除了需要:Apache Ignite集群
Ignite中的群集是一组服务器和客户端节点,其中服务器节点以环的形式组合为逻辑结构,并且客户端节点连接到相应的服务器节点。客户端节点和服务器节点之间的主要区别在于,前者不存储数据。

从逻辑的角度来看,数据属于分区,根据某些亲和力函数,这些分区分布在节点之间(有关Ignite中的数据分布的更多信息)。主(primary)分区可以具有副本(备份)。
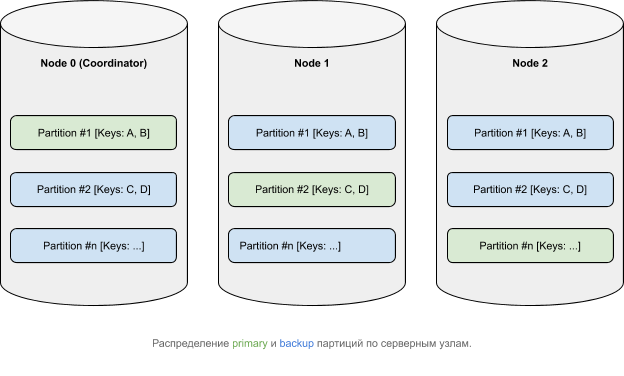
事务如何在Apache Ignite中工作
Apache Ignite中的集群体系结构对事务处理机制提出了一定要求:分布式环境中的数据一致性。这意味着位于不同节点上的数据必须根据ACID原则进行整体更改。有许多协议可用于执行您想要的操作。Apache Ignite使用一个分为两个阶段的两阶段提交算法:
- 准备;
- 承诺;
请注意,根据事务的隔离级别,获取锁的机制以及许多其他参数,阶段中的详细信息可能会更改。
让我们以下面的事务为例看一下两个阶段如何进行:
Transaction tx = client.transactions().txStart(PESSIMISTIC, READ_COMMITTED);
client.cache(DEFAULT_CACHE_NAME).put(1, 1);
tx.commit();
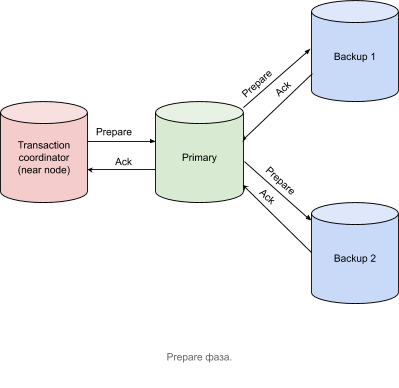
准备阶段
- — (near node Apache Ignite) — prepare- , primary- , .
- primary- Prepare- backup-, , . backup- .
- backup- Acknowledge- primary-, , , , .
Commit
在从包含主分区的所有节点接收到确认消息后,事务协调器节点发送一个Commit消息,如下图所示。
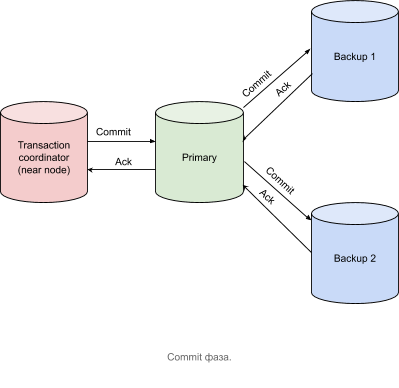
事务协调器收到所有确认消息后,就认为事务已完成。
从理论到实践
考虑事务的逻辑,让我们转向跟踪。
要在Apache Ignite中启用跟踪,请执行以下步骤:
- 让我们启用ignite-opencensus模块,并通过集群配置将OpenCensusTracingSpi设置为tracingSpi:
<bean class="org.apache.ignite.configuration.IgniteConfiguration"> <property name="tracingSpi"> <bean class="org.apache.ignite.spi.tracing.opencensus.OpenCensusTracingSpi"/> </property> </bean>
要么
IgniteConfiguration cfg = new IgniteConfiguration(); cfg.setTracingSpi( new org.apache.ignite.spi.tracing.opencensus.OpenCensusTracingSpi());
- 让我们设置一些非零级别的采样事务:
JVM_OPTS="-DIGNITE_ENABLE_EXPERIMENTAL_COMMAND=true" ./control.sh --tracing-configuration set --scope TX --sampling-rate 1
要么
ignite.tracingConfiguration().set( new TracingConfigurationCoordinates.Builder(Scope.TX).build(), new TracingConfigurationParameters.Builder(). withSamplingRate(SAMPLING_RATE_ALWAYS).build());
:
- API
JVM_OPTS="-DIGNITE_ENABLE_EXPERIMENTAL_COMMAND=true" - sampling-rate , , . , .
