序言
让我们从逻辑编程和Prolog语言开始。有关主题领域的知识以一组事实和规则的形式呈现在其中。事实描述了立即的知识。上一篇文章中的示例中有关客户(ID,名称和电子邮件地址)和发票(账户ID,客户,日期,应付金额和已付金额)的事实看起来像这样
client(1, "John", "john@somewhere.net").
bill(1, 1,"2020-01", 100, 50).规则描述了可以从其他规则和事实中推断出的抽象知识。该规则包括一个头部和一个身体。在规则的开头,您需要指定其名称和参数列表。规则的主体是由逻辑运算AND(由逗号指定)和OR(由分号指定)连接的谓词列表。谓词可以是事实,规则或内置谓词,例如比较运算,算术运算等。使用布尔变量设置规则头的自变量与谓词在其主体中的自变量之间的关系-如果同一变量位于两个不同自变量的位置,这意味着这些参数是相同的。当规则主体的逻辑表达式为true时,该规则被视为true。可以将域模型定义为一组引用规则:
unpaidBill(BillId, ClientId, Date, AmoutToPay, AmountPaid) :- bill(BillId, ClientId, Date, AmoutToPay, AmountPaid), AmoutToPay < AmountPaid.
debtor(ClientId, Name, Email) :- client(ClientId, Name, Email), unpaidBill(BillId, ClientId, _, _, _).我们设定了两个规则。在第一个中,我们断言所有少于应付金额的发票都是未付发票。在第二种情况下,债务人是拥有至少一张未付发票的客户。
Prolog的语法非常简单:程序的主要元素是规则,规则的主要元素是谓词,逻辑运算和变量。在规则中,注意力集中在变量上-它们扮演建模世界的对象的角色,并且谓词描述它们的属性和它们之间的关系。在债务人规则的定义中,我们声明,如果ClientId,Name和Email对象通过客户和unpaidBill关系关联,那么它们也将通过债务人关系关联。当问题被表述为一组规则,陈述或逻辑陈述时,Prolog会派上用场。例如,当使用自然语言语法时,编译器将在专家系统中对复杂系统(例如计算机,计算机网络,基础结构对象)进行分析。复杂,最好对卷积规则系统进行最好的描述,并留给Prolog运行时自动处理。
Prolog基于一阶逻辑(包括一些高阶逻辑元素)。使用称为SLD解析度(选择性线性确定子句解析度)的过程进行推理。简化后,其算法是所有可能解决方案的树遍历。推理过程为规则主体的第一个谓词找到所有解。如果知识库中的当前谓词仅由事实表示,那么解决方案就是那些与变量到值的当前绑定相对应的解决方案。如果按照规则,则需要对其嵌套谓词进行递归检查。如果找不到解决方案,则当前搜索分支失败。然后,为找到的每个部分解决方案创建一个新分支。在每个分支中,推理过程将找到的值绑定到变量,包含在当前谓词中,并递归搜索剩余谓词列表的解决方案。到达谓词列表的末尾时,工作结束。在递归定义规则的情况下,对解决方案的搜索可能会陷入无限循环。搜索过程的结果是值到布尔变量的所有可能绑定的列表。
