如果没有足够的RAM和良好的处理能力,即使在笔记本电脑上处理几GB的数据也只能是一项艰巨的任务。
尽管如此,数据科学家仍然必须找到解决此问题的替代解决方案。您可以选择设置熊猫来处理庞大的数据集,购买GPU或购买云计算能力。在本文中,我们将研究如何将Dask用于本地计算机上的大型数据集。
达斯克和Python
Dask是用于Python的灵活并行计算库。它与其他开源项目(例如NumPy,Pandas和scikit-learn)配合良好。Dask具有与NumPy数组等效的数组结构,Dask数据框与Pandas数据框相似,而Dask-ML是scikit-learn。
这些相似之处使您可以轻松将Dask集成到您的工作中。使用Dask的优点是您可以将计算扩展到计算机上的多个内核。这样您就有机会处理内存中无法容纳的大量数据。您还可以加快通常占用大量空间的计算。
资源
Dask DataFrame
当加载大量数据时,Dask通常会读取数据样本以识别数据类型。这通常会导致错误,因为同一列中可以有不同的数据类型。建议您提前声明类型以避免错误。Dask可以通过将巨大的文件切成参数定义的块来下载它们
blocksize。
data_types ={'column1': str,'column2': float}
df = dd.read_csv(“data,csv”,dtype = data_types,blocksize=64000000 )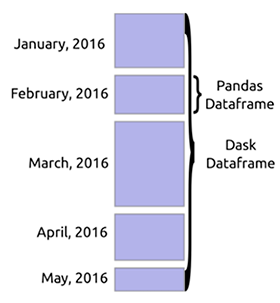
Dask DataFrame中的Source Commands与Pandas命令相似。例如,get
head和tail dataframe相似:
df.head()
df.tail()DataFrame中的函数是惰性的。也就是说,在调用函数之前,不会对它们进行求值
compute。
df.isnull().sum().compute()由于数据是按块加载的,因此某些Pandas功能
sort_values()将失败。但是你可以使用功能nlargest().
达斯克的集群
并行计算是Dask的关键,因为它允许您同时读取多个内核。 Dask提供
machine scheduler了在单个计算机上运行的功能。它无法缩放。还有一种distributed scheduler可以让您扩展到多台计算机。
使用
dask.distributed需要客户端配置。如果打算dask.distributed 在分析中使用它,这是您要做的第一件事。它提供了低延迟,数据本地性,工人与工人之间的通信,并且易于配置。
from dask.distributed import Client
client = Client()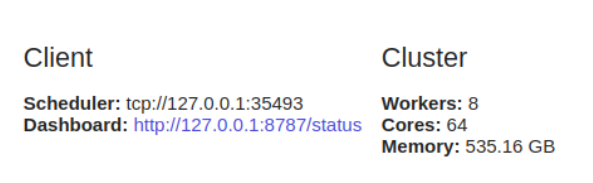
dask.distributed通过仪表板提供诊断功能,甚至在单台机器上
使用也是有益的。
如果您未配置
Client,则默认情况下,您将对一台计算机使用计算机调度程序。它将使用进程和线程在单台计算机上提供并发性。
达拉斯ML
Dask还允许并行模型训练和预测。目标
dask-ml是提供可扩展的机器学习。声明时n_jobs = -1 scikit-learn,可以并行运行计算。Dask使用此功能使您能够在集群中进行计算。您可以使用joblib软件包执行此操作,该软件包可在Python中启用并行性和流水线操作。使用Dask ML,您可以使用scikit-learn模型和其他库,例如XGboost。
一个简单的实现看起来像这样。
首先,导入
train_test_split将您的数据分为训练和测试用例。
from dask_ml.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)然后导入要使用的模型并将其实例化。
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(verbose=1)然后,您需要导入
joblib以启用并行计算。
import joblib然后从并行后端开始训练和预测。
from sklearn.externals.joblib import parallel_backend
with parallel_backend(‘dask’):
model.fit(X_train,y_train)
predictions = model.predict(X_test)限制和内存使用
Dask中的各个任务不能并行运行。工作者是继承了Python计算的优缺点的Python进程。此外,在分布式环境中工作时,必须注意确保数据的安全性和私密性。
Dask有一个中央调度程序,用于监视工作程序节点和集群中的数据。它还管理集群中的数据释放。任务完成后,它将立即将其从内存中删除,以为其他任务腾出空间。但是,如果特定客户端需要某些东西,或者对于当前的计算很重要,则它将存储在内存中。
Dask的另一个局限性在于它无法实现Pandas的所有功能。Pandas界面非常大,因此Dask并未完全涵盖它。也就是说,在Dask中执行其中的某些操作可能会很有挑战性。此外,在达斯克,来自熊猫的缓慢行动也将缓慢。
当您不需要Dask DataFrame时
在以下情况下,Dask可能不是您的正确选择:
- 当Pandas具有所需功能时,Dask尚未实现它们。
- 当您的数据完全适合您的计算机内存时。
- 当您的数据不是以表格形式显示时。如果是这样,请尝试dask.bag或disk.array。
最后的想法
在本文中,我们研究了如何使用Dask分布式处理本地计算机上的大量数据集。我们看到可以使用Dask了,因为它的语法已经为我们所熟悉。Dask还可以扩展到数千个内核。
我们还看到我们可以在机器学习中使用它进行预测和训练。如果您想了解更多信息,请查阅文档中的这些材料。
