
例如,您有一个SharePoint文档库。当您向该库添加文件时,通常会另外为文件提供某些元数据。创建几个字段并在其中写入一些信息,以便对该库中的文件进行分类。但这是手动完成的,对于每个文件,您需要一次又一次地输入数据。SharePoint Syntex旨在通过根据自定义模型从文件中提取关键数据并将此数据保存到库字段来自动执行此过程。听起来不错。让我们看看它是如何工作的?
如何激活SharePoint Syntex?
由于SharePoint Syntex具有单独的许可证,因此我们需要获取此许可证。转到Microsoft网站,找到SharePoint Syntex产品,然后单击“免费试用”。

输入您的Microsoft 365帐户并确认激活了试用许可证后,请转到Microsoft 365管理中心,然后转到左侧菜单中的“设置”部分,然后选择“自动理解内容”项。对于像我这样的俄罗斯语言环境,这听起来像是“内容理解自动化”。
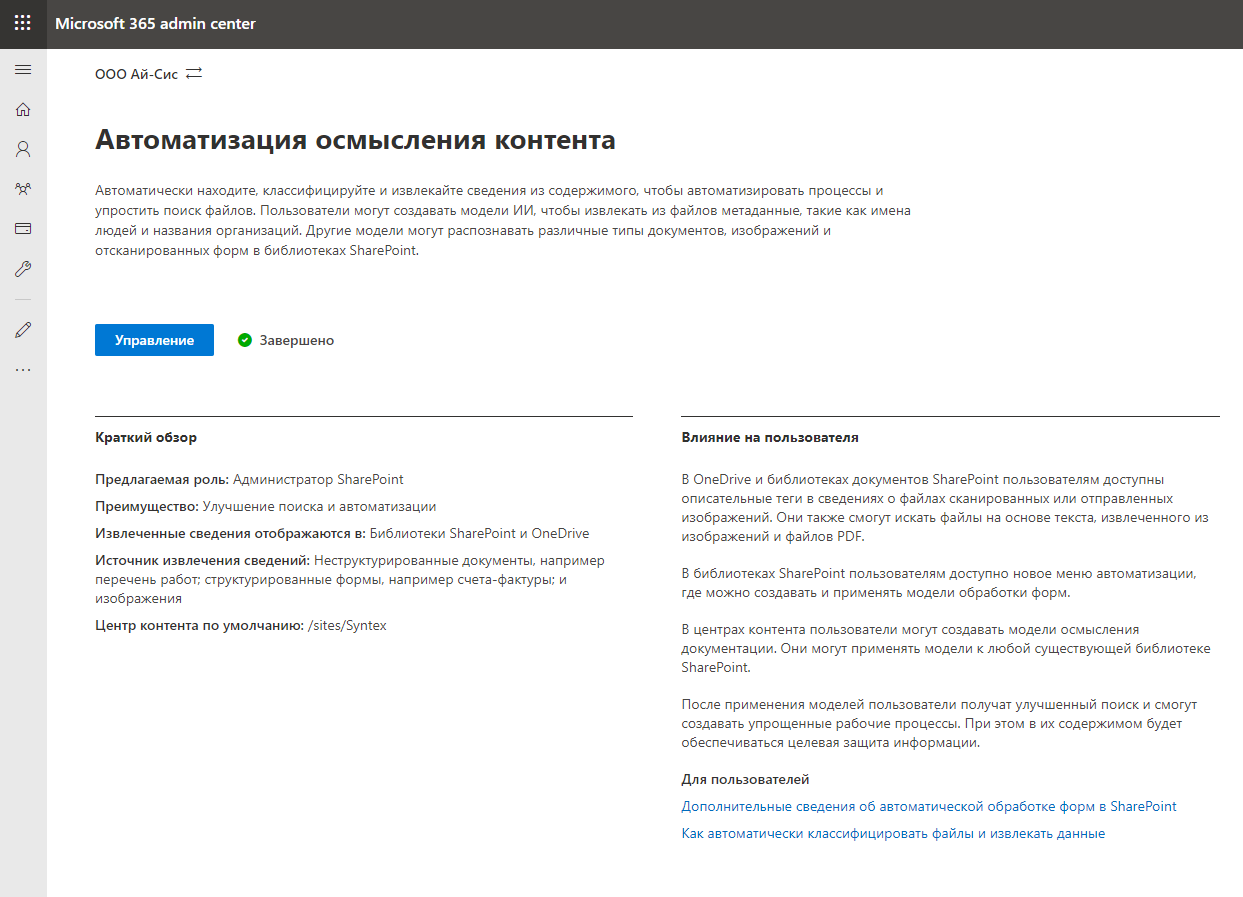
我们转到“管理”,然后继续设置服务。首先,有必要指出哪些库将支持SharePoint Syntex的功能。您可以选择特定的库或允许所有库。让我们破产吧。
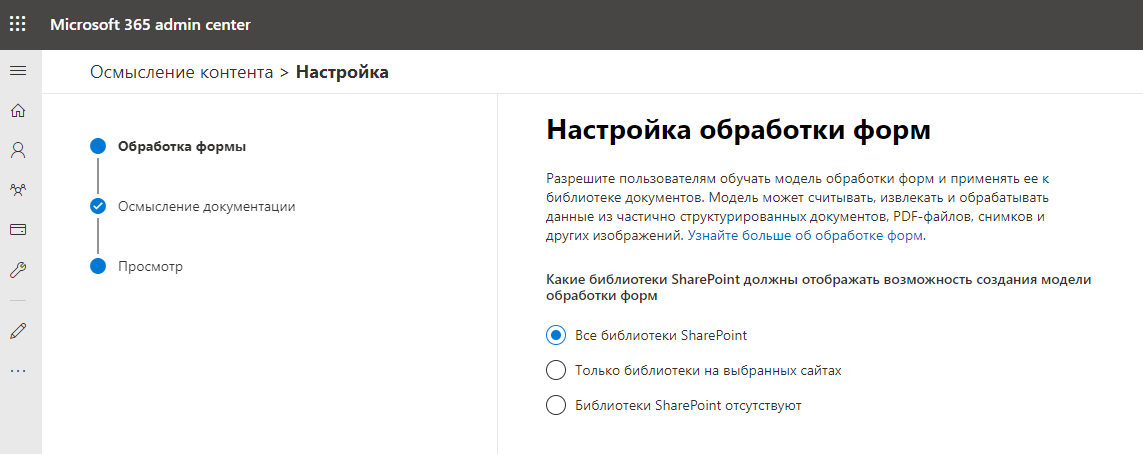
接下来,我们指定站点的名称和地址,这将是内容中心并存储经过训练的数据模型。似乎正在创建一个新的SharePoint Online收集网站。但是,这正是正在发生的情况。
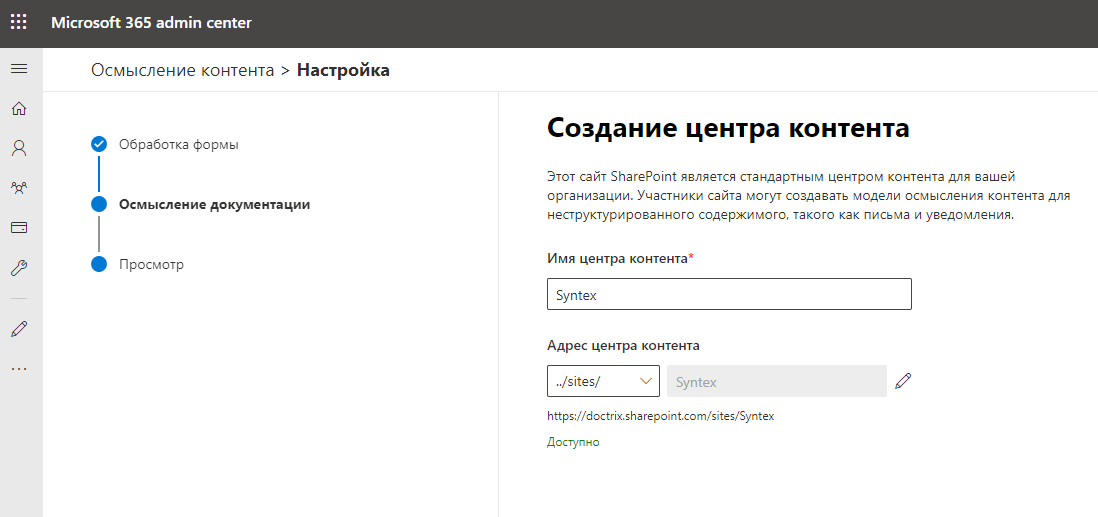
创建资源中心网站需要几分钟。我花了大约5分钟的时间,才设法倒了一些茶。我来了,对内容的理解已经激活了,哇。
