软件开发的这些方面之一是代码许可。对于某些开发人员来说,许可似乎是一片漆黑的森林,他们试图不介入,或者不了解一般的区别和许可规则,或者只是肤浅地了解它们,这就是为什么他们会犯下各种违法行为的原因。最常见的此类违反行为是复制(重用)和修改代码,从而侵犯其作者的权利。
对人员的任何帮助都始于研究当前状况-首先,数据收集对于进一步自动化的可能性是必需的;其次,他们的分析将使我们能够找出人们究竟在做错什么。在本文中,我将描述这样的研究:我将向您介绍软件许可证的主要类型(以及一些稀有但值得注意的许可证),我将讨论代码分析和在大量数据中搜索借用,并且会提供有关如何正确处理代码中许可证的建议。并避免常见错误。
代码许可简介
在Internet上,甚至在Habré上,已经有关于许可证的详细描述,因此我们将仅局限于对理解本研究的本质所必需的主题的简要概述。
我们只会谈论许可开源软件。首先,这是由于我们可以轻松地找到大量可用数据,而在这种范式中,其次是“开源软件”这一术语。可能会产生误导。从公司网站下载并安装通用专有程序时,要求您同意许可条款。当然,您通常不阅读它们,但总的来说,您了解这是某人的知识产权。与此同时,当开发商去GitHub上的项目,并看到所有的源文件,态度对他们是完全不同的:是的,有某种执照有,但它是开源的,软件是开放源码,这意味着你可以只取和做你想做的,对不对?不幸的是,并非一切都如此简单。
许可如何运作?让我们从最一般的权利划分开始:
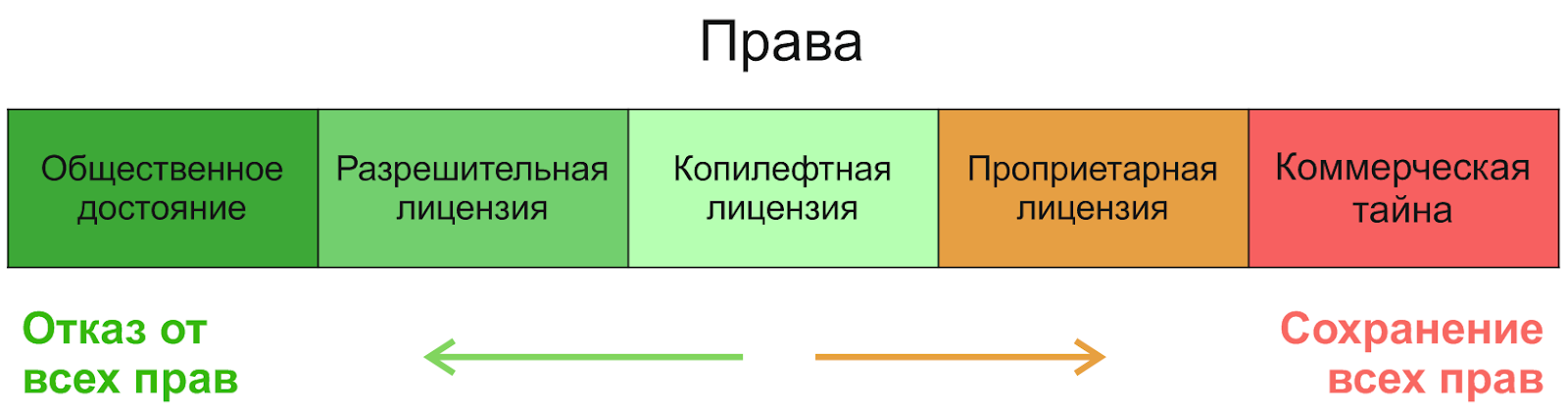
如果我们从右到左走,那么第一个将是商业秘密,其次是专有许可证-我们将不考虑它们。在开源软件领域,可以分为三类(根据自由度的提高):限制性许可(copyleft),非限制性许可(许可,许可)和公共领域。(这不是许可证,而是授予权利的一种方式)。要了解它们之间的区别,了解它们为什么会出现很有用。公共领域的概念与世界一样古老-创作者完全拒绝任何权利,并允许他使用自己的产品做任何想做的事情。但是,奇怪的是,自由从这种自由中诞生了,毕竟,另一个人可以接受这样的创作,对其稍加改动并对其进行“任何操作”,包括将其关闭并出售。 Copyleft开源许可证的创建恰恰是为了保护自由-从图片中它们的位置,您可以看到它们旨在保持平衡:允许使用,更改和分发产品,但不锁定产品,以使其自由。另外,即使作者不介意平仓和卖出方案,公共领域的概念因国家/地区而异,因此可能会造成法律上的麻烦。为了避免它们,使用了简单的许可许可证。
那么,许可许可证和Copyleft许可证有什么区别?像本主题中的所有内容一样,此问题是非常具体的,并且有例外,但是如果您进行简化,那么宽松的许可证不会对修改后的产品的许可证施加限制。也就是说,您可以采用这种产品,对其进行更改,然后以不同的许可(甚至是专有许可)将其放入项目中。与公共领域的主要区别通常是保留作者身份和提及原始作者的义务。最著名的许可许可证是MIT,BSD和Apache许可证。...一般而言,许多研究都将MIT视为最常见的开源许可证,并且还注意到自2004年Apache-2.0许可证推出以来,Apache-2.0许可证的受欢迎程度有了显着增长(例如,针对Java的研究)。
