
关于推荐系统的几句话
当然,每个人都多次见到他们。推荐系统是试图预测对特定用户可能有趣/需要/有用的东西的程序和服务,并向他们显示。“你喜欢这些跑鞋吗?您可能还需要一件风衣,心率监测仪和15种运动项目。“ 近年来,由于买卖双方都从该决定中“受益”,因此品牌在其工作中一直非常积极地实施推荐系统。消费者获得了一种工具,可以帮助他们在短时间内选择各种商品和服务,从而促进销售和受众的增长。
给了我们什么?
我曾为一家大型跨国公司的项目工作,该公司为客户提供SaaS货运解决方案或货运平台。
这听起来令人难以理解,但实际上是如何发生的:一方面,在平台上注册了有负载并需要将负载发送到某个地方的用户。他们放置了一个应用程序,例如“有一批装饰性化妆品,明天需要从阿姆斯特丹运到安特卫普”正在等待答案。另一方面,我们有配备卡车的人员或公司-货运公司。假设他们已经进行了每周的标准飞行,从巴黎到布鲁塞尔都有酸奶。他们需要回去,为了不带着空卡车走,找到了某种要在回去的路上运输的货物。为此,货运承运人前往我的客户的平台并进行搜索(从英文搜索),指出适合卡车的货物的方向和类型(或货运,英文)。该系统从托运人处收集申请并将其显示给货运公司。
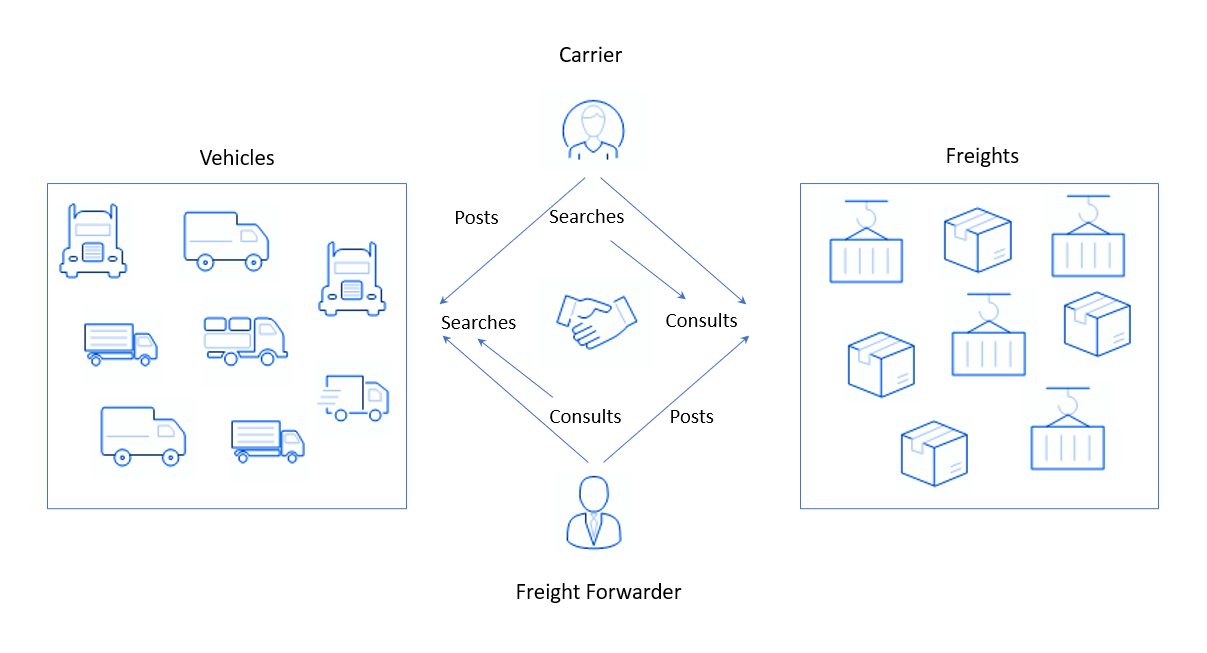
在这样的平台上,供需平衡很重要。在这里,货运船需要货物,而托运人则需要卡车,而要约则相反:货运公司的汽车和公司的货物。出于多种原因,难以维持余额,例如:
- 运营商与客户之间的封闭通信。当驱动程序通常仅与特定客户一起使用时,它在平台上不能很好地工作。如果托运人离开市场,该服务也可能失去承运人,因为它成为另一家物流公司的客户。
- 没有人想要运输的货物的存在。当小公司下达运输订单时,就会发生这种情况,然后这些订单不会被更新,因此会迅速留下活跃订单的数量。
该公司希望改善其货运交换平台的功能并增加用户的用户体验,以使他们能够看到系统的所有功能和各种商品,同时又不失去忠诚度。这可以使目标受众避免转向竞争性服务,并向货运公司证明,不仅可以从与他们合作的公司中找到合适的订单。
考虑到所有的愿望,我面临着开发一个推荐系统的任务,该系统将立即在平台入口处向承运人显示当前可用的相关货物,并猜测他们想运输什么以及在哪里运输。该系统将被集成到现有的货运平台中。
