这项研究的目的是什么?我想知道:
- Python在哪些应用程序中使用
- 需要什么知识:数据库,库,框架
- 每个方向需要多少专家
- 提供什么薪水

加载数据中
使用API:dev.hh.ru 从站点hh.ru下载的作业。应“ Python”的要求,1994年(莫斯科地区)的职位空缺被上传,分为培训和测试套件,分别为80%和20%。训练集的大小为1595,测试集的大小为399。该测试集仅用于“最高/最高级”技能和“工作分类”部分。
迹象
根据上传的职位空缺的文本,形成了两组最常见的n-gram单词:
- 西里尔文和拉丁文2克
- 1克拉丁文
在IT空缺中,关键技能和技术通常是用英语编写的,因此第二组仅包括拉丁语单词。
选择n-gram后,第一组包含81个2-gram,第二组包含98个1-gram:
| 没有。 | ñ | 克 | 重量 | 空缺 |
| 1个 | 2 | 在python中 | 八 | 258 |
| 2 | 2 | 光盘 | 八 | 230 |
| 3 | 2 | 对原理的理解 | 八 | 221 |
| 4 | 2 | sql知识 | 八 | 178 |
| 五 | 2 | 发展和 | 九 | 174 |
| ... | ... | ... | ... | ... |
| 82 | 1个 | sql | 五 | 490 |
| 83 | 1个 | linux | 6 | 462 |
| 84 | 1个 | PostgreSQL | 五 | 362 |
| 85 | 1个 | 码头工人 | 7 | 358 |
| 86 | 1个 | 爪哇 | 九 | 297 |
| ... | ... | ... | ... | ... |
已决定按照以下标准按优先顺序将空缺分组:
| 优先权 | 标准 | 重量 |
| 1个 | 领域(应用方向),职位,
n-gram经验: “机器学习”,“ linux管理”,“优秀知识” |
7-9 |
| 2 | 工具,技术,软件。
n-gram: “ sql”,“ linux os”,“ pytest” |
4-6 |
| 3 | 其他
n-gram技能: “技术教育”,“英语”,“有趣的任务” |
1-3 |
确定n-gram属于哪一组标准以及为其分配多少权重是在直观的水平上进行的。以下是几个示例:
- 乍一看,“ Docker”可以归为第二组条件,权重为4到6。但是在空缺中提及“ Docker”很可能意味着该空缺是“ DevOps工程师”的职位。因此,“ Docker”属于第一类,并且权重为7。
- «Java» , .. «Java» Java- « Python». «-». , , , «Java» 9.
n- — .
为了进行计算,将每个空位转换为尺寸为179(选定特征的数量)的矢量,该矢量的整数为0到9,其中0表示空位中不存在第i个n元语法,而1到9的数字表示不存在第i个n -克及其重量。此外,在本文中,点被理解为由这种向量表示的空位。
示例:
假设一个n-gram列表仅包含三个值:
没有。 ñ 克 重量 空缺 1个 2 在python中 八 258 2 2 对原理的理解 八 221 3 1个 sql 五 490
然后是文本的空缺。
要求:
- 3年以上python开发经验。
- 良好的知识SQL
向量是[8,0,5]。
指标
要使用数据,您需要对此有一个了解。就我们而言,我想看看是否有点的聚类,我们将其视为聚类。为此,我使用了t-SNE算法将所有矢量转换为2D空间。
该方法的本质是减小数据的维数,同时尽可能保持集合点之间距离的比例。用公式很难理解t-SNE是如何工作的。但是我喜欢一个在Internet上某个地方找到的示例:假设我们在三维空间中有球。我们通过不可见的弹簧将每个球与所有其他球连接,该弹簧不会以任何方式相交并且在穿越时不会相互干扰。弹簧沿两个方向作用,即它们既抵抗球彼此之间的距离又阻止其相互靠近。系统处于稳定状态,球是固定的。如果我们取一个球,然后将其拉回,然后释放,由于弹簧的作用力,它将返回到其原始状态。接下来,我们拿两个大盘子,把球挤成薄薄的一层,同时不干扰球在两个板之间的平面中移动。当所有弹簧的力达到平衡时,弹簧的力开始作用,球运动并最终停止。弹簧将起作用,以使彼此靠近的球保持相对闭合和平坦。同样,如果球被取下,则它们将彼此取下。在弹簧和板的帮助下,我们将三维空间转换为二维空间,以某种形式保留了点之间的距离!同样,如果球被取下,则它们将彼此取下。在弹簧和板的帮助下,我们将三维空间转换为二维空间,以某种形式保留了点之间的距离!同样,如果球被取下,则它们将彼此取下。在弹簧和板的帮助下,我们将三维空间转换为二维空间,以某种形式保留了点之间的距离!
