
URALCHEM生产肥料。俄罗斯排名第一-例如,用于生产硝酸铵的氨,尿素和氮肥在国内生产商中排名前三位。生产硫酸,二三组分肥料,磷酸盐等。所有这些都创建了传感器失效的激进环境。
我们构建了Data Lake,并同时寻找那些冻结,失效,开始提供虚假数据且通常行为与信息源行为不同的传感器。而且,“技巧”是不可能基于“不良”数据建立数学模型和数字孪生:它们根本无法正确解决问题并产生业务效果。
但是现代工厂需要数据湖来吸引数据科学家。在95%的情况下,不会以任何方式收集“原始”数据,而只考虑过程控制系统中的聚集体,这些聚集体会存储两个月,并且会存储指标的“动态变化”点,这是通过专门制定的算法计算得出的,对于数据科学家而言,这会降低数据质量,因为……可能会错过指标的“爆发”……实际上,这种情况发生在URALCHEM。有必要创建一个生产数据仓库,在车间和MES / ERP系统中提取源。首先,这是开始收集数据科学历史的必要条件。其次,让数据科学家拥有一个用于计算的平台和一个用于测试假设的沙箱,而不必在过程控制系统正在旋转的情况下加载同一平台。数据科学家试图分析可用数据,但这还不够。数据的存储抽取后会丢失,通常与传感器不一致。无法快速获取数据集,也没有地方可以使用它。
现在让我们回到传感器“驱动”时该怎么办。
当你建湖时
仅仅构建这样的东西还不够:
您还需要向业务证明一切都可行,并显示一个已完成项目的示例。显然,在这样一个联合体上进行一个项目是关于如何在一个国家建立共产主义,但条件恰恰是这样。我们使用显微镜,证明它们可以打钉子。
在全球范围内,URALCHEM的任务是数字化生产。作为所有这些动作的一部分,首先,创建一个沙箱来测试假设,提高生产过程的效率以及开发设备故障的预测模型,决策支持系统,从而减少停机时间并提高生产过程的质量。这是当您事先知道某事将要发生的时候,并且您可以在机器开始粉碎周围的所有东西之前一周进行修复。收益-降低生产成本并提高产品质量。
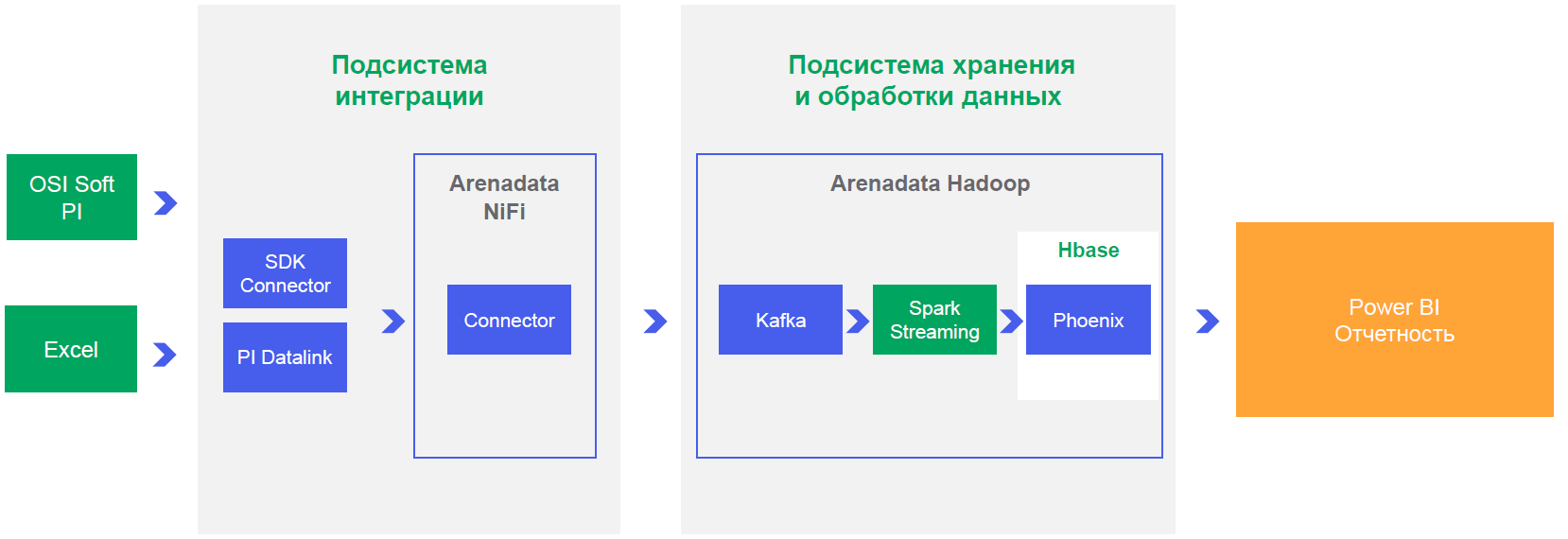
平台的标准和试点的基本要求就是这样出现的:存储大量信息,从商业智能系统在线访问数据,接近实时的计算以便尽快发布建议或通知。
我们设计出了集成选项,并意识到,要在NRT模式下实现性能和操作,您只需要通过连接器即可工作,该连接器会将数据添加到Kafka(水平可伸缩的消息代理,它仅允许您“订阅事件”以更改传感器读数,并基于即时进行此事件以进行计算并生成通知)。顺便说一下,URALCHEM JSC OTSO分公司生产系统开发部负责人Artur Khismatullin对我们有很大帮助。
例如,需要什么来建立设备故障的预测模型?
这要求实时地或以接近它的切片的方式从每个节点进行遥测。也就是说,不是每小时一次的一般状态,而是每秒钟直接读取所有传感器的特定读数。
