本文出现的原因有很多。
首先,在绝大多数书籍,Internet资源和数据科学课程中,根本没有考虑不同类型的数据规范化的细微差别,缺陷及其原因,或者只是顺便提及而没有实质性提及。
第二,例如,对具有大量功能的集合进行标准化的“盲目”使用-“以便每个人都一样”。特别是对于初学者(他本人也是一样)。乍一看,没关系。但是仔细检查后,可能会发现某些标志被无意识地置于特权位置,并且开始对结果产生更大的影响。
第三,我一直想得到一种考虑问题区域的通用方法。
重复是学习之母
规范化是将数据转换为某些无量纲单位。有时-在给定范围内,例如[0..1]或[-1..1]。有时-具有某些给定的属性,例如标准偏差为1。
规范化的主要目标是将以各种度量单位和值范围为单位的不同数据整合为一种形式,使您可以将它们相互比较或用于计算对象的相似性。在实践中,例如,对于集群和某些机器学习算法而言,这是必需的。
从分析上讲,任何归一化都可简化为公式
哪里 - 目前的价值,
-偏移值的值,
-要转换为“ 1”的间隔的大小
实际上,这全都归结为这样一个事实,即原始值的集合先被移位然后被缩放
例子:
极小(MINMAX) 。目标是将原始设置转换为范围[0..1]。为了他:
= , .
= — , .. “” .
. — 0 1.
= , .
— .
, .
, , “” . .
, - . , . , , . , . , — . , , , , *
* — , , ( ), , .
, — .
1 —
— .. , , 0 “” .
? « » . .
№ 1 — , .
, “ ” , , — , . ( ). ( ) .
, , .
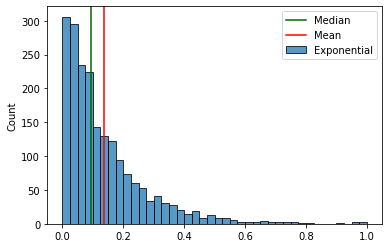
:
. “” .
, , , . .
2 —
. .
. , , [-1..1], . [-1..1], — [-1..100], , . .
. . , “”.
( ):

( ) , .
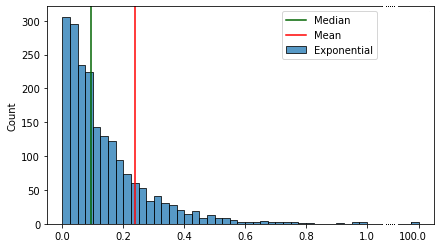
, () “”, .

— ( ). , “” .
75- 25- — . .. , “” 50% . “” / .
— “”, “” .
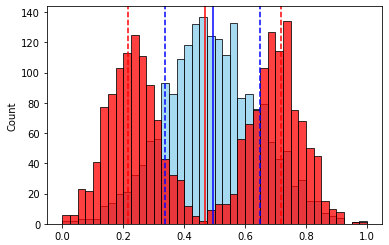
№ 2 — “” .
— .
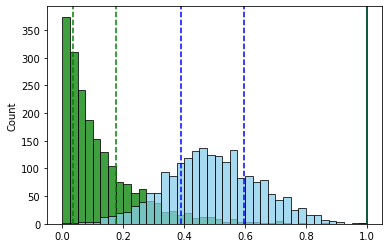
( ).