- , SPI, . , , .
- API
- PESSIMISTIC, SERIALIZABLE .
Transaction tx = client.transactions().txStart(PESSIMISTIC, SERIALIZABLE); client.cache(DEFAULT_CACHE_NAME).put(1, 1); tx.commit();
让我们转到GridGain控制中心(该工具的详细概述),然后看一下生成的跨度树: 在图中,我们可以看到在事务()的开头创建的事务根跨度。TxStart调用产生了两个条件跨度组:
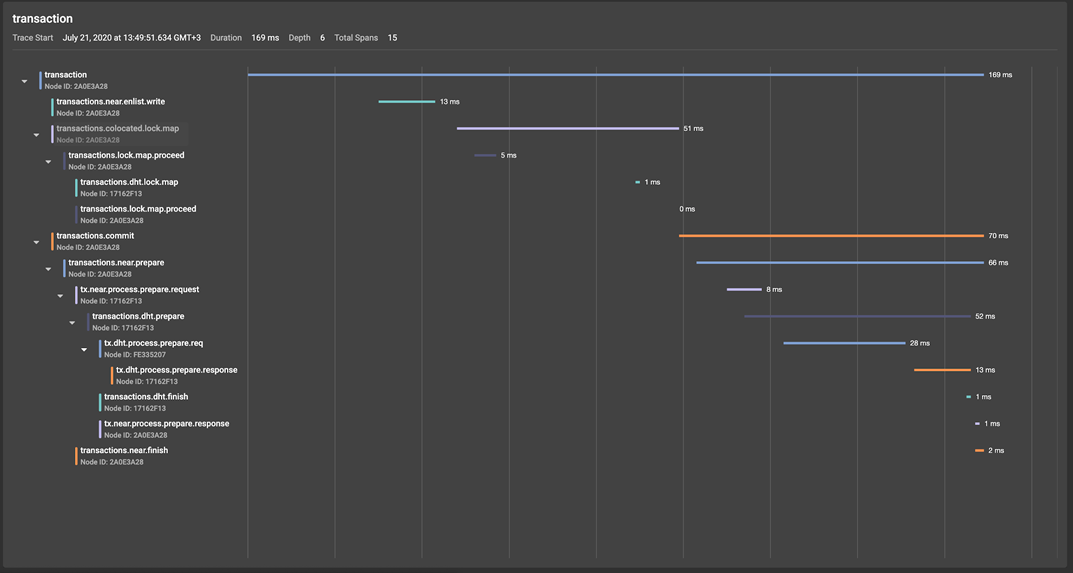
- 由put()操作启动的锁捕获机:
- transactions.near.enlist.write
- transactions.colocated.lock.map
- transactions.commit, tx.commit(), , , — prepare finish Apache Ignite (finish- commit- ).