配置SharePoint Syntex
转到SharePoint Syntex网站。从外观上看,它看起来像一个常规的SharePoint Online网站,但这只是乍一看。在此站点上,我们将建立并训练数据处理和分析模型。
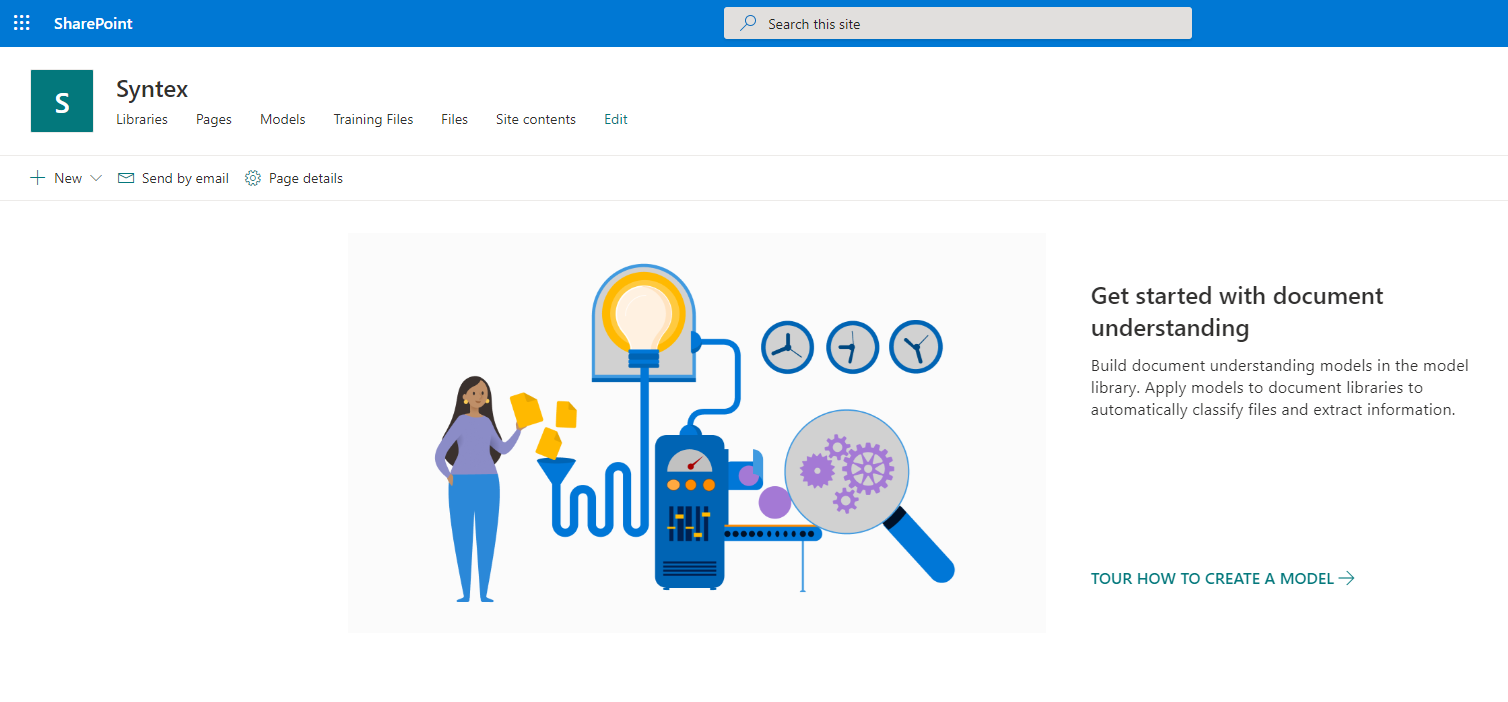
现在是时候开始建立模型了。单击“新建”,然后选择“文档理解模型”项。
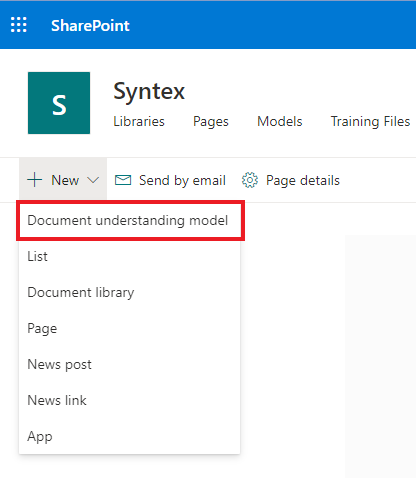
我们写下未来模型的名称,并指出需要为其创建一种新型的内容。我已经选择了该案例,该案例可能是您上一篇文章中熟悉的技术支持应用程序。不要为此类申诉而消失同一套模板。
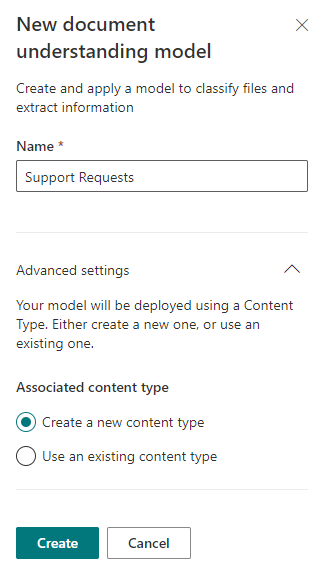