Copyleft许可证通常会限制副产品的分发和修改-您获得具有一定权利的产品,并且必须“进一步运行”,为所有用户提供相同的权利。这通常意味着承诺以相同的许可证重新分发软件并提供对源代码的访问。基于这一理念,Richard Stallman创建了第一个也是最受欢迎的版权保护许可,即GNU通用公共许可(GPL)。)。是她为未来的用户和开发人员提供最大的自由保护。我建议阅读Richard Stallman的免费软件运动历史,这很有趣。
Copyleft许可证有一个困难-传统上将其分为强和弱Copyleft。强权复制权正是上述内容,弱权复制权为开发人员提供了各种让步和例外。此类许可证最著名的示例是GNU较小通用公共许可证(LGPL):与旧版本一样,它只允许您在保留许可证的情况下修改和重新分发代码,但是,通过动态链接(在应用程序中将其用作库),可以省略此要求。换句话说,如果您想从此处借用源代码或进行某些更改,请观察copyleft,但是如果您只是想将其用作动态链接库,则可以在任何地方使用。
现在我们已经弄清楚了许可证本身,我们应该谈论它们的兼容性,因为我们想要防止的违规行为就是在其中存在(或者更确切地说,在没有许可证的情况下)。对这个主题感兴趣的任何人都应该遇到过这样的许可证兼容性方案:

乍一看这种方案,了解许可证的任何愿望都会消失。确实,有许多开源许可证,例如,可以在此处找到相当详尽的列表。同时,正如您将在下面的研究结果中看到的那样,您需要知道非常有限的数量(由于它们的分布极不均匀),而为了遵守所有条件,必须记住的规则甚至更少。此方案的一般向量非常简单:一切的源头都是公共领域,其背后是许可许可证,然后是弱的copyleft,最后是强的copyleft,并且许可证是兼容的“ right”:在copyleft项目中,您可以在许可许可证下重用代码,反之则不然-一切都是合乎逻辑的。
在这里可能会出现问题:如果代码没有许可证怎么办?那要遵循什么规则?可以复制此代码吗?这实际上是一个非常重要的问题。可能的是,如果将代码写在栅栏上,则可以将其视为公共领域,如果将它写在纸上的瓶子里,并钉在荒岛上(无版权),则可以简单地使用它。对于大型且已建立的平台(例如GitHub或StackOverflow),事情并不是那么简单,因为只要使用它们,您就自动同意它们的使用条款。现在,让我们在脑海中留下一个注释,然后稍后再回头-最后,也许这是稀有的,并且没有许可证几乎没有代码?
问题陈述和方法
因此,既然我们知道所有术语的含义,那么让我们先弄清楚我们想知道的内容。
- 开源软件中的代码复制有多普遍?开源项目中的代码中是否有很多克隆?
- 有哪些许可证?最常见的许可证是什么?该文件一次包含多个许可证吗?
- 最常见的借用是什么,即代码从一种许可证转移到另一种许可证?