我们将如何“猜测”?
与其他系统一样,我们的推荐系统可用于分析用户数据。您可以使用多种来源进行操作:
- 首先,公开有关货物运输申请的信息。
- 其次,平台提供有关承运人的数据。当用户与我们的客户签订合同时,他可以指出他拥有多少辆卡车以及什么类型的卡车。但是,不幸的是,此数据未更新之后。我们唯一可以依靠的是承运人所在的国家,因为它极有可能不会改变。
- 第三,该系统存储了几年的用户搜索历史:最近的请求和一年前的请求。
在他们决定实施推荐系统的应用程序中,已经存在一种根据以前的请求搜索商品的机制。因此,我们决定专注于识别模式或模式,以便用户搜索要运输的货物。也就是说,我们不建议负载,而是选择今天最适合此用户的方向。而且我们已经可以使用标准搜索引擎找到商品。
通常,热门搜索基于地理信息和其他参数,例如卡车的类型或运输的物品。这很容易跟踪,因为这些首选项几乎不变。下面我给出了其中一个用户的请求为期3天的数据。填充顺序如下:1列-出发国家,2-目的地国家,3-出发区域,4-目的地区域。

您可以看到该用户在国家和省中具有特定的首选项。但这不是每个人的情况,并非总是如此。通常,承运人仅指示目的地国或不指示出发地,例如,他在比利时,可以来任何省份取货。通常,查询有不同类型:国家间,国家间,区域间或区域间(最佳选择)。
算法样本
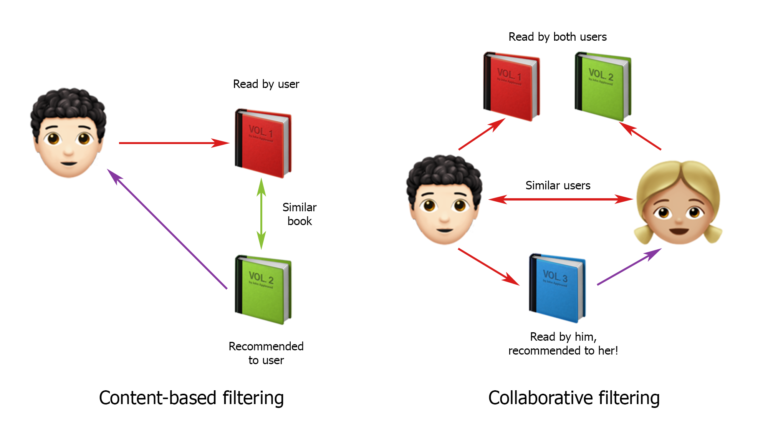
如您所知,创建推荐系统的策略主要分为基于内容的过滤和协作过滤。基于此分类,我开始构建解决方案。
我是从hub.forklog.com拍的照片
许多消息来源说协作过滤效果更好。很简单:我们正在尝试寻找与我们的用户相似且具有相似行为模式的用户,并且我们建议用户与他们的请求相同。通常,此解决方案是我向客户展示的第一个选项。但是他们不同意他的说法,并说这行不通。毕竟,一切都很大程度上取决于卡车的当前位置,在何处取货,在哪里居住以及在哪里运输更方便。我们对此一无所知,这就是为什么很难依靠其他用户的行为,即使乍一看他们是相似的。
