
团队为游戏中的每个变更投入了大量的工作,精力和资源:有时开发新功能或关卡需要花费几个月的时间。分析师的任务是最大程度地降低引入此类更改的风险,并帮助团队对项目的进一步开发做出正确的决定。
在分析决策时,重要的是要根据与受众的喜好相匹配的具有统计意义的数据,而不是直观的假设来进行指导。A / B测试有助于获取此类数据并进行评估。
A / B测试的6个“简单”步骤
对于搜索词“ A / B测试”或“拆分测试”,大多数资料来源提供了一些“简单”步骤即可成功进行测试。我的策略中有六个这样的步骤。
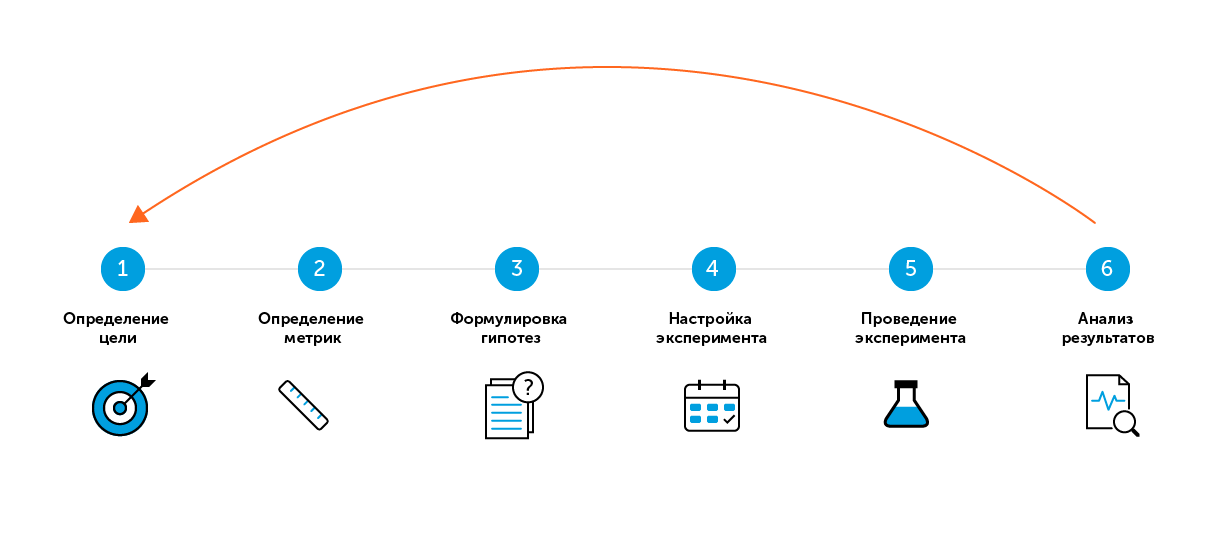
乍一看,一切都很简单:
- 有A组,控制权,比赛没有变化;
- 有B组,测试,有更改。例如,添加了新功能,增加了难度,更改了教程;
- 运行测试,看看哪个变体具有更好的性能。
实际上,这更加困难。为了使团队实施最佳解决方案,我作为分析师需要回答我对测试结果的信心如何。让我们逐步解决困难。
步骤1.确定目标
一方面,我们可以测试每个团队成员想到的所有内容-从按钮的颜色到游戏的难度级别。在设计阶段,进行拆分测试的技术能力已纳入我们的产品中。
另一方面,重要的是根据对目标指标的影响程度,对所有改善游戏的建议进行优先排序。因此,我们首先拟定一个计划,以从最高优先级假设到最低优先级假设进行分割测试。
我们尽量不要并行运行多个A / B测试,以便准确了解哪些新功能影响了目标指标。似乎采用这种策略,将需要更多时间来检验所有假设。但是优先级划分有助于在计划阶段切断毫无根据的假设。
我们获得的数据最能反映特定更改的效果,并且我们不会浪费时间设置具有可疑效果的测试。
我们绝对会与团队讨论发布计划,因为关注重点会在产品生命周期的不同阶段转移。在项目开始时,通常是Retention D1(保留D1)-游戏安装后第二天返回游戏的玩家百分比。在以后的阶段,这些可以是保留或获利指标:转化,ARPU等。
