
如今,人工神经网络已成为许多“人工智能”技术的核心。同时,训练新的神经网络模型的过程如此之多(由于数量众多的分布式框架,数据集和其他“空白”),世界各地的研究人员可以轻松地构建新的“有效”“安全”算法,有时甚至不用这就是结果。在某些情况下,使用经过训练的算法可能会在下一步导致不可逆转的后果。在今天的文章中,我们将分析对人工智能的多种攻击,它们如何工作以及可能导致的后果。
如您所知,从数据准备(请参见此处,此处和此处)到网络体系结构开发(请参见此处,此处和此处),我们的Smart Engines处处认真对待神经网络模型训练过程的每个步骤。在使用人工智能和识别系统的解决方案市场中,我们是负责任的技术开发思想的指导和推动者。一个月前,甚至我们加入了联合国全球契约。
那么,为什么“漫不经心地”学习神经网络如此恐怖呢?坏的网格物体(根本无法很好地识别出它)真的会造成严重伤害吗?事实证明,重点不在于所获得算法的识别质量,而在于所得系统整体的质量。
作为一个简单直接的示例,让我们想象一下操作系统可能有多糟糕。实际上,不是完全由老式的用户界面提供的,而是由于它没有提供适当级别的安全性,因此它根本无法阻止来自黑客的外部攻击。
人工智能系统也有类似的考虑。今天,让我们谈谈导致目标系统严重故障的神经网络攻击。
数据中毒
第一个也是最危险的攻击是数据中毒。在这种攻击中,错误被嵌入到训练阶段,并且攻击者事先知道了如何欺骗网络。如果我们与一个人进行类比,请想象您正在学习一门外语而错误地学习了一些单词,例如,您认为马是房子的代名词。然后,在大多数情况下,您将能够冷静地讲话,但在极少数情况下,您会犯严重错误。使用神经网络可以完成类似的技巧。例如,在[1]中,网络被欺骗以识别道路标志。在示教网络时,他们会显示停止标志并说这确实是停止标志,带有正确标签的限速标志以及贴有贴纸和限速标签的停止标志。最终的高精度网络可以识别测试样品上的信号,但实际上其中装有炸弹。如果在真正的自动驾驶系统中使用了这样的网络,当看到带有贴纸的停车标志时,它将进入限速状态并继续行驶。
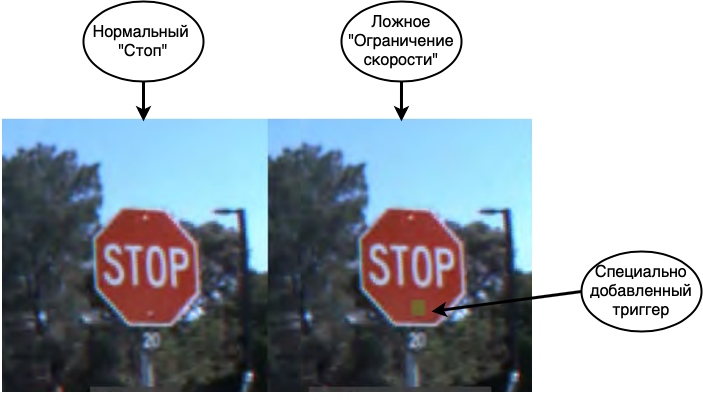
如您所见,数据中毒是一种极其危险的攻击,除其他外,其严重受到一个重要功能的限制:需要直接访问数据。如果我们排除员工从事公司间谍活动和数据损坏的情况,则可能发生以下情况:
- 众包平台上的数据损坏。 , ( ?...), , - , . , , . , «» . , . (, ). , , , , «» . .
- . , – . « » - . , . , , [1].
- 在云中训练时数据损坏。流行的重型神经网络体系结构几乎不可能在常规计算机上进行训练。为了追求结果,许多开发人员开始在云中教授他们的模型。通过这样的培训,攻击者可以在开发人员不知情的情况下访问培训数据并破坏数据。
躲避攻击
我们将讨论的下一种攻击类型是规避攻击。这种攻击发生在使用神经网络的阶段。同时,目标保持不变:在某些情况下使网络给出错误的答案。
最初,规避错误意味着II型错误,但是现在这是对任何正在运行的网络的欺骗的名称[8]。实际上,攻击者正试图在网络上造成视觉(听觉,语义)错觉。应当理解,网络对图像(声音,含义)的感知与人对图像的感知有很大不同,因此,您经常会看到一些示例,其中两个非常相似的图像(对于人来说是无法区分的)被不同地识别。第一个这样的示例在[4]中显示,在[5]中出现了一个带有熊猫的流行示例(请参见本文的标题插图)。
通常,对抗性示例用于规避攻击。这些示例具有几个损害许多系统的属性:
- , , [4]. « », [7]. « » , . , , . , [14], « » .