- 最常见的违规情况是什么,即原始或接收许可证条款所禁止的代码转换?
- 单个代码片段的可能来源是什么?这段代码被违反复制的可能性是多少?
要进行这样的分析,我们需要:
- 从大量开源项目中收集数据集。
- 在其中找到代码片段的克隆。
- 确定那些可以真正借用的克隆。
- 对于每段代码,确定两个参数-它的许可证和最后修改的时间,这对于找出一对克隆中的哪个片段较大,哪个片段较年轻是必要的,因此-谁可以从谁那里复制。
- 确定允许许可之间的哪些可能转换,以及不允许许可之间的哪些转换。
- 分析收到的所有数据以回答上述问题。
现在,让我们仔细看看每个步骤。
数据采集
对于我们来说,这非常方便,如今使用GitHub可以轻松访问许多开放源代码。它不仅包含代码本身,而且还包含其更改历史记录,这对于本研究非常重要:为了找出谁可以从谁那里复制代码,您需要知道每个片段何时添加到项目中。
要收集数据,您需要确定所研究的编程语言。事实是,克隆是在一种编程语言的框架内进行搜索的:谈到许可冲突,评估将现有算法重写为另一种语言更加困难。这样复杂的概念受专利保护,而在我们的研究中,我们正在谈论更典型的复制和修改。我们选择Java是因为它是使用最广泛的语言之一,并且在商业软件开发中特别流行-在这种情况下,潜在的违反许可特别重要。
作为基础,我们采用了现有的Public Git档案库,该档案库在2018年初将GitHub上所有拥有50颗星的项目汇集在一起。我们选择了Java中至少有一行的所有项目,并下载了完整的更改历史记录。在过滤了已移动或不再可用的项目之后,有23,378个项目占用了大约1.25 TB的硬盘空间。
此外,对于每个项目,我们转储了分叉列表,并在数据集中找到了几对分叉–这对于进一步过滤是必要的,因为我们对分叉之间的克隆不感兴趣。数据集中共有324个项目,其中有分支。
寻找克隆
要查找克隆(即相似的代码段),您还需要做出一些决定。首先,我们需要确定对相似代码感兴趣的数量和能力。传统上,有4种类型的克隆(从最精确到最不精确):
- 完全相同的克隆是完全相同的代码段,仅在样式决定(例如缩进,空白行和注释)方面有所不同。
- 重命名的克隆包括第一类,但变量和对象名称可能有所不同。
- 紧密克隆包括以上所有内容,但可以包含更重要的变化,例如添加,删除或移动表达,但片段仍相似。
- , — , ( ), ().
我们对复制和修改感兴趣,因此我们只考虑前三种类型的克隆。
第二个重要决定是要寻找多少大小的克隆。可以在文件,类,方法,单个表达式之间搜索相同的代码片段...在我们的工作中,我们以该方法为基础,因为这是最平衡的搜索粒度:人们通常不在整个文件中复制代码,而是在小的片段中复制代码,但同时复制方法-它仍然是一个完整的逻辑单元。
根据选定的解决方案,要查找克隆,我们使用了SourcererCC-一种使用词袋法搜索克隆的工具:每种方法都表示为令牌的频率列表(关键字,名称和文字),然后对此类集合进行比较,如果两种方法中令牌的比例超过一定比例(该比例称为相似性阈值),则该对称为克隆。尽管该方法很简单(基于对方法的语法树甚至是程序依赖图的分析,还有很多更复杂的方法),但它的主要优点是可伸缩性:像我们一样,使用如此大量的代码,非常重要的一点是,必须快速进行克隆的搜索。 ...