没有人收集或存储此数据。而且,我们至少需要六个月的历史数据,并且正如我所说,在过程控制系统中,它们最多可以存储最近三个月。也就是说,您需要首先从一个地方收集数据,在某个地方写入并在某个地方存储数据这一事实开始。每年每个节点大约10 GB的数据。
此外,您将需要以某种方式使用此数据。这需要安装,该安装通常允许您从数据库中进行选择。理想的情况是,在复杂的join'ah上,一天之内一切都不会恢复。尤其是后来,当生产开始增加婚姻预测的更多问题时。好吧,对于预测性维修,还有一个晚上的报告说,机器在半小时前发生故障时可能会发生故障-一般。
结果,数据科学家需要湖泊。
与其他类似解决方案不同,我们仍然需要在Hadoop上实现实时任务。因为下一个重要任务是材料成分数据,物质质量分析,生产材料消耗。
实际上,当我们自己构建平台时,企业需要我们做的下一件事就是,我们收集有关传感器故障的数据,并构建一个系统,该系统允许我们派遣工人进行更改或维修。同时,这也标志着他们的证词在历史上是错误的。
感测器
在生产环境中-恶劣的环境中,传感器工作困难且经常出现故障。理想情况下,传感器还需要一个预测性监视系统,但首先,至少要评估哪些是谎言,哪些不是。
事实证明,即使是一个简单的确定传感器的功能的模型对于另一个任务-建立数学平衡也至关重要。正确的过程计划-需要投入多少和什么,如何加热,如何进行处理:如果计划有误,则不清楚需要多少原材料。生产的产品不足-企业将无法获利。如果有多余的余地-再次损失,因为您需要存储。正确的物料平衡只能从传感器的正确信息中获得。
