基于变压器的模型在各种学科中都取得了出色的成绩,包括对话式AI,自然语言处理,图像甚至音乐。任何体系结构的主要组件都是Transformers注意模块(注意模块),该模块计算输入序列中所有对的相似度。但是,它不能随着输入序列长度的增加而很好地缩放,需要二次增加计算时间来获得所有相似度估计,以及用于构造用于存储这些估计的矩阵的内存量也需要二次增加。
对于需要更多关注的应用程序,已经提出了几种更快,更紧凑的代理,例如内存缓存技术,但是更常见的解决方案是使用稀疏关注。稀疏注意力通过仅从序列而不是所有可能的对中计算有限数量的相似性评分,从而减少了注意力机制的计算时间和内存需求,从而导致稀疏而不是完整的矩阵。这些稀疏的出现可以手动建议,可以使用优化技术找到,可以学习,甚至可以随机选择,例如稀疏变压器,长形变压器,路由变压器,改革者和大鸟。由于稀疏矩阵也可以由图形和边表示,因此稀疏方法也受图神经网络文献的启发,特别是关于图注意力网络中概述的注意力机制。这样的稀疏体系结构通常需要附加的层来隐式创建完整的关注机制。
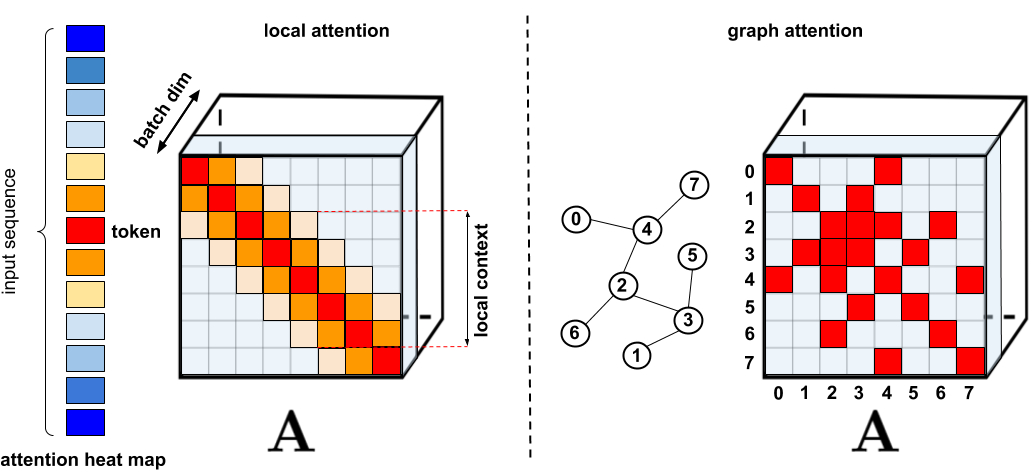
. : , . : Graph Attention Networks, , , . . « : » .
, . (1) , ; (2) ; (3) , , ; (4) , , . , , , Pointer Networks. , , , (softmax), .
, Performer, , . , , , ImageNet64, , PG-19. Performer () , , () . (Fast Attention Via Positive Orthogonal Random Features, FAVOR+), . ( , -). , .
, , , . , - . , , .
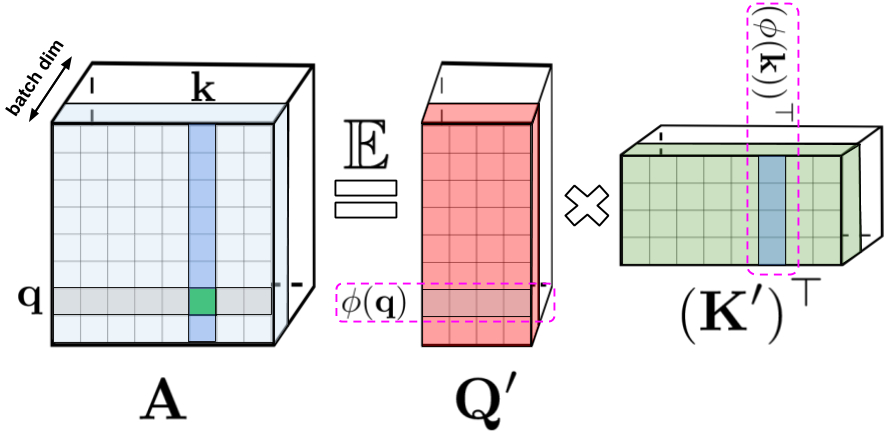
: , , , q k. : Q' K' , /. - , .