在上面的债务人规则示例中,解决规则将首先为客户谓词找到一个解决方案,并将其与布尔值相关联:ClientId = 1,Name =“ John”,Email =“ john@somewhere.net”。然后,对于变量值的此变体,将对下一个谓词unpaidBill执行解决方案。为此,您首先需要找到Bill谓词的解决方案,前提是ClientId =1。结果将是变量BillId = 1,Date =“ 2020-01”,AmoutToPay = 100,AmountPaid = 50的绑定。最后,将检查AmoutToPay <AmountPaid在内置比较谓词中。
语义网络
语义网络是表示知识的最受欢迎的方法之一。语义网是有向图形式的主题区域的信息模型。图的顶点与域的概念相对应,圆弧定义它们之间的关系。
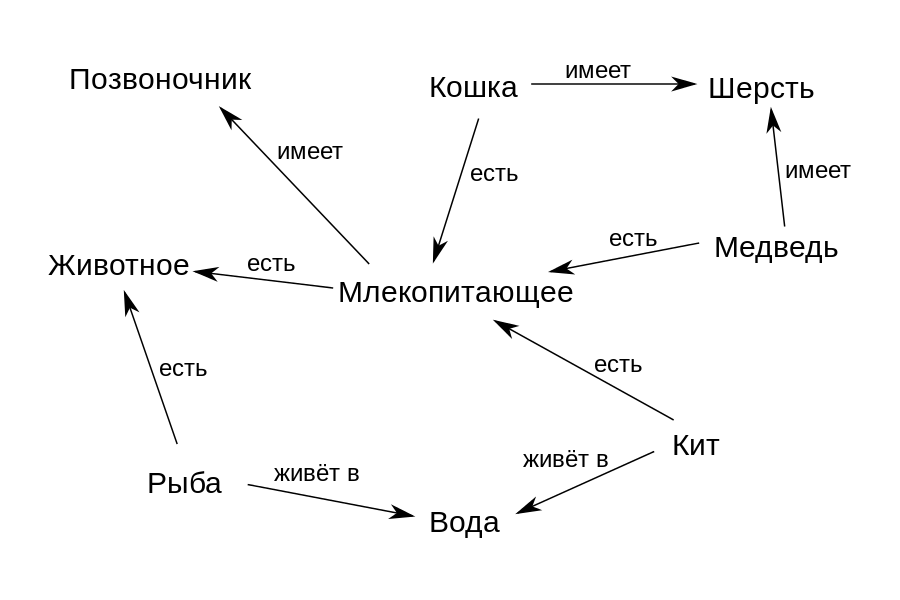
例如,根据上图中的图表,“鲸鱼”的概念与“哺乳动物”的关系是“ is”(“ is”),而“水”的概念与“住”相关。因此,我们可以正式设置主题领域的结构-它包含哪些概念以及它们如何相互关联。然后,可以使用这种图形来查找问题的答案并从中获得新知识。例如,如果我们确定关系“ is”表示类-子类关系,并且子类“ Whale”应继承其类“哺乳动物”的所有属性,则可以推断出“鲸鱼”,“具有”,“脊椎”的知识。
RDF
语义网是通过以适合于机器处理的形式对信息表示进行标准化来基于万维网资源构建全球语义网的尝试。为此,信息还以HTML标签的特殊属性形式嵌入HTML页面中,这允许以本体(一组事实,抽象概念以及它们之间的关系)的形式描述其内容的含义。
描述WEB资源语义模型的标准方法是RDF(资源描述框架或资源描述框架)。根据它,所有语句必须具有三元组“主题-谓语-对象”的形式。例如,有关“鲸鱼”概念的知识将以如下方式表示:“鲸鱼”是一个主语,“生活在”-一个谓词,“水”-是一个对象。可以使用有向图来描述此类语句的整个集合,主题和对象是其顶点,谓词是弧,谓词弧从对象指向主题。例如,来自动物示例的本体可以描述如下:
@prefix : <...some URL...>
@prefix rdf: <http://www.w3.org/1999/02/rdf-schema#>
@prefix rdfs: <http://www.w3.org/2000/01/22-rdf-syntax-ns#>
:Whale rdf:type :Mammal;
:livesIn :Water.