因此,在我们的试点项目中,选择了生产数据质量监控。
我们与技术人员坐在一起,获取“原始”数据,查看确认的设备故障。前两个原因很简单。
在这里,传感器突然开始显示原则上不应该显示的数据:
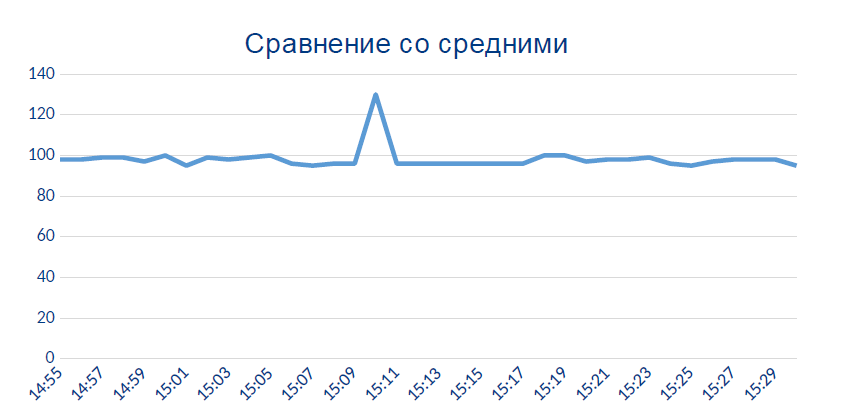
此局部峰值很可能是传感器因热或化学原因变坏的时刻。
还超出了允许的测量范围(当存在诸如水温从0到100的物理量时)。零时,水不会流过系统,而零时是水,这是蒸汽,我们会在车间没有屋顶的情况下注意到这一事实。
第二种情况也几乎是微不足道的:
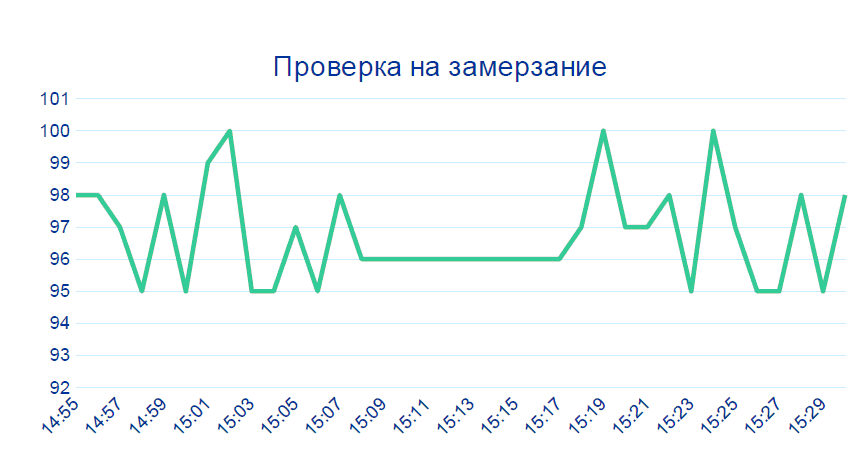
来自传感器的数据连续数分钟不会改变-在现场制作中不会发生这种情况。设备最有可能发生故障。
通过跟踪这些模式而没有任何大数据,关联性和数据历史记录,从而解决了80%的问题。但是要获得高于99%的准确度,则需要与相邻节点上的其他传感器进行另一次比较,尤其是在可疑遥测所涉及的部分之前和之后:
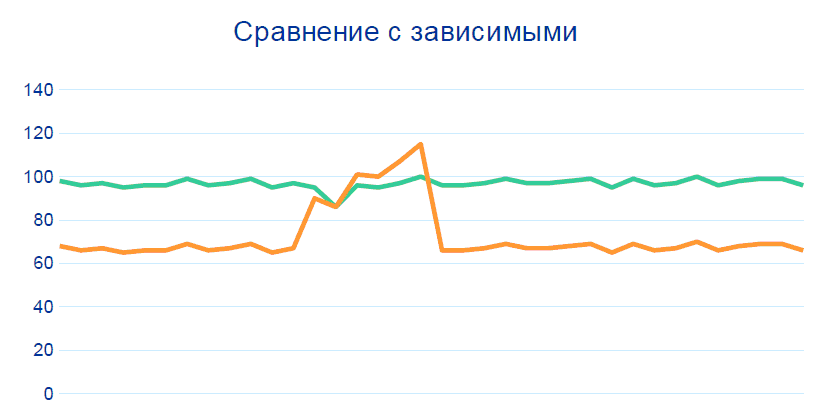
生产是一个平衡的系统:如果一个指示器发生变化,那么另一个指示器也必须发生变化。在该项目的框架内,形成了关于指标关系的规则,并且这些关系已由技术人员“标准化”。基于这些准则,基于Hadoop的系统可以识别潜在无法运行的传感器。
