在本文中,我将探讨一个稍微复杂和有趣的主题(至少对我来说,搜索团队的开发人员):全文搜索。我们将在容器区域中添加一个Elasticsearch节点,学习如何建立索引并搜索内容,并以TMDB 5000电影数据集中的五千部电影的描述作为测试数据... 我们还将学习如何制作搜索过滤器并充分挖掘排名。
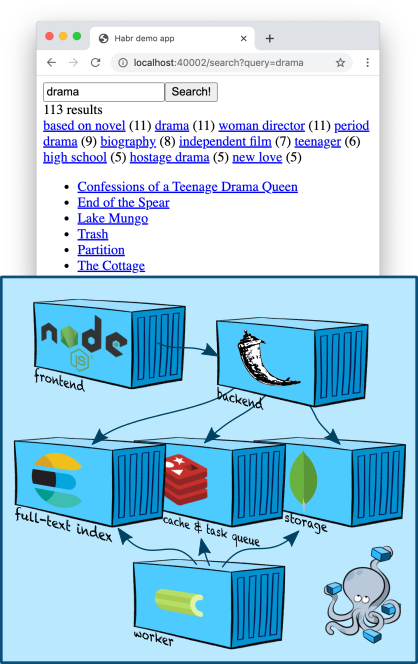
基础架构:Elasticsearch
Elasticsearch是一个流行的文档存储,可以建立全文索引,通常,它专门用作搜索引擎。Elasticsearch在Apache Lucene引擎的基础上增加了分片,复制,便捷的JSON API以及上百万个详细信息,使其成为最受欢迎的全文搜索解决方案之一。
让我们在我们的节点上添加一个Elasticsearch节点
docker-compose.yml:
services:
...
elasticsearch:
image: "elasticsearch:7.5.1"
environment:
- discovery.type=single-node
ports:
- "9200:9200"
...
环境变量
discovery.type=single-node告诉Elasticsearch为单独工作做准备,而不是寻找其他节点并将其合并到集群中(这是默认行为)。
请注意,即使我们的应用程序正在docker-compose创建的网络中导航,我们仍在向外发布端口9200。这纯粹是为了调试:通过这种方式,我们可以直接从终端访问Elasticsearch(直到我们提出了一种更智能的方式-下文中有更多介绍)。
在我们的连接中添加Elasticsearch客户并不难-好的,Elastic提供了一个简约的Python-client。
索引编制
在上一篇文章中,我们将主要实体-“卡片”放入了MongoDB集合中。我们可以按标识符从集合中快速检索其内容,因为MongoDB为我们建立了直接索引-为此它使用 B树。
现在我们面对的是逆任务-通过内容(或其片段)来获得卡的标识符。因此,我们需要一个反向索引。这是Elasticsearch派上用场的地方!
建立索引的一般方案通常是这样的。
- 使用唯一名称创建一个新的空索引,并根据需要进行配置。
- 我们遍历数据库中的所有实体,并将它们放入新索引中。
- 我们切换生产,以便所有查询都开始转到新索引。
- 删除旧索引。您可以随意在这里-存储最后几个索引,例如,这样可以更方便地调试一些问题。
让我们创建索引器的框架,然后在每个步骤中进行更详细的介绍。
import datetime
from elasticsearch import Elasticsearch, NotFoundError
from backend.storage.card import Card, CardDAO
class Indexer(object):
def __init__(self, elasticsearch_client: Elasticsearch, card_dao: CardDAO, cards_index_alias: str):
self.elasticsearch_client = elasticsearch_client
self.card_dao = card_dao
self.cards_index_alias = cards_index_alias
def build_new_cards_index(self) -> str:
# .
# .
index_name = "cards-" + datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
# .
# .
self.create_empty_cards_index(index_name)
# .
#
# .
for card in self.card_dao.get_all():
self.put_card_into_index(card, index_name)
return index_name
def create_empty_cards_index(self, index_name):
...
def put_card_into_index(self, card: Card, index_name: str):
...
def switch_current_cards_index(self, new_index_name: str):
...
索引编制:创建索引
Elasticsearch中的索引是由一个简单的PUT请求创建的,
/-或者在使用Python客户端(在我们的示例中)的情况下,通过调用
elasticsearch_client.indices.create(index_name, {
...