我仅使用t-SNE算法来可视化一组点。他帮助选择了一个度量标准,并为要素选择了权重。
如果我们使用日常生活中使用的欧几里德度量标准,那么空缺的位置将如下所示:

从图中可以看出,大多数点都集中在中心,侧面有小分支。使用这种方法,使用点之间距离的聚类算法不会产生任何好处。
有许多指标(确定两个点之间的距离的方式)可以很好地适用于您正在探索的数据。考虑到n克的权重,我选择了Jaccard距离作为度量。 Jaccard的措施很容易理解,但是对于解决所考虑的问题非常有效。
:
1 n-: « python», «sql», «docker»
2 n-: « python», «sql», «php»
:
« python» — 8
«sql» — 5
«docker» — 7
«php» — 9
(n- 1- 2- ): « python», «sql» = 8 + 5 = 13
( n- 1- 2- ): « python», «sql», «docker», «php» = 8 + 5 + 7 + 9 = 29
=1 — ( / ) = 1 — (13 / 29) = 0.55
计算所有对点之间的距离矩阵,矩阵的大小为1595 x 1595.唯一对之间的总距离为1,271,215。平均距离为0.96,在619659之间的距离为1(即完全没有相似性)。下表显示了总体而言,作业之间几乎没有相似之处:
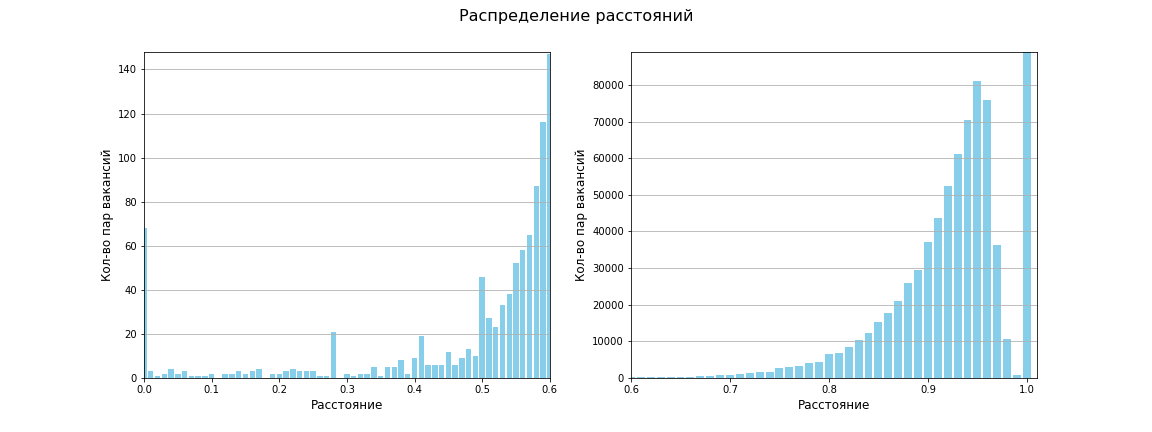
使用Jaccard指标,我们的空间现在看起来像这样:

出现了四个不同的密度区域,以及两个小的低密度簇。至少那是我的眼睛!
