
这是关于差异性隐私的系列文章中第二篇的翻译。
上周,在本系列的第一篇文章“差异性隐私-在维护机密性的同时分析数据(该系列的简介) ”中,我们研究了差异性隐私的基本概念和用法。今天,我们将根据预期的威胁模型考虑构建系统的可能选择。
部署满足差异隐私原则的系统并不是一件容易的事。作为示例,在我们的下一篇文章中,我们将看一个简单的Python程序,该程序将拉普拉斯噪声直接添加到处理敏感数据的函数中。但是,为了使它起作用,我们需要在一台服务器上收集所有必需的数据。
如果服务器被黑了怎么办?在这种情况下,差异性隐私将无济于事,因为它只能保护由于程序工作而获得的数据!
在基于差异隐私原则部署系统时,重要的是要考虑威胁模型:我们要从哪个对手保护系统。如果此模型包括可以完全利用敏感数据破坏服务器的攻击者,那么我们需要更改系统,以使其能够抵御此类攻击。
也就是说,尊重差异隐私的系统架构必须同时考虑隐私和安全性。隐私控制可以从系统返回的数据中检索什么。而安全可以考虑相反的任务:它是在对数据的访问的部分控制权,但它并没有给出关于其内容的任何保证。
中央差分隐私模型
在差异隐私工作中最常用的威胁模型是中央差异隐私模型(或简称为“中央差异隐私”)。
主要组件-可信数据存储区(trusted data curator)。每个来源都将他的机密数据发送给他,然后将其收集在一个地方(例如,在服务器上)。如果我们假设存储库自己处理敏感数据,不将其传输给任何人并且不会被任何人破坏,则该存储库是受信任的。换句话说,我们认为拥有敏感数据的服务器不会受到威胁。
作为中心模型的一部分,我们通常会在查询响应中添加噪音(我们将在下一篇文章中介绍Laplace实现)。该模型的优势是能够添加最低的噪声值,从而保持差异隐私原则所允许的最大准确性。下面是过程图。我们在受信任的数据存储区和分析人员之间设置了隐私壁垒,以便只有符合指定的差异性隐私标准的结果才能出现。因此,分析人员不需要被信任。
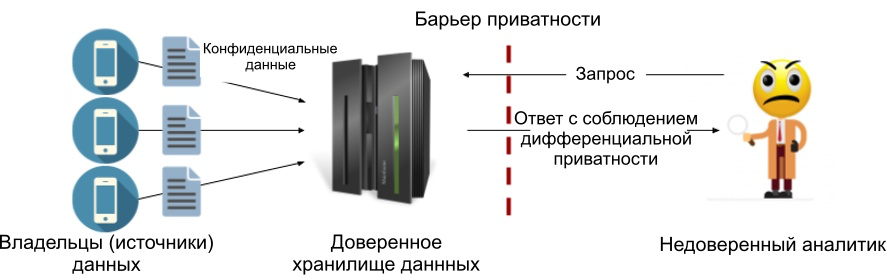
图1:中央差分隐私模型。
中央模型的缺点是它需要一个受信任的存储,而其中许多则不需要。实际上,对数据使用者的不信任通常是使用差异隐私原则的主要原因。
本地差异隐私模型
本地差异隐私模型允许您摆脱受信任的数据存储区:每个数据源(或数据所有者)在将其传输到存储区之前都会对其数据添加噪音。这意味着存储将永远不会包含敏感信息,这意味着不需要其授权书。下图显示了本地模型的设备:在其中,隐私屏障位于数据的每个所有者与存储之间(可能会或可能不会受到信任)。
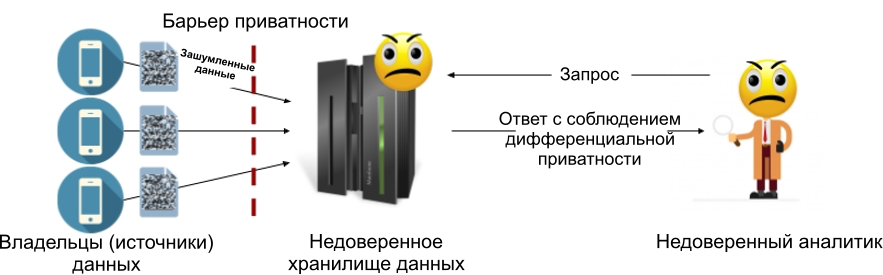
图2:本地差异隐私模型。
本地差异隐私模型避免了中央模型的主要问题:如果数据仓库遭到破坏,那么黑客将只能访问已经满足差异隐私要求的嘈杂数据。这就是为什么为Google RAPPOR [1]和Apple的数据收集系统[2]等系统选择本地模型的主要原因。
但另一方面?局部模型的准确性不如中央模型。在本地模型中,每个源独立添加噪声以满足其自己的差异性隐私条件,因此来自所有参与者的总噪声比中心模型中的噪声大得多。
最终,这种方法仅适用于具有非常持久的趋势(信号)的查询。例如,苹果公司使用本地模型来估算表情符号的受欢迎程度,但结果仅对最受欢迎的表情符号(趋势最为明显)有用。通常,此模型不用于更复杂的查询,例如美国人口普查局[10]或机器学习所使用的查询。
混合模型