})
请求主体可以包含三个字段。
- 别名说明(
"aliases": ...)。别名系统使您可以了解Elasticsearch端当前最新的索引。我们将在下面讨论。 - 设置(
"settings": ...)。当我们是具有实际生产能力的大人物时,我们将能够在此处配置复制,分片和其他SRE功能。 - 数据模式(
"mappings": ...)。在这里,我们可以指定要索引的文档中的字段类型,需要反向索引的字段,需要支持的聚合等等。
现在,我们仅对该方案感兴趣,并且它非常简单:
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "english"
},
"text": {
"type": "text",
"analyzer": "english"
},
"tags": {
"type": "keyword",
"fields": {
"text": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
我们已将字段标记为
name,并将text其标记为英文文本。解析器是Elasticsearch中的一个实体,在将文本存储到索引之前对其进行处理。在english分析器的情况下,文本将沿单词边界(细节)分成多个标记,然后根据英语规则对单个标记进行词形修饰(例如,单词trees将简化为tree),太笼统的词缀(如the)将被删除,而其余的词缀将被放入反向索引中。
领域
tags有点复杂。一种keyword假设此字段的值是一些字符串常量,分析器不需要处理;逆索引将基于其``原始''值构建-无需分词化和词义化。但是Elasticsearch将创建特殊的数据结构,以便可以通过该字段的值读取聚合(例如,以便与搜索同时,可以找出在满足搜索查询的文档中找到了哪些标签以及数量如何)。这对于本质上是枚举的字段很有用;我们将使用此功能制作一些很酷的搜索过滤器。
但是为了使标签的文本也可以通过文本搜索进行搜索,我们向其添加了一个子字段
"text",通过与name和类似的方式进行配置text上面-本质上,这意味着Elasticsearch将在所访问的所有文档的名称下创建另一个“虚拟”字段,该字段tags.text会将内容复制到其中tags,但会根据不同的规则对其进行索引。
索引:填充索引
要为文档建立索引
/-/_create/id-,只需向PUT请求即可,或者在使用Python客户端时,只需调用所需的方法即可。我们的实现将如下所示:
def put_card_into_index(self, card: Card, index_name: str):
self.elasticsearch_client.create(index_name, card.id, {
"name": card.name,
"text": card.markdown,
"tags": card.tags,
})
注意领域
tags。尽管我们将其描述为包含关键字,但是我们发送的不是字符串,而是字符串列表。Elasticsearch支持这一点;我们的文档将位于任何值。
索引编制:切换索引
要实现搜索,我们需要知道最新的完整索引的名称。别名机制使我们可以将此信息保留在Elasticsearch端。
别名是指向零个或多个索引的指针。 Elasticsearch API允许您在搜索时使用别名名而不是索引名(POST
/-/_search而不是POST /-/_search);在这种情况下,Elasticsearch将搜索别名指向的所有索引。
我们将创建一个名为的别名
cards,该别名将始终指向当前索引。因此,在构建完成后切换到实际索引将如下所示:
def switch_current_cards_index(self, new_index_name: str):
try:
# , .
remove_actions = [
{
"remove": {
"index": index_name,
"alias": self.cards_index_alias,
}
}
for index_name in self.elasticsearch_client.indices.get_alias(name=self.cards_index_alias)
]
except NotFoundError:
# , - .
# , .
remove_actions = []
#
# .
self.elasticsearch_client.indices.update_aliases({
"actions": remove_actions + [{
"add": {
"index": new_index_name,
"alias": self.cards_index_alias,
}
}]
})
我不会更详细地介绍别名API。所有详细信息都可以在文档中找到。
这里有必要说明一下,在真正的高负载服务中,这样的切换可能会很痛苦,并且进行预热可能很有意义-使用某种已保存的用户查询池来加载新索引。
可以在此commit中找到实现索引的所有代码。
编制索引:添加内容
对于本文中的演示,我正在使用TMDB 5000 Movie Dataset中的数据。为避免版权问题,我只提供从CSV文件导入实用程序的代码,建议您从Kaggle网站下载。下载后,只需运行命令
docker-compose exec -T backend python -m tools.add_movies < ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv
创建五千张电影卡和一个团队
docker-compose exec backend python -m tools.build_index
建立索引。请注意,最后一个命令实际上并不构建索引,而只是将任务放入任务队列中,之后它将在工作线程上执行-我在上一篇文章中更详细地讨论了这种方法。
docker-compose logs worker向您展示工人的尝试方式!
实际上,在开始搜索之前,我们希望亲眼看看是否在Elasticsearch中编写了某些内容,如果有,则外观如何!
最直接,最快的方法是使用Elasticsearch HTTP API。首先,让我们检查别名指向的位置:
$ curl -s localhost:9200/_cat/aliases
cards cards-2020-09-20-16-14-18 - - - -
很好,索引存在!让我们仔细看看:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18 | jq
{
"cards-2020-09-20-16-14-18": {
"aliases": {
"cards": {}
},
"mappings": {
...
},
"settings": {
"index": {
"creation_date": "1600618458522",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "iLX7A8WZQuCkRSOd7mjgMg",
"version": {
"created": "7050199"
},
"provided_name": "cards-2020-09-20-16-14-18"
}
}
}
}
最后,让我们看一下它的内容:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18/_search | jq
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4704,
"relation": "eq"
},
"max_score": 1,
"hits": [
...