:Fish rdf:type :Animal;
:livesIn :Water.这种表示法称为Turtle,旨在使人们可以理解。但是也可以用XML,JSON格式或使用HTML文档的标签和属性来编写。尽管在Turtle表示法中可以将谓词和对象按主题分组以提高可读性,但在语义级别上每个三元组都是独立的。
RDF在数据模型复杂且包含大量对象类型以及它们之间的关系的情况下很有用。例如,维基百科提供了以RDF格式访问其文章内容的权限。文章中描述的事实经过了结构化,属性和关系的描述,包括其他文章中的事实。
RDFS
RDF模型是图;默认情况下,其中不包含其他语义。每个人都可以根据需要解释图中的链接。您可以使用RDF Schema向其添加一些标准链接-一组用于在RDF之上构建本体的类和属性。RDFS允许您描述概念之间的标准关系,例如资源对某个类的所有权,类之间的层次结构,属性层次结构,以及限制主题和对象的可能类型。
例如,语句
:Mammal rdfs:subClassOf :Animal.指定“哺乳动物”是“动物”概念的子类,并继承其所有属性。因此,“鲸鱼”的概念也可以归因于“动物”类。但是为此必须指出,“哺乳动物”和“动物”是类:
:Animal rdf:type rdfs:Class.
:Mammal rdf:type rdfs:Class.同样,可以对谓词设置对其主语和宾语的可能值的约束。
声明
:livesIn rdfs:range :Environment.指示“生存”关系的对象应始终是属于“环境”类的资源。因此,我们必须添加一个声明,即“水”概念是“环境”概念的子类:
:Water rdf:type :Environment.
:Environment rdf:type rdfs:ClassRDFS允许您描述数据模式-枚举类,属性,设置其层次结构和对其值的限制。RDF是用具体事实填充此架构并定义它们之间的关系。现在我们可以问一个关于这个图的问题。这可以使用类似于SQL的特殊查询语言SPARQL来完成:
SELECT ?creature
WHERE {
?creature rdf:type :Animal;
:livesIn :Water.
} 该查询将为我们返回2个值:“ Whale”和“ Fish”。
以前的出版物中包含帐户和客户的示例可以大致实现如下。使用RDF,您可以描述数据模式并用值填充它:
:Client1 :name "John";
:email "john@somewhere.net".
:Client2 :name "Mary";
:email "mary@somewhere.net".
:Bill_1 :client :Client1;
:date "2020-01";
:amountToPay 100;
:amountPaid 50.
:Bill_2 :client :Client2;
:date "2020-01";
:amountToPay 80;
:amountPaid 80.但是本系列第一篇文章中的抽象概念,例如“债务人”和“未付帐单”,包括算术运算和比较。它们不适合概念语义网络的静态结构。可以使用SPARQL查询来表达这些概念:
SELECT ?clientName ?clientEmail ?billDate ?amountToPay ?amountPaid
WHERE {
?client :name ?clientName;
:email ?clientEmail.
?bill :client ?client;
:date ?billDate;
:amountToPay ?amountToPay;
:amountPaid ?amountPaid.
FILTER(?amountToPay > ?amountPaid).
}WHERE子句是三重模式和过滤条件的列表。布尔变量可以替换为三元组,其名称以“?”开头 查询执行程序的任务是找到所有可能的变量值,这些变量的所有三元组模式都将包含在图中并满足过滤条件。
与Prolog不同,在Prolog中,规则可用于构造其他规则,而在RDF中,查询不是语义Web的一部分。一个请求不能被引用为另一个请求的数据源。的确,SPARQL能够将查询结果表示为图形。因此,您可以尝试将查询结果与原始图组合,然后在组合图上运行新查询。但是,这样的决定显然超出了RDF的意识形态。
猫头鹰
语义Web技术的重要组成部分是OWL(Web本体语言),这是一种描述本体的语言。使用RDFS词汇表,您只能表达概念之间最基本的关系-类和关系的层次结构。OWL提供了更丰富的词汇。例如,您可以指定两个类(或两个实体)是等效的(或不同的)。结合本体时经常会遇到此任务。
您可以基于交集,并集或其他类的添加来创建复合类:
- 相交时,复合类的所有实例也必须应用于所有源类。例如,“海洋哺乳动物”必须同时是“哺乳动物”和“ Sea Dweller”。
- . , , «» «», «» «». «».
- , . , «» «».
- . , .
- — , .
