
传统上,在10月,重点再次放在GPT-3上。来自OpenAI的有关该模型的新闻有好几个-不太好。
OpenAI与Microsoft达成交易
我们必须从一个不太愉快的故事开始-微软接管了GPT-3的专有权。可以预见的是,这笔交易激起了人们的愤慨-OpenAI的创始人埃隆·马斯克(Elon Musk)现在是该公司董事会的前成员,他说微软实际上已经接管了OpenAI。
事实是,OpenAI最初是作为一个具有很高使命的非营利组织创建的-不允许人工智能掌握在单独的州或公司的手中。该组织的创始人呼吁在这一领域开放研究,以便技术为全人类的利益而努力。
微软辩护说,他们不会限制对模型API的访问。因此,实际上,什么都没有改变-在此之前OpenAI也没有发布代码,但是如果以前甚至合作伙伴公司仅被允许通过API与GPT-3一起工作,那么Microsoft现在拥有专有使用权。
来自Sberbank的ruGPT3
现在,更令人高兴的消息是-来自Sberbank的研究人员发布了一种开放访问的模型,该模型重复了GPT-3架构,该模型基于GPT-2代码,最重要的是接受了俄语语料库的培训。
收集了俄罗斯文学作品,维基百科数据,新闻和问答网站的快照,门户网站Pikabu,22century.ru banki.ru和Omnia Russica的资料,作为培训的数据集。开发人员还包括来自GitHub和StackOverflow的数据,以教授如何生成和编程代码。清除的数据总量超过600 GB。
这个消息肯定是好消息,但有一些警告。该模型类似于GPT-3,但不相似。作者自己承认它比最大版本的GPT-3(拥有1,750亿重量)小230倍,这意味着它无法完全重复基准测试结果。也就是说,不要指望这种模型编写的文本与新闻文本没有区别。
还值得考虑的是,所描述的GPT-3架构可能与实际实现有所不同。您只能在阅读训练参数之后才能确定地说,并且如果在权重发布之前有所延迟,那么鉴于最近发生的事件,就不能指望它们。
事实是,项目预算取决于培训参数的数量,而据专家介绍,GPT-3的培训费用至少为1000万美元。因此,只有拥有强大ML专家和强大计算资源的大型公司才能复制OpenAI的工作。
2020年AI状况报告
以上所有内容都证实了关于机器学习领域的第三次年度报告的结论。专门从事AI初创企业的投资者Nathan Benaich和Ian Hogarth发布了一份详细演讲,内容涵盖技术,人力资源,工业应用和法律复杂性。
奇怪的是,多达85%的研究是在没有源代码的情况下发布的。如果可以通过将代码经常编入项目的基础结构这一事实来证明商业组织是合理的,那么研究机构和DeepMind和OpenAI等非营利性公司呢?