聚类
选择高斯混合模型(GMM)作为聚类算法。该算法接收向量形式的数据作为输入,n_components参数是必须将集合拆分为的簇数。您可以在此处查看该算法的工作原理(英语)。我使用了scikit-learn库中的现成GMM实现:sklearn.mixture.GaussianMixture。
请注意,GMM不使用度量标准,而是仅按一组要素及其权重来分隔数据。在本文中,Jaccard距离用于可视化数据,计算聚类的紧密度(对于紧密度,我采用了聚类点之间的平均距离),并确定集群的中心点(典型的空位) -到集群其他点的平均距离最小的点。许多聚类算法精确地使用了点之间的距离。 “其他方法”部分将讨论基于度量的其他类型的聚类,并给出良好的结果。
在上一节中,通过肉眼确定将最有可能出现六个群集。这就是n_components = 6时聚类结果的外观:

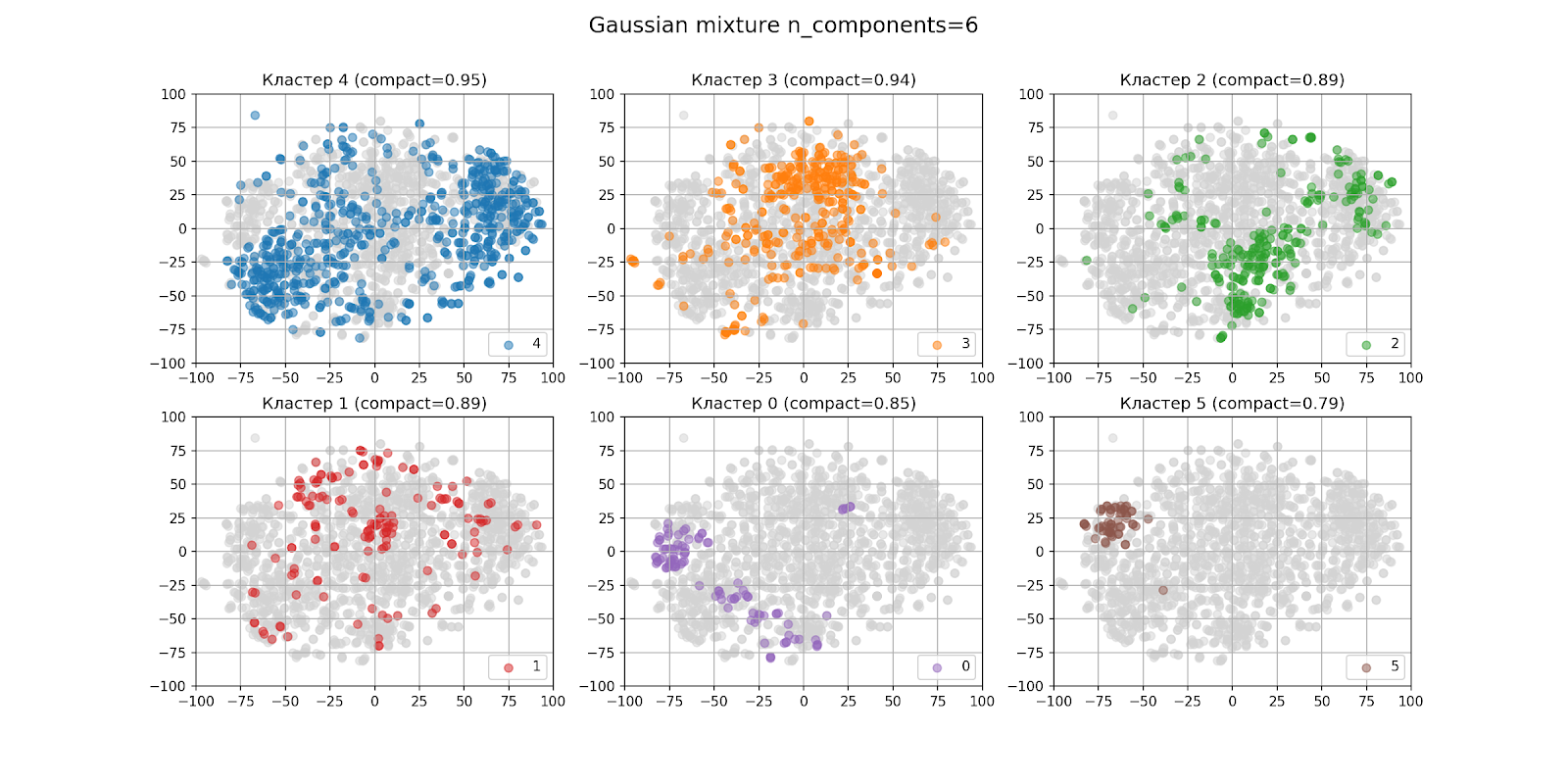
在单独输出群集的图中,群集按从左到右,从上到下的点数的降序排列:群集4最大,群集5最小。每个群集的紧凑性在方括号中指出。
从外观上看,即使考虑到t-SNE算法不是完美的,聚类也不是很好。分析聚类时,结果也不令人鼓舞。
为了找到n_components集群的最佳数量,我们将使用AIC和BIC标准,您可以在此处阅读。这些标准的计算内置在sklearn.mixture.GaussianMixture方法中。这是标准图的样子:

当n_components = 12时,BIC准则具有最低(最佳)值,AIC准则也具有接近最小值(n_components = 23时的最小值)的值。让我们将空缺分为12个类:


现在,群集在外观和数值上都更加紧凑。在手动分析过程中,空缺被分为特征组以了解一个人。该图显示了群集的名称。编号为11和4的群集标记为<垃圾2>:
- 在群集11中,所有要素的总权重大致相同。
- 集群4专用于Java。但是,集群中Java Developer的职位很少,通常需要Java知识,因为“这将是一个额外的优势”。
集群
除去编号为11和4的两个无信息的群集后,结果为10个群集:
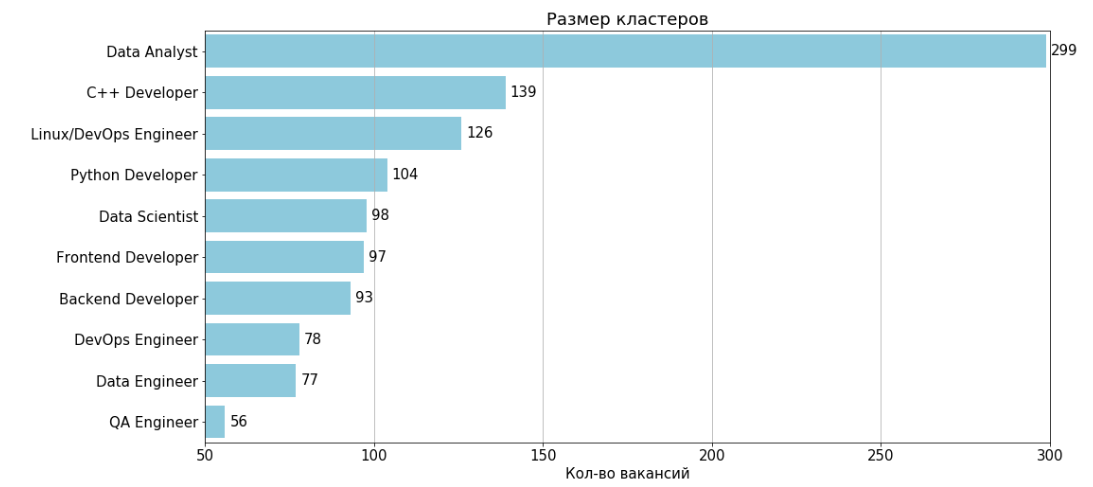
对于每个群集,都有一张在群集空缺中最常见的功能和2字形表。
图例:
S-发现特征的空位百分比乘以特征的权重
% -发现特征/ 2-克的空位百分比
典型簇空位-空位,与簇中其他点的平均距离最小
数据分析师
职位数量:299名
典型职位:35,805,914
| 没有。 | 体重签名 | 小号 | 标志 | % | 2克 | % |
| 1个 | 擅长 | 3.13 | sql | 64.55 | sql知识 | 18.39 |
| 2 | [R | 2.59 | 擅长 | 34.78 | 在发展中 | 14.05 |
| 3 | sql | 2.44 | [R | 28.76 | Python R | 14.05 |
| 4 | sql知识 | 1.47 | 双 | 19.40 | 大 | 13.38 |
| 五 | 数据分析 | 1.17 | 画面 | 15.38 | 发展和 | 13.38 |
| 6 | 画面 | 1.08 | 谷歌 | 14.38 | 数据分析 | 13.04 |
| 7 | 大 | 1.07 | vba | 13.04 | python的知识 | 12.71 |
| 八 | 发展和 | 1.07 | 科学 | 9.70 | 分析仓库 | 11.71 |
| 九 | vba | 1.04 | dwh | 6.35 | 开发经验 | 11.71 |
| 十 | python的知识 | 1.02 | 甲骨文 | 6.35 | 资料库 | 11.37 |
C ++开发人员
职位数量:139个
典型职位:39,955,360