我们使用了不同的相似性阈值来查找不同的克隆,并且还分别使用100%相似性阈值进行了搜索,其中仅识别了相同的克隆。此外,已设置最小调查方法大小,以丢弃可能不借用的琐碎和通用的代码段。
该搜索进行了长达66天的连续计算,发现了3860万种方法,其中只有1170万种通过了最小尺寸阈值,其中760万种参与了克隆。总共发现了12亿对克隆。
最后修改时间
为了进一步分析,我们仅选择项目间的克隆对,即在不同项目中发现的相似代码片段对。从许可的角度来看,我们对同一项目中的代码片段不是很感兴趣:重复您自己的代码被认为是不好的做法,但是并不禁止这样做。总共有大约5.61亿个项目间对,即大约所有对的一半。这些对包括380万种方法,因此有必要确定上一次修改的时间。为此,将git blame命令应用于每个文件(结果为89.8万,因为文件中可以有多个方法),该命令显示文件中每行的最后修改时间。
因此,我们具有方法中每行的最后修改时间,但是如何确定整个方法的最后修改时间呢?这似乎很明显-您花了最近的时间并使用它:毕竟,它确实显示了上次更改方法的时间。但是,对于我们的任务,这样的定义并不理想。让我们考虑一个例子:
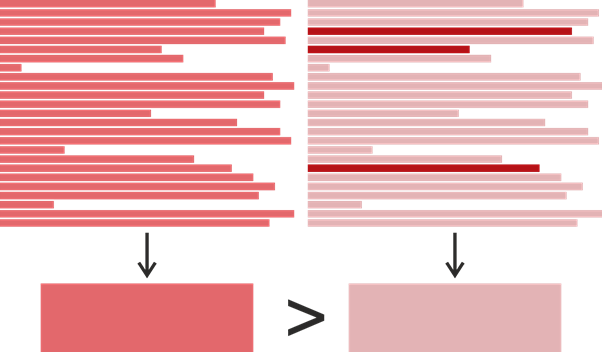
假设我们发现了几个片段形式的克隆,每个片段有25行。这里更饱和的颜色意味着后期的修改时间。假设左边的片段是在2017年一次写的,右边的片段是在2015年写的,第22行是在2019年修改的。事实证明,右边的片段是后来修改的,但是如果我们想确定谁可以从谁那里复制,假设相反,则更合乎逻辑:左边的片段借用了右边的片段,而右边的片段随后略有变化。基于此,我们将一段代码的最后修改时间定义为各行最后一次修改的最频繁发生的时间。如果突然有几次这样的情况,则选择一个较晚的时间。
有趣的是,我们数据集中最古老的代码段是在Java刚出炉时于1997年4月写的,他发现了一个在2019年制造的克隆!
定义许可证
