监视Kubernetes内部端点和API可能会出现问题,尤其是如果目标是利用自动化基础架构即服务时。我们在Smarkets尚未达到这个目标,但是幸运的是,我们已经很接近了。我希望我们在这方面的经验可以帮助其他人实施类似的措施。
我们一直梦想着开发人员能够开箱即用地监视任何应用程序或服务。在迁移到Kubernetes之前,该任务是使用Prometheus度量标准或使用statsd完成的,后者将统计信息发送到基础主机,然后将其转换为Prometheus度量标准。随着我们继续利用Kubernetes,我们开始分离集群,我们希望做到这一点,以便开发人员可以通过服务注释将指标直接导出到Prometheus。 metrics,这些指标仅在群集内可用,也就是说,无法在全局范围内收集它们。
这些限制是我们使用Kubernetes之前的配置的瓶颈。最终,他们不得不重新考虑监视服务的体系结构和方式。此旅程将在下面讨论。
起点
对于与Kubernetes相关的指标,我们使用两种提供指标的服务:
-
kube-state-metrics根据来自K8s API服务器的信息为Kubernetes对象生成指标; -
kube-eagle导出豆荚的Prometheus指标:其请求,限制,使用情况。
可能(并且有一段时间我们一直在这样做)暴露具有集群外部指标的服务或打开与API的代理连接,但是这两个选项都不理想,因为它们减慢了工作速度并且没有提供必要的系统独立性和安全性。
通常,将部署监视解决方案,该解决方案由在Kubernetes中运行并从平台本身收集指标的Prometheus服务器中央群集以及从该群集中收集的内部Kubernetes指标组成。选择这种方法的主要原因是,在过渡到Kubernetes的过程中,我们将所有服务收集在同一集群中。添加其他Kubernetes集群后,我们的架构如下所示:
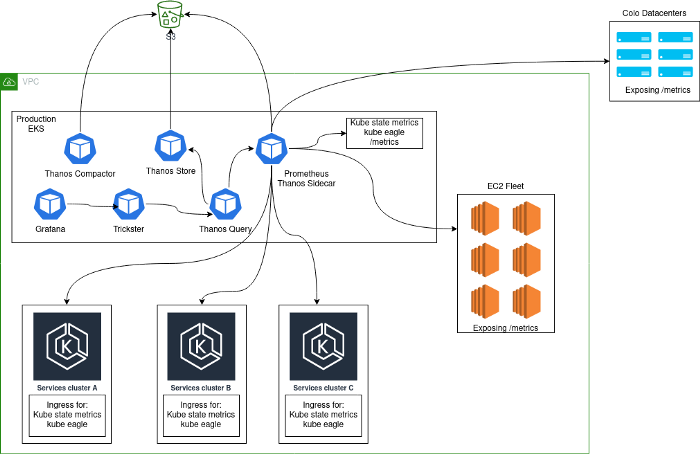
问题
这样的架构不能被称为稳定,高效或有生产力的:毕竟,用户可以从应用程序导出statsd指标,这导致某些指标的基数非常高。如果以下数量级看起来很熟悉,您可能会熟悉类似的问题。
分析2小时的Prometheus区块时:
- 130万个指标;
- 383个标签名称;
- 每个度量标准的最大基数为662,000(大多数问题正是由于这个原因)。
这种高基数主要是由于暴露了包括HTTP路径的statsd计时器。我们知道这并不理想,但是这些指标用于跟踪Canary部署中的关键错误。
在安静的时候,每秒收集大约40,000个度量标准,但是在没有任何问题的情况下,它们的数量可以增长到18万个。
对高基数指标的某些特定查询导致(可能)Prometheus内存不足-当使用它(Prometheus)来警告和评估Canary部署的性能时,这是非常令人沮丧的情况。
另一个问题是,每个Prometheus实例上存储了三个月的数据,因此启动时间(WAL重播)非常长,这通常导致同一请求被路由到第二个Prometheus实例,并且“已经删除了。
为了解决这些问题,我们实施了Thanos和Trickster:
- Thanos允许在Prometheus中存储较少的数据,并减少了由于过度使用内存而导致的事件数量。在容器旁边,Prometheus Thanos运行了一个Sidecar容器,该容器在S3中存储数据块,然后thanos-compact将其压缩。因此,借助Thanos,在Prometheus外部实现了长期数据存储。