例。将项目发布到软启动后,保留指标需要特别注意。在此阶段,让我们重点说明一个可能的问题:保留D1尚未达到特定游戏类型的公司基准水平。有必要分析通过第一级的漏斗。假设您注意到在开始和第3级完成之间有大量的玩家-第3级的完成率较低。
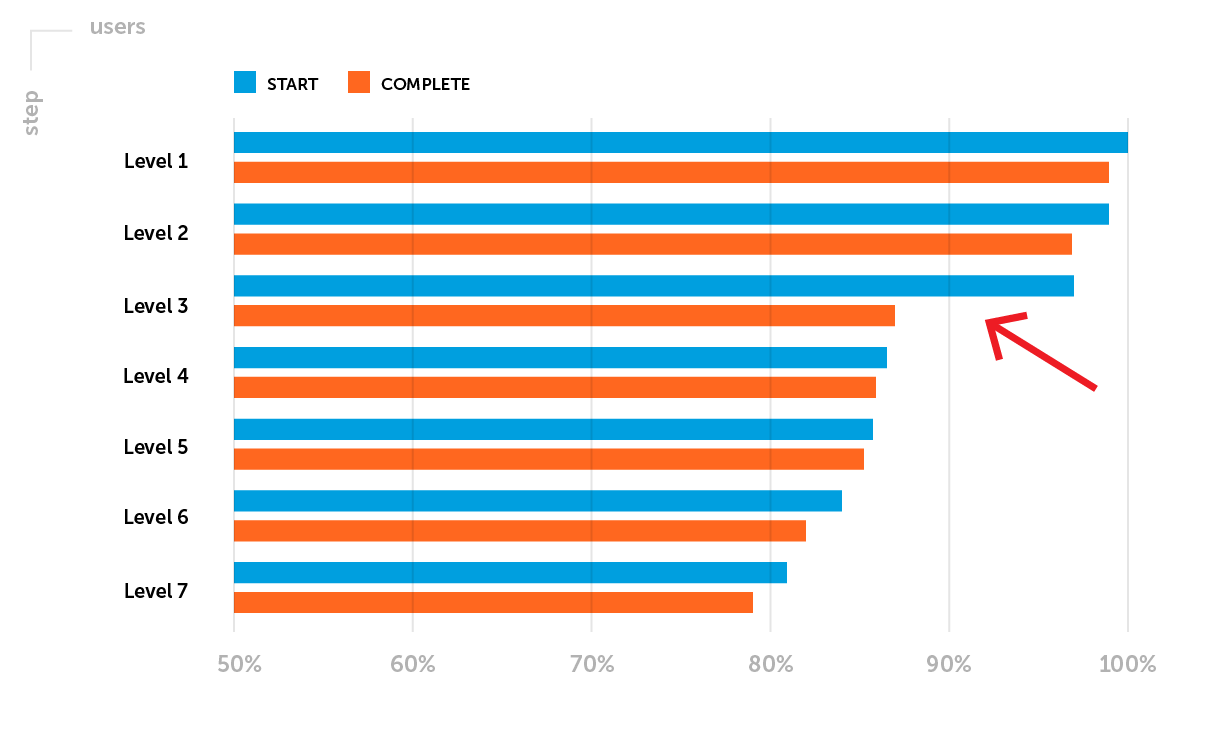
计划的A / B测试的目标是:通过增加成功完成3级水平的玩家的比例来增加保留率D1。
步骤2.定义指标
在开始A / B测试之前,我们需要确定受监控的参数-我们选择指标,更改后的指标将显示游戏的新功能是否比原始功能更成功。
有两种类型的指标:
- 定量的-会话的平均持续时间,平均检查的值,完成级别所需的时间,经验的数量等等;
- 质量-保留率,转化率等。
度量的类型影响评估结果的重要性的方法和工具的选择。
经过测试的功能可能不会影响一个目标,而是会影响许多指标。因此,我们通常观察变化,但是在评估目标指标没有统计学意义时不要尝试找到“任何东西”。
根据第一步的目标,对于即将到来的A / B测试,我们将评估第三级的完成率-一种定性指标。
步骤3.提出假设
每个A / B检验都会测试一个一般假设,该假设在发布前就已制定。我们回答这个问题:我们期望测试组有哪些变化?措词通常看起来像这样:
“我们希望(影响)会导致(改变)”
统计方法的工作方式相反-我们无法使用它们来证明假设是正确的。因此,在提出一般假设之后,确定了两个统计假设。他们有助于理解,对照组A和测试组B之间观察到的差异是事故或变更的结果。
在我们的示例中:
- 零假设(H0):降低级别3的难度不会影响成功完成级别3的用户的比例。A组和B组的3级完成率并没有真正的差异,并且观察到的差异是随机的。
- 替代假设(H1):降低级别3的难度将增加成功完成级别3的用户比例。B组的3级完成率高于A组,而这些差异是变化的结果。
在这一阶段,除了提出假设外,还必须评估预期的效果。