允许您将概念链接在一起的此类表达式称为构造函数。
OWL还允许您设置许多重要的关系属性:
- 传递性。如果关系P(x,y)和P(y,z)成立,那么关系P(x,z)也将得到满足。这样的关系的示例是“更多”-“较少”,“父母”-“孩子”等。
- 对称。如果满足关系式P(x,y),则也满足关系式P(y,x)。例如,相对关系。
- 功能依赖性。如果关系P(x,y)和P(x,z)成立,则y和z的值必须相同。父亲关系就是一个例子-一个人不能有两个不同的父亲。
- 关系倒置。您可以指定如果满足关系P1(x,y),则必须再满足一个关系P2(y,x)。此类关系的一个示例是父子关系。
- 关系链。您可以设置为:如果A与B的某些属性相关联,而B与C的属性相关联,则A(或C)属于给定类。例如,如果A的父亲是B,而父亲B的父亲是父亲C,则A是C.的孙子。
您还可以对关系参数的值设置限制。例如,指定参数必须始终属于某个类,或者指定一个类必须至少具有给定类型的一种关系,或为此限制这种类型的关系数。或者,您可以指定通过给定关系与给定值相关的所有实例都属于特定类。
OWL现在是用于构建本体的事实上的标准工具。与RDFS相比,该语言更适合于构建大型和复杂的本体。 OWL语法使您可以表达概念的更多不同属性以及它们之间的关系。但是它也引入了许多其他限制,例如,同一概念不能同时声明为一个类和另一个类的实例。 OWL本体更加严格,更加标准化,因此更具可读性。如果RDFS只是RDF图之上的几个其他类,则OWL具有不同的数学基础-描述逻辑。因此,可以使用正式的推理程序,使您可以从OWL本体中提取新信息,检查其一致性并回答问题。
描述性逻辑是一阶逻辑。其中只允许一个位置谓词(例如,一个概念属于一个类),两个位置谓词(一个概念具有一个属性及其值)以及上面列出的类构造函数和关系属性。描述性逻辑中的所有其他一阶逻辑表达式均已删除。例如,“未付款发票”的概念属于“发票”类别,“发票”的概念具有“待付款额”和“已付款额”属性的陈述将是可以接受的。但是要声明“未付款发票”属性“应付款额”应大于属性“已付款额”,这是行不通的。这需要包含用于比较这些属性的谓词的规则。不幸,OWL的构造函数不允许您这样做。
因此,描述性逻辑的表达能力低于一阶逻辑。但是另一方面,描述逻辑中的推理算法要快得多。此外,它还具有可判定性-可在有限时间内找到有保证的解决方案。可以相信,实际上,这样的词汇量足以构建复杂而庞大的本体,OWL是表达能力和推理效率之间的良好折衷。
另外值得一提的是SWRL(语义Web规则语言),它将在OWL中创建类和属性的能力与在Datalog语言的受限版本中编写规则相结合。这些规则的样式与Prolog中的样式相同。SWRL支持用于比较,数学,字符串,日期和列表处理的内置谓词。这正是我们借助一个简单的表达式来实现“未付发票”概念所缺少的。
植物群2
作为语义网络的替代方法,请考虑使用诸如框架之类的技术。框架是描述复杂对象,抽象图像,事物模型的结构。它由一个名称,一组属性(特性)及其值组成。该属性值可以是另一帧。此外,该属性可以具有默认值。可以将用于计算其值的函数附加到属性。框架还可以包括服务过程,包括用于此类事件的处理程序,例如创建,删除框架,更改属性的值等。框架的重要属性是继承的能力。子框架包括父框架的所有属性。