- 就Trickster而言,它充当时间序列数据库的反向代理和缓存。它允许我们最多缓存所有请求的99.53%。大多数请求来自工作站/电视上运行的仪表板,具有打开控制面板的用户以及警报。只能显示时间序列增量的代理对于这种工作负载非常有用。
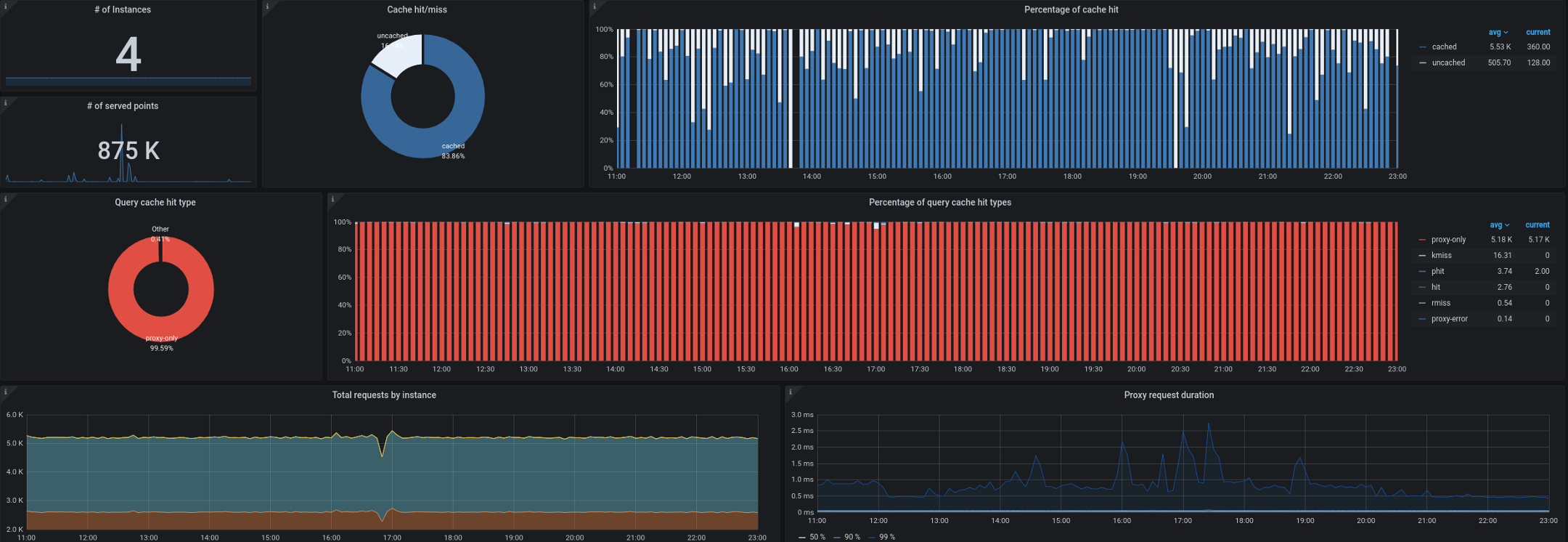
我们还开始遇到从集群外部收集kube-state-metrics的问题。您还记得,我们经常不得不每秒处理多达180,000个指标,即使在单个入口kube-state指标中设置了40,000个指标,集合的速度也会降低。我们有一个10秒钟的目标间隔来收集指标,在高负载期间,此SLA经常被远程收集kube-state-metrics或kube-eagle违反。
选件
在考虑如何改进体系结构时,我们考虑了三种不同的选择:
- Prometheus + Cortex(https://github.com/cortexproject/cortex);
- Prometheus + Thanos接收(https://thanos.io);
- Prometheus + VictoriaMetrics(https://github.com/VictoriaMetrics/VictoriaMetrics)。
有关它们的详细信息和特性比较可在Internet上找到。在我们的特定案例中(以及在对具有高基数的数据进行测试之后),VictoriaMetrics无疑是赢家。
决断
普罗米修斯
为了改进上述架构,我们决定将每个Kubernetes集群隔离为一个单独的实体,并将Prometheus纳入其中。现在,任何新集群都附带了“开箱即用”的监视功能,以及全局仪表板(Grafana)中可用的指标。为此,kube-eagle,kube-state-metrics和Prometheus服务已集成到Kubernetes集群中。然后,Prometheus被配置了外部标签以识别集群,并在VictoriaMetrics中
remote_write指向insert(请参见下文)。
维多利亚度量
VictoriaMetrics时间序列数据库实现了Graphite,Prometheus,OpenTSDB和Influx协议。它不仅支持PromQL,而且还向其中添加了新功能和模板,从而避免了Grafana查询的重构。另外,它的性能令人赞叹。
我们以集群模式部署了VictoriaMetrics,并将其分为三个单独的组件:
1. VictoriaMetrics存储(vmstorage)
该组件负责存储导入的数据
vminsert。我们将自己限制为该组件的三个副本,并组合成一个StatefulSet Kubernetes。
./vmstorage-prod \
-retentionPeriod 3 \
-storageDataPath /data \
-http.shutdownDelay 30s \
-dedup.minScrapeInterval 10s \
-http.maxGracefulShutdownDuration 30s
VictoriaMetrics插入(vminsert)