假设:“我们预计,降低3级难度会导致3级完成率从85%提高到95%,即超过11%。”
(95%-85%)/ 85%= 0.117 => 11.7%
在此示例中,当确定级别3的预期完成率时,我们的目标是使其与起始级别的平均完成率更接近。
第4步:设置实验
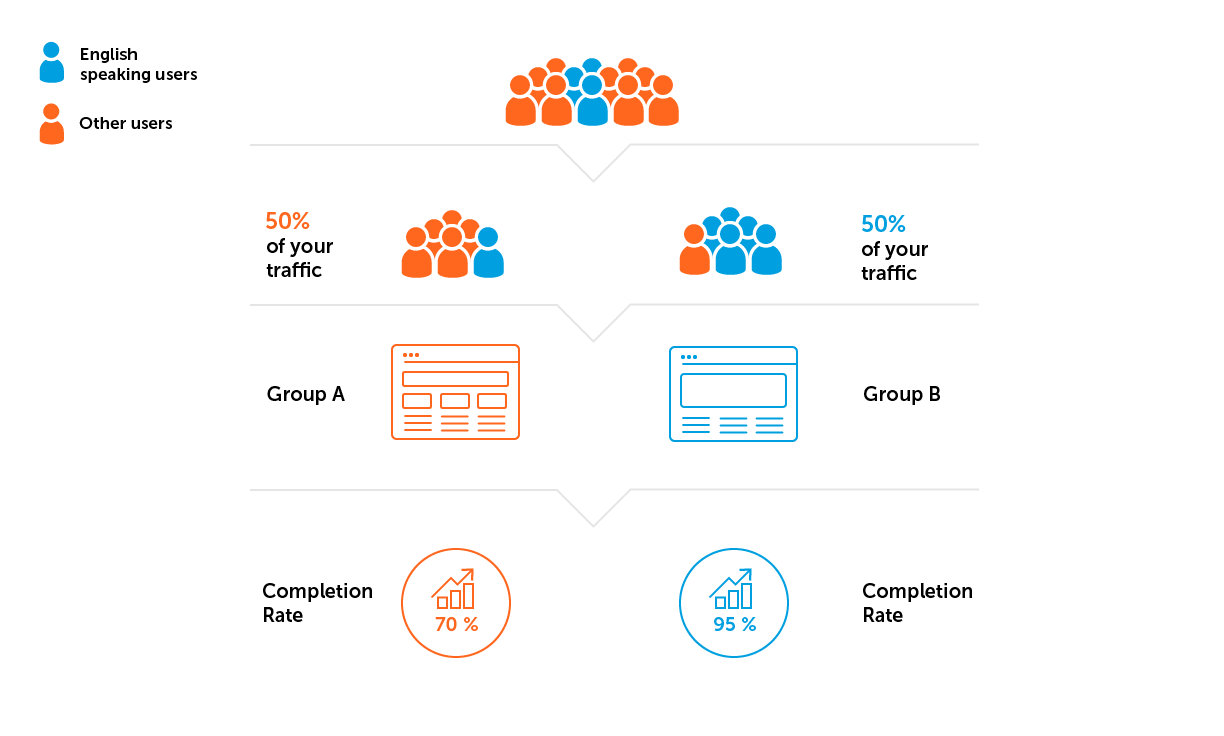
1.在开始实验之前,为A / B组定义参数:我们向哪个受众发起测试,针对哪个玩家比例,在每个组中设置哪些设置。
2.我们检查样本整体的代表性和各组样本的均质性。您可以预先运行A / A测试以评估这些参数-测试中,测试组和对照组具有相同的功能。 A / A测试有助于确保两组的目标指标在统计上均没有显着差异。如果存在差异,则无法运行具有此类设置(样本大小和信任级别)的A / B测试。
样本并不能完全代表,但我们始终会根据用户的特征(新/旧用户,游戏级别,国家/地区)关注用户的结构。一切都取决于A / B测试的目的,并且需要事先协商。每个组中的用户结构在条件上相同是很重要的。
这里有两个潜在的危险陷阱:
- 实验期间,分组中的高指标可能是吸引良好流量的结果。如果参与率很高,则流量很好。错误的流量是指标下降的最常见原因。
- 样本异质性。假设我们的示例中的项目是为讲英语的听众开发的。这意味着我们需要避免出现以下情况:来自英语不占主导地位的国家/地区的更多用户将属于其中一个群体。
3.计算样本量和实验时间。
考虑到庞大的在线计算器,这一刻似乎是透明的。
但是,使用它们需要输入特定的初始信息。要选择适当的在线计算器选项,请记住数据类型并理解以下术语。
- 普通人群-将来将向其分发A / B测试结论的所有用户。
- 示例-实际经过测试的用户。根据样本分析的结果,得出有关整个普通人群行为的结论。
- , . — , , , .
- , . .
- (α) — , (0), .
- (1-α) — , , .
- (1-β) — , , .