]
}
}
总共,我们的索引是4704个文档,在该字段中
hits(由于太大,我跳过了该文档),甚至可以看到其中一些的内容。成功!
浏览索引内容以及通常对Elasticsearch进行各种形式纵容的一种更便捷的方法是使用Kibana。让我们将容器添加到
docker-compose.yml:
services:
...
kibana:
image: "kibana:7.5.1"
ports:
- "5601:5601"
depends_on:
- elasticsearch
...
第二次之后,
docker-compose up我们可以转到该地址的Kibana localhost:5601(请注意,服务器可能无法快速启动),经过短暂的设置后,可以在一个不错的Web界面中查看索引的内容。
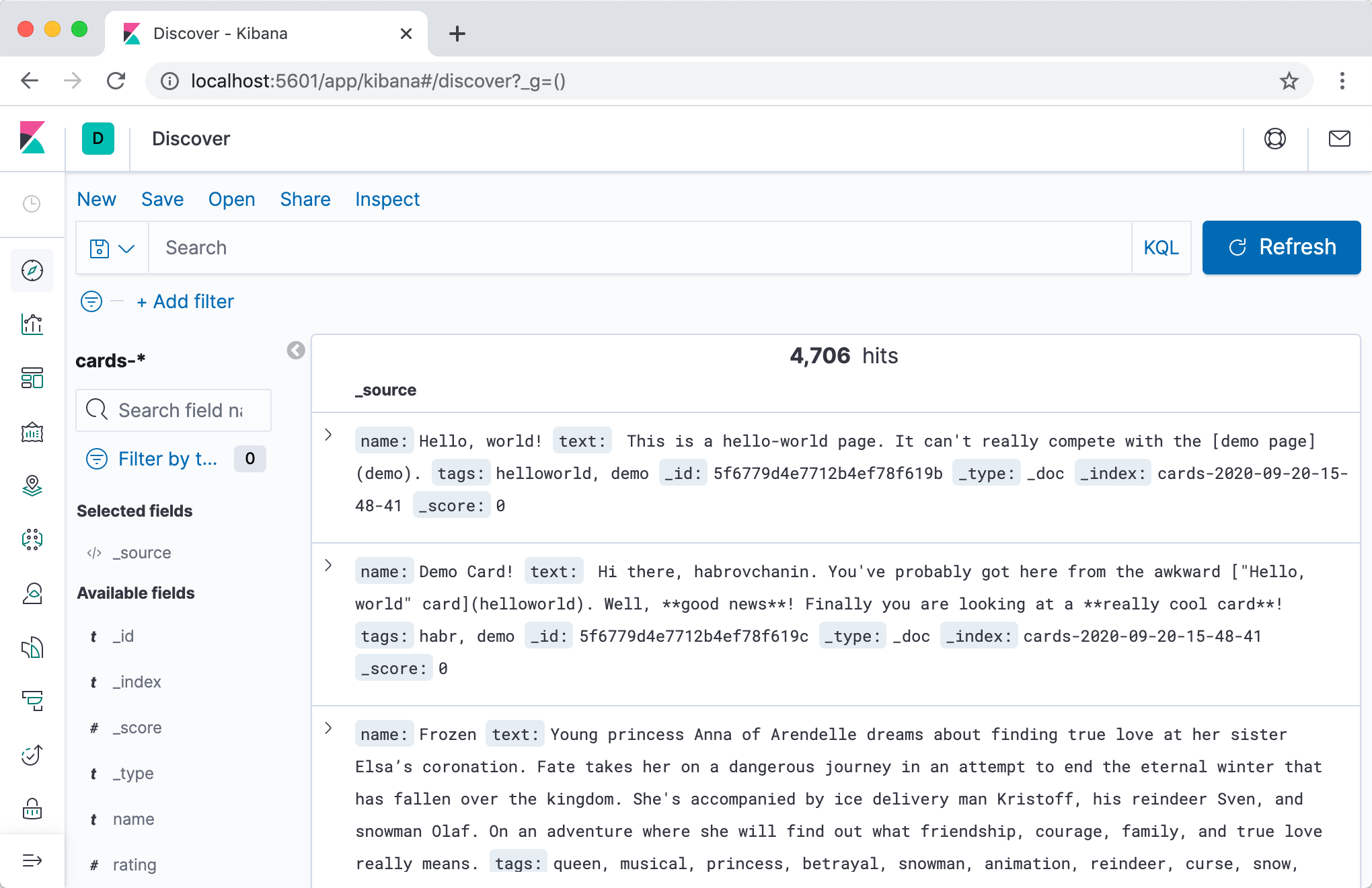
我强烈建议您使用“开发工具”选项卡-在开发过程中,您经常需要在Elasticsearch中发出某些请求,而在具有自动完成和自动格式化功能的交互模式下,此操作更加方便。
搜索
经过所有无聊的准备之后,是时候为我们的Web应用程序添加搜索功能了!