, , . , , , , -.
FAVOR+:
, . , . , , . , FAVOR+.
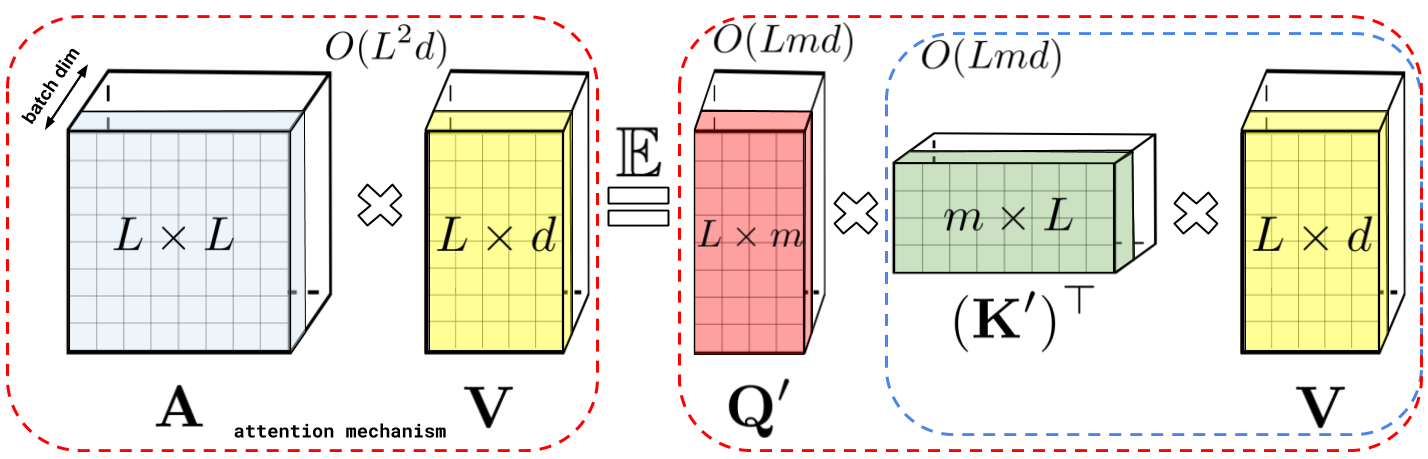
: , A V. : Q' K', A , , , , A .
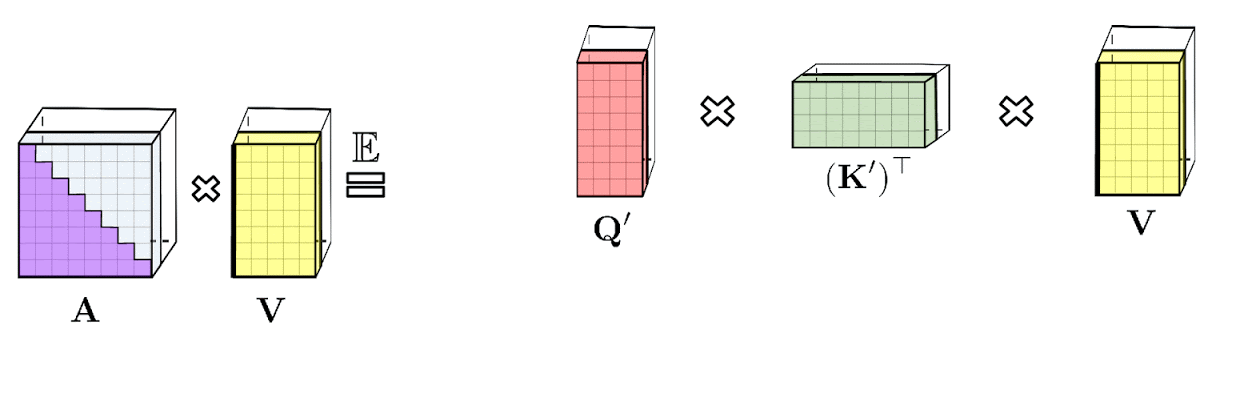