
有条件无损网络领域正在发生什么
多年来,当数据传输媒体经历快速发展时,工程师设法遇到许多阻碍在以太网上成功实施存储网络和高性能计算集群的现象:损失,无保证的信息传递,死锁,微爆和其他不愉快的事情。
结果,为特定情况构建参考专用网络被认为是正确的:
- IB用于高负载计算集群;
- 经典存储网络的FC;
- 以太网用于服务任务。
尝试实现多功能性的过程类似于插图。

对于某些任务,矢量可以重合(类似于天鹅和小龙虾的矢量),并且可以实现情景通用性,尽管效率要比选择高度专业化的场景低。
如今,华为在多任务融合工厂中看到了未来,并为客户提供了一种AI Fabric解决方案,该解决方案一方面用于提高网络性能而又不造成损失的场景(到2020年每个服务器端口将达到200 Gbps),另一方面旨在提高网络性能。应用程序(迁移到RoCEv2)。
顺便说一句,我们另外有一个关于AI Fabric技术组件的详细帖子。
什么需要优化
在讨论算法之前,先弄清楚它们到底要改进什么是有意义的。
静态ECN导致这样一个事实,即随着具有单个收件人的发送服务器数量的增加,出现了次优的流量模式(坦率地说,我们正在处理所谓的多对一播客模型)。
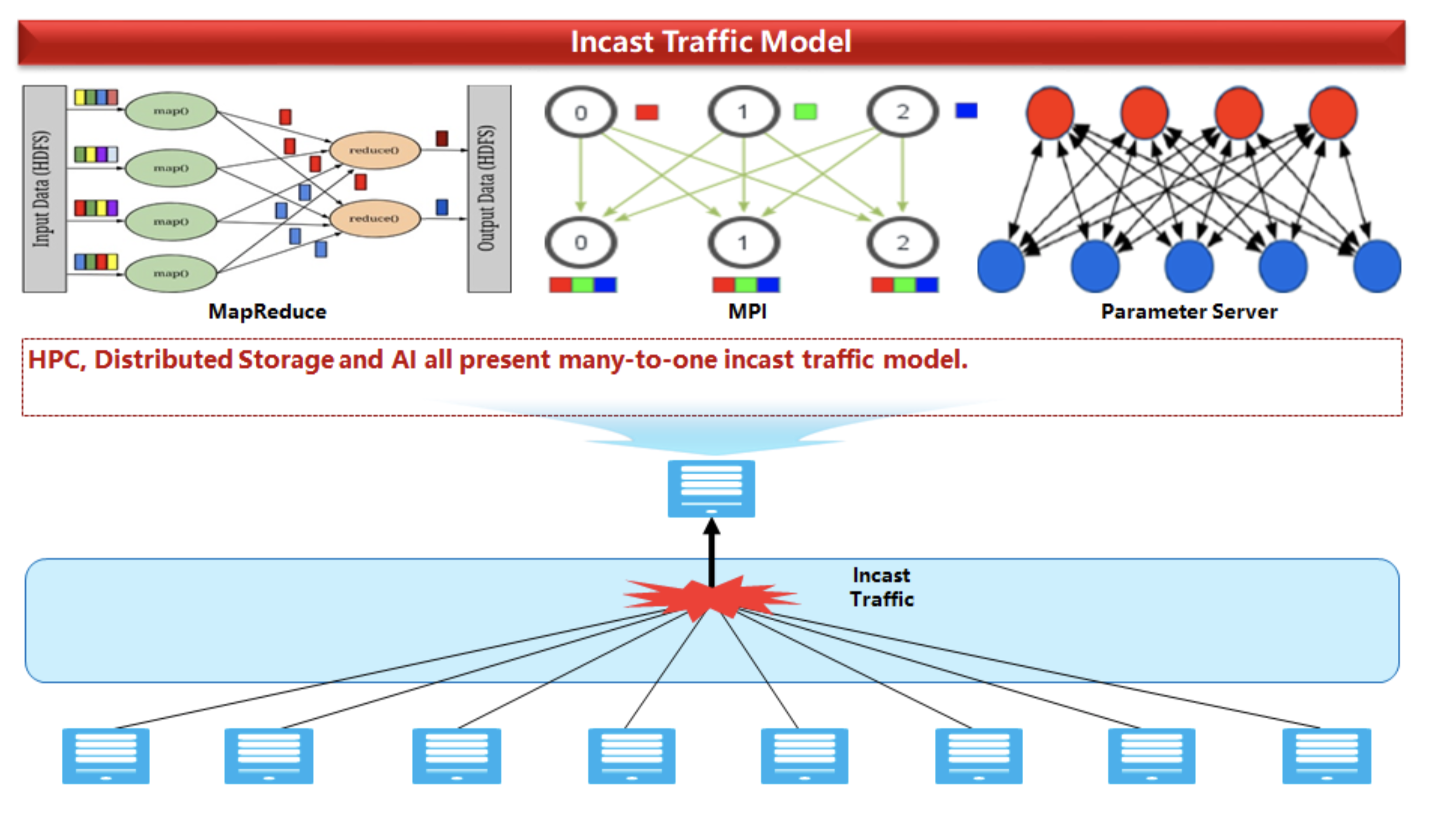
在传统的以太网中,我们必须手动平衡网络丢失的几率和网络本身的不良性能。如果在不进行持续调整的情况下

