本文是对上一篇文章的扩展:使用Apache NiFi自动化Jira Analytics。现在,我想扩展一下我们对Jira Software进行报告的观点以及使用R进行实现的经验。这里的语言当然不是教条。今天,我们的一切都是概念。 图片是在这里借用的。

让我们想象一个任务跟踪器。作为分析师,我可以从中提取什么数据?还是任何现成的分析平台?该期间的任务数量,日志记录统计信息,项目的基本细目分类,有关员工生产力的一些图片……仅此而已。
但是,所做的一切都会变得肥胖。因此,您可能可以选择更具全局性的内容:团队在做什么以及它朝哪个方向发展。
是的,我们做到了。但是,并非并非没有PM的帮助。
重组任务跟踪器
当然,每个特定的Jira与其他任何显着不同。我们的解决方案可能对您而言不是最有效的,甚至根本不适用。
我请您以我们外包公司为例,仅将此视为组织任务跟踪器的想法。
我们只采取了两步。
首先也是最简单的。他们接受了一个方向上的所有任务,当然应该与史诗有关。史诗是Jira中最大的对象,代表多个问题。它们有助于建立层次结构和结构,还可以跨越多个sprint和版本。
关于第二点的更多信息。如果有,我们将能够看到全局并回答战略性问题工作流将作为一种流程呈现,每个员工都参与其中。为此,在我们的案例中,IT4IT概念是理想的,其运行模型基于四流价值链: 实际上,我们做了什么。利用IT4IT,我们在Jira中添加了一个任务组件。我们有以下内容:

- 服务到投资组合(需求和选择) -“挑选”,搜索,服务选择,技术的阶段。
- 要求部署(计划和设计) -讨论,开发计划,服务开发,服务。
- 请求部署(开发) -服务开发,某种服务。
- 请求部署(Deploy) -部署某些内容。
- 请求部署(测试) -测试服务。
- 要求实现-运营已开发服务,提供服务的阶段。
- 检测到纠正(纠正) -修复,修订内部服务和服务。
- 检测到更正(监控和反馈) -同一件事,仅+与客户端通信。
在此阶段,最困难的事情可能是说服员工相信跟踪器中的多余物品并非一无是处,并且必须正确填写。
R中的数据分析
现在,执行报告应该没有障碍。我将阐述传统知识的相似性。
由于团队在每个星期开始时都会聚集在一起进行规划,因此报告应该是每周一次。对于我们而言,重要的是要查看有关任务的外观和进度,员工的日志记录以及每个员工对整体情况的贡献的统计信息。回答问题:团队在做什么-就史诗和组成部分而言。
知道我们需要得到什么之后,我们就去卸载数据。通过Jira API,我们请求上周更新的所有问题(问题)。我们从中提取密钥,并为每个任务加载日志记录历史记录(worklog)和更改历史记录(changelog)。带有超载的变态对绕过顶点限制是必要的。
接下来,责任R的区域开始,因为对接收到的数据的预处理是报告生成脚本的组成部分。
里面没有什么聪明的,您只需要解析来自api的JSON并仅保留必要的属性(Jira中的项目)。在处理更改日志的唯一时刻,我们只对任务状态更改感兴趣,其余的可以安全地删除。
最后,我们进入了分析。
找出在过去一周中有多少个任务已经打开,正在进行,关闭和推迟。看一下R代码:
#
this_week_opened <- jira_changelog_data %>%
filter(issue_type != "Epic") %>%
filter(as.Date(issue_created) >= start_date) %>%
filter(as.Date(issue_created) <= end_date) %>%
select(key, issue_created) %>% unique() %>% nrow()
#
this_week_processed <- jira_worklog_data %>%
filter(as.Date(started) >= start_date) %>%
filter(as.Date(started) <= end_date) %>%
select(key) %>% unique() %>% nrow()
#
this_week_closed <- jira_changelog_data %>%
filter(issue_type != "Epic") %>%
filter(as.Date(issue_resolutiondate) >= start_date) %>%
filter(as.Date(issue_resolutiondate) <= end_date) %>%
select(key, issue_created) %>% unique() %>% nrow()
# /
this_week_holded <- issue_history %>%
filter(change_date >= start_date) %>%
filter(change_date <= end_date) %>%
filter(toString == "Hold" | toString == "Backlog") %>%
select(key) %>% unique() %>% nrow()这会让您想起伪代码吗?如果我说运算符' %>% '将数据从上一个函数传输到下一个函数。整个链中的最后修改将保存到变量中。想象一下,我们刚刚达到了进入R的门槛!
你爱上他了吗?然后,如果您愿意,我将添加更多信息。
来自维基百科的词:
通常,作为一种编程语言,R非常简单,甚至是原始的。它的最大优势在于可以无限扩展软件包。
基本R交付包括一组基本软件包,截至2019年,总共提供了超过15,316个软件包。
而今天的最后一件事。今年,[R破门进入世界(十大最流行的语言证明)。我为他感到骄傲。
请原谅我的这次撤退。我可以谈论R几个小时。只是他完全笼罩在神话中,我喜欢摧毁它们-一种业余爱好,你知道。
让我们回到报告中。拥有所需的数字后,我们将其可视化。之后,我们将记录员工人数。这就是我们的外观: 我将继续向您展示来自同一真实报告的最终图像。 下图反映了我们的业务范围。它还使您可以通过运营活动评估员工的工作量。 这是按组件划分的所有任务的细分。他回答了我们正在做什么的问题。我用数字补充图片。
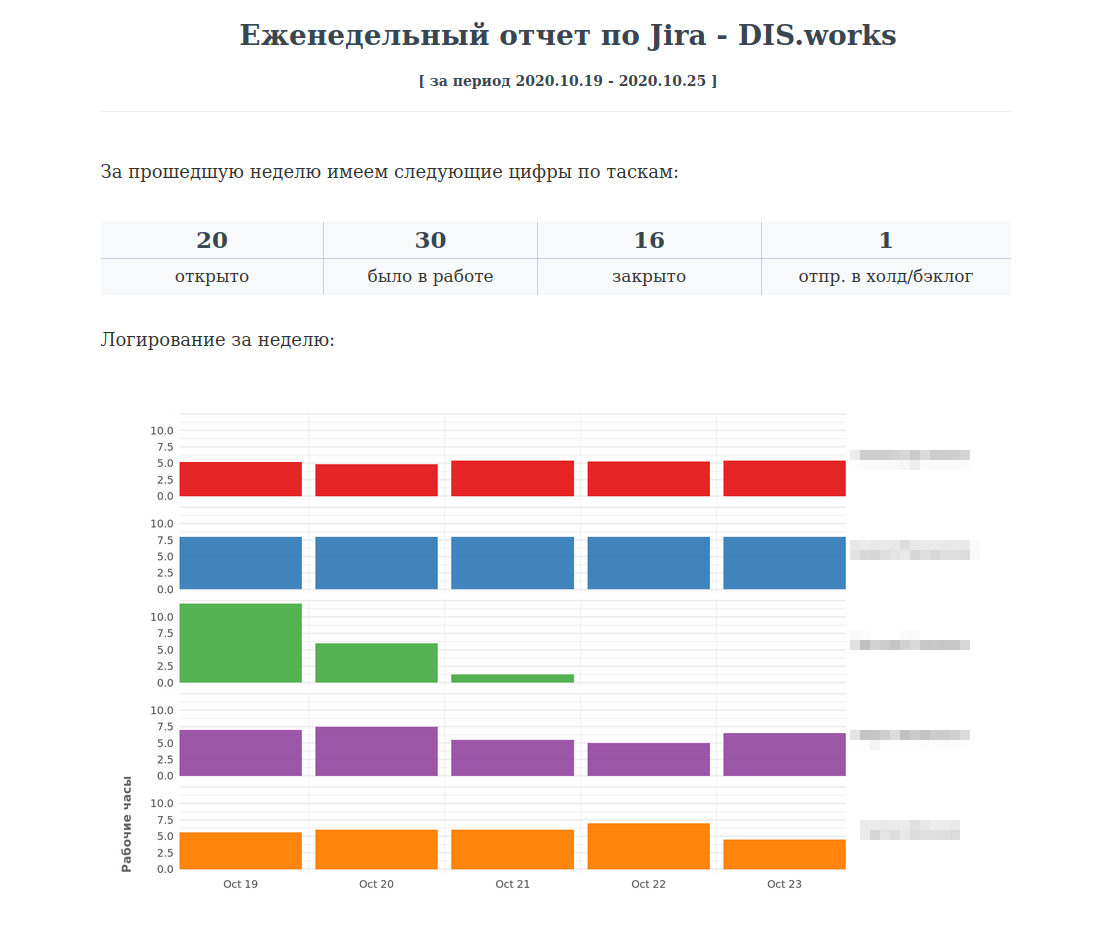


好吧,每位员工对上述全局所做的承诺贡献。
我相信您会立即注意到我们的开发人员在哪里,管理员在哪里。我们正在努力做到这一点。 真实报告还补充了任务执行的摘要。这是对最开始发布的常规统计信息的补充,其中包括任务名称和负责人的姓名。

生成报告
您可以设置自动报告生成,例如,在星期一使用R脚本使用cronR软件包来创建自动报告,这非常简单。
与我们在一起,一切都变得更加复杂和优雅。我们每周使用Apache NiFi从Jira API下载数据,运行报告生成脚本,并通过Email将报告发送给所有员工。这个主题如此广泛,值得单独发表一篇文章。
结论
Jira Software实现的数量以及使用它的公司数量很多。同时,每个老板都需要拥有自己独特的指标库,才能在战术上正确地进行管理。是的,有用于ira分析的eazyBI和其他插件,但结果就像在商店中购买西装而不是定制的定制。
所考虑的报告是根据模板缝制的。据老板说,它提供了单位或团队正在做什么的战略视图。希望本文能帮助您在家中实现类似的功能。
谢谢。