现在介绍基于内容的系统。它们的工作方式如下:首先,确定并创建用户个人资料,然后根据其特征选择建议。这是一个很好的选择,但在我们的案例中有一些细微差别。首先,一个用户可以隐藏一群正在为许多卡车寻找货物的人,并从不同的IP登录。其次,从确切的数据中,我们只有承运人所在的国家,而有关卡车数量及其类型的信息仅在用户提出要求时才大致“显示”。也就是说,为了为我们的项目构建基于内容的系统,您需要查看每个用户的请求,并尝试找到其中最受欢迎的请求。
我们的第一个推荐系统没有使用复杂的算法。我们试图对查询进行排名,并找到最高心的推荐对象。为了测试该概念,我们的团队与真实用户一起工作:向他们发送建议,然后收集反馈。原则上,运营商喜欢结果。然后,我将我们的建议与运营商最近的需求进行了比较,发现该系统对于行为模式稳定的用户来说非常有效。但是,不幸的是,对于那些提出更多要求的人,建议的准确性不是很高-需要改进系统。
我继续弄清楚我们在这里要处理什么。实际上,这是一个隐藏的马尔可夫模型,其中一群人可以位于每个用户之后。而且,用户可能处于各种隐藏状态:没有数据,他们当前在哪里有卡车,一个账户上有多少人,以及下次何时需要去某个地方。当时,我不知道用于生成隐马尔可夫模型的现成解决方案,因此我决定寻找更简单的方法。
认识PageRank
因此,我提请注意由Google创始人谢尔盖·布林(Sergey Brin)和拉里·佩奇(Larry Page)创建的PageRank算法,该搜索引擎仍然使用它来向用户推荐网站。PageRank以图形的形式表示整个Internet空间,其中每个网页都是其节点。它可用于计算每个节点的“重要性”(或等级)。PageRank从根本上不同于之前存在的搜索算法,因为它不是基于页面的内容,而是基于页面内部的链接。也就是说,每个页面的等级取决于指向该页面的链接的数量和质量。Brin和Page证明了该算法的收敛性,这意味着我们始终可以计算有向图中任何节点的等级并得出不会改变的值。
让我们看一下它的公式:
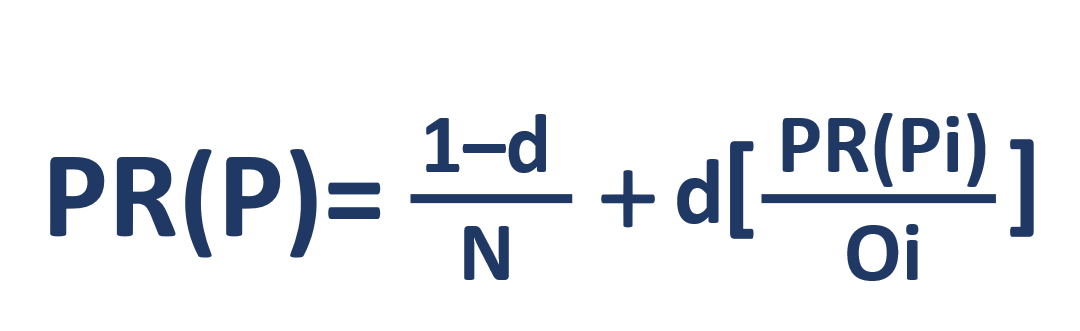
- PR(P) – rank
- N –
- i –
- O –
- d – . -, , - . , . 0 ≤ d ≤ 1 – d 0,85. .