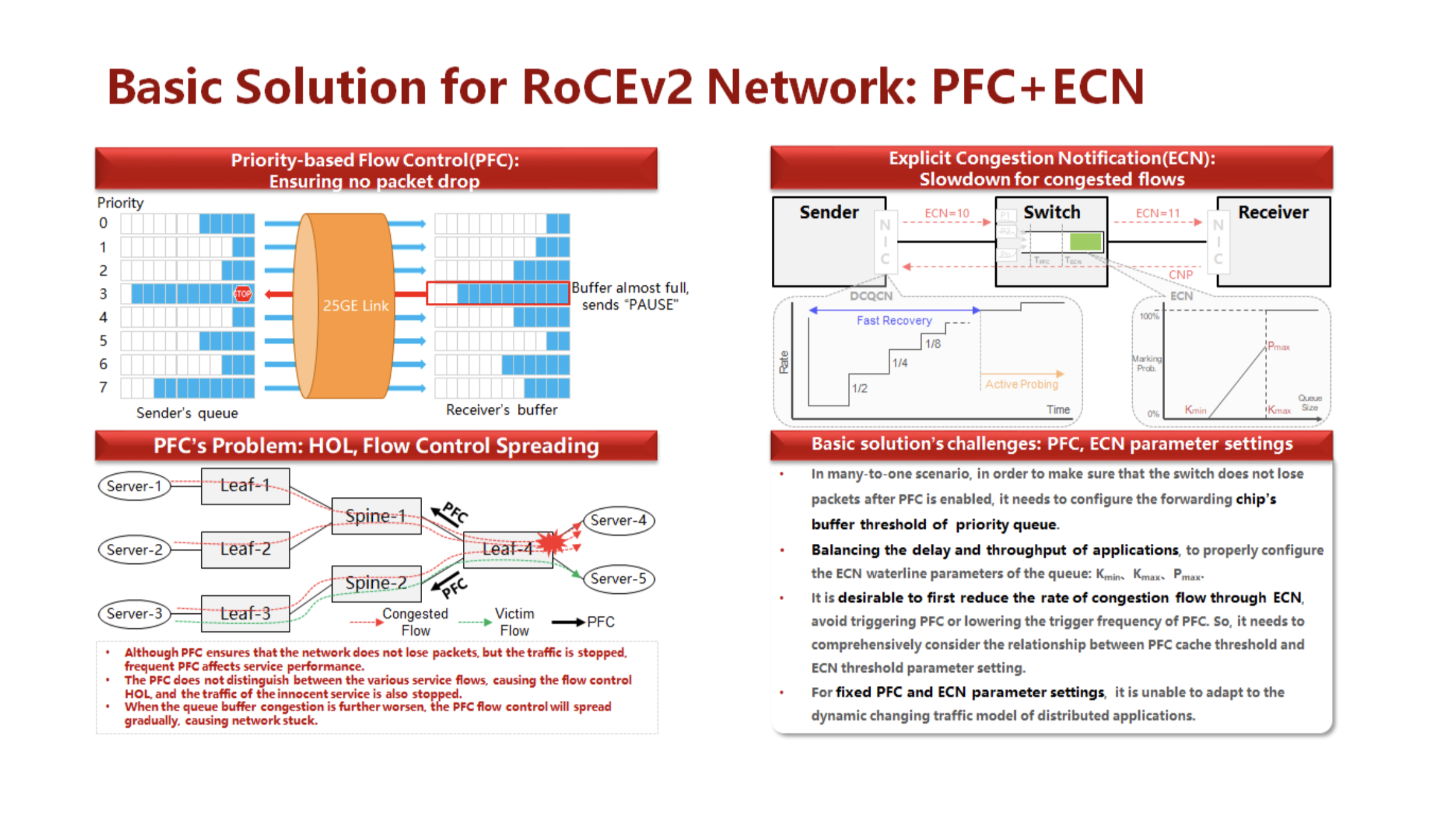
使用PFC / ECN捆绑包,我们还将看到相同的先决条件(请参见下图)。
为了解决上述问题,我们使用AI ECN算法,其实质是及时更改ECN阈值。下图显示了外观。
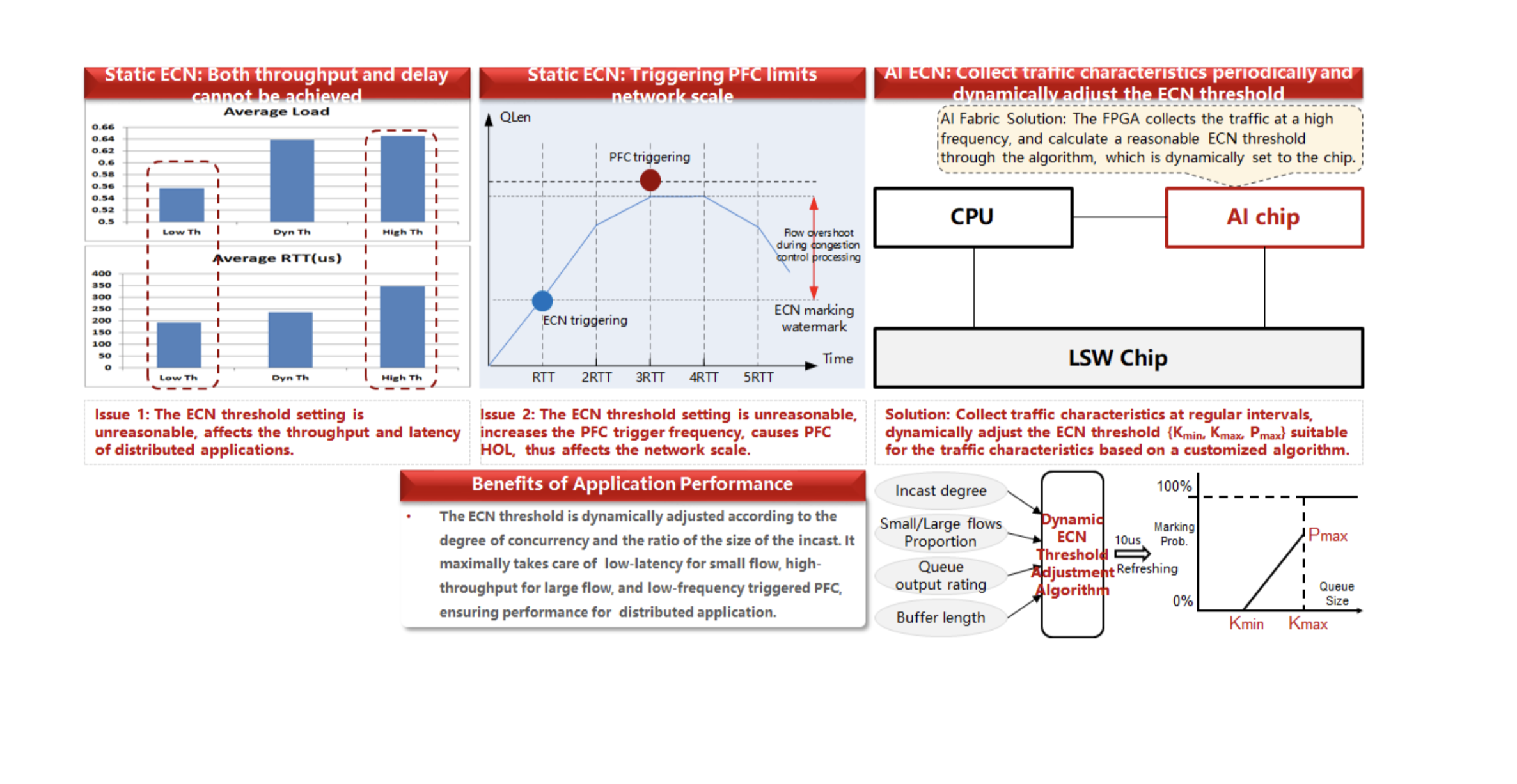
以前,当我们使用Broadcom芯片组+ Ascend 310 AI处理器套件时,用于调整这些参数的选项数量有限。
我们可以有条件地称呼这种变体软件AI ECN,因为逻辑是在单独的芯片上完成的,并且已经“整合”到了商用芯片组中。配备有华为P5芯片组的型号具有更广泛的“人工智能”功能(尤其是在最新版本中),这是因为其上实现了必要功能的很大一部分。