接下来,我们将看到一个包含逐步说明的页面,该说明描述了使未来模型正常工作以及理想地正常工作所需要做的事情。因此,首先,您需要上传几个文件(建议至少5个),帮助SharePoint Syntex根据需要对它们进行分类,并配置所谓的“提取器”-用于从文件中提取数据的模板。完成所有步骤后,可以将此模型应用于必需的SharePoint库。
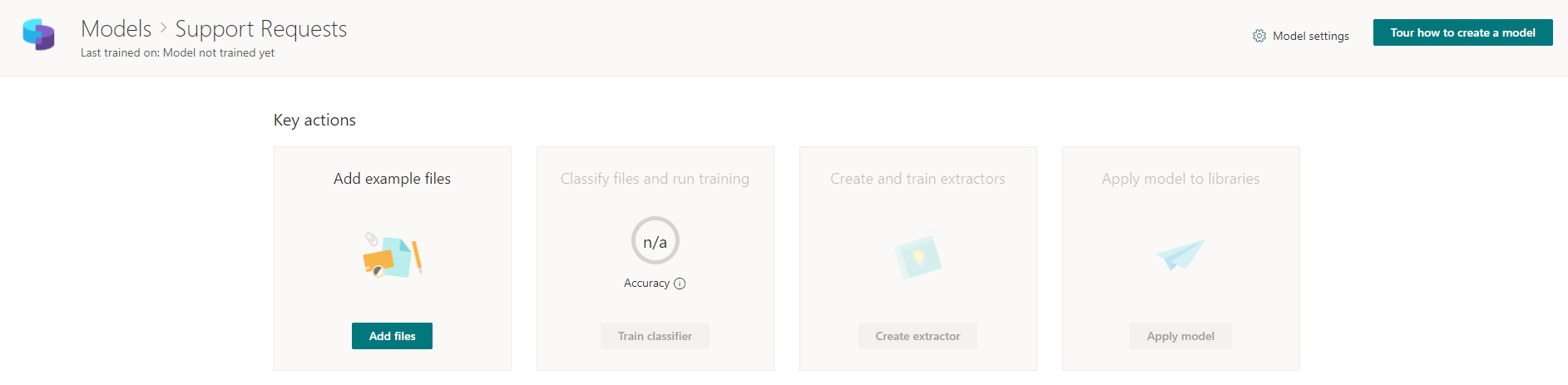
我们添加准备好的模板文件,这些文件将用于对将来的实际文件进行分类。
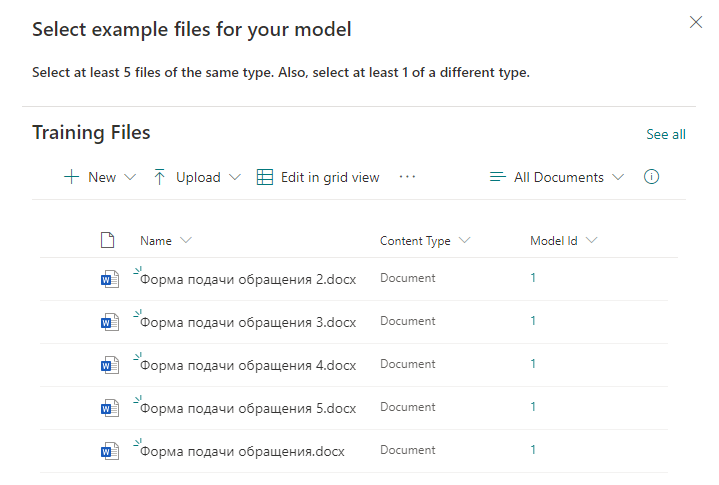
然后,我们指定将用于在文档中搜索信息的关键字。在每一行中,我们指示将用于搜索的新单词或短语。
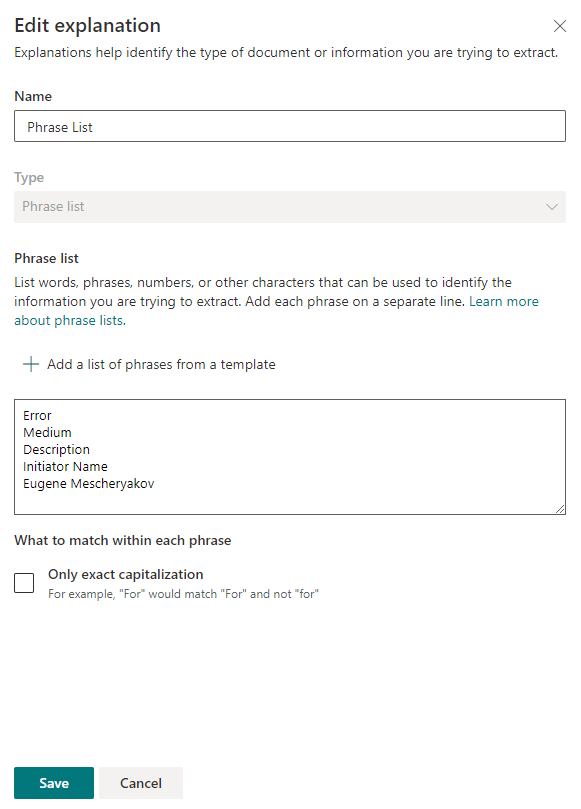