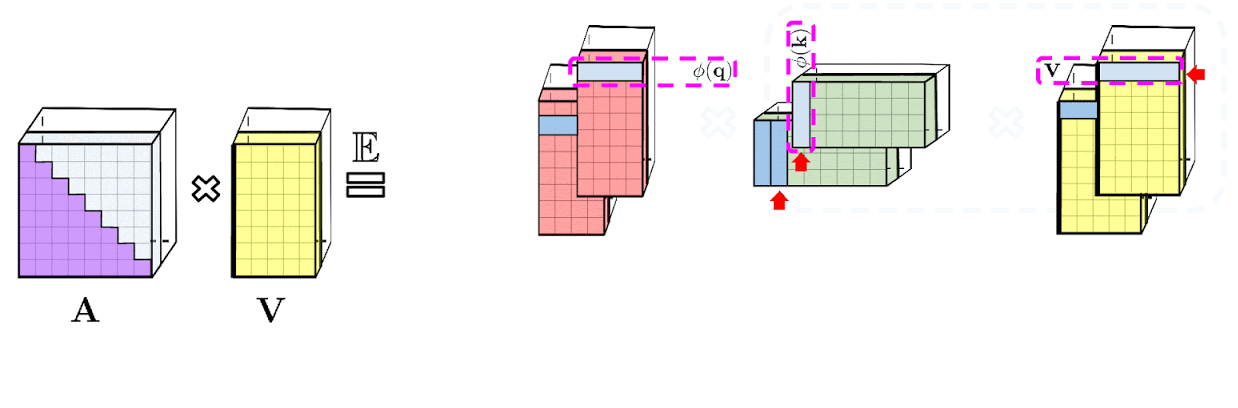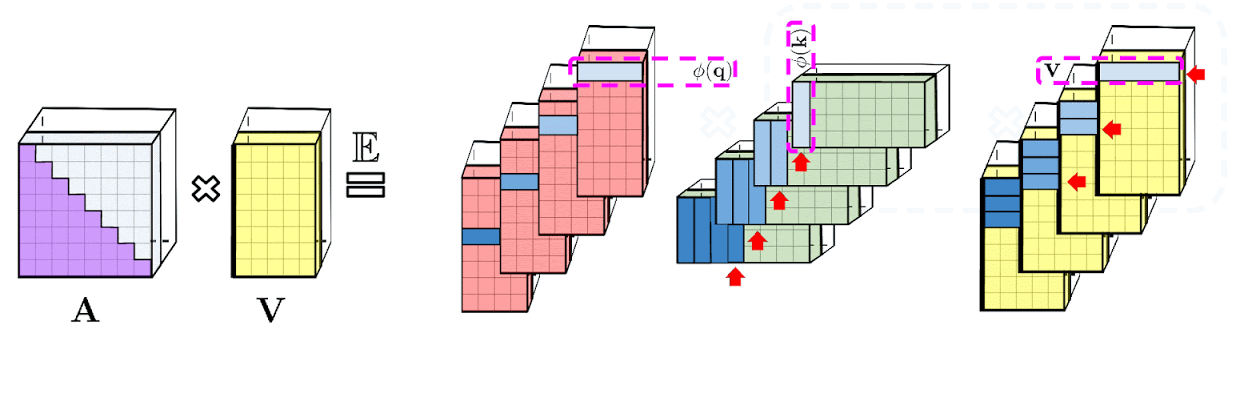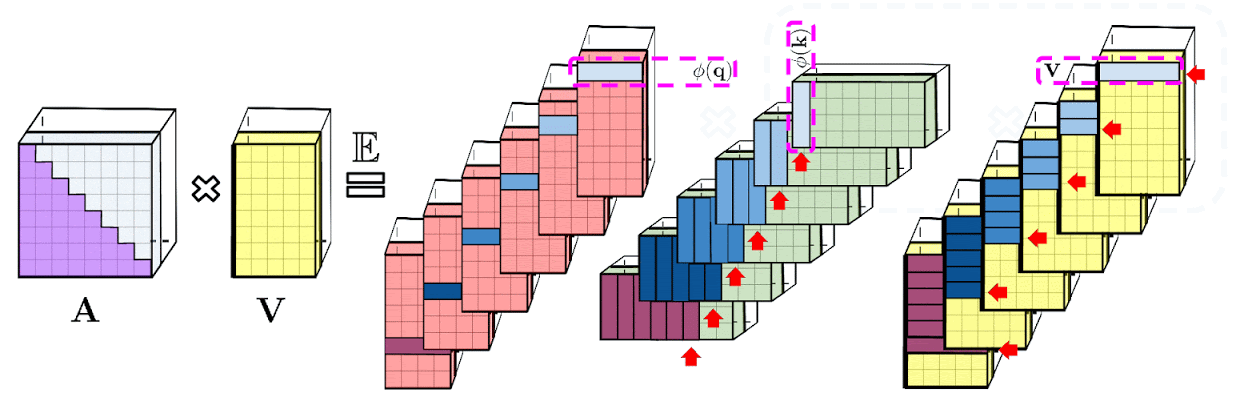
: , . : , .