我们如何使用算法
使用Ascend 310(或P卡的内置模块),我们开始分析流量并将其与已知应用程序的基准进行比较。

在已知应用程序的情况下,将实时优化流量指示器,在未知应用程序的情况下,将过渡到下一步。

关键点:
- 进行DDQN强化学习,探索,积累大量基线配置以及探索最佳ECN遵从策略。
- CNN分类器识别方案并确定建议的DDQN阈值是否可靠。
- 如果推荐的DDQN阈值不可靠,则使用启发式方法对其进行校正,以确保该解决方案得到了概括。
这种方法允许您调整使用未知应用程序的机制,如果确实需要,您可以使用交换机管理系统的Northbound API为应用程序设置模型。

关键点:
- DDQN会累积大量基准配置内存样本,并深入检查网络状态和基准配置协调逻辑以学习策略。
- CNN神经网络分类器可识别方案,以避免在未知方案中建议使用不可靠的ECN配置时可能产生的风险。
我们得到什么
经过这样的适应周期并更改了其他网络阈值和设置后,就可以一次解决多种类型的问题。
- 性能问题:低带宽,长延迟,数据包丢失,抖动。
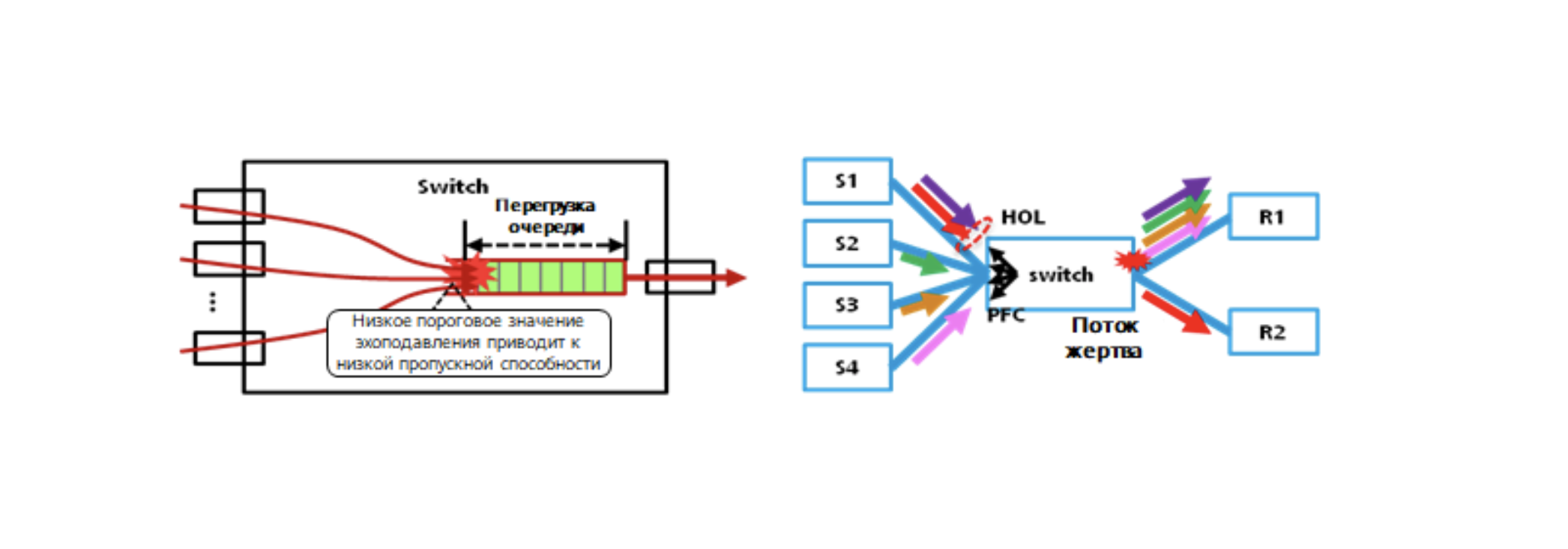
- PFC问题:PFC死锁,HOL,风暴等。PFC技术导致许多系统级问题。