保存设置后,您可以尝试扫描现有文件中的关键短语。如果找到匹配项,则文件旁边将是“匹配项”。
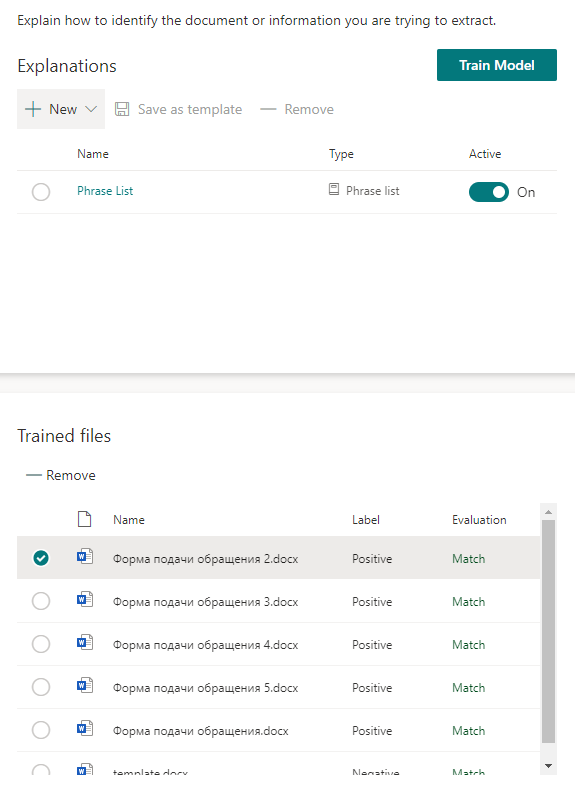
我们开始训练模型,然后倒茶。需要一些时间。
训练模型后,有必要配置“提取器”-数据提取模型。每个提取器本质上都是一种特定类型的SharePoint字段,它将在目标库中自动生成。将文件添加到此库后,将从文件中提取的信息写入此字段。
创建提取器时,需要指定其名称和类型。当前支持4种类型:
- 单行文字
- 多行文字
- 日期和时间
- 数
您还可以使用SharePoint库中的现有字段。
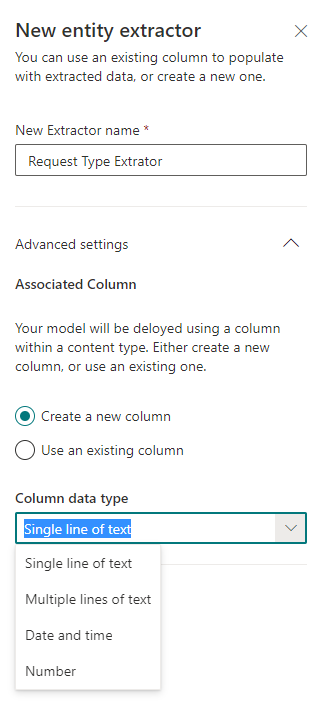
在上载文件的模板中设置提取器时,双击在上一步中识别的我们要提取的信息。
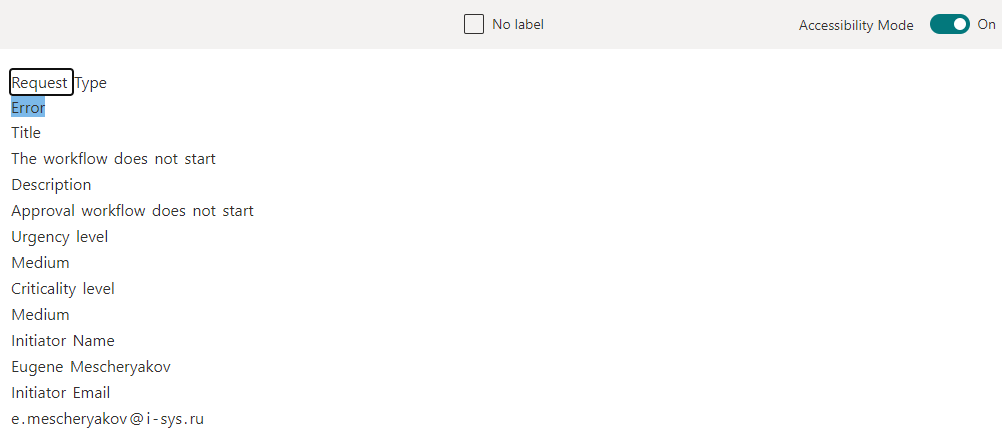