| 没有。 | 体重签名 | 小号 | 标志 | % | 2克 | % |
| 1个 | ++ | 9.00 | ++ | 100.00 | 开发经验 | 44.60 |
| 2 | 爪哇 | 3.30 | linux | 44.60 | C ++ | 27.34 |
| 3 | linux | 2.55 | 爪哇 | 36.69 | C ++ Python | 17.99 |
| 4 | C # | 1.88 | sql | 23.02 | 在C ++中 | 16.55 |
| 五 | 走 | 1.75 | C # | 20.86 | 发展 | 15.83 |
| 6 | 发展 | 1.27 | 走 | 19.42 | 数据结构 | 15.11 |
| 7 | 非常精通 | 1.15 | Unix | 12.23 | 写作经验 | 14.39 |
| 八 | 数据结构 | 1.06 | 张量流 | 11.51 | 编程 | 13.67 |
| 九 | 张量流 | 1.04 | 重击 | 10.07 | 在发展中 | 13.67 |
| 十 | 编程经验 | 0.98 | PostgreSQL | 9.35 | 编程语言 | 12.95 |
Linux / DevOps工程师
就业人数:126名
典型职位:39,533,926
| 没有。 | 体重签名 | 小号 | 标志 | % | 2克 | % |
| 1个 | Ansible | 5.33 | linux | 84.92 | 光盘 | 58.73 |
| 2 | 码头工人 | 4.78 | Ansible | 76.19 | 行政经验 | 42.06 |
| 3 | 重击 | 4.78 | 码头工人 | 74.60 | bash python | 33.33 |
| 4 | 光盘 | 4.70 | 重击 | 68.25 | TCP IP | 39.37 |
| 五 | linux | 4.43 | 普罗米修斯 | 58.73 | 定制体验 | 28.57 |
| 6 | 普罗米修斯 | 4.11 | zabbix | 54.76 | 监控和 | 26.98 |
| 7 | Nginx的 | 3.67 | Nginx的 | 52.38 | 普罗米修斯 | 23.81 |
| 八 | 行政经验 | 3.37 | 格拉那 | 52.38 | 监控系统 | 22.22 |
| 九 | zabbix | 3.29 | PostgreSQL | 51.59 | 与码头工人 | 16.67 |
| 十 | 麋鹿 | 3.22 | Kubernetes | 51.59 | 配置管理 | 16.67 |
Python开发人员
职位空缺:104
典型职位:39,705,484
| 没有。 | 体重签名 | 小号 | 标志 | % | 2克 | % |
| 1个 | 在python中 | 6.00 | 码头工人 | 65.38 | 在python中 | 75.00 |
| 2 | 詹戈 | 5.62 | 詹戈 | 62.50 | 发展 | 51.92 |
| 3 | 烧瓶 | 4.59 | PostgreSQL | 58.65 | 开发经验 | 43.27 |
| 4 | 码头工人 | 4.24 | 烧瓶 | 50.96 | Django烧瓶 | 04.24 |
| 五 | 发展 | 4.15 | Redis | 38.46 | 休息api | 23.08 |
| 6 | PostgreSQL | 2.93 | linux | 35.58 | 来自的python | 21.15 |
| 7 | aiohttp | 1.99 | Rabbitmq | 33.65 | 资料库 | 18.27 |
| 八 | Redis | 1.92 | sql | 30.77 | 写作经验 | 18.27 |
