使用CUDA运行时API进行计算。CPU和GPU计算的比较
在本文中,我决定比较在CPU和GPU上用C ++编写的算法的执行情况(在支持的Nvidia GPU上使用Nvidia CUDA运行时API进行计算)。CUDA API允许在GPU上执行一些计算。使用cuda的c ++文件的扩展名为.cu。
该算法如下所示。
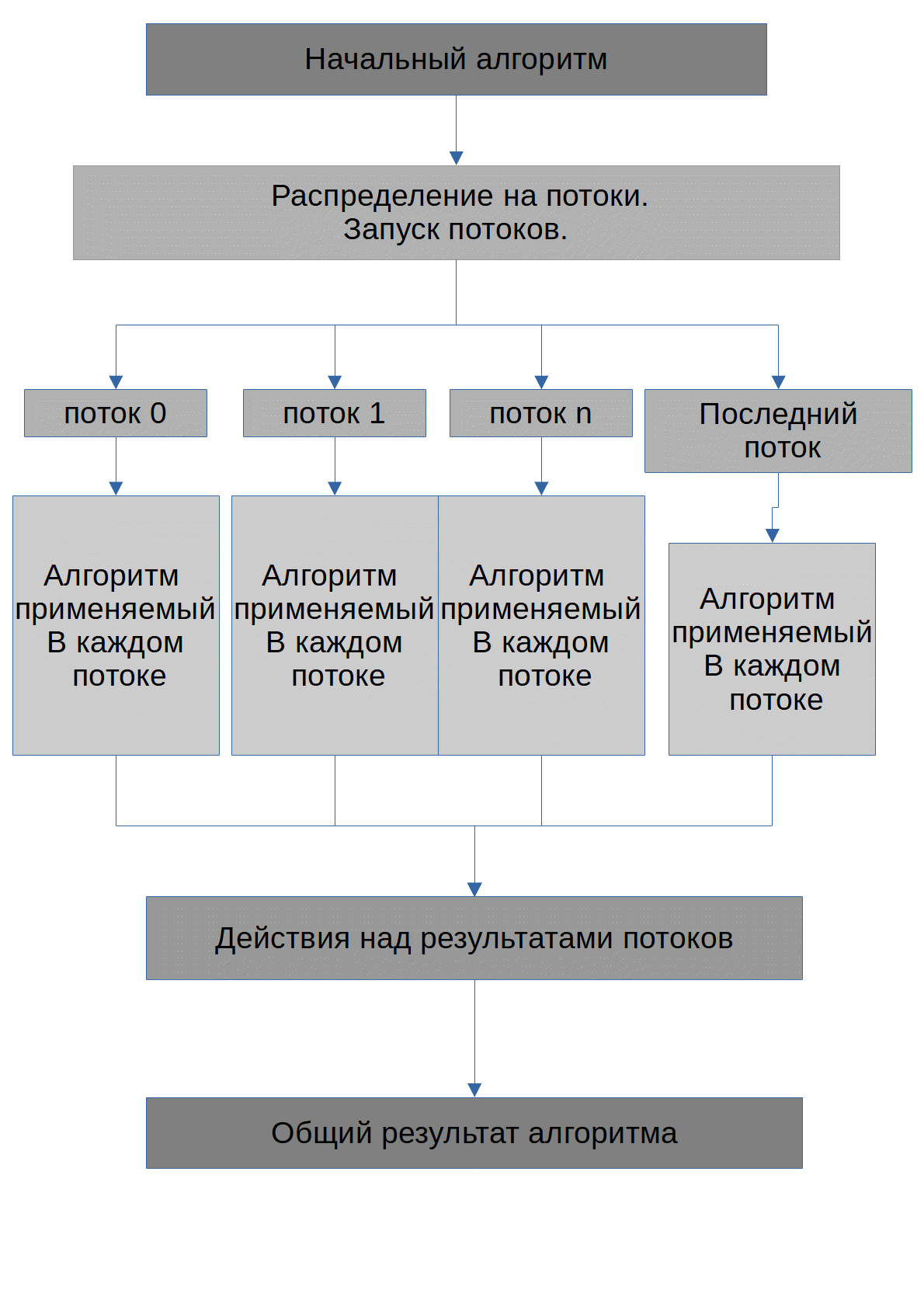
该算法的任务是找到可能的数字X,当将其提高到程度degree_of时,将获得初始数字max_number。我马上注意到,将要传输到GPU的所有数字都将存储在数组中。每个线程执行的算法如下所示:
int degree_of=2;
int degree_of_max=Number_degree_of_max[0];//
int x=thread;//
int max_number=INPUT[0];// ,
int Number=1;
int Degree;
bool BREAK=false;// while
while(degree_of<=degree_of_max&&!BREAK){
Number=1;
for(int i=0;i<degree_of;i++){
Number*=x;
Degree=degree_of;
}
if(Number==max_number){
OUT_NUMBER[thread]=X;//OUT_NUMBER Degree
OUT_DEGREE[thread]=Degree;// OUT_DEGREE X
}
degree_of++;
// :
if(degree_of>degree_of_max||Number>max_number){
BREAK=true;
}
}
在CPU C ++上执行的代码。
#include <iostream>
#include<vector>
#include<string>// getline
#include<thread>
#include<fstream>
using namespace std;
int Running_thread_counter = 0;
void Upload_to_CPU(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max, int THREAD);
void Upload_to_CPU(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max, int THREAD) {
int thread = THREAD;
Running_thread_counter++;
unsigned long long MAX_DEGREE_OF = max[0];
int X = thread;
unsigned long long Calculated_number = 1;
unsigned long long DEGREE_OF = 2;
unsigned long long INP = INPUT[0];
Stop[thread] = false;
bool BREAK = false;
if (X != 0 && X != 1) {
while (!BREAK) {
if (DEGREE_OF <= MAX_DEGREE_OF) {
Calculated_number = 1;
for (int counter = 0; counter < DEGREE_OF; counter++) {
Calculated_number *= X;
}
if (Calculated_number == INP) {
Stepn[thread] = DEGREE_OF;
Number[thread] = X;
Stop[thread] = true;
BREAK = true;
}
DEGREE_OF++;
}
else { BREAK = true; }
}
}
}
void Parallelize_to_threads(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max, int size);
int main()
{
int size = 1000;
unsigned long long *Number = new unsigned long long[size], *Degree_of = new unsigned long long[size];
unsigned long long *Max_Degree_of = new unsigned long long[1];
unsigned long long *INPUT_NUMBER = new unsigned long long[1];
Max_Degree_of[0] = 7900;
INPUT_NUMBER[0] = 216 * 216 * 216;
ifstream inp("input.txt");
if (inp.is_open()) {
string t;
vector<unsigned long long>IN;
while (getline(inp, t)) {
IN.push_back(stol(t));
}
INPUT_NUMBER[0] = IN[0];//
Max_Degree_of[0] = IN[1];//
}
else {
ofstream error("error.txt");
if (error.is_open()) {
error << "No file " << '"' << "input.txt" << '"' << endl;
error << "Please , create a file" << '"' << "input.txt" << '"' << endl;
error << "One read:input number" << endl;
error << "Two read:input max stepen" << endl;
error << "." << endl;
error.close();
INPUT_NUMBER[0] = 1;
Max_Degree_of[0] = 1;
}
}
// ,
//cout << INPUT[0] << endl;
bool *Elements_that_need_to_stop = new bool[size];
Parallelize_to_threads(Number, Degree_of, Elements_that_need_to_stop, INPUT_NUMBER, Max_Degree_of, size);
vector<unsigned long long>NUMBER, DEGREEOF;