第二个也是最重要的步骤是确定每个块的许可证。为此,我们使用了以下方案。首先,使用Ninka工具,确定直接在文件头中指示的许可证。如果有一个,则将其视为其中每种方法的许可证(Ninka能够同时识别多个许可证)。如果文件中未指定任何内容,或者信息不足(例如,仅版权),则使用文件所属的整个项目的许可证。有关它的数据包含在原始Public Git存档中,我们在此基础上收集了数据集,并使用另一种工具Go License Detector进行了确定。如果许可证不在文件或项目中,则将这些方法标记为GitHub,因为它们要遵守GitHub服务条款(这是我们所有数据的下载地)。
以这种方式定义了所有许可证之后,我们终于可以回答哪个许可证最受欢迎。我们总共找到94个不同的许可证。我们在此处提供文件的统计信息,以通过多种方法来补偿由于文件过大而引起的可能的纠结。
该时间表的主要特点是许可证分配最不均衡。在图形中可以看到三个区域:两个拥有超过10万个文件的“许可证”,另外十个拥有10万到10万个文件的许可证,以及长尾的少于1万个文件的许可证。
首先让我们考虑最流行的区域,在此我们以线性比例显示前两个区域:
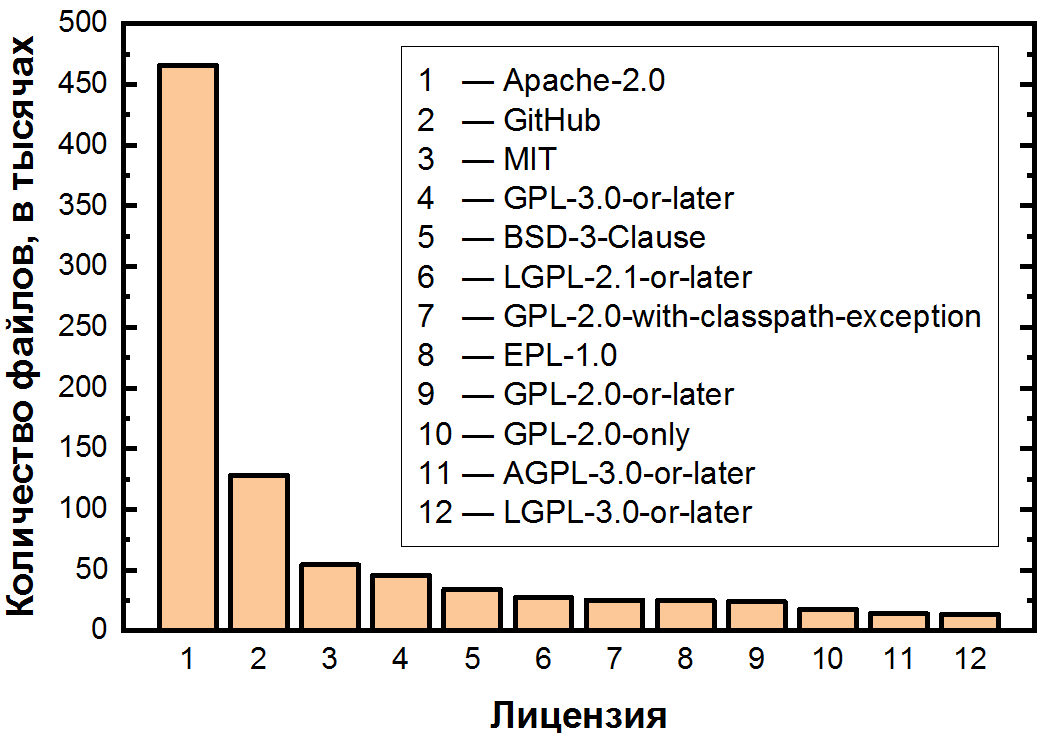
即使在最受欢迎的许可证中,也可以看到不均匀性。 Apache-2.0排名第一,在所有允许的许可证中是最平衡的,它覆盖了所有文件的一半以上。
其次是臭名昭著的缺少许可证,我们仍然必须对其进行更详细的分析,因为即使在中型和大型存储库(超过50个星)中,这种情况也很常见。这种情况非常重要,因为仅将代码上传到GitHub并不会使其公开。-如果有一些实用的知识,您需要从本文中记住,就是这样。通过将代码上传到GitHub,即表示您同意使用条款,该条款规定可以查看和创建代码。但是,除此以外,对代码的所有权利均归作者所有,因此分发,修改甚至使用都需要明确的许可。事实证明,不仅所有开源软件都不是完全免费的,甚至GitHub上的所有代码也不是完全开源的!而且由于有很多这样的代码(14%的文件,并且在数据集中未包含的较不受欢迎的项目中,很有可能甚至更多),这可能是造成大量违规的原因。
在前五名中,我们还看到了已经提到的MIT和BSD许可许可证,以及copyleft的GPL-3.0或更高版本。 GPL系列的许可证不仅在许多版本(不是很差)上有所不同,而且在“或更高版本”的附言中也不同,后者使用户可以使用此许可证或其更高版本的条款。这就引出了另一个问题:在这94个许可证中,显然有相似的“家族”-其中哪个家族最大?