现在是为包含三个节点的简单图形计算PageRank的简单示例。重要的是要记住,在开始时,所有节点的权重均等于1 /节点数。
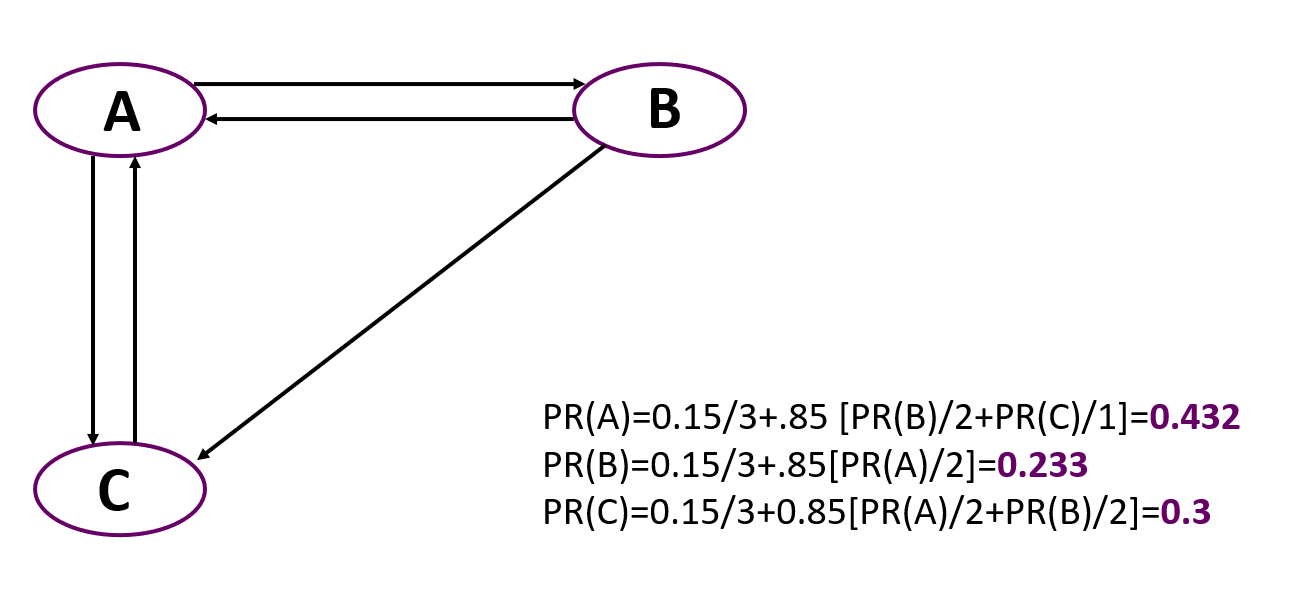
您可以看到这里最重要的是节点A,尽管事实上只有两个节点指向它,例如C。但是指向A的节点的等级高于导致C的节点的等级。
假设与解决方案
因此,PageRank描述了没有隐藏状态的马尔可夫过程。使用它,我们将始终找到每个节点的最终权重,但是我们将无法跟踪图中的变化。该算法非常好,我们能够对其进行调整并提高结果的准确性。为此,我们对PageRank进行了修改-个性化PageRank算法,该算法与基本算法有所不同,因为它始终会向有限数量的节点执行转换。也就是说,当用户厌倦了“遍历”链接时,他不会切换到随机节点,而是切换到给定集合之一。
在我们的例子中,图的节点将是用户请求。由于我们的算法应该为第二天的工作提供建议,因此我已经细分了每天针对每个运营商的所有请求。现在我们来建立一个图:如果类型B的搜索紧随类型A的搜索,则节点A连接到节点B,也就是说,对类型A的搜索是由用户在寻找路线B的那天之前进行的。例如:星期二(A)的“巴黎-布鲁塞尔”,以及星期三,“布鲁塞尔-科隆”(B)。而且某些用户每天发出大量请求,因此多个节点一次相互连接,结果,我们得到了非常复杂的图。