让我们将这项艰巨的任务分为三个阶段,分别进行讨论。
- 将
Searcher负责搜索逻辑的组件添加到后端。它将构成对Elasticsearch的查询,并将结果转换为对我们的后端更易消化的内容。 - 将端点添加到API(句柄/路由/在公司中您称其为什么?),即可
/cards/search执行搜索。它将调用组件的方法Searcher,处理结果并将其返回给客户端。 - 让我们在前端实现搜索界面。
/cards/search当用户决定要搜索的内容并显示结果(以及可能的一些其他控件)时,它将联系。
搜索:我们实施
编写搜索经理并不比设计一个经理容易。让我们描述搜索结果和管理器界面,并讨论它为何如此且没有什么不同。
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0) -> CardSearchResult:
pass
有些事情是显而易见的。例如,分页。我们是一家雄心勃勃的
有些不太明显。例如,ID列表,而不是卡列表。 Elasticsearch默认存储我们的整个文档,并将它们返回到搜索结果中。可以关闭此行为以节省搜索索引的大小,但这显然对我们来说还为时过早。那么,为什么不立即退回卡呢?答:这将违反单一责任原则。也许有一天,我们将在卡管理器中完成复杂的逻辑,根据用户的设置将卡翻译成其他语言。恰恰在这一刻,卡片页面上的数据和搜索结果中的数据将被分散,因为我们将忘记向搜索管理器添加相同的逻辑。等等等等。
这个接口的实现是如此简单,以至于我懒得写本节了:-(
# backend/backend/search/searcher_impl.py
from typing import Any
from elasticsearch import Elasticsearch
from backend.search.searcher import CardSearchResult, Searcher
ElasticsearchQuery = Any #
class ElasticsearchSearcher(Searcher):
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query
})
total_count = result["hits"]["total"]["value"]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
)
def _make_text_query(self, query: str) -> ElasticsearchQuery:
return {
# Multi-match query
# ( match
# query, ).
"multi_match": {
"query": query,
# ^ – .
# , .
"fields": ["name^3", "tags.text", "text"],
}
}
_match_all_query: ElasticsearchQuery = {"match_all": {}}
实际上,我们只是转到Elasticsearch API并从结果中仔细提取找到的卡的ID。
端点实现也很简单:
# backend/backend/server.py
...
def search_cards(self):
request = flask.request.json
search_result = self.wiring.searcher.search_cards(**request)
cards = self.wiring.card_dao.get_by_ids(search_result.card_ids)
return flask.jsonify({
"totalCount": search_result.total_count,
"cards": [
{
"id": card.id,
"slug": card.slug,
"name": card.name,
# ,
# ,
# .
} for card in cards
],
"nextCardOffset": search_result.next_card_offset,
})
...
尽管使用了大量的端点来实现前端,但是通常很简单,我不想在本文中集中讨论。您可以在此commit中看到所有代码。

到目前为止一切顺利,让我们继续前进。
 搜索:添加过滤器
搜索:添加过滤器
文本搜索很酷,但是如果您曾经搜索过大量资源,那么您可能已经看到了各种好东西,例如过滤器。
我们对TMDB 5000数据库中电影的描述除了标题和描述之外还带有标签,因此让我们通过标签来实现过滤器进行培训。我们的目标是在屏幕截图中:单击标签时,只有带有该标签的电影才应保留在搜索结果中(其编号显示在其旁边的括号中)。

要实现过滤器,我们需要解决两个问题。
- 根据要求了解了解哪些过滤器可用。我们不想在每个屏幕上都显示所有可能的过滤器值,因为它们很多,大多数都会导致结果为空; 您需要了解按请求找到的文档具有哪些标签,理想情况下应使N最受欢迎。
- 实际上,要学习应用过滤器-在搜索结果中仅保留带有标签的文档,即用户选择的过滤器。
Elasticsearch中的第二个是通过查询API来简单实现的(请参阅条款查询),第一个是通过稍微少一些的聚合机制实现的。
因此,我们需要知道在找到的卡片中找到了哪些标签,并能够使用必要的标签过滤卡片。首先,让我们更新搜索管理器设计:
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class TagStats:
tag: str
cards_count: int
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
tag_stats: Iterable[TagStats]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0,