| 九 | linux | 1.73 | mongodb | 25.00 | 与码头工人 | 17.31 |
| 十 | Rabbitmq | 1.68 | aiohttp | 22.12 | 与PostgreSQL | 16.35 |
数据科学家
职位数量:98个
典型职位:38071218
| 没有。 | 体重签名 | 小号 | 标志 | % | 2克 | % |
| 1个 | 大熊猫 | 7.35 | 大熊猫 | 81.63 | 机器学习 | 63.27 |
| 2 | 麻木 | 6.04 | 麻木 | 75.51 | 熊猫麻木 | 43.88 |
| 3 | 机器学习 | 5.69 | sql | 62.24 | 数据分析 | 29.59 |
| 4 | 火炬 | 3.77 | 火炬 | 41.84 | 数据科学 | 26.53 |
| 五 | 毫升 | 3.49 | 毫升 | 38.78 | python的知识 | 25.51 |
| 6 | 张量流 | 3.31 | 张量流 | 36.73 | 麻木的 | 24.49 |
| 7 | 数据分析 | 2.66 | 火花 | 32.65 | python熊猫 | 23.47 |
| 八 | scikitlearn | 2.57 | scikitlearn | 28.57 | 在python中 | 21.43 |
| 九 | 数据科学 | 2.39 | 码头工人 | 27.55 | 数理统计 | 20.41 |
| 十 | 火花 | 2.29 | Hadoop | 27.55 | 机器算法 | 20.41 |
前端开发人员
就业人数:97名
典型职位:39,681,044
| 没有。 | 体重签名 | 小号 | 标志 | % | 2克 | % |
| 1个 | javascript | 9.00 | javascript | 100 | HTML CSS | 27.84 |
| 2 | 詹戈 | 2.60 | html | 42.27 | 开发经验 | 25.77 |
| 3 | 反应 | 2.32 | PostgreSQL | 38.14 | 在发展中 | 17.53 |
| 4 | 节点js | 2.13 | 码头工人 | 37.11 | javascript知识 | 15.46 |
| 五 | 前端 | 2.13 | 的CSS | 37.11 | 和支持 | 15.46 |
| 6 | 码头工人 | 2.09 | linux | 32.99 | python和 | 14.43 |
| 7 | PostgreSQL | 1.91 | sql | 31.96 | CSS JavaScript | 13.40 |
| 八 | linux | 1.79 | 詹戈 | 28.87 | 资料库 | 12.37 |
| 九 | HTML CSS | 1.67 | 反应 | 25.77 | 在python中 | 12.37 |
| 十 | 的PHP | 1.58 | 节点js | 23.71 | 设计和 | 11.34 |
后端开发人员
就业人数:93名
典型职位:40,226,808
| 没有。 | 体重签名 | 小号 | 标志 | % | 2克 | % |
| 1个 | 詹戈 | 5.90 | 詹戈 | 65.59 | python Django的 | 26.88 |
| 2 | js | 4.74 | js | 52.69 | 开发经验 | 25.81 |
| 3 | 反应 | 2.52 | PostgreSQL | 40.86 | python的知识 | 20.43 |
| 4 | 码头工人 | 2.26 | 码头工人 | 35.48 | 在发展中 | 18.28 |
| 五 | PostgreSQL | 2.04 | 反应 | 27.96 | 光盘 | 17.20 |
| 6 | 对原理的理解 | 1.89 | linux | 27.96 | 自信的知识 | 16.13 |