Performer , , , .
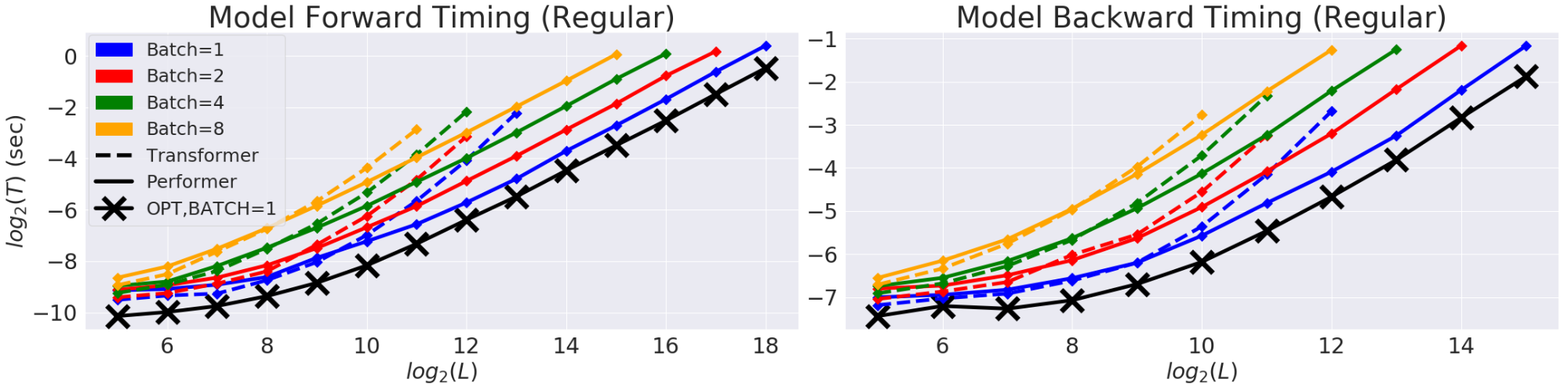
(T) (L). GPU. (X) «» , , , . Performer .
, Performer, -, , .
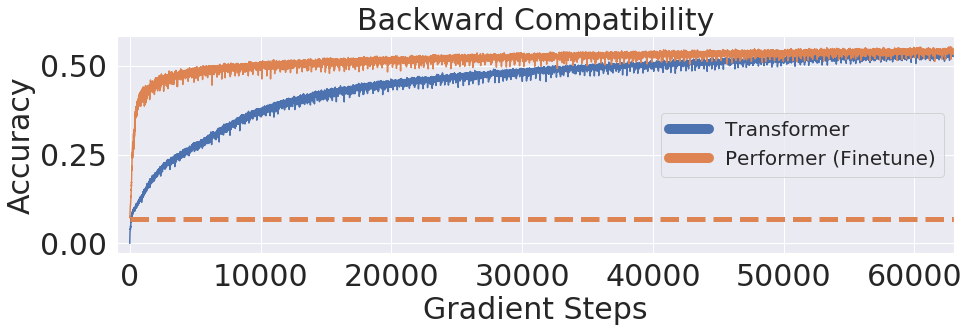
One Billion Word Benchmark (LM1B), Performer, 0.07 ( ). Performer .
:
— , . , , 20 . (, UniRef) , . Performer-ReLU ( ReLU, , ) , Performer-Softmax (accuracy) , .