for (int i = 0; i < size; i++) {
if (Elements_that_need_to_stop[i]) {
if (Degree_of[i] < INPUT_NUMBER[0] && Number[i] < INPUT_NUMBER[0]) {//
NUMBER.push_back(Number[i]);
DEGREEOF.push_back(Degree_of[i]);
}
}
}
// ,
//
/*
for (int f = 0; f < NUMBER.size(); f++) {
cout << NUMBER[f] << "^" << DEGREEOF[f] << "=" << INPUT_NUMBER[0] << endl;
}
*/
ofstream out("out.txt");
if (out.is_open()) {
for (int f = 0; f < NUMBER.size(); f++) {
out << NUMBER[f] << "^" << DEGREEOF[f] << "=" << INPUT_NUMBER[0] << endl;
}
out.close();
}
}
void Parallelize_to_threads(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max, int size) {
thread *T = new thread[size];
Running_thread_counter = 0;
for (int i = 0; i < size; i++) {
T[i] = thread(Upload_to_CPU, Number, Stepn, Stop, INPUT, max, i);
T[i].detach();
}
while (Running_thread_counter < size - 1);//
}
为了使算法起作用,需要具有初始编号和最大程度的文本文件。
用于执行GPU计算的代码C ++。Cu
// cuda_runtime.h device_launch_parameters.h
// cyda
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include<vector>
#include<string>// getline
#include <stdio.h>
#include<fstream>
using namespace std;
__global__ void Upload_to_GPU(unsigned long long *Number,unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT,unsigned long long *max) {
int thread = threadIdx.x;
unsigned long long MAX_DEGREE_OF = max[0];
int X = thread;
unsigned long long Calculated_number = 1;
unsigned long long Current_degree_of_number = 2;
unsigned long long Original_numberP = INPUT[0];
Stop[thread] = false;
bool BREAK = false;
if (X!=0&&X!=1) {
while (!BREAK) {
if (Current_degree_of_number <= MAX_DEGREE_OF) {
Calculated_number = 1;
for (int counter = 0; counter < Current_degree_of_number; counter++) {
Calculated_number *=X;
}
if (Calculated_number == Original_numberP) {
Stepn[thread] = Current_degree_of_number;
Number[thread] = X;
Stop[thread] = true;
BREAK = true;
}
Current_degree_of_number++;
}
else { BREAK = true; }
}
}
}
cudaError_t Configure_cuda(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max,unsigned int size);
int main()
{
int size = 1000;
unsigned long long *Number=new unsigned long long [size], *Degree_of=new unsigned long long [size];
unsigned long long *Max_degree_of = new unsigned long long [1];
unsigned long long *INPUT_NUMBER = new unsigned long long [1];
Max_degree_of[0] = 7900;
ifstream inp("input.txt");
if (inp.is_open()) {
string text;
vector<unsigned long long>IN;
while (getline(inp, text)) {
IN.push_back( stol(text));
}
INPUT_NUMBER[0] = IN[0];
Max_degree_of[0] = IN[1];
}
else {
ofstream error("error.txt");
if (error.is_open()) {
error<<"No file "<<'"'<<"input.txt"<<'"'<<endl;
error<<"Please , create a file" << '"' << "input.txt" << '"' << endl;
error << "One read:input number" << endl;
error << "Two read:input max stepen" << endl;
error << "." << endl;
error.close();
INPUT_NUMBER[0] = 1;
Max_degree_of[0] = 1;
}
}
bool *Elements_that_need_to_stop = new bool[size];
// cuda