tags: Optional[Iterable[str]] = None) -> CardSearchResult:
pass
现在让我们继续执行。我们需要做的第一件事是通过该字段创建一个聚合
tags:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -10,6 +10,8 @@ ElasticsearchQuery = Any
class ElasticsearchSearcher(Searcher):
+ TAGS_AGGREGATION_NAME = "tags_aggregation"
+
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
@@ -18,7 +20,12 @@ class ElasticsearchSearcher(Searcher):
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query,
+ "aggregations": {
+ self.TAGS_AGGREGATION_NAME: {
+ "terms": {"field": "tags"}
+ }
+ }
})
现在,在从Elasticsearch搜索结果,场会
aggregations从哪个,使用钥匙,TAGS_AGGREGATION_NAME我们可以得到桶包含什么值都在外地信息tags的发现,文档以及如何他们经常发生。让我们提取这些数据并按上面的设计将其返回:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -28,10 +28,15 @@ class ElasticsearchSearcher(Searcher):
total_count = result["hits"]["total"]["value"]
+ tag_stats = [
+ TagStats(tag=bucket["key"], cards_count=bucket["doc_count"])
+ for bucket in result["aggregations"][self.TAGS_AGGREGATION_NAME]["buckets"]
+ ]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
+ tag_stats=tag_stats,
)
添加过滤器应用程序是最简单的部分:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -16,11 +16,17 @@ class ElasticsearchSearcher(Searcher):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
- def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
+ def search_cards(self, query: str = "", count: int = 20, offset: int = 0,
+ tags: Optional[Iterable[str]] = None) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
- "query": self._make_text_query(query) if query else self._match_all_query,
+ "query": {
+ "bool": {
+ "must": self._make_text_queries(query),
+ "filter": self._make_filter_queries(tags),
+ }
+ },
"aggregations": {
必须包含在子句中的子查询是强制性的,但是在计算文档的速度以及相应的排名时也将考虑它们。如果我们在文本中添加更多条件,则最好在此处添加它们。filter子句中的子查询仅过滤而不影响速度和排名。
它仍然要执行
_make_filter_queries():
def _make_filter_queries(self, tags: Optional[Iterable[str]] = None) -> List[ElasticsearchQuery]:
return [] if tags is None else [{
"term": {
"tags": {
"value": tag
}
}
} for tag in tags]
同样,我不会停留在前端部分。所有代码都在此commit中。
测距
因此,我们的搜索将查找卡片,并根据给定的标签列表对其进行过滤,并以某种顺序显示它们。但是哪一个呢?顺序对于实际搜索非常重要,但是我们在诉讼过程中所做的所有工作都是按照顺序向Elasticsearch暗示,通过
^3在多重匹配查询中指定优先级,在卡片标题中找到单词比在描述或标签中找到单词更有利可图。
尽管默认情况下,Elasticsearch使用基于TF-IDF的复杂公式对文档进行排名,对于我们想象中的雄心勃勃的初创公司来说,这还远远不够。如果我们的文件是货物,我们需要能够说明其销售;如果它是用户生成的内容,则可以考虑其新鲜度,等等。但是我们不能简单地按销售数量/添加日期排序,因为那样我们就不会考虑与搜索查询的相关性。
排名是一个庞大而令人困惑的技术领域,在本文结尾处无法涵盖。所以在这里,我改用大笔画;我将尝试以最笼统的方式告诉您如何在搜索结果中排列工业等级排名,并且将揭示一些如何使用Elasticsearch实施的技术细节。
排名任务非常复杂,因此解决它的主要现代方法之一是机器学习也就不足为奇了。将机器学习技术应用于排名统称为学习排名。
一个典型的过程如下所示。