现在,让我们仔细看看事务的准备阶段,该阶段从事务协调器节点(在Apache Ignite术语中为近节点)开始,生成transaction.near.prepare span。
进入主分区后,prepare-request会触发transactions.dht.prepare跨度的创建,在该跨度中,prepare-request被发送到tx.process.prepare.req备份,在此由tx.dht.process.prepare.response处理并发送返回到主分区,该主分区沿着创建跨度tx.near.process.prepare.response的方式将确认消息发送到事务协调器。本示例中的“完成”阶段与“准备”阶段相似,这使我们无需进行详细分析。
通过单击任何跨度,我们将看到相应的元信息:
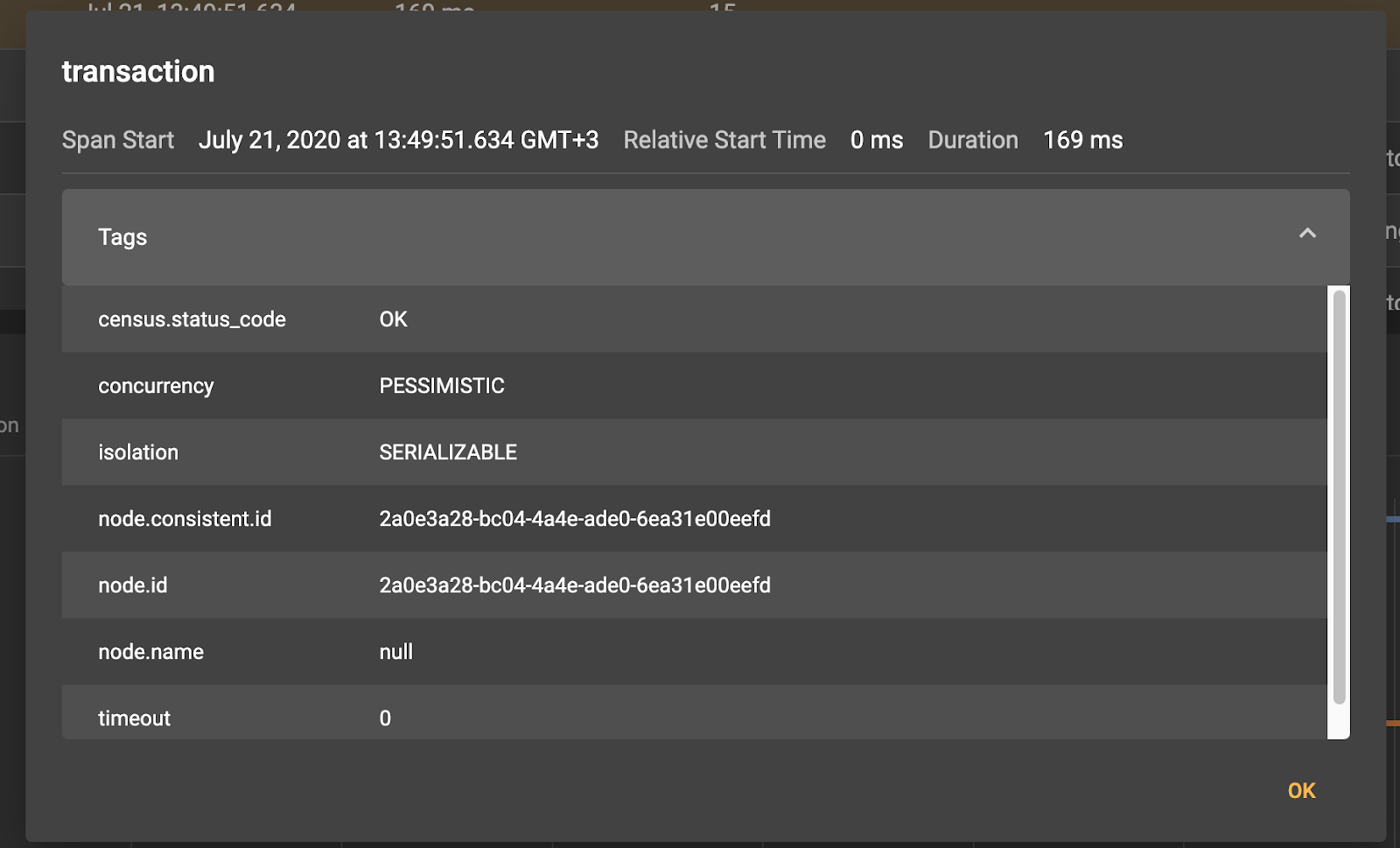
因此,例如,对于根事务跨度,我们看到它是在客户端节点0eefd上创建的。
我们还可以通过启用通信协议的跟踪来增加事务跟踪的粒度。
设置跟踪参数
JVM_OPTS="-DIGNITE_ENABLE_EXPERIMENTAL_COMMAND=true" ./control.sh --tracing-configuration set --scope TX --included-scopes Communication --sampling-rate 1 --included-scopes COMMUNICATION ignite.tracingConfiguration().set(
new TracingConfigurationCoordinates.Builder(Scope.TX).build(),
new TracingConfigurationParameters.Builder().
withIncludedScopes(Collections.singleton(Scope.COMMUNICATION)).