- “” . , , “”.
. .. . — 1.
, , , № 3 — . ( ) .
, , . 2-
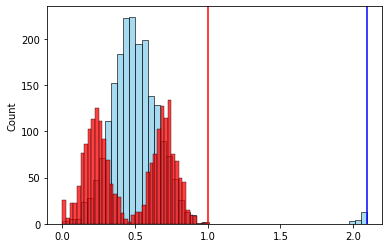
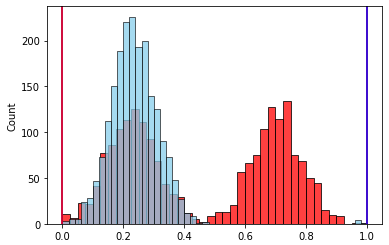
, , . .
, “-”. — .
— , . , . , , , , ? .
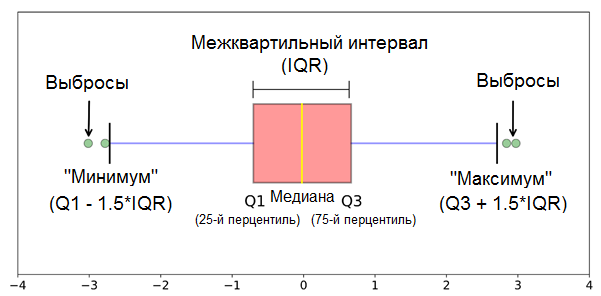
, . , “” , 1,5 (IQR) .*
* — ( .) 1,5 3 — .
.
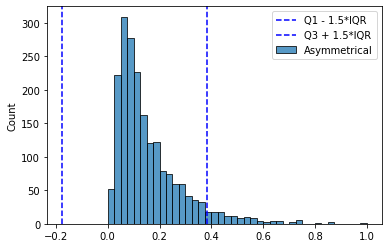
— - , .
. (, , ) “” — 7%. (3 * IQR) — . . .. .
, . “ ” (1,5 * IQR) , . , - “” .
(Mia Hubert and Ellen Vandervieren) 2007 . “An Adjusted Boxplot for Skewed Distributions”.
“ ” , 1,5 * IQR.
“ ” medcouple (MC), :
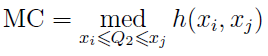
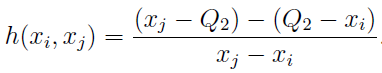
“ ” , , , 1,5 * IQR — 0,7%
:
:

:
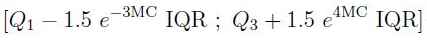
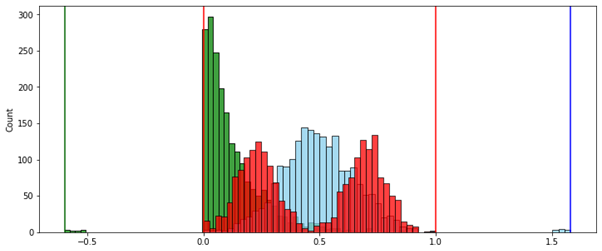
. .
, , :
- , , .
- .
- () — , , [0..1]
… — Mia Hubert Ellen Vandervieren
. .
, ( ) (MinMax — ).
№ 1 — . . , “” .
:
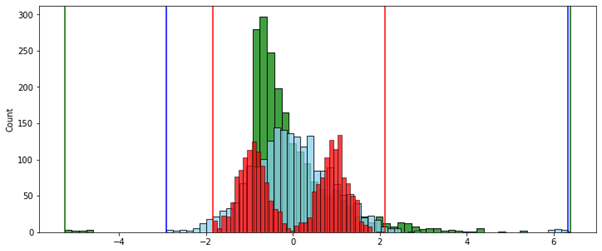
( ):

:

, — , , .
№ 2 — . [0..1]. , , .
MinMax ( ):
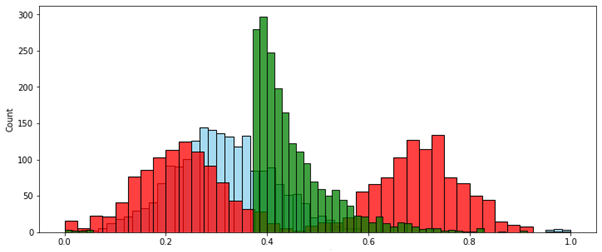
:
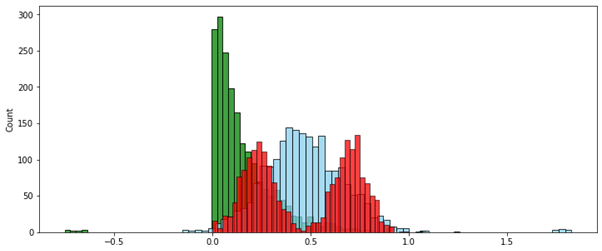
. -, , — .. 0 1.
, “” [0..1], , — , , , . .
* * *
最后,为了有机会亲身体验这种方法,您可以从此处尝试我的演示类AdjustedScaler 。
它不是为处理大量数据而优化的,而仅与pandas DataFrame一起使用,但是对于试验,实验甚至是更严重的空白,它都非常合适。尝试一下。