| 7 | python的知识 | 1.63 | 后端 | 22.58 | 休息api | 15.05 |
| 八 | 后端 | 1.58 | Redis | 22.58 | HTML CSS | 13.98 |
| 九 | 光盘 | 1.38 | sql | 20.43 | 理解能力 | 10.75 |
| 十 | 前端 | 1.35 | MySQL的 | 19.35 | 在一个陌生人 | 10.75 |
DevOps工程师
份数 :78
典型份数:39634258
| 没有。 | 体重签名 | 小号 | 标志 | % | 2克 | % |
| 1个 | op | 8.54 | op | 94.87 | 光盘 | 51.28 |
| 2 | Ansible | 5.38 | Ansible | 76.92 | bash python | 30.77 |
| 3 | 重击 | 4.76 | linux | 74.36 | 行政经验 | 24.36 |
| 4 | 詹金斯 | 4.49 | 重击 | 67.95 | 和支持 | 23.08 |
| 五 | 光盘 | 4.10 | 詹金斯 | 64.10 | 码头工人kubernetes | 20.51 |
| 6 | linux | 3.54 | 码头工人 | 50.00 | 发展和 | 17.95 |
| 7 | 码头工人 | 2.60 | Kubernetes | 41.03 | 写作经验 | 17.95 |
| 八 | 爪哇 | 2.08 | sql | 29.49 | 和定制 | 17.95 |
| 九 | 行政经验 | 1.95 | 甲骨文 | 25.64 | 发展和 | 16.67 |
| 十 | 和支持 | 1.85 | 开班 | 24.36 | 脚本编写 | 14.10 |
数据工程师
职位数量:77个
典型职位:40,008,757
| 没有。 | 体重签名 | 小号 | 标志 | % | 2克 | % |
| 1个 | 火花 | 6.00 | Hadoop | 89.61 | 数据处理 | 38.96 |
| 2 | Hadoop | 5.38 | 火花 | 85.71 | 大数据 | 37.66 |
| 3 | 爪哇 | 4.68 | sql | 68.83 | 开发经验 | 23.38 |
| 4 | 蜂巢 | 4.27 | 蜂巢 | 61.04 | sql知识 | 22.08 |
| 五 | 斯卡拉 | 3.64 | 爪哇 | 51.95 | 发展和 | 19.48 |
| 6 | 大数据 | 3.39 | 斯卡拉 | 51.95 | Hadoop Spark | 19.48 |
| 7 | 等 | 3.36 | 等 | 48.05 | Java Scala | 19.48 |
| 八 | sql | 2.79 | 空气流动 | 44.16 | 数据质量 | 18.18 |
| 九 | 数据处理 | 2.73 | 卡夫卡 | 42.86 | 和处理 | 18.18 |
| 十 | 卡夫卡 | 2.57 | 甲骨文 | 35.06 | Hadoop蜂巢 | 18.18 |
质量检查工程师
份数 :56
典型职位:39630489
| 没有。 | 体重签名 | 小号 | 标志 | % | 2克 | % |
| 1个 | 测试自动化 | 5.46 | sql | 46.43 | 测试自动化 | 60.71 |
| 2 | 测试经验 | 4.29 | a | 42.86 | 测试经验 | 53.57 |
| 3 | a | 3.86 | linux | 35.71 | 在python中 | 41.07 |
| 4 | 在python中 | 3.29 | 硒 | 32.14 | 自动化经验 | 35.71 |