cudaError_t cudaStatus = Configure_cuda(Number, Degree_of, Elements_that_need_to_stop, INPUT_NUMBER, Max_degree_of, size);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
vector<unsigned long long>NUMBER, DEGREEOF;
for (int i = 0; i < size; i++) {
if (Elements_that_need_to_stop[i]) {
NUMBER.push_back(Number[i]);//
DEGREEOF.push_back(Degree_of[i]);//
}
}
// ,
/*
for (int f = 0; f < NUMBER.size(); f++) {
cout << NUMBER[f] << "^" << DEGREEOF[f] << "=" << INPUT_NUMBER[0] << endl;
}*/
ofstream out("out.txt");
if (out.is_open()) {
for (int f = 0; f < NUMBER.size(); f++) {
out << NUMBER[f] << "^" << DEGREEOF[f] << "=" << INPUT_NUMBER[0] << endl;
}
out.close();
}
//
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
cudaError_t Configure_cuda(unsigned long long *Number, unsigned long long *Degree_of, bool *Stop,unsigned long long *INPUT, unsigned long long *max,unsigned int size) {
unsigned long long *dev_Number = 0;
unsigned long long *dev_Degree_of = 0;
unsigned long long *dev_INPUT = 0;
unsigned long long *dev_Max = 0;
bool *dev_Elements_that_need_to_stop;
cudaError_t cudaStatus;
// GPU
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
//
cudaStatus = cudaMalloc((void**)&dev_Number, size * sizeof(unsigned long long));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_Number");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_Degree_of, size * sizeof(unsigned long long));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_Degree_of");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_Max, size * sizeof(unsigned long long int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_Max");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_INPUT, size * sizeof(unsigned long long));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_INPUT");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_Elements_that_need_to_stop, size * sizeof(bool));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_Stop");
goto Error;
}
// GPU
cudaStatus = cudaMemcpy(dev_Max, max, size * sizeof(unsigned long long), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_INPUT, INPUT, size * sizeof(unsigned long long), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Upload_to_GPU<<<1, size>>>(dev_Number, dev_Degree_of, dev_Elements_that_need_to_stop, dev_INPUT, dev_Max);
//
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// ,
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// GPU
cudaStatus = cudaMemcpy(Number, dev_Number, size * sizeof(unsigned long long), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(Degree_of, dev_Degree_of, size * sizeof(unsigned long long), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(Stop, dev_Elements_that_need_to_stop, size * sizeof(bool), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:// GPU
cudaFree(dev_INPUT);
cudaFree(dev_Degree_of);
cudaFree(dev_Max);
cudaFree(dev_Elements_that_need_to_stop);
cudaFree(dev_Number);
return cudaStatus;
}
识别码