我们决定要排名。我们将感兴趣的实体放入索引中,学习如何针对给定的搜索查询获得这些实体的合理顶部(例如,一些简单的排序和切除),现在我们想学习如何以更智能的方式对其进行排名。
确定我们如何排名...我们决定要根据服务的业务目标对结果进行排名的特征。例如,如果我们的实体是我们出售的产品,我们可能希望按照购买可能性的降序对它们进行排序;如果是模因-喜欢或分享的可能性,依此类推。当然,我们不知道如何计算这些概率-充其量只能估算,甚至对于拥有足够统计数据的旧实体也是如此-但是我们将尝试讲授该模型基于间接符号进行预测。
提取标志...我们为实体提供了一组功能,可以帮助我们评估实体与搜索查询的相关性。除了相同的TF-IDF(它已经知道如何为我们计算Elasticsearch)外,一个典型的例子是CTR(点击率):我们记录了整个时间的服务日志,对于每对实体+搜索查询,我们计算该实体在搜索结果中出现了多少次对于这个请求以及它被点击了多少次,我们一一除以其他方法-有条件的点击概率的最简单估算就可以了。我们还可以提出用户特定的特征和用户实体配对的特征来个性化排名。提出符号后,我们编写代码来计算它们,将其放入某种存储中,并且知道如何针对给定的搜索查询,用户和一组实体实时提供它们。
汇总训练数据集。有很多选项,但是通常,所有选项都是由我们服务中的“好”(例如,先单击然后是购买)事件和“不好”(例如,单击并返回发行)事件形成的。当我们组装数据集时,它是以下语句列表:“对产品X与查询Q的相关性的评估大约等于P”;对对列表“产品X与产品Y与查询Q的相关性更高”;或一组列表“对于查询Q,产品P 1,P 2,...的正确排序” -that“,我们将相应的符号收紧到其中出现的所有行。
我们训练模型。这是所有ML经典:训练/测试,超参数,再训练,
我们嵌入模型。对于我们来说,剩下的就是以某种方式在整个顶部动态地计算模型,以便已经排名的结果到达用户手中。有很多选择。出于说明目的,我(再次)将重点介绍一个简单的Elasticsearch插件Learning to Rank。
排名:Elasticsearch学习排名插件
Elasticsearch Learning to Rank是一个插件,它向Elasticsearch添加了在SERP中计算ML模型并立即根据计算出的比率对结果进行排名的功能。它还将帮助我们获得与实时使用的功能相同的功能,同时重用Elasticsearch的功能(TF-IDF等)。
首先,我们需要将容器中的插件与Elasticsearch连接。我们需要一个简单的Dockerfile
# elasticsearch/Dockerfile
FROM elasticsearch:7.5.1
RUN ./bin/elasticsearch-plugin install --batch http://es-learn-to-rank.labs.o19s.com/ltr-1.1.2-es7.5.1.zip
以及对以下内容的相关更改
docker-compose.yml:
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -5,7 +5,8 @@ services:
elasticsearch:
- image: "elasticsearch:7.5.1"
+ build:
+ context: elasticsearch
environment:
- discovery.type=single-node
我们还需要Python客户端中的插件支持。令人惊讶的是,我发现对Python的支持并没有随插件一起完成,因此特别是对于本文,我已经将其淘汰。加入
elasticsearch_ltr到requirements.txt与升级接线客户端:
--- a/backend/backend/wiring.py
+++ b/backend/backend/wiring.py
@@ -1,5 +1,6 @@
import os
+from elasticsearch_ltr import LTRClient
from celery import Celery
from elasticsearch import Elasticsearch
from pymongo import MongoClient
@@ -39,5 +40,6 @@ class Wiring(object):
self.task_manager = TaskManager(self.celery_app)
self.elasticsearch_client = Elasticsearch(hosts=self.settings.ELASTICSEARCH_HOSTS)
+ LTRClient.infect_client(self.elasticsearch_client)
self.indexer = Indexer(self.elasticsearch_client, self.card_dao, self.settings.CARDS_INDEX_ALIAS)
self.searcher: Searcher = ElasticsearchSearcher(self.elasticsearch_client, self.settings.CARDS_INDEX_ALIAS)
排名:锯切迹象
Elasticsearch中的每个请求不仅返回找到的文档ID的列表,而且还会很快返回其中的一些(您将如何将单词score转换为俄语?)。所以,如果这是一个比赛或者多匹配查询,我们正在使用,然后快速计算是很那个的结果棘手的公式涉及TF-IDF;如果布尔查询是嵌套查询率的组合;如果函数分数查询-计算给定函数的结果(例如,文档中某些数字字段的值),依此类推。 ELTR插件使我们能够将任何请求的速度用作标志,从而使我们能够轻松地将有关文档与请求的匹配程度(通过多次匹配查询)和我们预先放入文档中的一些预先计算的统计信息(通过函数得分查询)组合在一起...