这些参数的组合使您可以计算每组所需的样本量和测试时间。
在在线计算器中,您可以使用输入数据来了解它们之间关系的性质。
一个例子。让我们使用Optimizely计算器计算转换率为1%的样本量。考虑在95%的置信水平下预期效果大小为5%(指标计算为1-α)。请注意,在此计算器的界面中,术语统计显着性用于表示显着性水平为5%的“置信度”。
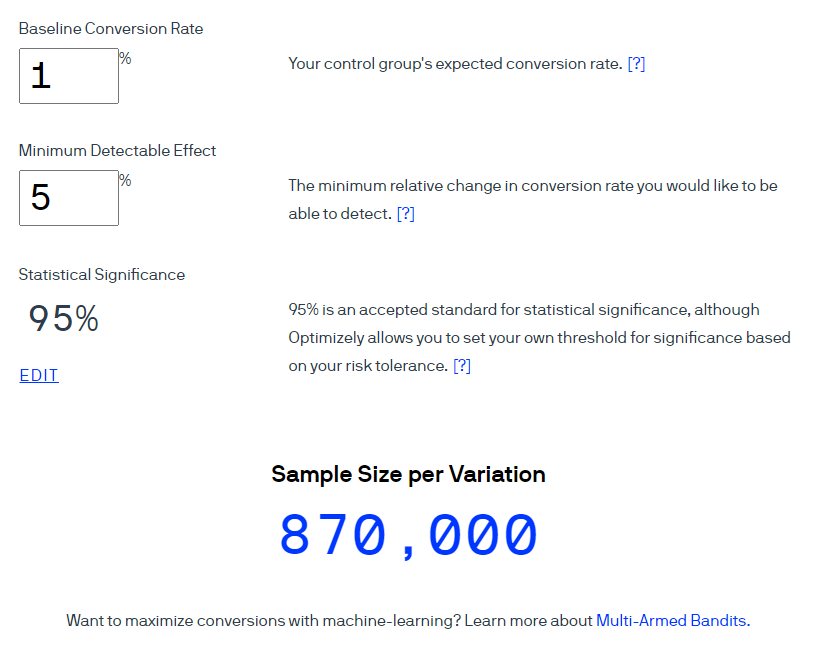
优化声称每个组中应包含870,000个用户。
将样本量转换为近似测试持续时间-两个简单的计算。
计算编号1.样本数量×实验中的组数=所需的用户总数
计算编号2.所需的用户总数÷每天的平均用户数=实验的近似天数
如果第一组需要870,000用户,则对于两个选项的测试总数用户数将达到1,740,000。考虑到每天1,000名玩家的访问量,测试应持续1,740天。此持续时间不合理。在此阶段,我们通常会修改假设,基准数据和测试的适当性。
在我们的第3级改善示例中,转化率是成功完成第3级的人数所占的比例。也就是说,转化率为85%,我们希望将该指标至少提高11%。有了95%的信任度,我们每个组获得130个用户。

在拥有1000位用户的相同流量下,粗略地说,该测试可以在不到一天的时间内完成。这个结论从根本上是错误的,因为它没有考虑到每周的季节性。用户行为在一周的不同日期有所不同,例如,在假期可能会有所不同。在某些项目中,这种影响非常明显,而在另一些项目中,这种影响几乎不明显。这不是在所有项目中也不是所有测试中都必需的条件,但是在我参与过的项目中,始终会观察到KPI每周都会季节性变化。
因此,考虑到季节性,我们将测试持续时间四舍五入到几周。通常,我们的测试周期为一到两周,具体取决于A / B测试的类型。
步骤5.进行实验