还有人说,数据集和模型的增加导致预算的增加,并且鉴于机器学习领域的停滞,每项新突破都需要不成比例的庞大预算(比较GPT-2和GPT-3的大小),这意味着他们可以负担得起只有大公司。
我们建议您熟悉本文档,因为该文档简洁明了,说明清楚。另外,上一份报告对2020年的四项预测已经实现。
我们不会进一步夸大其词,这里仍然有好故事,否则该收藏将不存在。
从Google和Facebook打开多语言模型
5号
Google已经发布了T5系列多语言模型的源代码和数据集。由于与OpenAI有关的大肆宣传,尽管规模令人印象深刻,但几乎没有注意到此消息-最大的模型具有130亿个参数。
为了进行培训,使用了101种语言的数据集,其中俄语位居第二。我们的强大和强大是网络上第二受欢迎的地方,这可以解释为事实。
M2M-100
Facebook也紧随其后,并提出了一种多语言模型,根据他们的说法,该模型允许直接翻译100x100语言对而无需中间语言。
在机器翻译领域,习惯上为每种单独的语言和任务创建和训练模型。但是在Facebook的情况下,由于社交网络的用户以160多种语言发布内容,因此这种方法无法有效扩展。
通常,一次处理多种语言的多语言系统依赖英语。翻译是中间和不精确的。由于数据不足,很难弥合源语言和目标语言之间的差距,因为很难找到从中文到法语的翻译,反之亦然。为此,创作者必须通过反向翻译生成合成数据。
本文提供了基准,该模型比依赖英语的类似物更好地解决了翻译问题,并提供了到数据集的链接。

视频会议的进展
10月,来自Nvidia的一些有趣消息立刻出现了。
样式GAN2
首先,我们发布了StyleGAN2的更新。现在,低资源模型体系结构在具有少于30,000张图像的数据集上提供了改进的性能。新版本引入了对混合精度的支持:训练速度提高了约1.6倍,推理速度提高了1.3倍,GPU消耗降低了1.5倍。我们还添加了模型超参数的自动选择:针对不同分辨率和不同数量的可用图形处理器的数据集的现成解决方案。
尼莫
神经模块是一个开源工具包,可帮助您快速创建,训练和调整对话模型。NeMo由一个核心组成,该核心为所有模型和集合提供单一的“外观”,由按作用域分组的模块组成。
马辛
另一个已发布的产品可能会在内部使用上述两种技术。Maxine视频通话平台结合了整个机器学习算法。这包括已经熟悉的分辨率提高,噪声消除,背景去除以及矫正凝视和阴影,通过关键的面部特征(即深造假)恢复图片,生成字幕以及将语音实时翻译成其他语言。就是说,Nvidia几乎将以前单独遇到的所有内容组合成一个数字产品。您现在可以申请抢先体验。