链接框架系统形成一个非常类似于RDF图的语义网络。但是在创建本体的任务中,框架已被OWL(现在已成为事实上的标准)所取代。 OWL更具表现力,具有更高级的理论基础-形式描述逻辑。与在框架模型中彼此独立描述概念的属性的RDF和OWL不同,在框架模型中,概念及其属性被视为一个整体-框架。如果在RDF和OWL模型中,图的顶点包含概念的名称,而边包含其属性,则在框架模型中,图的顶点包含具有所有属性的概念,并且边包含其属性之间的连接或概念之间的继承关系。
在这种情况下,框架模型非常类似于面向对象的编程模型。它们在很大程度上相同,但是范围不同-框架旨在为概念和它们之间的关系以及OOP建模-建模对象的行为,它们之间的相互作用。因此,OOP提供了用于将一个组件的实现细节对其他组件隐藏的其他机制,从而限制了对类的方法和字段的访问。
现代框架语言(例如KL-ONE,PowerLoom,Flora-2)将对象模型的复合数据类型与一阶逻辑结合在一起。在这些语言中,您不仅可以描述对象的结构,还可以在规则中对这些对象进行操作,创建描述对象属于给定类的条件的规则,等等。类的继承和组合机制将接受逻辑解释,推理程序可以使用该逻辑解释。这些语言比OWL更具表现力,并且不限于二位谓词。
作为示例,让我们尝试用Flora-2语言对债务人实施示例... 该语言包括3个组件:F逻辑框架逻辑,框架和一阶逻辑的组合,高阶的HiLog逻辑(提供用于形成有关其他语句和元编程的结构的语句的工具)和事务逻辑更改逻辑(允许描述数据变化和计算的副作用。现在我们只对F-逻辑框架逻辑感兴趣。首先,我们将使用它来声明描述客户和债务人的概念(类)的框架的结构:
client[|name => \string,
email => \string
|].
bill[|client => client,
date => \string,
amountToPay => \number,
amountPaid => \number,
amountPaid -> 0
|].现在我们可以声明这些概念的实例(对象):
client1 : client[name -> 'John', email -> 'john@somewhere.net'].
client2 : client[name -> 'Mary', email -> 'mary@somewhere.net'].
bill1 : bill[client -> client1,
date -> '2020-01',
amountToPay -> 100
].
bill2 : bill[client -> client2,
date -> '2020-01',
amountToPay -> 80,
amountPaid -> 80
].“->”符号表示属性与对象中的特定值和类声明中的默认值的关联。在我们的示例中,账单类别的amountPaid字段的默认值为零。“:”符号表示创建该类的实体:client1和client2是客户端类的实体。
现在,我们可以声明“未付款发票”和“债务人”概念是“帐户”和“客户”概念的子类:
unpaidBill :: bill.
debtor :: client.符号“ ::”声明了类之间的继承关系。继承其所有字段的类,方法和默认值的结构。仍然需要声明指定未付费账单和债务人类别的归属的规则:
?x : unpaidBill :- ?x : bill[amountToPay -> ?a, amountPaid -> ?b], ?a > ?b.