工厂操作员对传感器被正确检测感到高兴,因为这意味着他们可以迅速派遣维修人员或简单地清洁所需的传感器。
实际上,飞行员最终在商店中列出了显示错误信息的可能无法工作的传感器。
您可能会问,对紧急情况和紧急情况的响应是如何在项目实施之前实施的,以及在项目实施后如何实施。我会回答,对事故的反应不会减慢速度,因为在这种情况下,多个传感器会立即显示问题所在。
技术人员或部门负责人负责安装的效率(并在发生事故时采取措施)。他们完全了解他们的设备正在发生什么以及如何发生,并且知道如何忽略某些传感器。安装过程中的过程控制系统负责数据的质量。通常,当传感器损坏时,它不会进入非工作模式。对于技术人员,他仍然是工人;技术人员必须做出反应。技术人员检查事件并发现没有任何反应。看起来像这样:“我们只分析动力学,我们不看绝对,我们知道它们不正确,我们需要调整传感器。”我们向自动化过程控制系统的专家“突出”传感器错误以及错误位置。现在,他没有计划内的正式回合,而是有针对性地修理了特定设备,然后进行回合,对技术不信任。
为了更清楚地计划步行需要多长时间,我只想简单地说,每个站点都有三到五千个传感器。我们提供了一个全面的分析工具,可提供经过处理的数据,专家需要在此基础上做出验证决定。根据他的经验,我们“突出”了所需的内容。您不再需要手动检查每个传感器,从而减少了遗漏某些东西的可能性。
结果是什么