GPL许可证排在第三位-列表中有8种许可证。这个家族是最重要的,因为它们一起覆盖了12.6%的文件,仅次于Apache-2.0,并且缺少许可证。排在第二位的是BSD。除了传统的3款版本,甚至是2和4款版本,也有很特定许可证-仅11件。例如,其中包括BSD 3条款无核许可证,它是具有3条的常规BSD,以下声明不得使用此软件来创建或操作任何核产品:
您承认该软件不是设计而成,许可或打算用于任何核设施的设计,建造,运行或维护。
最多样化的是知识共享许可系列,您可以在此处阅读有关信息。其中有多达13个,并且出于一个重要原因,它们也至少值得一读:StackOverflow上的所有代码均根据CC-BY-SA许可。
在较稀有的许可证中,有一些值得注意的许可证,例如,进行公开许可证(WTFPL)所需的内容,该文件涵盖529个文件,并允许您完全按照代码中的名称进行操作。例如,还有Beerware许可证,该许可证还允许您执行任何操作并鼓励作者在开会时购买啤酒。在我们的数据集中,我们还遇到了此许可证的变体,在其他地方(Sushiware许可证)没有找到。因此,她鼓励作者购买寿司。
另一个奇怪的情况是,在一个文件(即文件)中找到多个许可证。在我们的数据集中,只有0.9%的此类文件。 7.4万个文件同时被两个许可证覆盖,共发现74对不同的此类许可证。 419个文件涵盖了多达三个许可证,并且有8个这样的三元组。最后,我们数据集中的一个文件在标题中提到了四个不同的许可证。
可能的借款
现在我们已经讨论了许可证,我们可以讨论它们之间的关系。首先要做的是删除不可能借用的克隆。让我提醒您,目前我们尝试以两种方式考虑这一点-代码片段的最小大小和在一个项目中排除克隆。现在,我们将过滤出另外三种类型的对:
- 我们对分叉和原始分叉之间(例如,同一项目的两个分叉之间)之间的配对不感兴趣-为此,我们收集了它们。
- 我们也对属于同一组织或用户的不同项目之间的克隆不感兴趣(因为我们假设版权是在同一组织内共享的)。
- 最后,通过手动检查两个项目之间异常大量的克隆,我们发现了重要的镜像(它们也是间接派生的),即,将相同的项目上载到了不相关的存储库。