| 五 | 发展和 | 2.57 | 网路 | 32.14 | 发展和 | 32.14 |
| 6 | sql | 2.05 | 码头工人 | 30.36 | 测试经验 | 30.36 |
| 7 | linux | 2.04 | 詹金斯 | 26.79 | 写作经验 | 28.57 |
| 八 | 硒 | 1.93 | 后端 | 26.79 | 测试 | 23.21 |
| 九 | 网路 | 1.93 | 重击 | 21.43 | 自动化测试 | 21.43 |
| 十 | 后端 | 1.88 | UI | 19.64 | 光盘 | 21.43 |
薪水
集群中只有1,167个职位中的261个(22%)职位空缺显示薪水。
在计算工资时:
- 如果指定范围“从...到...”,则使用平均值
- 如果仅指示“从...”或仅“至...”,则采用此值
- 税后薪金使用的(或给定的)计算(净值)
在图表上:
- 集群按工资中位数的降序排列
- 方框中的竖线-中位数
- 方块-范围[Q1,Q3],其中Q1(25%)和Q3(75%)是百分位。那些。50%的薪水掉进了盒子里
- “小胡子”的薪水范围为[Q1-1.5 * IQR,Q3 + 1.5 * IQR],其中IQR = Q3-Q1-四分位数范围
- 单个点-未落入胡须的异常。(图中未包含异常)

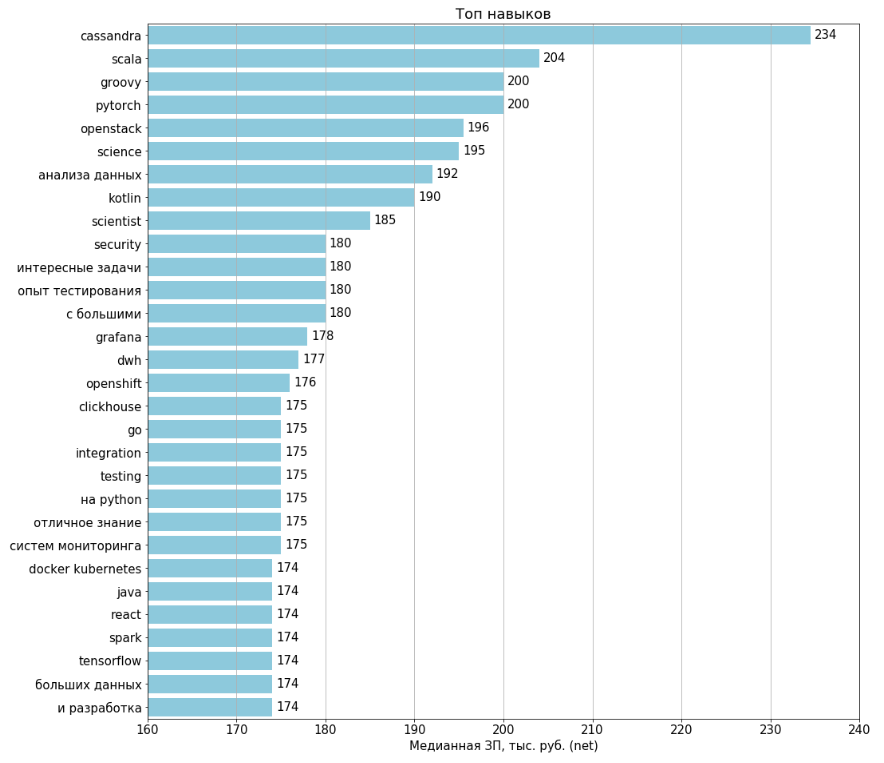
顶级/反顶级技能
该图表是针对1994年所有空缺职位构建的。薪水以443(22%)个职位空缺表示。为了计算每个功能,选择存在该功能的职位空缺,并根据其空缺计算工资。

工作分类
无需求助于复杂的数学模型,就可以使聚类变得更加容易:将空缺的顶级名称进行汇总,然后将其分组。接下来,分析每组的前n克和平均薪水。无需突出显示特征并为其分配权重。
对于“ Python”查询,此方法很好(在某种程度上)。但是对于请求“ 1C程序员”,此方法将不起作用,因为对于空缺名称的1C程序员,很少指出1C配置或应用区域。 1C的使用领域很多:会计,薪资计算,税收计算,制造企业的成本计算,仓库会计,预算编制,ERP系统,零售,管理会计等。
就我自己而言,我看到两项分析职位空缺的任务:
- 了解在哪里使用我不了解的编程语言(如本文所述)。
- 筛选新发布的作业。
聚类适合解决第一个问题,也适合解决第二个问题-各种分类器,随机森林,决策树,神经网络。不过,我想评估所选模型对职位分类问题的适用性。
如果您使用sklearn.mixture.GaussianMixture内置的predict()方法,则不会发生任何事情。他将大多数职位空缺归因于大型集群,而前三个集群中的两个没有信息。我使用了另一种方法:
- 我们采用我们要分类的空缺。我们对其进行矢量化处理,并在我们的空间中取得了一点。
- 我们计算了从该点到所有群集的距离。在点和群集之间的距离下,我获得了从该点到群集中所有点的平均距离。
- 距离最小的集群是所选空缺的预测类别。距群集的距离表明了这种预测的可靠性。
- 为了提高模型的准确性,我选择0.87作为阈值距离,即 如果到最近群集的距离大于0.87,则该模型不会对空位进行分类。
为了评估模型,从测试集中随机选择了30个空缺。在“结论”列中:
N / a:模型未分类作业(距离> 0.87)
+:正确分类
-:错误分类
| 职位空缺 | 最近的集群 | 距离 | 判决 |
| 37637989 | Linux / DevOps工程师 | 0.9464 | 不适用 |
| 37833719 | C ++开发人员 | 0.8772 | 不适用 |
| 38324558 | 数据工程师 | 0.8056 | + |
| 38517047 | C ++开发人员 | 0.8652 | + |
| 39053305 | 垃圾 | 0.9914 | 不适用 |
| 39210270 | 数据工程师 | 0.8530 | + |