为了添加有关从一颗心转移到另一颗心的重要性的信息,我们添加了图形边缘的权重。 A-B边的权重是用户在搜索A之后搜索B的次数。考虑到查询的年龄也很重要,因为用户可以更改其模板:他可以移动或重组主要的运输方式,此后他又不想空着卡车去了。因此,您需要监视路由的历史记录-我们添加了reency参数,这也会影响节点的权重。
值得考虑季节性因素:例如,我们可能知道,承运人经常在9月去法国,而在10月则去德国。因此,在某个月中,可以给“受欢迎”的心脏更多的重量。另外,我们依赖于有关用户上次搜索内容的信息。这有助于间接猜测卡车的位置。
结果
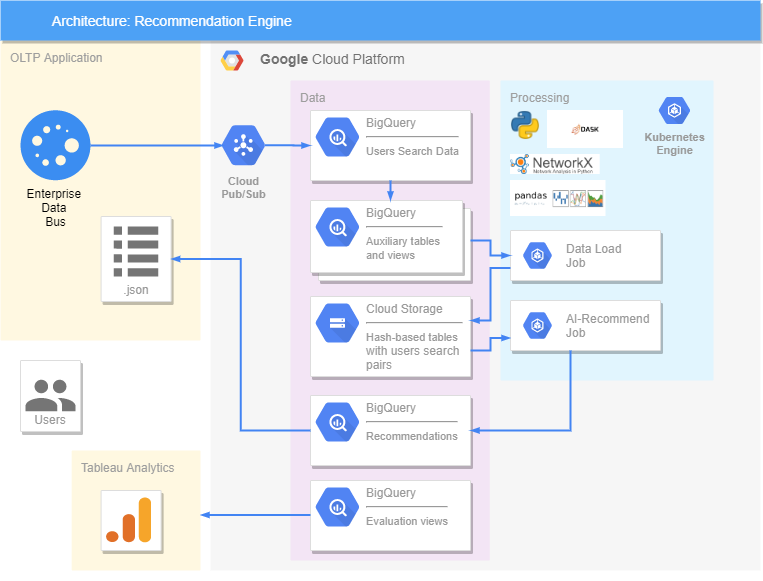
一切都在Google平台上实现。我们有一个OLTP应用程序,查询数据往返于此,并到达BigQuery,在那里形成包含已处理信息的其他视图和表。 DASK库用于加速和并行化大量数据的处理。在我们的解决方案中,所有数据都被传输到Cloud Storage,因为DASK仅与之配合使用,并且不与BigQuery交互。在Kubernetes中创建了两个作业,其中一个将数据从BigQuery传输到Cloud Storage,第二个提出建议。它的工作方式是这样的:Job从Cloud Storage中获取有关心对的数据,对其进行处理,为接下来的一天生成建议,然后将其发送回BigQuery。从那里,已经是.json格式,我们可以将建议发送到OLTP应用程序,用户将在其中看到它们。在Tableau中评估推荐的准确性,在此将我们的推荐与用户以后实际寻找的内容以及他的反应(喜欢与否)进行比较。
