显然,与获得第一和第二名的竞争对手相比,这种聊天机器人的自动化水平较低。
因此,根据基准测试的结果,确定了聊天机器人工作的优缺点,并对竞争的聊天机器人进行了比较。下一步是确定这些问题区域。如何做到这一点?让我们考虑一些基于数据分析的方法:AutoML,过程挖掘,DE方法。
自动语言
目前,人工智能已经渗透并继续渗透到许多业务领域,这不可避免地导致对DataScience领域能力的需求增加。但是,对此类专家的需求增长快于其技能水平。事实是,机器学习模型的开发需要大量资源,不仅需要专家的大量知识,而且还需要花费大量时间来建立模型和比较模型。为了减轻由稀缺性造成的压力,并减少开发模型的时间,许多公司已开始创建可以使DataScientists的工作自动化的算法。这种算法称为AutoML。
AutoML,也称为自动机器学习,可帮助DataScientist自动化开发机器学习模型的耗时且重复的任务,同时保持其质量。尽管AutoML模型可以节省您的时间,但只有在解决的问题持久且重复时,它们才有效。在这些条件下,AutoML模型表现良好并且显示出可接受的结果。
现在,让我们使用AutoML解决我们的问题:在聊天机器人的工作中确定问题区域。如上所述,聊天机器人是机器人或专用程序。她知道如何从消息中提取关键字并在数据库中搜索合适的答案。寻找正确的答案是一回事,保持逻辑对话,模仿与真实人的交流是一回事。此过程取决于聊天机器人的脚本编写情况。
想象一个情况,当客户提出一个问题,而聊天机器人奇怪地,不合逻辑地或通常在另一个主题上回答他。结果,客户对这个答案不满意,充其量只写关于自己对答案的误解,最坏的情况是对聊天机器人的负面消息。因此,AutoML的任务是从总数(基于数据库中卸载的chatbot日志)中识别否定对话,此后有必要确定这些对话与哪些场景有关。获得的结果将是完善这些方案的基础。
首先,让我们标记客户与聊天机器人的对话。在每次对话中,我们只留下来自客户的消息。如果在客户的消息中聊天机器人的方向是否定的,或者不理解他的回答,请设置标志= 1,在其他情况下,将其设置为0:

标记来自客户端的消息
接下来,我们声明AutoML模型,在标记的数据上对其进行训练并保存(所有必需的模型参数也会传递,但是在下面的示例中未显示)。
automl = saa.AutoML
res_df, feat_imp = automl.train('test.csv', 'test_preds.csv', 'classification', cache_dir = 'tmp_dir', use_ids = False)
automl.save('prec')我们加载结果模型,然后对测试文件的目标变量进行预测:
automl = saa.AutoML
automl.load('text_model.pkl')
preds_df, score, res_df = automl.predict('test.csv', 'test_preds.csv', cache_dir = 'tmp_dir')
preds_df.to_csv('preds.csv', sep=',', index=False)接下来,我们评估结果模型:
test_df = pd.read_csv('test.csv')
threshold = 0.5
am_test = preds_df['prediction'].copy()
am_test.loc[am_test>=threshold] = 1
am_test.loc[am_test<threshold] = 0
clear_output()
print_result(test_df[target_col], am_test.apply(int))产生的错误矩阵:

在创建模型的过程中,我们尝试最小化类型1错误(将良好的对话归为不良对话),因此,对于所得的分类器,我们在等于0.66的f1度量处停止。在训练有素的模型的帮助下,有可能识别出65,000个“不良”会议,从而使我们能够确定7个效果不佳的情况。
流程挖掘
为了识别问题场景,我们还将使用基于流程挖掘的工具-多种方法和方法的总称,旨在基于事件日志的研究来分析和改进信息系统或业务流程中的流程。
使用这种方法,我们能够确定长时间无效对话所涉及的7种情况:
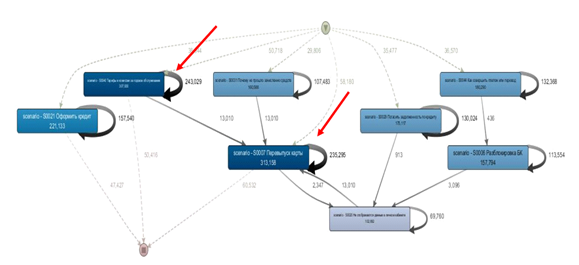
18%的对话有超过4条来自聊天机器人的消息,上图中的
每个元素都是一种情况。从图中可以看到,脚本是循环的,而粗体的循环箭头表示客户端和聊天机器人之间的对话相当长。
此外,为了查找不良情况,我们准备了一个单独的数据集,并基于该数据集构建了图形。为此,仅保留那些无法访问操作员的对话框,然后将其过滤掉具有未解决问题的对话框。结果,我们确定了5种修订场景,其中聊天机器人无法解决客户的问题。
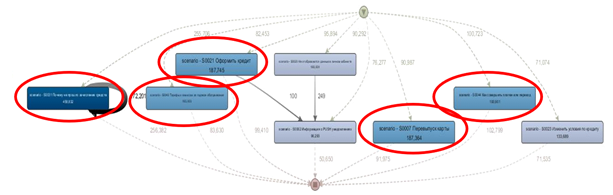
确定的场景占所有对话的15%
DE(数据工程)方法
还使用一种简单的分析方法来搜索问题场景:确定了对话,反馈等级(从客户方面)在1到7分之间,然后选择了此样本中最常见的场景。
例如,通过全面使用基于AutoML,Process Mining和DE的方法,我们在公司的聊天机器人中确定了需要改进的问题区域。
现在,聊天机器人越来越好了!