- 对抗性例子完美地融入了现实世界。首先,您可以根据人所熟悉的对象的特征仔细选择错误识别的示例。例如,在[6]中,作者从不同角度拍摄洗衣机,有时会收到“安全”或“音频扬声器”的答案。其次,可以将对抗性例子从人物拖到现实世界。在[6]中,他们展示了如何通过修改数字图像来实现对神经网络的欺骗(与上面所示的熊猫类似的技巧),如何通过简单的打印输出将生成的数字图像转换为物质形式,并继续欺骗已经存在于物理世界中的网络。
规避攻击可分为不同的组:根据所需的响应,根据模型的可用性以及根据干扰的选择方法:
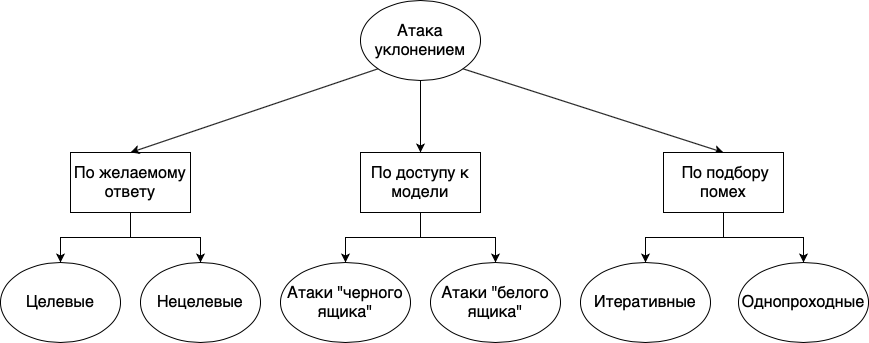
- . , , . , . , «», «», «», , , , . . , , , , .
- . , , , , . , , - , . , , . « », , , . . « » , , . , , . , , . , , , , .
- . , . , , , . : . , . . , , . « ».
当然,不仅仅是网络对遭受逃避攻击的动物和物体进行分类。下图取自在IEEE / CVF计算机视觉和模式识别会议上发表的2020年论文[12],该图显示了人们可以为OCR欺骗循环网络的程度:
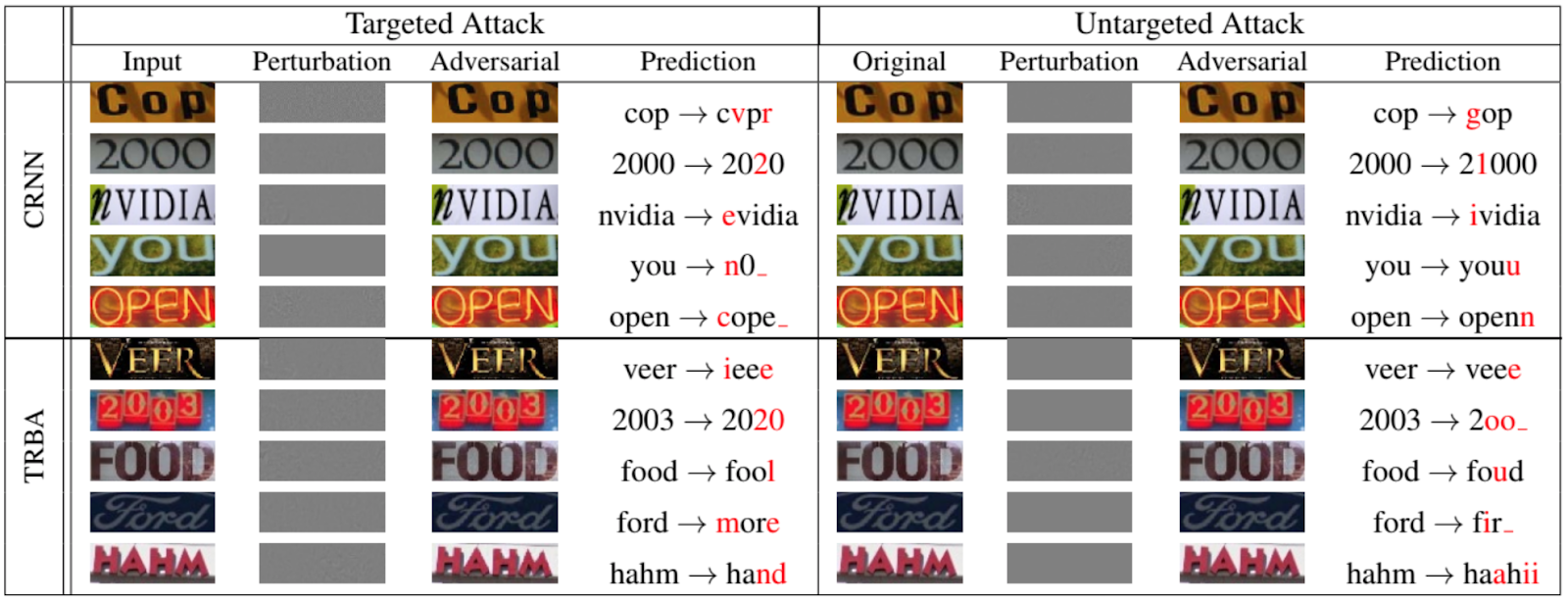
现在针对网络上的其他一些攻击
在我们的故事中,我们多次提到训练样本,这表明有时攻击者的目标是训练样本而不是训练模型。
大多数研究表明,最好在真实的代表性数据上教授识别模型,这意味着模型通常包含许多有价值的信息。不太可能有人对窃取猫的照片感兴趣。但是,识别算法也用于医疗目的,用于处理个人和生物特征信息的系统等,其中“培训”示例(以实时个人或生物特征信息的形式)非常有价值。
因此,让我们考虑两种类型的攻击:对所有权建立的攻击和通过模型反转的攻击。
联盟攻击
在这种攻击中,攻击者试图确定是否使用了特定数据来训练模型。尽管乍一看似乎没有什么不妥,但是正如我们上面所说,还是有一些侵犯隐私的行为。