运行A / B测试后,您立即想查看结果,但是大多数资料来源都严格禁止这样做,以消除偷看问题。我认为用简单的话来解释问题的实质,到目前为止,还没有人成功。这些文章的作者基于对概率的评估以及各种数学建模结果,从而使读者进入“复杂数学公式”区域。他们的主要结论是一个几乎无可争辩的事实:在输入所需样本之前以及开始测试后经过规定天数之前不要查看数据。结果,许多人误解了“偷窥”问题,并从字面上遵循建议。
我们已经设置了流程,以便我们可以查看每天用于监视项目KPI的相关数据。在预先准备好的仪表板中,我们从一开始就跟踪实验的进度:我们检查各组的招募是否均匀,开始测试后是否存在任何可能影响结果的关键问题,等等。
主要规则是不要得出过早的结论。所有结论均根据A / B测试的规定设计得出,并在详细报告中进行了总结。自A / B测试启动以来,我们一直在监控指标的变化。
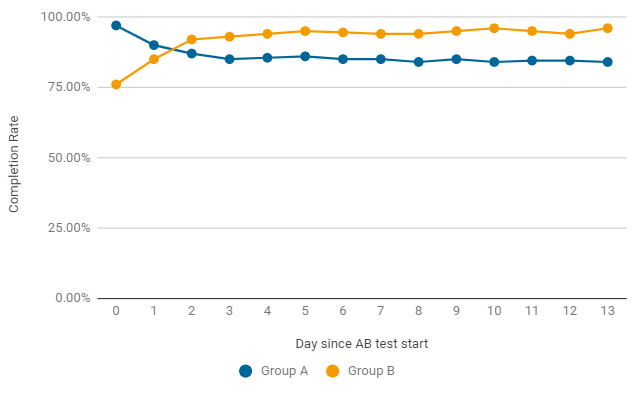
例如,在A / B测试中,完成率可以每天变化。在发布后的前两天,该游戏变体获胜而没有发生变化(A组),但事实证明这只是偶然。第二天之后,B组中的指标始终获得更好的结果。要完成测试,它不仅需要统计显着性,而且还需要稳定性,因此我们正在等待测试结束。
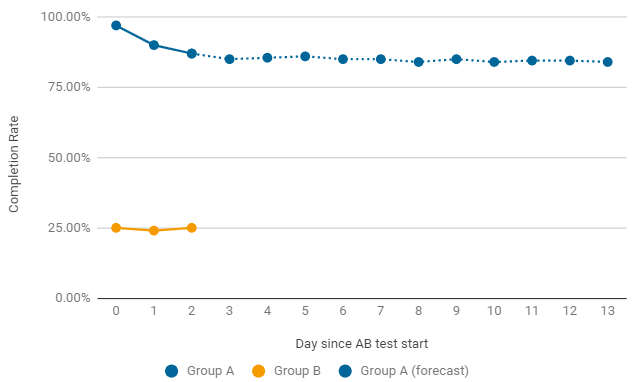
一个值得何时过早结束A / B测试的示例。如果在发布后其中一组给出了极低的费率,我们会立即寻找造成这种下降的原因。最常见的错误是游戏级别的配置和设置。在这种情况下,当前测试会过早终止,并开始进行新的修复。
步骤6.分析结果
关键指标的计算不是特别困难,但是评估所获得结果的重要性是一个单独的问题。
在评估质量指标(例如保留率和转化率)时,可以使用在线计算器来测试结果的统计显着性。
我的前3个在线计算器可完成以下任务:
- Evan的A / B工具是最受欢迎的工具。它实现了几种评估测试重要性的方法。使用时,您需要清楚地了解每个输入参数的本质,独立地解释结果并得出结论。
- , A/B Testguide. , . — , .