中央和本地模型都具有优点和缺点,现在的主要工作是从中获得最大的收益。
例如,您可以使用在Prochlo系统中实现的改组模型[4]。它包含一个不受信任的数据存储,许多个人数据所有者以及几个部分受信任的混洗器。...每个源首先在其数据中添加少量噪声,然后将其发送到搅拌器,然后在将其发送到数据仓库之前添加更多的噪声。底线是,搅动者不太可能与数据存储或彼此“勾结”(或同时被黑客入侵),因此,由源添加的少量噪声足以保证隐私。每个混频器都可以处理多个源,就像中央模型一样,因此少量的噪声将确保所得数据集的私密性。
搅拌器模型是局部模型和中央模型之间的折衷方案:它添加的噪声比局部模型少,但比中央模型大。
您还可以将差分隐私与加密技术结合使用,例如在安全的多方计算(MPC)或完全同态加密(FHE)中。 FHE允许使用加密的数据进行计算而无需先对其解密,而MPC允许一组参与者在不泄露其数据的情况下安全地对分布式源执行查询。微分私有函数的计算使用加密安全(或仅安全)计算是一种实现中央模型准确性并具有本地优势的有前途的方法。而且,在这种情况下,安全计算的使用消除了对具有可信存储的需求。最近的工作[5]展示了MPC和差异隐私的结合所产生的令人鼓舞的结果,吸收了两种方法的大多数优点。的确,在大多数情况下,安全计算比本地执行的计算要慢几个数量级,这对于大型数据集或复杂查询尤为重要。安全计算目前处于积极的开发阶段,因此其性能正在迅速提高。
所以?
在下一篇文章中,我们将看看我们的第一个开源工具,该工具将差分隐私概念付诸实践。让我们看一下其他工具,这些工具对于新手都是可用的,并且适用于超大型数据库,例如美国人口普查局的数据库。我们将尝试根据差异隐私原则计算人口数据。
订阅我们的博客,不要错过下一篇文章的翻译。很快。
资料来源
[1] Erlingsson,Úlfar,Vasyl Pihur和Aleksandra Korolova。 “ Rappor:随机汇总的隐私保护顺序响应。”在2014年ACM SIGSAC计算机和通信安全会议论文集中,第pp。 1054-1067。 2014.
[2] Apple Inc. “ Apple差异隐私技术概述”。访问了7/31/2020。https://www.apple.com/cn/privacy/docs/Differential_Privacy_Overview.pdf
[3] Garfinkel,Simson L.,John M. Abowd和Sarah Powazek。 “在部署差异性隐私时遇到了问题。”在《 2018年电子社会隐私研讨会》的论文集中,第133-137。 2018。
[4] Bittau,Andrea,ÚlfarErlingsson,Petros Maniatis,Ilya Mironov,Ananth Raghunathan,David Lie,Mitch Rudominer,Ushasree Kode,Julien Tinnes和Bernhard Seefeld。“ Prochlo:为人群中的分析提供强大的隐私权。” 在《第26届操作系统原理研讨会论文集》中,第11页。441-459。2017.
[5] Roy Chowdhury,Amrita,王成宏,西河,Ashwin Machanavajjhala和Somesh Jha。“加密:不受信任的服务器上的加密辅助差分隐私。” 在2020年ACM SIGMOD国际数据管理会议论文集中,第2页。603-619。2020年。