该组件从使用Prometheus的部署中接收数据并将其转发给
vmstorage。该参数将replicationFactor=2数据复制到三个服务器中的两个。因此,如果其中一个实例vmstorage遇到问题或重新启动,则仍然有一个可用的数据副本。
./vminsert-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-replicationFactor=2
VictoriaMetrics选择(vmselect)
接受来自Grafana(Trickster)的PromQL请求,并从中请求原始数据
vmstorage。目前,search.disableCache由于该架构包含负责缓存的Trickster,因此我们已禁用了cache();因此,它应vmselect始终获取最新的完整数据。
/vmselect-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-dedup.minScrapeInterval=10s \
-search.disableCache \
-search.maxQueryDuration 30s
大图
当前的实现如下所示:
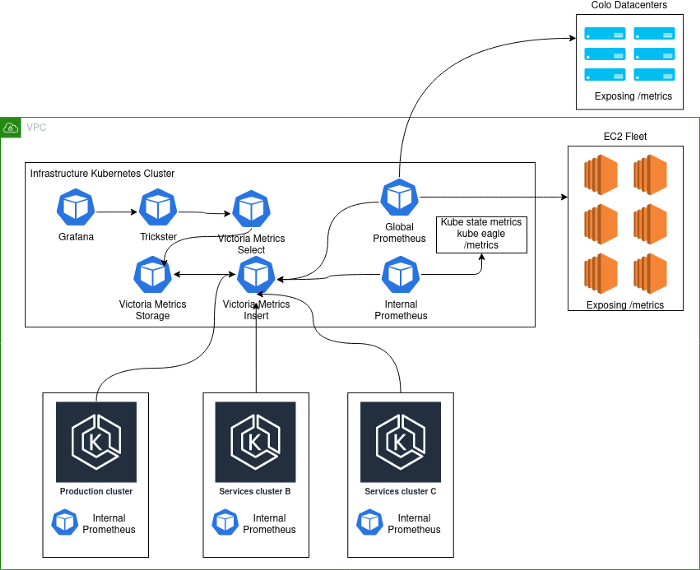
模式说明:
- Production- . , K8s . - , . .
- deployment K8s Prometheus', VictoriaMetrics insert Kubernetes.
- Kubernetes deployment' Prometheus, . , , Kubernetes , . Global Prometheus EC2, colocation- -Kubernetes-.
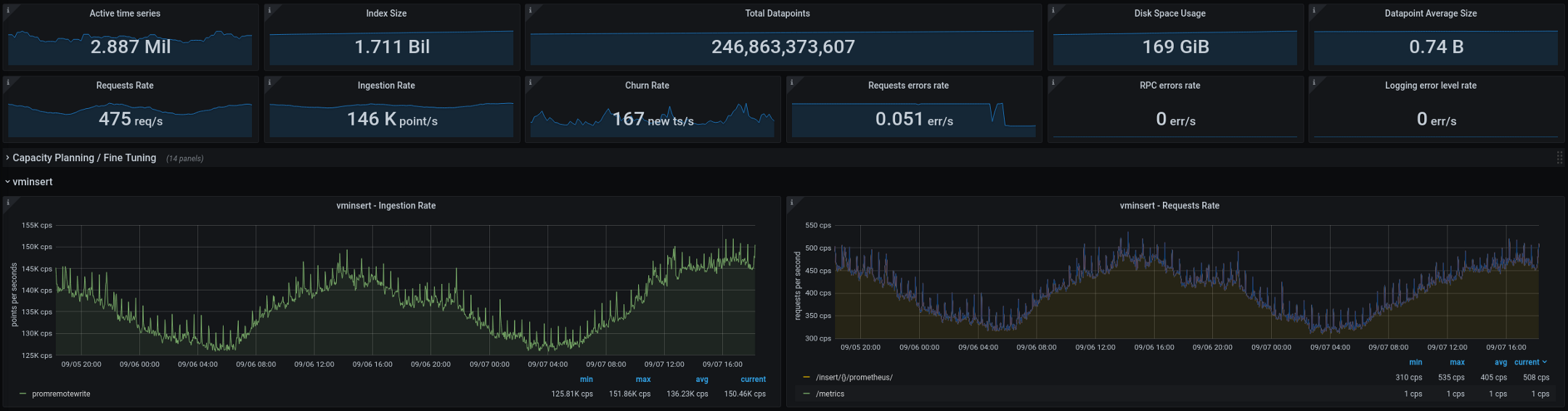
以下是VictoriaMetrics当前正在处理的指标(总计两周,图表显示了两天的间隔): 新架构在投入生产后表现良好。在旧的配置中,我们每两周进行两次或三个基数“爆炸”,而在新的配置中,它们的数目降为零。 这是一个很好的指标,但是我们计划在接下来的几个月中进一步改进一些功能:
- 通过改进statsd集成来减少指标的基数。
- 比较Trickster和VictoriaMetrics中的缓存-您需要评估每个解决方案对效率和性能的影响。有人怀疑Trickster可以在不损失任何东西的情况下被完全抛弃。
- Prometheus stateless- — stateful, . , StatefulSet', ( pod disruption budgets).
-
vmagent— VictoriaMetrics Prometheus- exporter'. , Prometheus , .vmagentPrometheus ( !).
如果您对上述改进有任何建议或想法,请与我们联系。如果您正在改善Kubernetes监控,我们希望本文描述了我们的艰难旅程,对您有所帮助。
译者的PS
另请参阅我们的博客:
- “普罗米修斯的未来和项目生态系统(2020年) ”;
- “监控和Kubernetes ”(审查和视频报告);
- “ Kubernetes中Prometheus运算符的设备和机制。”