
贵公司是否希望在不牺牲隐私的情况下收集和分析数据以研究趋势?也许您已经使用各种工具来保存它,并想加深您的知识或分享您的经验?无论如何,这种材料适合您。
是什么促使我们开始撰写本系列文章?NIST(美国国家标准技术研究院)去年推出了隐私工程协作空间-一个合作平台,其中包含开源工具,以及系统机密性设计和风险管理所需的解决方案和过程描述。作为此空间的主持人,我们帮助NIST在匿名化领域收集可用的差异隐私工具。 NIST还发布了“隐私权框架:通过企业风险管理改善隐私权的工具”和概述了一系列隐私权问题(包括匿名化)的行动计划。现在,我们希望帮助Collaboration Space实现计划中设定的匿名化(取消标识)目标。最终,帮助NIST将这一系列出版物发展成更深入的差异性隐私指南。
每篇文章都将从基本概念和应用示例开始,以帮助专业人员(例如业务流程所有者或数据隐私官)学习足够多的知识,以至于变得危险(开玩笑)。在回顾了基础知识之后,我们将分析可用的工具及其中使用的方法,这对于从事特定实现工作的人员而言已经很有用。
我们将通过描述关键概念和差异隐私的概念来开始我们的第一篇文章,我们将在后续文章中使用它们。
问题的提法
您如何在不影响特定人群的情况下研究人口数据?让我们尝试回答两个问题:
- 佛蒙特州有多少人居住?
- 佛蒙特州有多少人叫Joe Near?
第一个问题涉及整个人口的财产,第二个问题披露有关特定人的信息。我们需要能够确定整个人群的趋势,同时不允许出现有关特定个人的信息。
但是我们如何回答“佛蒙特州有多少人居住”这个问题? -我们将其进一步称为“查询”-不回答第二个问题“佛蒙特州有多少人叫乔·尼尔(Joe Nier)”?最常见的解决方案是去识别(或匿名化),即从数据集中删除所有识别信息(以下,我们认为我们的数据集包含有关特定人员的信息)。另一种方法是只允许聚合查询,例如,取平均值。不幸的是,现在我们已经知道,没有一种方法可以提供必要的隐私保护。匿名数据是与其他数据库建立链接的攻击目标。只有在采样组的大小为足够大。但是即使在这种情况下,成功的攻击也是可能的[1,2,3,4]。
差异隐私
差异隐私[5,6]是“具有隐私”概念的数学定义。它不是一个特定的过程,而是一个过程可以拥有的属性。例如,您可以计算(证明)给定的流程符合差异隐私原则。
简而言之,对于每个数据都在要分析的数据集中的人,无论您的数据是否在数据集中,差异隐私都可以确保差异隐私分析的结果几乎是无法区分的。差异隐私分析通常被称为一种机制,我们将其称为...
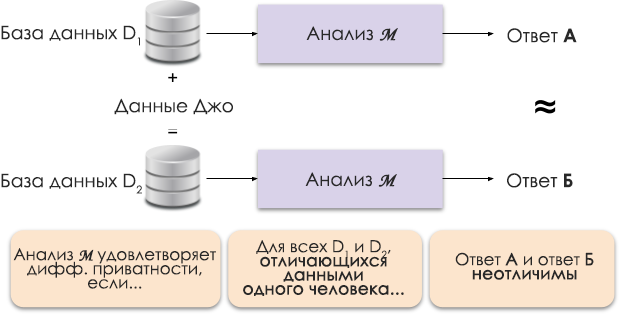
图1:差异隐私的示意图。
差异隐私的原理如图1所示。答案A是在没有乔的数据的情况下计算的,答案B是在他的数据的情况下计算的。有人认为这两个答案是无法区分的。也就是说,无论查看结果的人如何,都无法分辨是在哪种情况下使用了Joe的数据,以及在哪种情况下没有使用。
我们通过更改隐私参数ε(也称为隐私损失或隐私预算)来控制所需的隐私级别。 ε值越小,结果的可分辨性就越小,个人数据的安全性就越高。
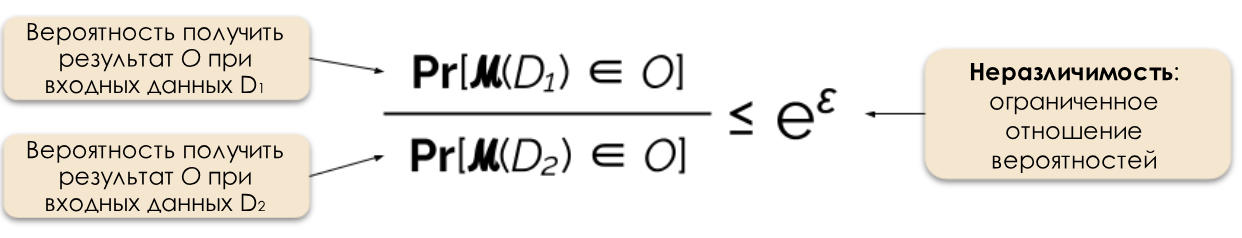
图2:差异隐私的正式定义。
通常,我们可以通过在响应中添加随机噪声来响应具有不同隐私的请求。困难在于准确确定要添加噪声的位置和数量。最受欢迎的噪声噪声机制之一是拉普拉斯机制[5,7]。
越来越多的隐私请求需要更多的噪声来满足差分隐私的特定epsilon值。而且,这种额外的噪音会降低所得结果的实用性。在以后的文章中,我们将更详细地介绍隐私以及隐私与实用程序之间的权衡。
差异隐私的好处
与以前的技术相比,差异隐私具有几个重要的优点。
- , , ( ) .
- , .
- : , . , . , .
由于这些优点,在实践中应用差异性隐私方法比其他一些方法更可取。不利的一面是这种方法是相当新的,在学术研究界之外很难找到可靠的工具,标准和可靠的方法。但是,我们认为,由于对保护数据隐私的可靠而简单的解决方案的需求不断增长,这种情况将在不久的将来得到改善。
下一步是什么?
订阅我们的博客,很快我们将发布下一篇文章的译文,其中介绍了构建差异性隐私系统时必须考虑的威胁模型,并讨论了差异性隐私的中央模型与本地模型之间的差异。
资料来源
[1] Garfinkel,Simson,John M. Abowd和Christian Martindale。“了解对公共数据的数据库重建攻击。” ACM通讯62.3(2019):46-53。
[2] Gadotti,Andrea等。“当信号进入噪声时:利用diffix的粘性噪声。” 第28届USENIX安全研讨会(USENIX Security 19)。2019
[3]迪努尔,IRIT,和Kobbi尼辛。“在保留隐私的同时显示信息。” 关于数据库系统原理的第二十二届ACM SIGMOD-SIGACT-SIGART研讨会论文集。2003。
[4] Sweeney,Latanya。“简单的人口统计通常可以唯一地识别人。” 卫生(旧金山)671(2000):1-34。
[5] Dwork,辛西娅等。“在私有数据分析中校准噪声敏感性。” 密码学会议理论。斯普林格,柏林,海德堡,2006年。
[6]伍德,亚历山德拉,米卡·奥特曼,亚伦·本贝内克,马克·本,马克·加贝蒂,詹姆斯·洪纳克,科比·尼西姆,大卫·奥布莱恩,托马斯·斯坦克和萨里尔·瓦丹。«差异性隐私:非技术受众的入门读物。»范。J.Ent。和技术。L. 21(2018):209。
[7] Dwork,辛西娅和亚伦·罗斯。“差异隐私的算法基础。” 理论计算机科学的基础和趋势,第9卷,第1期。3-4(2014):211-407。