由于我们手中有一个TMDB 5000数据库,其中包含电影说明以及它们的评分,因此,我们将该评分作为示例性的预先计算的功能。
在这个提交中我在Web应用程序的后端添加了一些用于存储功能的基本基础结构,并支持从电影文件中加载评级。为了不强迫您阅读另一堆代码,我将介绍最基本的代码。
- 我们将这些功能存储在一个单独的集合中,并由一个单独的管理员来获取它们。将所有数据转储到一个实体中是一种不好的做法。
- 我们将在索引编制阶段与该经理联系,并将所有可用的符号放入索引编制的文档中。
- 要了解索引架构,我们需要在开始索引构建之前了解所有现有功能的列表。我们现在将对该列表进行硬编码。
- 由于我们不会按特征值过滤文档,而只会从已经找到的文档中提取文档以计算模型,因此我们将通过
index: false模式中带有选项的新字段来关闭逆索引的构造,并因此节省一些空间。
排名:收集数据集
因为,首先,我们没有生产,其次,这篇文章的利润率为约遥测,卡夫卡,NiFi,Hadoop的,Spark和构建ETL过程,我只是将故事太小产生我们的卡随机浏览和点击次数和某种搜索查询。之后,您将需要计算得出的卡请求对的特征。
现在是时候更深入地研究ELTR插件API了。为了计算特征,我们将需要创建一个特征存储实体(据我所知,这实际上只是Elasticsearch中的一个索引,插件在其中存储所有数据),然后创建一个特征集-一系列特征以及如何计算每个特征的描述。在那之后,我们去一个特殊的请求去Elasticsearch就足够了,结果是为每个找到的实体获取特征值的向量。
让我们从创建功能集开始:
# backend/backend/search/ranking.py
from typing import Iterable, List, Mapping
from elasticsearch import Elasticsearch
from elasticsearch_ltr import LTRClient
from backend.search.features import CardFeaturesManager
class SearchRankingManager:
DEFAULT_FEATURE_SET_NAME = "card_features"
def __init__(self, elasticsearch_client: Elasticsearch,
card_features_manager: CardFeaturesManager,
cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.card_features_manager = card_features_manager
self.cards_index_name = cards_index_name
def initialize_ranking(self, feature_set_name=DEFAULT_FEATURE_SET_NAME):
ltr: LTRClient = self.elasticsearch_client.ltr
try:
# feature store ,
# ¯\_(ツ)_/¯
ltr.create_feature_store()
except Exception as exc:
if "resource_already_exists_exception" not in str(exc):
raise
# feature set !
ltr.create_feature_set(feature_set_name, {
"featureset": {
"features": [
#
# ,
# ,
# .
self._make_feature("name_tf_idf", ["query"], {
"match": {
# ELTR
# , .
# , ,
# ,
# match query.
"name": "{{query}}"
}
}),
# , .
self._make_feature("combined_tf_idf", ["query"], {
"multi_match": {
"query": "{{query}}",
"fields": ["name^3", "tags.text", "text"]
}
}),
*(
#
# function score.
# -
# , 0.
# (
# !)
self._make_feature(feature_name, [], {
"function_score": {
"field_value_factor": {
"field": feature_name,
"missing": 0
}
}
})
for feature_name in sorted(self.card_features_manager.get_all_feature_names_set())
)
]
}
})
@staticmethod
def _make_feature(name, params, query):
return {
"name": name,
"params": params,
"template_language": "mustache",
"template": query,
}
现在-为给定查询和卡片计算功能的函数:
def compute_cards_features(self, query: str, card_ids: Iterable[str],
feature_set_name=DEFAULT_FEATURE_SET_NAME) -> Mapping[str, List[float]]:
card_ids = list(card_ids)
result = self.elasticsearch_client.search({
"query": {
"bool": {
# ,
# — ,
# .
# ID.
"filter": [
{
"terms": {
"_id": card_ids
}
},
# — ,
# SLTR.
#
# feature set.
# ( ,
# filter, .)
{
"sltr": {
"_name": "logged_featureset",
"featureset": feature_set_name,
"params": {
# .
# , ,
#
# {{query}}.
"query": query
}
}
}
]
}
},
#
# .
"ext": {
"ltr_log": {
"log_specs": {
"name": "log_entry1",
"named_query": "logged_featureset"
}
}
},
"size": len(card_ids),
})
# (
# ) .
# ( ,
# , Kibana.)
return {
hit["_id"]: [feature.get("value", float("nan")) for feature in hit["fields"]["_ltrlog"][0]["log_entry1"]]
for hit in result["hits"]["hits"]
}
一个简单的脚本,接受带有请求和身份证的CSV作为输入,并输出具有以下功能的CSV:
# backend/tools/compute_movie_features.py
import csv
import itertools
import sys
import tqdm
from backend.wiring import Wiring
if __name__ == "__main__":
wiring = Wiring()
reader = iter(csv.reader(sys.stdin))
header = next(reader)
feature_names = wiring.search_ranking_manager.get_feature_names()
writer = csv.writer(sys.stdout)
writer.writerow(["query", "card_id"] + feature_names)
query_index = header.index("query")
card_id_index = header.index("card_id")
chunks = itertools.groupby(reader, lambda row: row[query_index])
for query, rows in tqdm.tqdm(chunks):
card_ids = [row[card_id_index] for row in rows]
features = wiring.search_ranking_manager.compute_cards_features(query, card_ids)
for card_id in card_ids:
writer.writerow((query, card_id, *features[card_id]))
最后,您可以全部运行!
