Bob Steagall最近在CppCon 2020上做了题为“ SIMD思维历险记”的演讲,除其他外,他谈到了他使用AVX512对窗口7进行中值滤波的经验。这句话给我两种感觉:一方面,这很酷,据称比最笨拙的STL实现快近20倍;另一方面,在一次算法中,从16个输入样本中得出的结果是,只有2个输出,尽管输入数据足以容纳10个,而且一些实现细节使我想尝试对其进行改进。我想了一下,想到了一个主意,然后提出了一个主意,然后在“软件中”尝试了一下,并意识到我有一些要分享的地方:)因此,这篇文章变成了事实。
基本实施
我将简要描述Bob的工作方式(实际上是对故事的相应部分以及他自己的照片的简短重述)。他使用AVX512制作了以下原语(我将省略他所描述的与唯一的AVX512操作直接对应的原语):
旋转:将AVX-512寄存器中的元素旋转一圈

带进位移位:从寄存器中移出项目,替换第二个寄存器中的项目
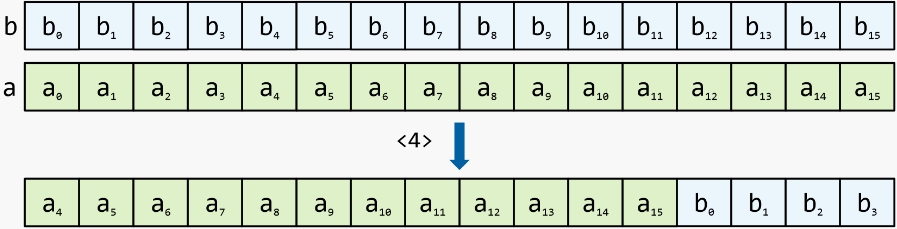
带进位的原位移位:与带进位的移位类似,但是输入寄存器通过引用传递,移位结果保留在其中
与交换比较:并行地对一个寄存器中的8对元素进行排序

, , : perm 0..15, ; mask 1 «» . : , perm. vmin , vmax ́ . , .
, , . :
1) shift with carry, «» , «» (.. 0 0..6, 1 — 1..7 . .)
2) , 0 , 1 —
3) 7 , — 6 compare and exchange, . — — .
0
- , . , , ( , L2). , . AVX-512…
1
, — . 7 ; 6 !

, 6 r1-r6 , r0 r7? S[0..5], X, , S[3] .
X >= S[3], S[3] ,X <= S[2], S[2] S[3], S[2]S[2] < X < S[3], X S[3], , X. ,clamp(X, S[2], S[3])=>min(max(X, S[2]), S[3])!
:
«» 4 7- ( 0, 7, 2, 9) – X 4
6- 1..6 3..8 ( 0..7 8..15, )
6-
clamp 2 3 X[0] X[1], 2 3 X[2] X[3]
2x — 2 ( 6 5 , 7 — 6), clamp . : 1,86x . . ?
2
«» X . 6- ; 5 , 2 ( 3 ). — : S[0] <=> S[1], S[2] <=> S[3], S[4] <=> S[5]
2, . . , , !

— 2 , 2 . , : 1.06x. , .
3
- , 1, 6- .

, 4 ( ), 6; , 4- ?
2 , 4- . 6- : 2- Y 4- S, 2 3 ( Z). , min(Y[0], S[0]) => Z[0], ; max(Y[0], S[0]) Z[1]..Z[5] – . max(Y[1], S[3]) , min(Y[1], S[3]).
4- S[1], S[2], min/max. , 4 , 1 2 — 2 3 6- . , «» 4- S[1] S[2], — . , 2 , Y.
:
r1-r2 . .
— Y, r1-2, r5-6, r7-8, r11-12; permute 4 , Y r0-1, r4-5 . .
( ) «» ; r3-r6 r7-r10
max min Y[0]/S[0], Y[1]/S[3]
mask_permute Y S, S[1] S[2] ,
4
1 2, min/max X 8
, , , 2. — 1.64x , 2, 3 , .
; ( - permute; , - ), .
, :)
benchmark:
512 : 3.1-3.2 ; 7.3 , memcpy avx-512
50 : 2.8-2.9 ; 1.8 , memcpy (!)
.
5? , (disclaimer: — ).
16- 12 .
- 3 ( …)
1 , 4 ( 6 ) 4- — , . . 4 , 5 ; 8 .
2 , — 2 ; , .
3 , . , — , 12 . , «» — 24 , 12 .
9? 8 .
—
1 — 2 8- 4 , 4 ( 7 6 )
2 — , -
3 — , — 6- 2, 6- ( , ) , 8-.
, - . , https://github.com/tea/avx-median/. « », , -. , .
- , — . .
UPDATE
AVX2 . , , , , ( , 16 , ). , : 1.64x , .
事实证明,并没有失去所有的东西-第一个优化步骤也可以应用于此变体!您需要收集X的32条边,需要弄乱数据以进行排序,还需要对已排序的数据进行置换等,但是尽管有所有这些手势,我们的加速度还是为1.27倍。
我没有尝试执行步骤2和3,因为它显然会更慢。对于带有窗口11的情况,它们很有可能会发挥作用(但我不知道是否有人需要带有大窗口的快速一维中值滤波器)。