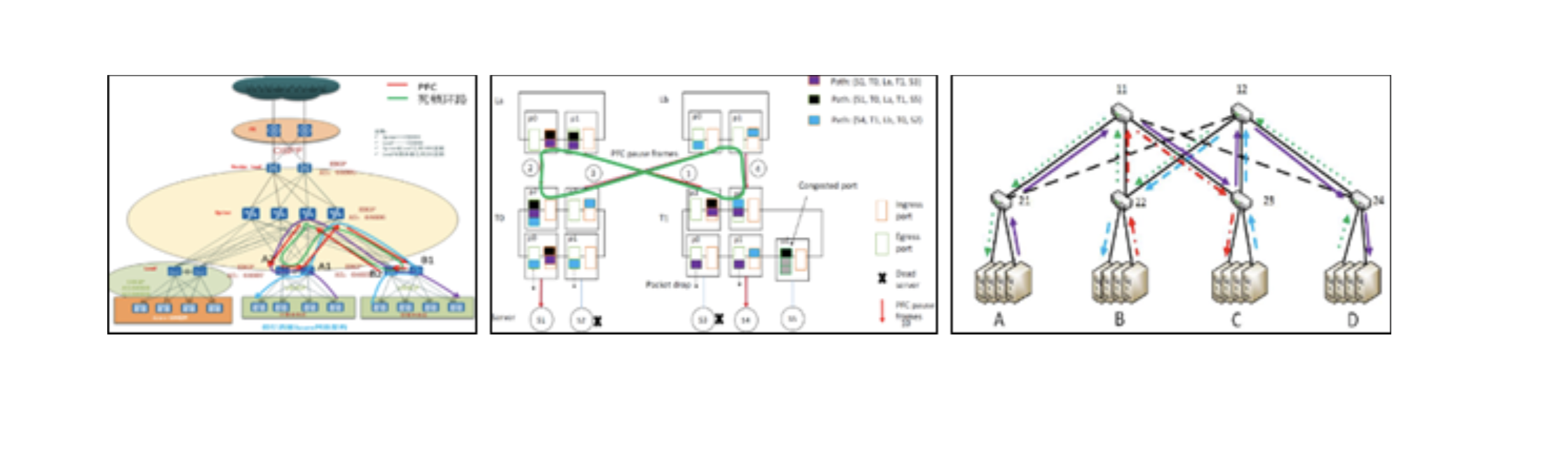
- RDMA应用程序挑战:AI /高性能计算,分布式存储和组合。RDMA应用程序对网络性能敏感。
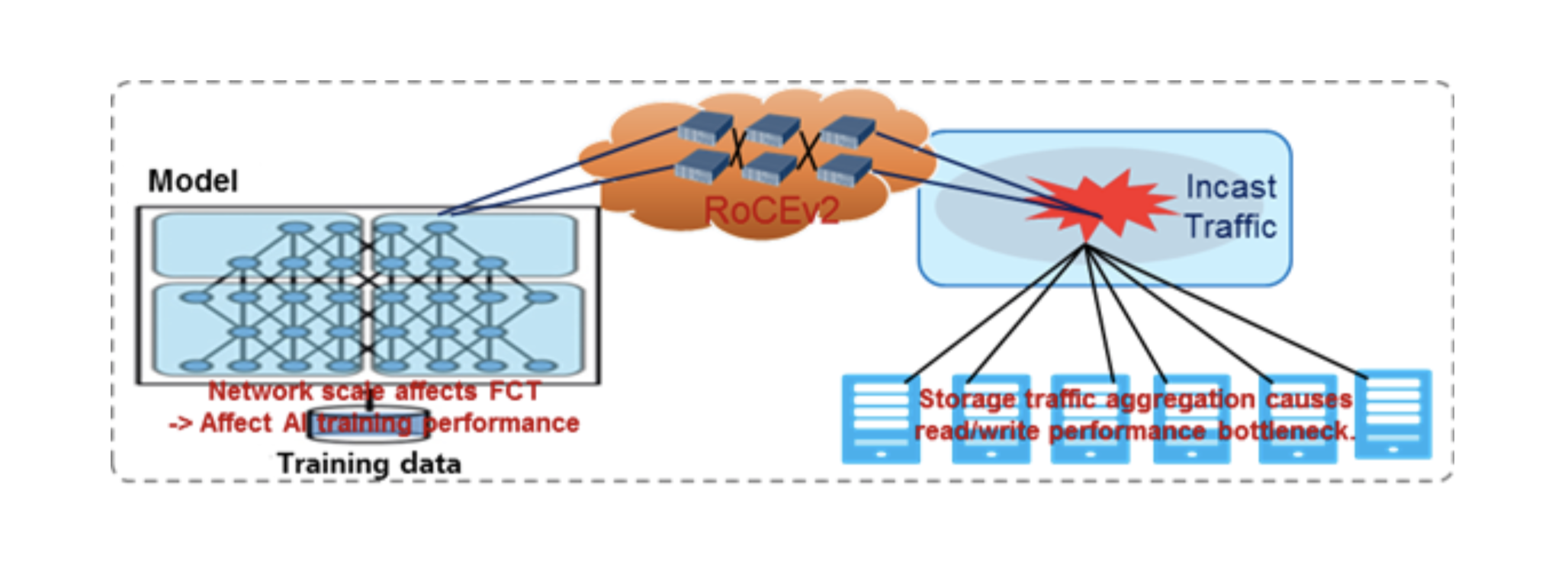
概要
最终,其他机器学习算法可以帮助我们解决“无响应”以太网网络环境中的经典问题。因此,我们与透明,便捷的端到端网络服务生态系统相比,迈出了一步,与一系列不同的技术和产品形成了鲜明的对比。
***
华为解决方案继续出现在我们的在线图书馆中。包括本文中涉及的主题(例如,在针对“智能”数据中心的各种方案构建全尺寸AI解决方案之前)。您可以在此处找到未来几周的在线讲座列表。