当然,我想分享结果。例如,这里有一个用户每天制作14个国家/地区的心脏。我们还向他推荐了相同的金额:
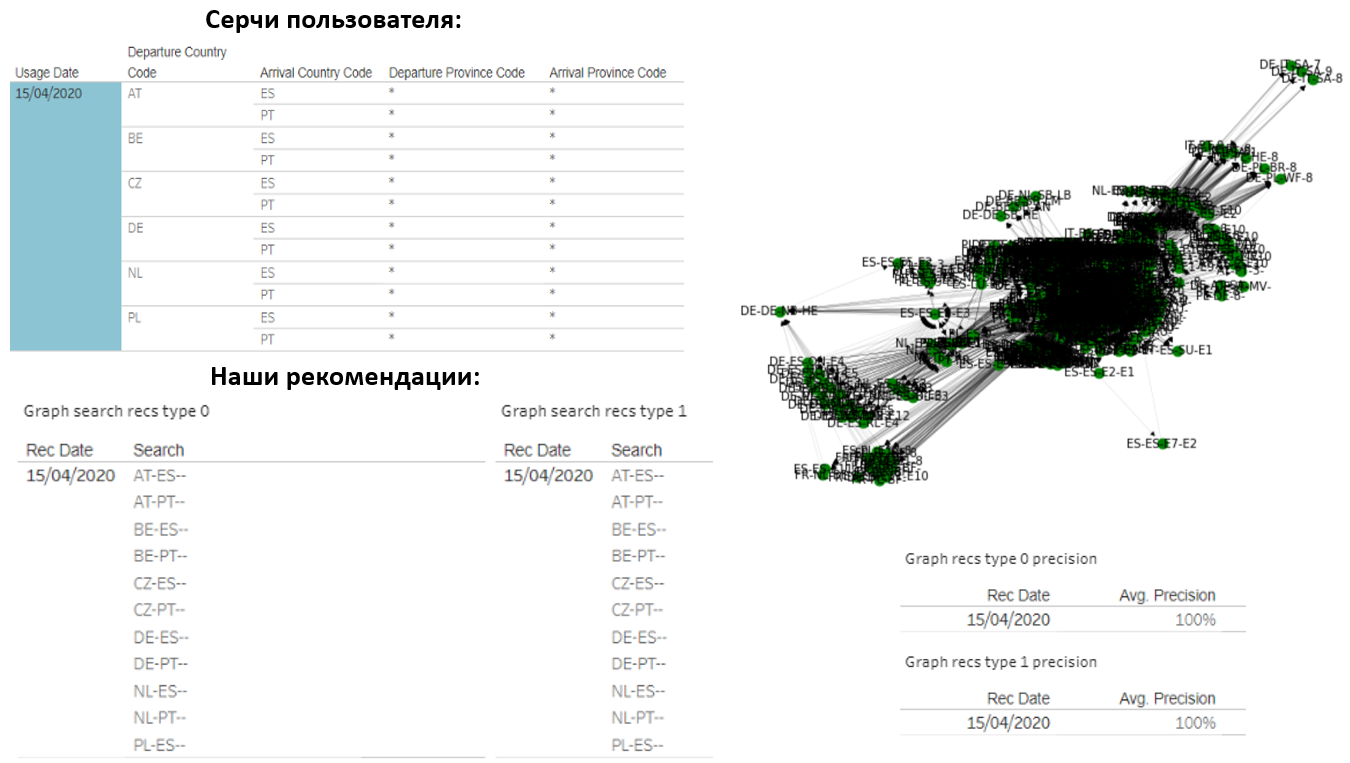
事实证明,我们的选择完全符合他的需求。该用户的图表包含大约1000个不同的请求,但我们设法非常准确地猜测出他会感兴趣的内容。
第二个用户平均每2天提出8个不同的请求,并且他以“国家/地区”格式进行搜索,并显示特定的出发区域。此外,出发和交付的国家完全不同。因此,我们无法“猜测”所有结果,结果的准确性降低了:

请注意,用户有2个权重不同的图。在其中一项中,准确度达到了38%,这意味着我们推荐的8个选项中有3个是相关的。而且,也许,如果我们在这些方向上找到载荷,则用户会选择它们。
最后也是最简单的示例。一个人每天大约进行2次搜索。它具有非常稳定的模式,没有太多的首选项,并且具有简单的图形。结果,我们的预测准确性为100%。

实际表现
- 我们的算法在4个标准CPU和10 GB内存上运行。
- 数据量高达10亿条记录。
- 为大约20,000个所有用户创建建议需要18分钟。
- DASK库用于并行化,而NetworkX库用于PageRank算法。
我可以说我们的搜索和实验已经取得了很好的结果。以图表的形式呈现货运平台用户的行为,并使用PageRank,这使我们能够准确地预测他们的未来偏好,从而建立有效的推荐系统。