withSamplingRate(SAMPLING_RATE_ALWAYS).build())

现在,我们可以访问有关群集节点之间的网络上消息传输的信息,例如,这将有助于回答是否可能由网络通信的细微差别引起的问题。我们将不讨论细节,我们仅注意socket.write和socket.read跨度的集合分别负责写入套接字和读取此消息或该消息。
异常处理和崩溃恢复
因此,我们看到Apache Ignite中的分布式事务协议的实现接近规范的协议,并允许您根据所选的事务隔离级别来获得适当程度的数据一致性。显然,细节决定了魔鬼,并且上面所分析材料的范围之外还保留了很大的逻辑层。因此,例如,我们没有考虑到参与其中的节点发生故障时交易的操作和恢复机制。我们现在将解决此问题。
上面我们说过,在Apache Ignite中的事务上下文中,可以区分三种类型的节点:
- 事务协调器(节点附近);
- 主节点为对应的密钥(primary node);
- 具有备份密钥分区的节点(备份节点);
以及交易本身的两个阶段:
- 准备;
- 完;
通过简单的计算,我们将需要处理节点崩溃的六个选项-从准备阶段的备份下降到完成阶段的事务协调器崩溃。让我们更详细地考虑这些选项。
准备阶段和完成阶段的备份失败
这种情况不需要任何其他操作。作为与主节点重新平衡的一部分,数据将独立地传输到新的备份节点。

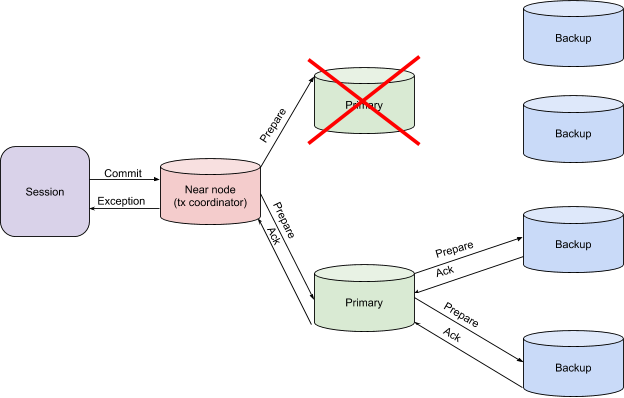
准备阶段主节点下降
如果存在接收不一致数据的风险,则事务协调器将引发异常。这是传递控制权以决定重新启动事务的信号,或者是解决客户端应用程序问题的另一种方法。
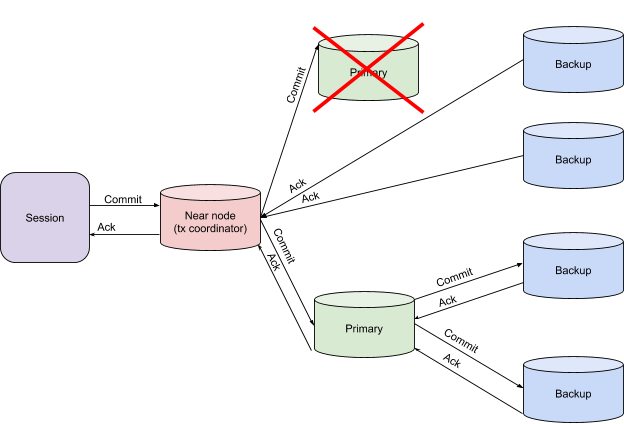
在完成阶段主节点的掉落
在这种情况下,事务协调器等待其他NodeFailureDetection消息,在接收到该消息后,如果数据已写入备份分区,则事务协调器可以决定事务是否成功完成。
交易协调员倒台
最有趣的情况是事务上下文丢失。在这种情况下,主节点和备用节点直接直接交换本地事务上下文,从而还原全局上下文,这使得可以做出决定来验证提交。例如,如果节点之一报告它未收到完成消息,则事务将回滚。

概要
在以上示例中,我们检查了事务流,并使用跟踪进行了说明,该事务详细显示了内部逻辑。如您所见,Apache Ignite中的事务实现接近两阶段提交的经典概念,在事务性能方面进行了一些调整,涉及到锁定机制,故障后的恢复功能以及事务超时逻辑。