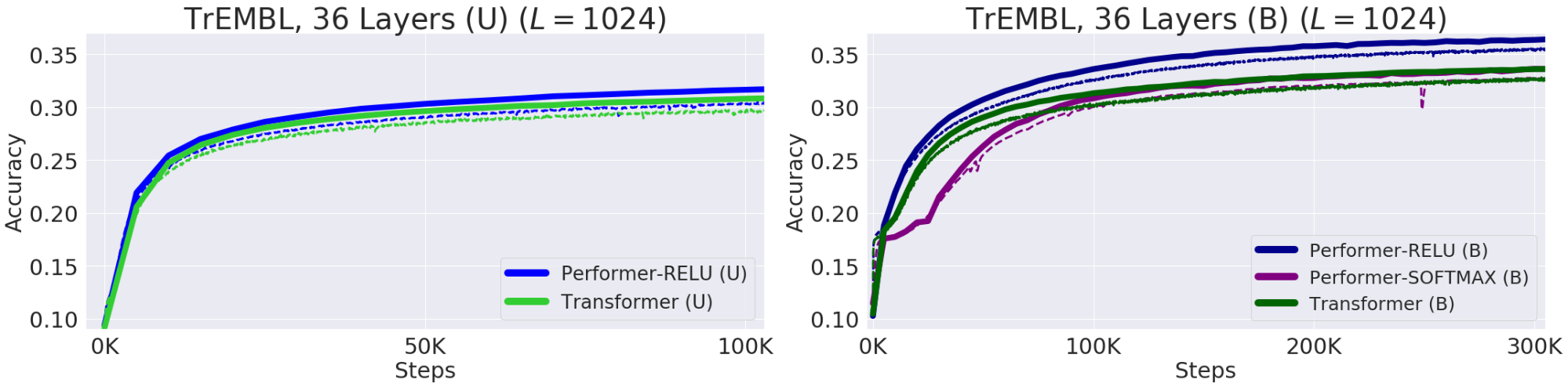
. (Train) — , (Validation) – , — (U), — (B). 36 ProGen (2019) , 16x16 TPU-v2. .
Protein Performer, ReLU. Performer , , . , , . Performer' . , , Performer - .
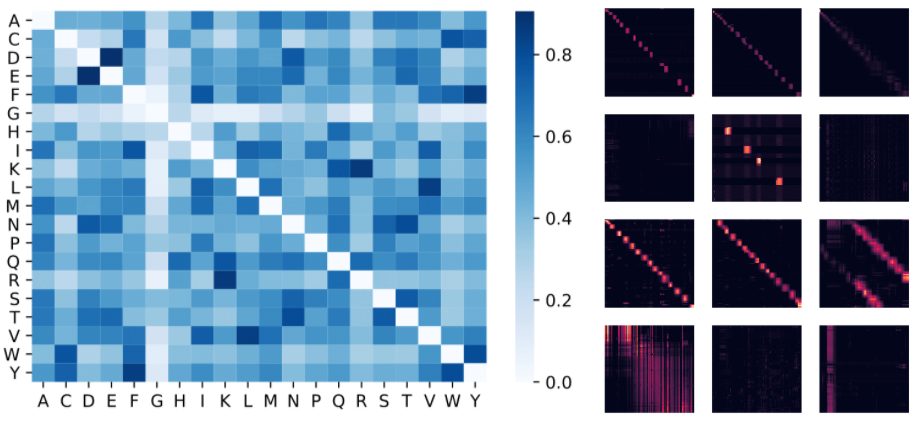
: , . , (D, E) (F, Y), . : 4 () 3 «» () BPT1_BOVIN, .
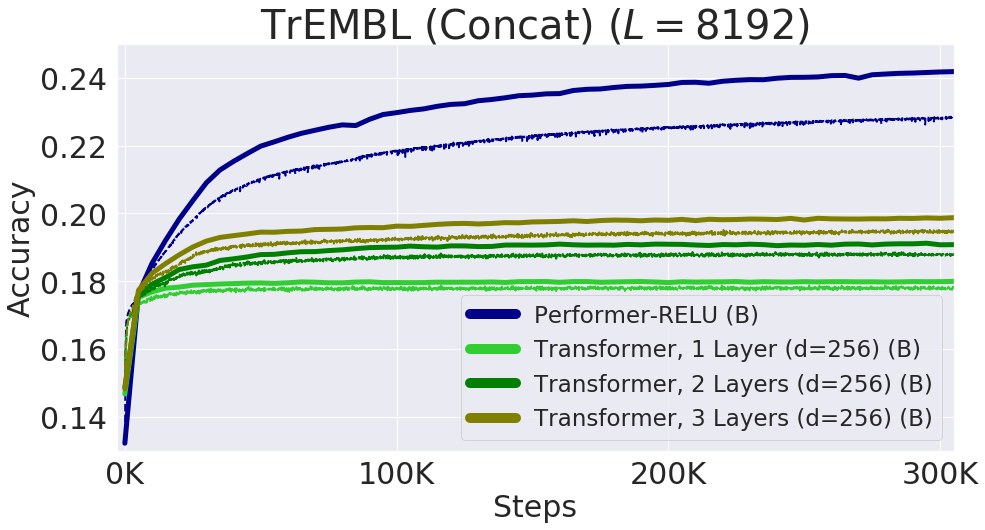
8192, . TPU, ( ) .
, . , , FAVOR Reformer. , Performer' . , , .
- — Krzysztof Choromanski, Lucy Colwell
- —
- 编辑和排版-谢尔盖Shkarin