| 39349530 | 前端开发人员 | 0.8593 | + |
| 39402677 | 数据工程师 | 0.8396 | + |
| 39415267 | C ++开发人员 | 0.8701 | 不适用 |
| 39734664 | 数据工程师 | 0.8492 | + |
| 39770444 | 后端开发人员 | 0.8960 | 不适用 |
| 39770752 | 数据科学家 | 0.7826 | + |
| 39795880 | 数据分析师 | 0.9202 | 不适用 |
| 39947735 | Python开发人员 | 0.8657 | + |
| 39954279 | Linux / DevOps工程师 | 0.8398 | -- |
| 40008770 | DevOps工程师 | 0.8634 | -- |
| 40015219 | C ++开发人员 | 0.8405 | + |
| 40031023 | Python开发人员 | 0.7794 | + |
| 40072052 | 数据分析师 | 0.9302 | 不适用 |
| 40112637 | Linux / DevOps工程师 | 0.8285 | + |
| 40164815 | 数据工程师 | 0.8019 | + |
| 40186145 | Python开发人员 | 0.7865 | + |
| 40201231 | 数据科学家 | 0.7589 | + |
| 40211477 | DevOps工程师 | 0.8680 | + |
| 40224552 | 数据科学家 | 0.9473 | 不适用 |
| 40230011 | Linux / DevOps工程师 | 0.9298 | 不适用 |
| 40241704 | 垃圾桶2 | 0.9093 | 不适用 |
| 40245997 | 数据分析师 | 0.9800 | 不适用 |
| 40246898 | 数据科学家 | 0.9584 | 不适用 |
| 40267920 | 前端开发人员 | 0.8664 | + |
总计:12个职位没有结果,2个职位-错误分类,16个职位-正确分类。模型完整性-60%,模型准确性-89%。
弱边
第一个问题-让我们考虑两个空缺:
空缺1-“ Lead C ++程序员”
“要求:
- 超过5年的C ++开发经验。
- 对Python的了解将是额外的优势。“
职位空缺2-“ Python主程序员”从模型的角度来看,这些空缺是相同的。我试图通过特征在文本中出现的顺序来调整特征的权重。这并没有带来任何好处。
“要求:
- 5年以上Python开发经验。
- 对C ++的了解将是额外的优势,
第二个问题是,就像许多聚类算法一样,GMM对集合中的所有点进行聚类。非信息集群本身不是问题。但是信息丰富的集群也包含离群值。但是,这可以通过清除群集来轻松解决,例如,通过删除与其余群集点具有最大平均距离的非典型点。
其他方法
集群比较 页面很好地演示了各种集群算法。GMM是唯一取得良好成绩的产品。
其余算法要么不起作用,要么给出非常适度的结果。
在我实施的方法中,有两种情况取得了良好的效果:
- 在彼此相距较远的某个邻域中选择高密度点。这些点成为群集的中心。然后,在中心的基础上,开始了集群形成的过程-相邻点的连接。
- 聚集聚类是点和聚类的迭代合并。scikit-learn库提供了这种群集,但是效果不佳。在我的实现中,我在每次合并迭代后更改了连接矩阵。当达到某些边界参数时,该过程停止-实际上,如果聚类了1500个元素,则树状图将无助于理解合并过程。
结论
我所做的研究为我提供了本文开头所有问题的答案。在实现各种已知算法的过程中,我获得了有关群集的动手经验。我真的希望这篇文章能激发读者进行分析研究,并以某种方式对这一激动人心的课程有所帮助。