?x : debtor :- ?x : client, ?_ : unpaidBill[client -> ?x]. 第一条语句指出,如果变量
?是票据实体并且其amountToPay字段大于amountPaid ,则该变量为unpaidBill实体。在第二种情况下,?属于unpaidBill类的对象(如果它属于客户类)并且在unpaidBill类的至少一个实体中,客户字段的值等于某个变量?。unpaidBill类的该实体将与一个匿名变量关联,该匿名变量?_的值不再使用。
您可以使用查询获取债务人列表:
?- ?x:debtor.我们要求您找到与债务人类别有关的所有价值观。结果将是该变量的所有可能值的列表
?x:
?x = client1框架逻辑将面向对象模型的可视性与逻辑编程的功能结合在一起。在需要重点关注概念结构的情况下,使用数据库,为复杂的系统建模,集成不同的数据将非常方便。
的SQL
最后,让我们看一下SQL语法的主要功能。在上一本书中,我们说过SQL具有逻辑理论基础-关系演算,并考虑了LINQ中带有债务人的示例的实现。在语义上,SQL接近于框架语言和OOP模型-在关系数据模型中,主要元素是一张表,它被视为一个整体,而不是一个单独的属性集。
SQL语法非常适合此表方向。该请求分为多个部分。由表,视图和嵌套查询表示的模型实体已移至FROM部分。它们之间的关系是使用JOIN操作指定的。字段和其他条件之间的依赖关系在WHERE和HAVING子句中。代替绑定谓词参数的布尔变量,我们直接在查询中对表字段进行操作。该语法比“线性” Prolog语法更清楚地描述了域模型的结构。
我如何看待建模语言的语法样式
使用未付款发票示例,我们可以比较逻辑编程(Prolog),帧逻辑(Flora-2),语义Web技术(RDFS,OWL和SWRL)和关系演算(SQL)等方法。我在表格中总结了它们的主要特征:
| 语言 | 数学基础 | 风格定位 | 适用范围 |
|---|---|---|---|
| 序言 | 一阶逻辑 | 在规则上 | 基于规则的系统,模式匹配。 |
| RDFS | 图形 | 概念之间的联系 | WEB资源数据架构 |
| 猫头鹰 | 描述逻辑 | 概念之间的联系 | 本体论 |
| 西南RL | Datalog一阶逻辑的简化版本 | 在概念之间的链接之上的规则 | 本体论 |
| 植物群2 | 帧+一阶逻辑 | 在对象结构之上的规则 | 数据库,为复杂的系统建模,集成不同的数据 |
| 的SQL | 关系演算 | 在桌子上的结构 | 数据库 |
现在,您需要找到一种建模语言的数学基础和语法样式,该语言旨在与半结构化数据和来自不同来源的数据集成一起使用,并将其与通用的面向对象和功能编程语言结合使用。
最具表现力的语言是Prolog和Flora-2-它们基于完整的一阶逻辑和高阶逻辑元素。其余方法是其子集。除了RDFS之外,它与形式逻辑完全无关。在此阶段,成熟的一阶逻辑在我看来似乎是首选。首先,我打算对此进行详细介绍。但是关系演算或演绎数据库逻辑形式的有限选项也有其优势。在处理大量数据时,它提供了出色的性能。将来应单独考虑。描述逻辑似乎太受限制,无法表达概念之间的动态关系。
从我的角度来看,对于处理半结构化数据和集成不同的数据源,框架逻辑比面向规则的Prolog或OWL(面向关系和概念类)更适合。框架模型明确描述了对象的结构,并将注意力集中在对象上。对于具有许多属性的对象,框架形式比规则或主题属性对象三元组更具可读性。继承也是一种非常有用的机制,可以大大减少重复代码的数量。与关系模型相比,框架逻辑使您可以更自然地描述复杂的数据结构,例如树和图形。最重要的是知识描述框架模型与OOP模型的接近性将允许以一种自然的方式将它们集成为一种语言。
我想借用SQL查询结构。概念的定义可以具有复杂的形式,将其分解为多个部分以强调其组成部分并促进感知也无济于事。而且,对于大多数开发人员而言,SQL语法非常熟悉。
因此,我想将框架逻辑作为建模语言的基础。但是由于目标是描述数据结构并集成不同的数据源,因此,我将尝试放弃面向规则的语法,而将其替换为从SQL借用的结构化版本。领域模型的主要元素将是“概念”(concept)。在其定义中,我想包括从源数据中提取其实体所需的所有信息:
- 概念的名称;
- 一组属性;
- () , ;
- , ;
- , .
该概念的定义类似于SQL查询。整个领域模型将采用相互关联的概念的形式。
我计划在下一个出版物中展示建模语言的结果语法。对于那些现在想熟悉它的人,这里有英文科学风格的全文,可在这里找到:
面向混合本体的半结构化数据处理编程
链接到以前的出版物:
设计一种多范式编程语言。第1部分-它的作用是什么?
我们设计了一种多范式编程语言。第2部分-PL / SQL,LINQ和GraphQL中的模型构建比较