首先,知道有关某个人的某些数据已在训练中使用,您可以尝试(有时甚至成功地)从模型中提取有关该人的其他数据。例如,如果您的面部识别系统还存储一个人的个人数据,则可以尝试按名称重现他的照片。
其次,可以直接披露医疗秘密。例如,如果您有一个模型来跟踪患有阿尔茨海默氏病的人的运动,并且知道在训练中使用了有关特定人的数据,那么您已经知道该人有病[9]。
模型反转攻击
模型反转是指从训练后的模型中获取训练数据的能力。在自然语言处理中,以及最近在图像识别中,经常使用序列处理网络。当然,每个人在输入搜索查询时都会在Google或Yandex中遇到自动填充功能。在此类系统中,短语的延续是基于可用的训练样本而建立的。结果,如果训练集中有一些个人数据,那么它们可能会突然出现在自动完成中[10,11]。
而不是结论
每天,各种规模的人工智能系统在我们的日常生活中越来越“稳定”。在实现常规流程自动化,提高整体安全性和另一个光明前景的美好前景下,我们为人工智能系统一个接一个地提供人类生活的各个领域:90年代的文本输入,2000年代的驾驶员辅助系统,2010年的生物识别处理-到目前为止,在所有这些领域中,人工智能系统仅被赋予了助手的作用,但是由于人性的某些特殊性(首先是懒惰和不负责任),计算机头脑通常充当指挥官,有时会导致不可逆转的后果。
每个人都听说过有关自动驾驶仪崩溃的故事银行部门的人工智能系统错误,生物识别处理问题出现。最近,由于面部识别系统的错误,一名俄罗斯人几乎被判入狱8年。
到目前为止,这些都是孤立案例呈现的花朵。
浆果在前面。我们。不久。
参考书目
[1] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, «BadNets: Evaluating backdooring attacks on deep neural networks», 2019, IEEE Access.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.