收到业务确认,该堆栈可用于解决生产问题。我们存储和处理站点数据。现在,企业必须选择以下流程以供数据科学家操作。当他们任命负责数据质量控制的人员时,为他制定法规并将其实施到生产过程中。
这就是我们实现这种情况的方式:
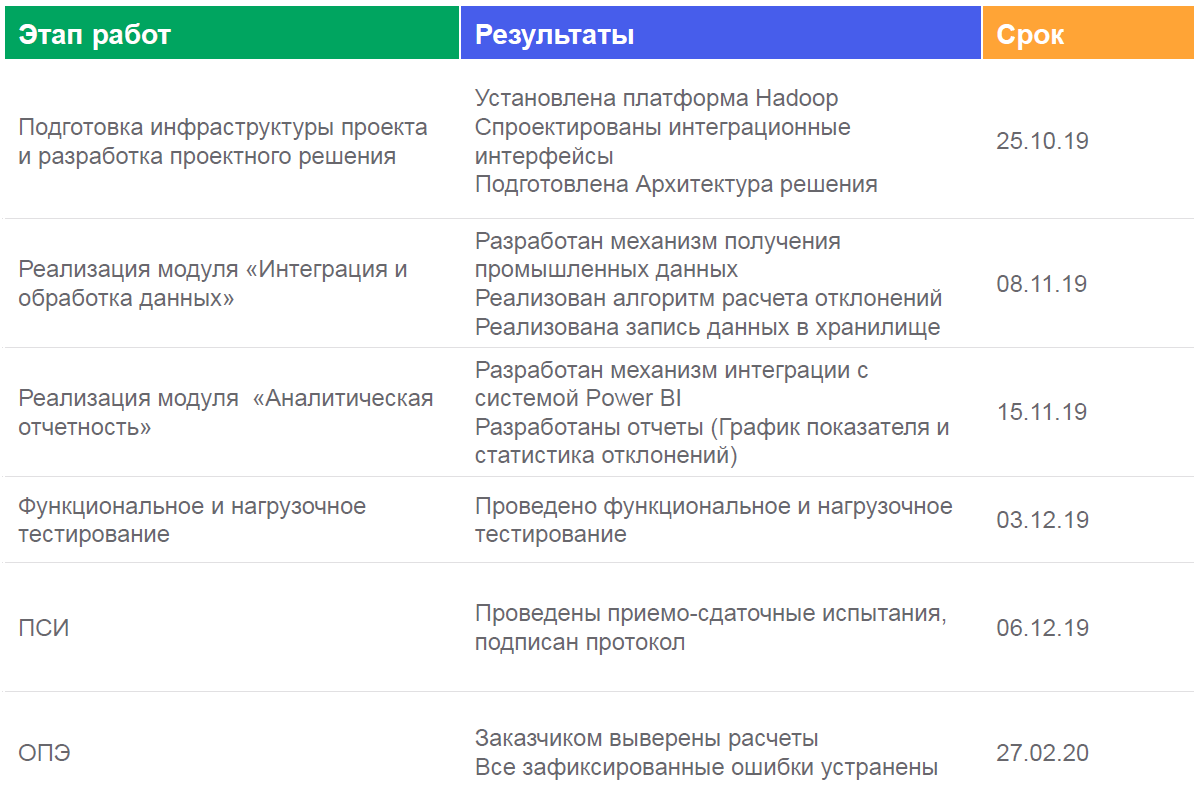
仪表盘看起来像这样:它们显示
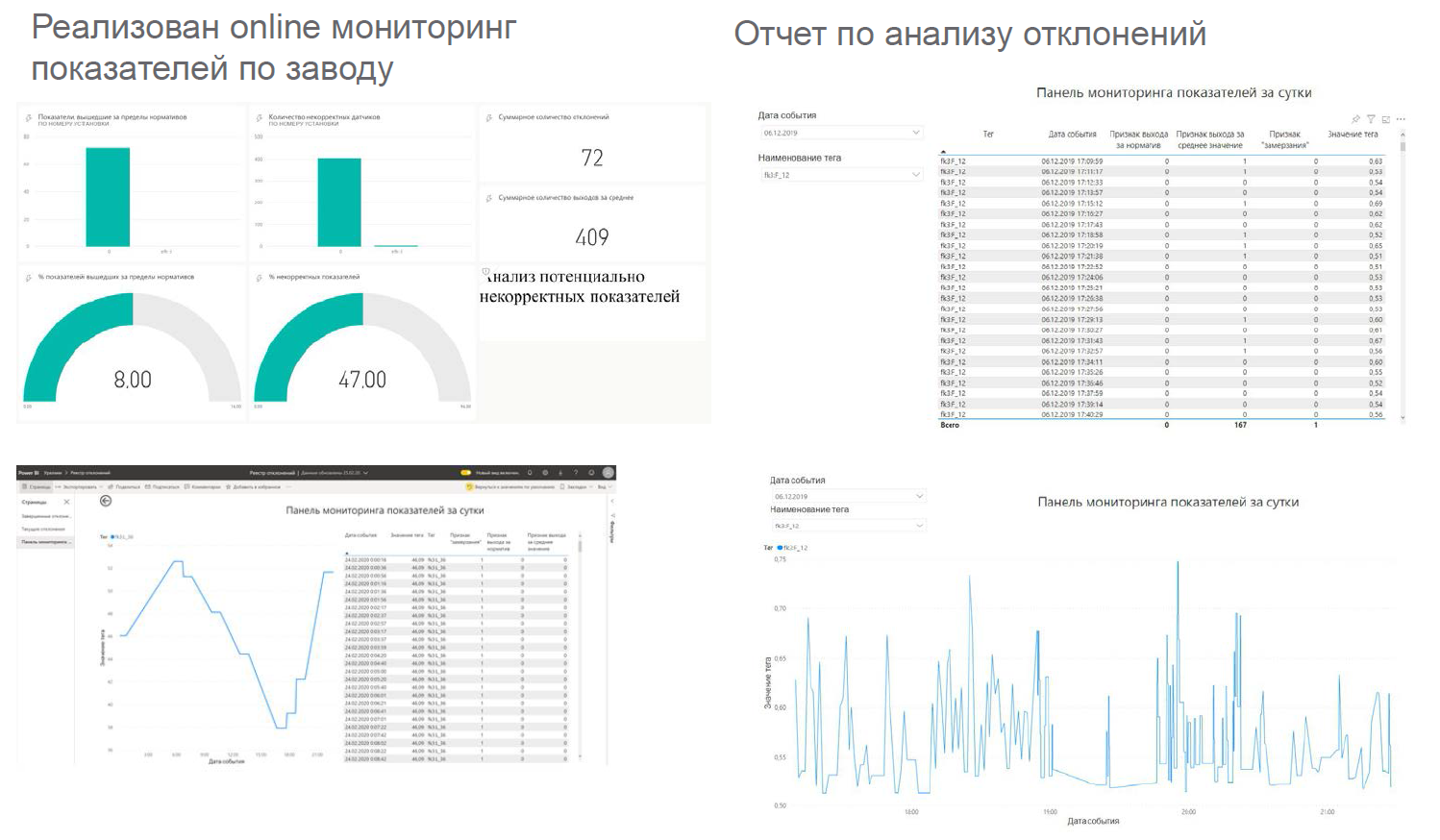
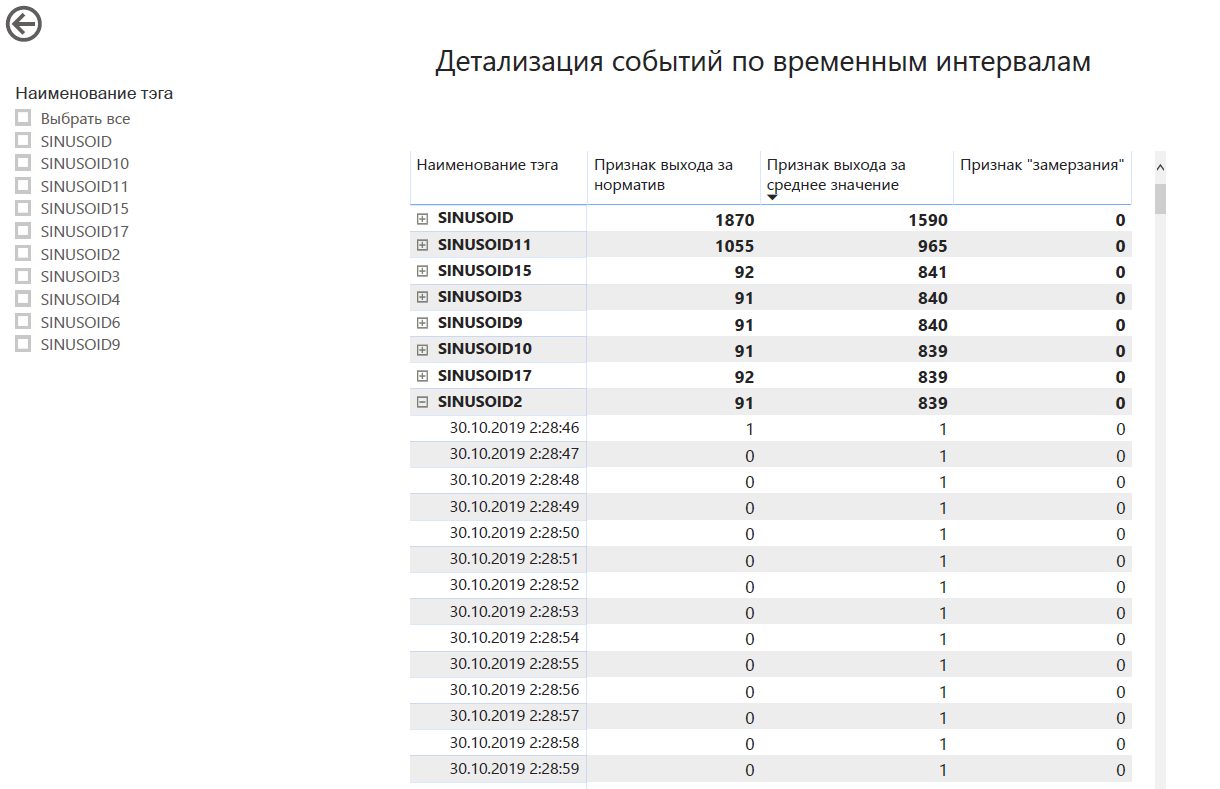
在以下位置:

我们拥有的东西:
- 在技术级别创建了一个信息空间,以处理设备传感器的读数;
- 验证了基于大数据技术存储和处理数据的能力;
- 测试了商务智能系统(例如Power BI)与基于Arenadata Hadoop平台构建的数据湖一起工作的能力;
- 引入了统一的分析存储,以从设备传感器收集生产信息,并可以长期存储信息(一年计划的累积数据量约为2 TB);
- 已经开发了用于以近实时模式获取数据的机制和方法;
- 已经开发出一种用于确定传感器在接近实时模式下的偏差和错误操作的算法(计算-每分钟一次);
- 测试了系统操作以及在BI工具中生成报告的能力。
最重要的是,我们已经解决了一个完全的生产问题-我们使例行程序自动化了。我们提供了一种预测工具,为技术人员腾出了时间来解决更智能的问题。
如果您还有其他疑问,请联系我们-chemistry@croc.ru