# feature set
docker-compose exec backend python -m tools.initialize_search_ranking
#
docker-compose exec -T backend \
python -m tools.generate_movie_events \
< ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv \
> ~/Downloads/habr-app-demo-dataset-events.csv
#
docker-compose exec -T backend \
python -m tools.compute_features \
< ~/Downloads/habr-app-demo-dataset-events.csv \
> ~/Downloads/habr-app-demo-dataset-features.csv
现在我们有了两个文件-带有事件和标志-我们可以开始训练了。
排名:训练并实施模型
让我们跳过加载数据集的详细信息(您可以在此commit中看到完整的脚本),直截了当地。
# backend/tools/train_model.py
...
if __name__ == "__main__":
args = parser.parse_args()
feature_names, features = read_features(args.features)
events = read_events(args.events)
# train test 4 1.
all_queries = set(events.keys())
train_queries = random.sample(all_queries, int(0.8 * len(all_queries)))
test_queries = all_queries - set(train_queries)
# DMatrix — , xgboost.
#
# . 1, ,
# 0, ( . ).
train_dmatrix = make_dmatrix(train_queries, events, feature_names, features)
test_dmatrix = make_dmatrix(test_queries, events, feature_names, features)
# !
#
# ML,
# XGBoost.
param = {
"max_depth": 2,
"eta": 0.3,
"objective": "binary:logistic",
"eval_metric": "auc",
}
num_round = 10
booster = xgboost.train(param, train_dmatrix, num_round, evals=((train_dmatrix, "train"), (test_dmatrix, "test")))
# .
booster.dump_model(args.output, dump_format="json")
# , :
# ROC-.
xgboost.plot_importance(booster)
plt.figure()
build_roc(test_dmatrix.get_label(), booster.predict(test_dmatrix))
plt.show()
发射
python backend/tools/train_search_ranking_model.py \
--events ~/Downloads/habr-app-demo-dataset-events.csv \
--features ~/Downloads/habr-app-demo-dataset-features.csv \
-o ~/Downloads/habr-app-demo-model.xgb
请注意,由于我们使用先前的脚本导出了所有必要的数据,因此该脚本不再需要在docker内部运行-它需要在您的计算机上运行,并且已经安装了
xgboost和sklearn。同样,在实际生产中,以前的脚本必须在可以访问生产环境的某个地方运行,但事实并非如此。
如果一切正确完成,模型将成功训练,我们将看到两张漂亮的照片。首先是这些功能重要性的图表:

尽管事件是随机产生的,
combined_tf_idf事实证明它比其他方法具有更大的意义-因为我做了一个诡计,并人为地降低了以旧方式排名的搜索结果中较低的卡片的点击概率。模型注意到这一事实是一个好兆头,也表明我们没有在学习过程中犯任何完全愚蠢的错误。
第二张图是ROC曲线:

蓝线在红线上方,这意味着我们的模型预测的标签比抛硬币要好一些。 (妈妈朋友的ML工程师曲线应几乎触及左上角。)
问题非常小-我们添加了一个脚本来填充模型,填写模型并向搜索查询中添加一个小的新项-记录:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -27,6 +30,19 @@ class ElasticsearchSearcher(Searcher):
"filter": list(self._make_filter_queries(tags, ids)),
}
},
+ "rescore": {
+ "window_size": 1000,
+ "query": {
+ "rescore_query": {
+ "sltr": {
+ "params": {
+ "query": query
+ },
+ "model": self.ranking_manager.get_current_model_name()
+ }
+ }
+ }
+ },
"aggregations": {
self.TAGS_AGGREGATION_NAME: {
"terms": {"field": "tags"}
现在,在Elasticsearch执行我们需要的搜索并使用其(相当快的)算法对结果进行排名之后,我们将获取前1000个结果,并使用(相对较慢)的机器学习公式进行重新排名。成功!
结论
我们使用了简约的Web应用程序,从本身没有搜索功能转变为具有许多高级功能的可扩展解决方案。这并非易事。但这也不难!最终的应用程序位于Github上一个名称适中的分支中的存储库中,
feature/search并且需要具有机器学习库的Docker和Python 3才能运行。
我使用Elasticsearch展示了它的总体工作原理,遇到的问题以及如何解决它们,但这当然不是唯一可供选择的工具。在选择要建立
而且,当然,此解决方案并不声称是完整的和可投入生产的,而仅仅是说明如何完成所有工作。您几乎可以无休止地改善它!
- 增量索引。当通过修改我们的卡时,
CardManager最好立即在索引中更新它们。为了CardManager不知道我们在服务中也进行了搜索,并且没有循环依赖关系,我们将不得不以一种或另一种形式拧紧依赖关系反转。 - 为了在我们的特定情况下建立索引,MongoDB与Elasticsearch捆绑在一起,您可以使用现成的解决方案,例如mongo-connector。
- , — Elasticsearch .
- , , .
- , , . -, -, - … !
- ( , ), ( ). , .
- , , .
- 通过分片和复制来编排节点集群是一种完全独立的乐趣。
但是为了保持文章的可读性,我会停在这里,让您独自面对这些挑战。感谢您的关注!