- A/B Testing Calculator Neilpatel. -, .
一个例子。为了分析此类A / B测试,我们有一个仪表板,可显示得出结论所需的所有信息,并自动突出显示目标发生重大变化的结果。

让我们看看如何使用计算器得出有关此A / B测试的结论。
初始数据:
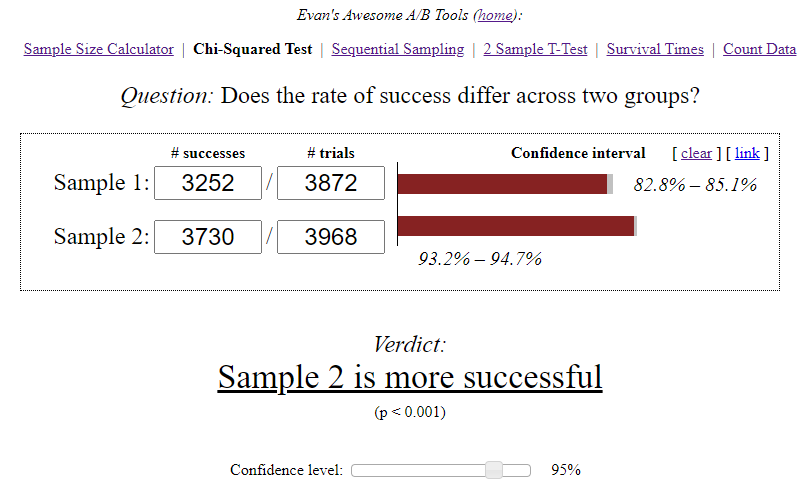
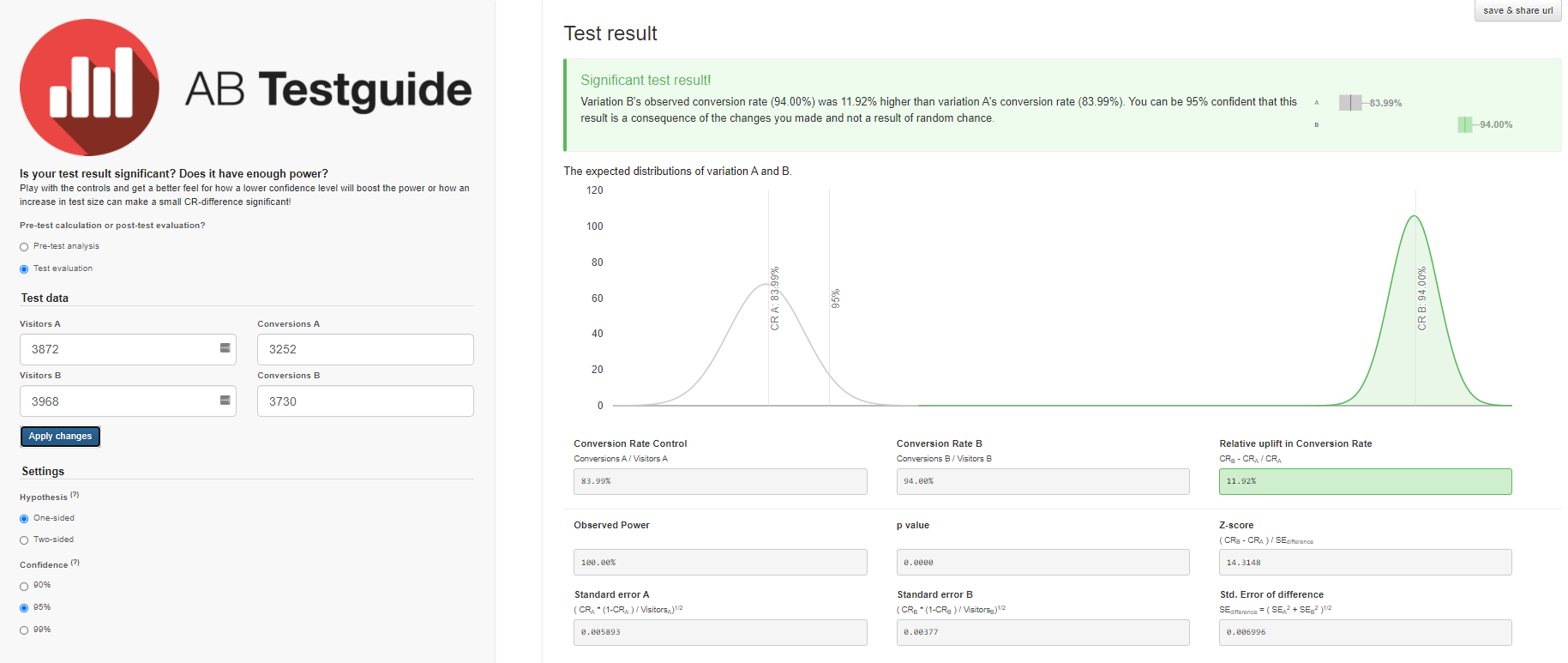
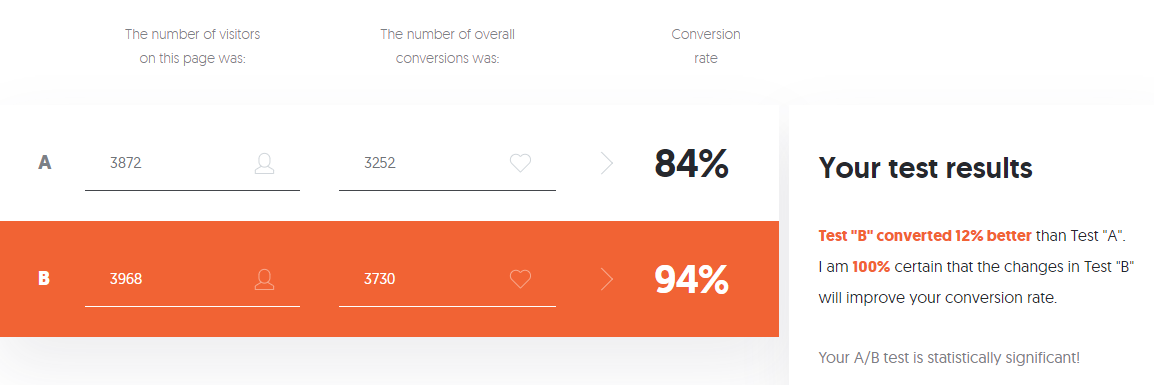
- 在A组中,在开始第3级的3870位用户中,只有3252位用户成功通过了考试-这是84%。
- 在B组中,在3968位用户中,有3730位成功通过了该级别的测试,即94%。
Evan的A / B工具计算器计算出每个选项的置信区间,同时考虑了样本量和所选的显着性水平。
独立结论:
- A — 84,00%, 82,8%—85,1%. B — 94,00%, 93,2%—94,7%. (94%-84%)/84% = 0,119 => 12%
- 12% , A. — , . 95%.
- .
我们将使用A / B Testguide计算器获得类似的结果。但是在这里您已经可以进行设置,获取图形结果和公式化的结论。
如果您担心这么多设置,不需要或不需要处理计算器计算出的各种数据,则可以使用Neilpatel的A / B测试计算器。
每个在线计算器都有自己的标准和算法,可能没有考虑到实验的所有功能。结果,在结果的解释中出现疑问。另外,如果目标指标是定量的-平均检查或第一次会话的平均时间-列出的在线计算器将不再适用,并且需要更高级的评估方法。
我针对每个A / B测试起草了详细的报告,因此,我已经选择并实施了适合我任务的方法和标准,以评估结果的统计显着性。
结论
A / B测试是一种工具,它不能对“哪个选项更好?”这一问题给出明确的答案,而只能使您减少寻找最佳解决方案的不确定性。进行此操作时,细节在准备的所有阶段都很重要,每个不准确性都会浪费资源,并且可能会对结果的可靠性产生负面影响。希望本文对您有所帮助,并帮助您避免A / B测试中的错误。