奇怪的是,剩下的对中有多达11.7%是相同的克隆,相似性阈值为100%-也许直觉上似乎在GitHub上应该没有那么绝对相同的代码。
我们将按照以下步骤处理在过滤之后剩余的所有对:
- 我们将两个方法的最后修改时间进行比较。
- , : .
- , «» «» . , 2015 MIT, 2018 — Apache-2.0, MIT → Apache-2.0.
最后,我们总结了每个潜在借用的对的数量,并按降序对其进行了排序:
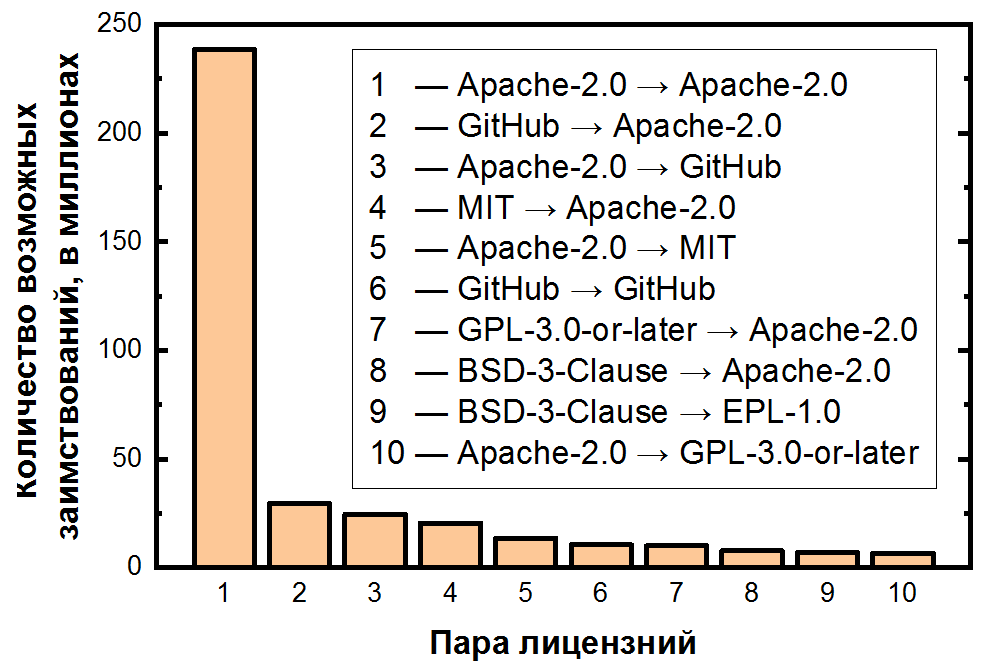
这里的依赖性更加极端:Apache-2.0中可能借用的代码占所有克隆对的一半以上,并且前10对许可证已经覆盖了80%以上的克隆。同样重要的是要注意,第二和第三最频繁的对处理未许可文件-这也是其频率的明显结果。对于五个最受欢迎的许可证,您可以将过渡显示为热图:
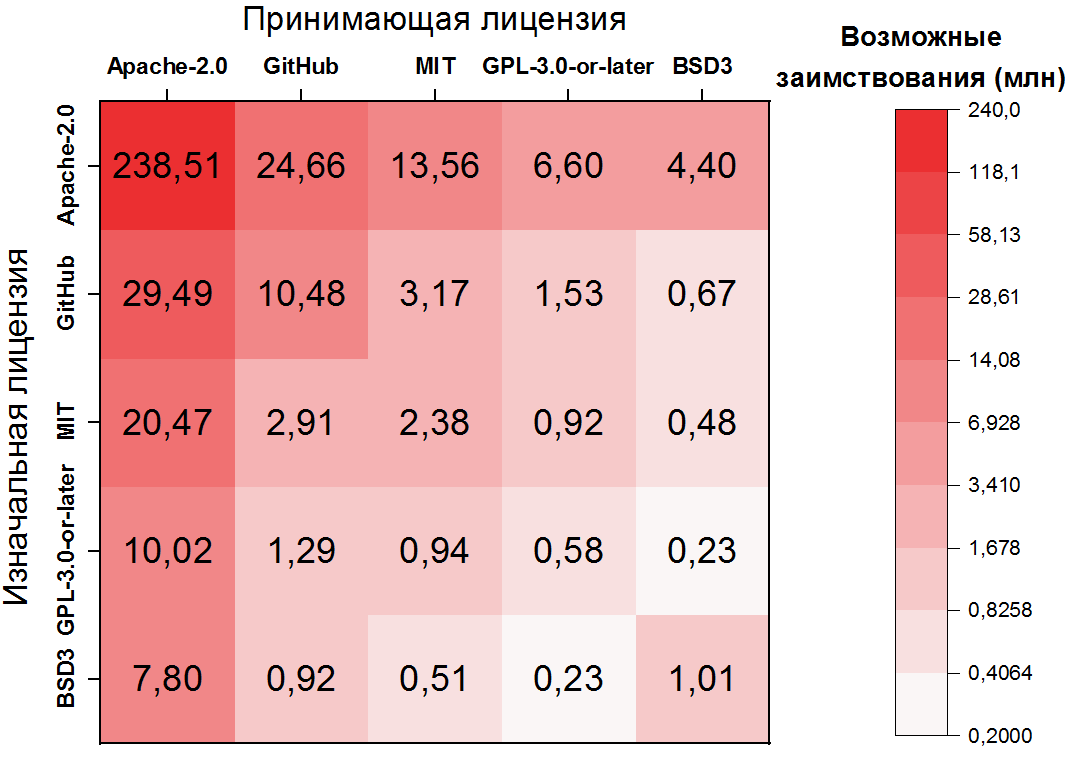
可能违反许可
我们研究的下一步是确定潜在的违反行为对,即违反原始许可证和主机许可证条款的借用。为此,您需要将上述许可对标记为允许或禁止转换。因此,例如,最流行的转换(Apache-2.0→Apache-2.0)当然是允许的,但是第二个转换(GitHub→Apache-2.0)却被禁止。但是有很多这样的对。
要解决此问题,请记住,渲染的前10对许可证覆盖所有克隆对的80%。由于这种不平衡,事实证明足以手动标记仅176对许可证以覆盖99%的克隆对,这在我们看来是可以接受的准确性。在这些夫妇中,我们考虑了四种禁止的夫妇:
- 从没有许可证的文件中复制(GitHub)。如前所述,这种复制需要代码作者的直接许可,并且我们认为在大多数情况下不是这样。
- 也禁止未经许可复制到文件,因为这实际上是在擦除,删除许可。许可许可证(例如Apache-2.0或BSD)允许代码在其他许可证(包括专有许可证)中重用,但是即使这些许可证也要求将原始许可证保留在文件中。
- .
- (, Apache-2.0 → GPL-2.0).