Google的新发展
由于隔离,今年在视频会议领域确实是领导者的真正竞赛。 Google Meet分享了一个案例研究,该案例基于Mediapipe框架(可以跟踪眼睛,头部和手部的运动),创建了用于高质量背景去除的算法。
Google还为iOS上的YouTube故事服务推出了一项新功能,可改善语音质量。这是一个有趣的情况,因为与视频相比,视频可使用的增强器要多很多倍。该算法监视并记录语音和视觉标记(例如面部表情,嘴唇移动)之间的相关性,然后将其用于将语音与背景声音(包括来自其他扬声器的声音)分离。
该公司还提出了新的尝试在手语识别领域。
说到视频会议软件,还值得一提的是新的Deepfake算法。
对话
最近,在开放访问中发布了仅依靠音频流对照片进行动画处理的算法代码。值得注意的是,因为通常Deepfake算法会将视频作为输入。

难以置信
新一代的Deepfake算法将自己的任务设定为不仅要替换脸部,还要替换整个身体,包括头发的颜色,肤色和身材。这项技术将主要用于在线购物领域,因此您可以使用品牌本身提供的商品照片,而不必租用个别模型。视频演示中可以看到更多的应用程序。到目前为止,这似乎令人信服,但很快一切都会改变。
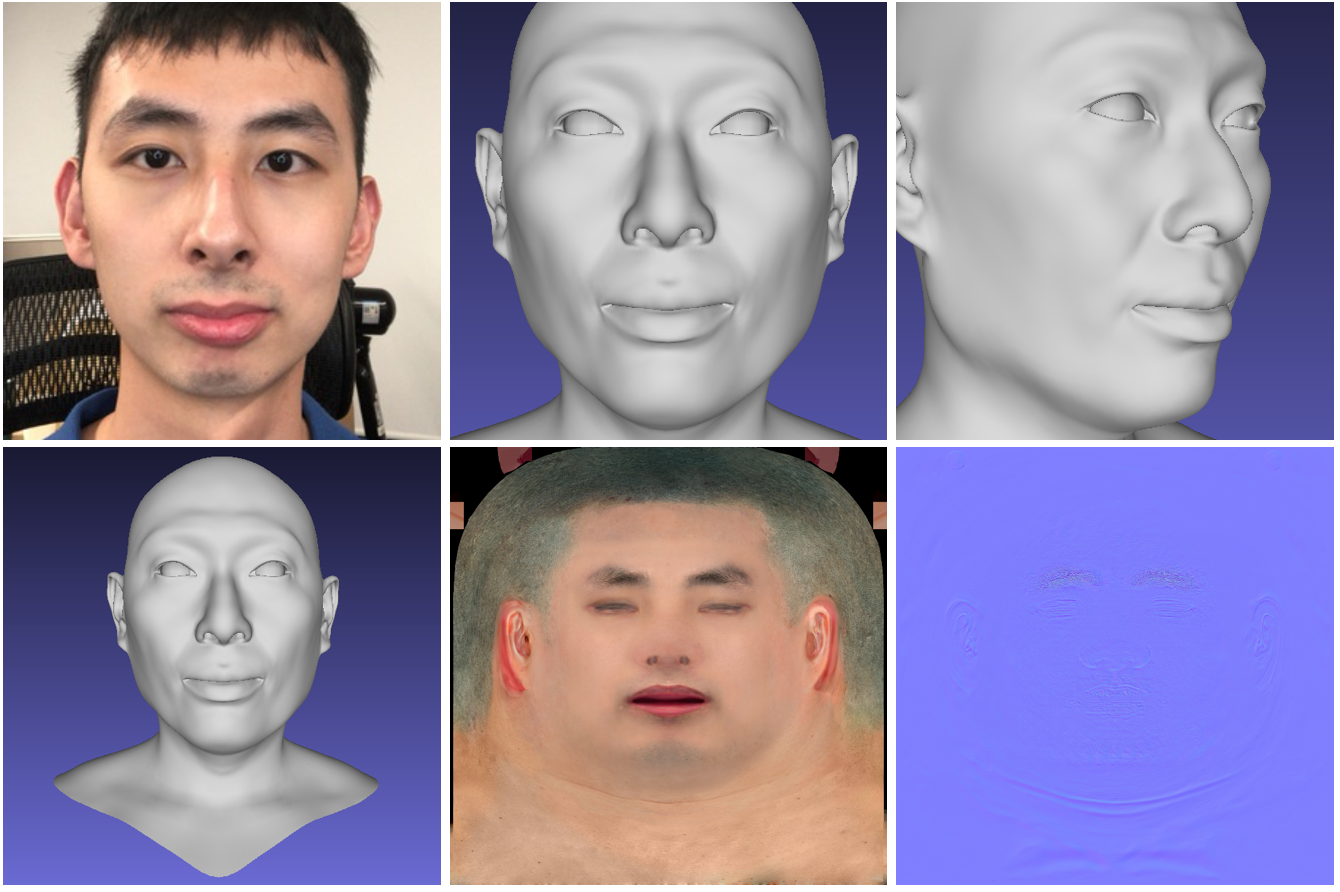
Hi-Fi 3D人脸
神经网络从照片生成人脸的高质量3D模型。该模型接受来自常规RGB-D摄像机的短视频作为输入,并在输出处提供生成的面部3D模型。项目代码和3DMM模型是公开可用的。

SkyAR
作者介绍了一种开源技术,可以用视频实时替换天空,这也使您可以控制样式。可以在目标视频上生成天气效果,例如闪电。
管道模型分阶段解决了许多任务:网格使天空无光,跟踪移动的对象,对图像进行包装和重新着色以匹配天空盒的配色方案。

海通
该工具解决了在水下图像中还原真实色彩的艰巨任务。即,该算法考虑到对象的深度和距离,以便恢复照明并从图像中去除水。到目前为止,仅数据集可用。
用于诊断Covid-19的MIT模型
总之,我们将在一个相关主题上分享一个有趣的案例-麻省理工学院的研究人员开发了一种模型,该模型可通过强迫咳嗽记录将无症状冠状病毒感染的患者与健康人区分开。
该模型已在成千上万的咳嗽录音带上进行了训练。根据麻省理工学院的说法,该算法可以识别出已确认患有Covid-19的人,其准确性为98.5%。
政府当局已经批准了该应用程序的创建。用户将能够下载咳嗽的录音,并根据结果确定是否有必要在实验室进行全面分析。
就这样,谢谢您的关注!