我们创建了几个这样的提取器,标记了必要的数据,然后,移至最后一部分-将经过训练的模型应用于SharePoint库,并检查其是否全部正常工作。

选择所需的SharePoint网站并指定目标库。我事先创建了HelpDesk Requests库,但未对其进行任何更改,而是将其保留为原始形式。我们保存设置并转到库。保存SharePoint Syntex设置后,新的SharePoint字段将出现在库中,按名称和类型对应于所创建的提取器。
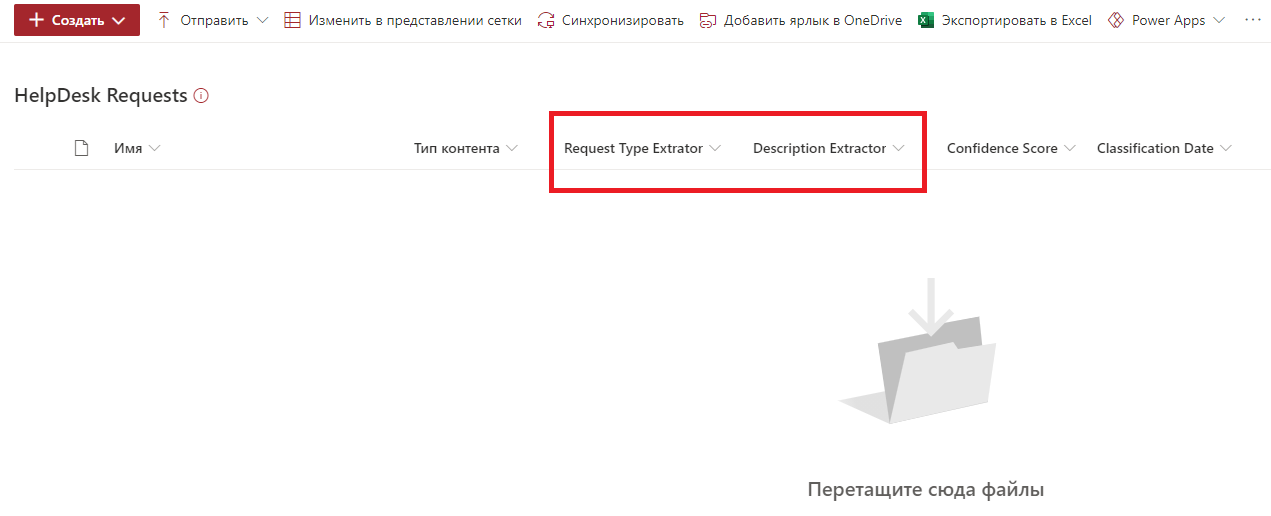
仍然可以将文件添加到库中并进行检查。添加另一个请求模板文件。

SharePoint Syntex可以识别案例类型和描述。数据存储在字段中。一切似乎都井井有条。
总
设置SharePoint Syntex数据模型只花了我很少的时间,所有内容都非常直观并且易于配置和使用。从专家那里,我看到了一种非常有用的功能,可以自动从文件内容中提取关键信息并将其写入SharePoint字段。此功能可以极大地加快工作速度,并消除用户工作的不必要阶段,添加文件后,有必要在库中手动填写许多必备条件。缺点-我想要提取器的更多类型的字段以及与Microsoft Power Platform的更紧密集成。但是我确信,它将作为下一个更新的一部分很快添加。
此外,SharePoint Syntex需要单独的许可证(每位用户每月5美元),目前尚未包含在Microsoft 365的企业许可证中。但是在将来,一切都可能会发生变化,SharePoint Syntex可能会成为Microsoft 365基本服务的一部分。请尝试激活试用版。一个月,然后查看此服务的功能。祝大家拥有美好的一天!