所有其他稀有的许可证(覆盖1%的克隆)对都被标记为允许的(以免不必要地责怪任何人),除非那些出现没有许可证的代码(永远不能复制)。
结果,在加价之后,事实证明,允许借入的借款为72.8%,禁止为27.2%。下图显示了最违反和最违反的许可证。

左侧是最容易违反的许可证,即,可能违反数量最多的来源。其中,第一个位置是没有许可证的文件,这是重要的实践注释-您需要特别密切地监视没有许可证的文件。... 有人可能想知道Apache-2.0许可许可证在此列表中的作用。但是,从上面的热图中可以看到,从中获得的大约2500万笔禁止借用是无许可证文件的借用,因此这是其流行的结果。
右侧是复制有违规的许可证,此处显示了大多数相同的Apache-2.0和GitHub。
个别方法的起源
最后,我们到了研究的最后一点。一直以来,我们都在讨论成对的克隆,这是此类研究的惯例。但是,您需要了解这种判断的某些方面,即不完整性。事实是,例如,如果一段代码中有20个“较老的”兄弟(或“父母”,谁知道),那么所有这20对都将被视为潜在借用。这就是为什么我们在谈论“潜在的”和“可能的”借用-特定方法的作者不太可能从20个不同的地方借用它。尽管如此,该推理仍可以视为有关不同许可证之间的克隆的推理。
为避免这种不完整的判断,您可以从不同角度看同一张图片。克隆图片实际上是一个有向图:所有方法都是其上的顶点,并通过从最早到最小的有向边(如果您不考虑同一天的方法)来连接。在前两节中,我们从边缘的角度查看了此图:我们获取了每个边缘并研究了其顶点(获得了非常多的许可证对)。现在让我们从顶点的角度来看它。图上的每个顶点(方法)都有祖先(“高级”克隆)和后代(“初级”克隆)。它们之间的链接也可以分为“允许”和“禁止”。
基于此,每种方法都可以归为以下类别之一,其图表显示在图像中(此处的实线表示禁止借用,虚线表示允许):提供的

两种配置可能构成对许可条件的违反:
- 严重违反意味着该方法具有祖先,并且禁止从祖先进行任何转换。这意味着,如果开发人员实际复制了代码,那么他会违反许可证来这样做。
- 弱违反意味着该方法有祖先,并且其中只有一些落后于禁止的转换。这意味着开发人员可能违反了许可证的规定复制了代码。
其他配置不违反:
- , , .
- — , — , .
- , , — , . , , — , . : , , , , ( , , ).
那么这些方法如何分布在我们的数据集中呢?

您可以看到大约三分之一的方法根本没有克隆,而另外三分之一仅在链接项目中才有克隆。另一方面,5.4%的方法表示“轻微违反”,而4%表示“严重违反”。尽管这些数字似乎并不大,但在或多或少的大型项目中仍然存在成千上万种方法。
TL; DR
考虑到本文包含了大量的经验数字和图表,让我们重复我们的主要发现:
- 具有克隆的方法数以百万计,并且它们之间有十亿对以上。
- , Java- 50 , 94 , : Apache-2.0 . Apache-2.0 .
- , 27,2%, .
- 35,4% , 5,4% «» , 4% «» .
?
最后,我想谈一谈为什么完全需要上述所有条件。我至少有三个答案。
首先,这很有趣。许可与编程的所有其他方面一样多样。由于某些许可证的特殊性和稀有性,许可证清单本身很奇怪,人们以不同的方式编写和使用它们。毫无疑问,这通常也适用于代码中的克隆和代码相似性。有些方法有数千个克隆,有些方法没有一个克隆,但乍一看并不总是容易发现它们之间的根本区别。
其次,对我们的发现进行详细分析,使我们能够制定一些实用的技巧:
- - . Apache-2.0, MIT, BSD-3-Clause, GPL LGPL.
- : . - , , .
- GitHub, . . — , . : - , , , , . , .
有关许可证的清晰说明,以及有关为新项目选择许可证的建议,您可以使用tldrlegal或choicealicense之类的服务。
最后,获得的数据可用于创建工具。目前,我们的同事正在开发一种方法,该方法可以使用机器学习方法(其中只有很多特定的许可证)和IDE插件来快速确定许可证,该插件将允许开发人员跟踪其项目中的依赖关系并提前注意到可能存在的不兼容性。
希望您从本文中学到了一些新东西。遵守基本许可条款不是那么麻烦,并且您可以根据规则尽一切努力。让我们一起教育,教育他人,并进一步接近实现“正确的”开源软件的梦想!