__global__ 要使用CUDA API,在调用函数之前,您需要为阵列保留内存并将元素传输到GPU内存。由于计算是在GPU上完成的,因此这增加了代码量,但允许卸载CPU,因此cuda至少为卸载不使用cuda的其他工作负载提供了卸载处理器的机会。
在cuda上的示例中,处理器的任务仅是在GPU上加载指令并处理来自GPU的结果。在CPU的代码中,处理器处理每个线程。值得注意的是,cyda在可启动的线程数上有限制,因此在两种算法中,我都使用了等于1000的相同线程数。此外,对于CPU,我使用了变量
int Running_thread_counter = 0;计算已经执行的线程数,然后等待所有线程执行完毕。
测试配置
CUDA GPU-Z
- CPU :amd ryzen 5 1400(4core,8thread)
- :8DDR4 2666
- GPU:Nvidia rtx 2060
- OS:windows 10 version 2004
- Cuda:
- Compute Capability 7.5
- Threads per Multiprocessor 1024
- CUDA 11.1.70
- GPU-Z:version 2.35.0
- Visual Studio 2017
CUDA GPU-Z
为了测试算法,我使用了
以下C#代码
,它使用初始数据创建了一个文件,然后使用CPU或GPU顺序启动算法的exe文件并测量其运行时间,然后将该时间和算法的结果输入到文件result.txt中。Windows任务管理器用于测量处理器负载。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Diagnostics;
using System.IO;
namespace ConsoleAppTESTSTEPEN_CPU_AND_GPU_
{
class Program
{
static string Upload(Int64 number,Int64 degree_of)
{
string OUT = "";
string[] Chord_values = new string[2];
Int64 Degree_of = degree_of;
Int64 Number = number;
Chord_values[0] = Number.ToString();
Chord_values[1] = Degree_of.ToString();
File.WriteAllLines("input.txt", Chord_values);//
OUT+="input number:" + Number.ToString()+"\n";
OUT+="input degree of number:" + Degree_of.ToString()+"\n";
DateTime running_CPU_application = DateTime.Now;//
Process proc= Process.Start("ConsoleApplication29.exe");//exe c++ x64 CPU
while (!proc.HasExited) ;//
DateTime stop_CPU_application = DateTime.Now;//
string[]outs = File.ReadAllLines("out.txt");//
File.Delete("out.txt");
OUT+="CPU:"+"\n";
if (outs.Length>0)
{
for (int j = 0; j < outs.Length; j++)
{
OUT+=outs[j]+"\n";
}
}
else { OUT+="no values"+"\n"; }
OUT+="running_CPU_application:" + running_CPU_application.ToString()+"\n";
OUT+="stop_CPU_application:" + stop_CPU_application.ToString()+"\n";
OUT+="GPU:"+"\n";
// korenXN.exe x64 GPU
DateTime running_GPU_application = DateTime.Now;
Process procGPU = Process.Start("korenXN.exe");
while (!procGPU.HasExited) ;
DateTime stop_GPU_application = DateTime.Now;
string[] outs2 = File.ReadAllLines("out.txt");
File.Delete("out.txt");
if (outs2.Length > 0)
{
for (int j = 0; j < outs2.Length; j++)
{
OUT+=outs2[j]+"\n";
}
}
else { OUT+="no values"+"\n"; }
OUT+="running_GPU_application:" + running_GPU_application.ToString()+"\n";
OUT+="stop_GPU_application:" + stop_GPU_application.ToString()+"\n";
return OUT;//
}
static void Main()
{
Int64 start = 36*36;//
Int64 degree_of_strat = 500;//
int size = 20-5;//
Int64[] Number = new Int64[size];//
Int64[] Degree_of = new Int64[size];//
string[]outs= new string[size];//
for (int n = 0; n < size; n++)
{
if (n % 2 == 0)
{
Number[n] = start * start;
}
else
{
Number[n] = start * degree_of_strat;
Number[n] -= n + n;
}
start += 36*36;
Degree_of[n] = degree_of_strat;
degree_of_strat +=1000;
}
for (int n = 0; n < size; n++)
{
outs[n] = Upload(Number[n], Degree_of[n]);
Console.WriteLine(outs[n]);
}
System.IO.File.WriteAllLines("result.txt", outs);// result.txt
}
}
}
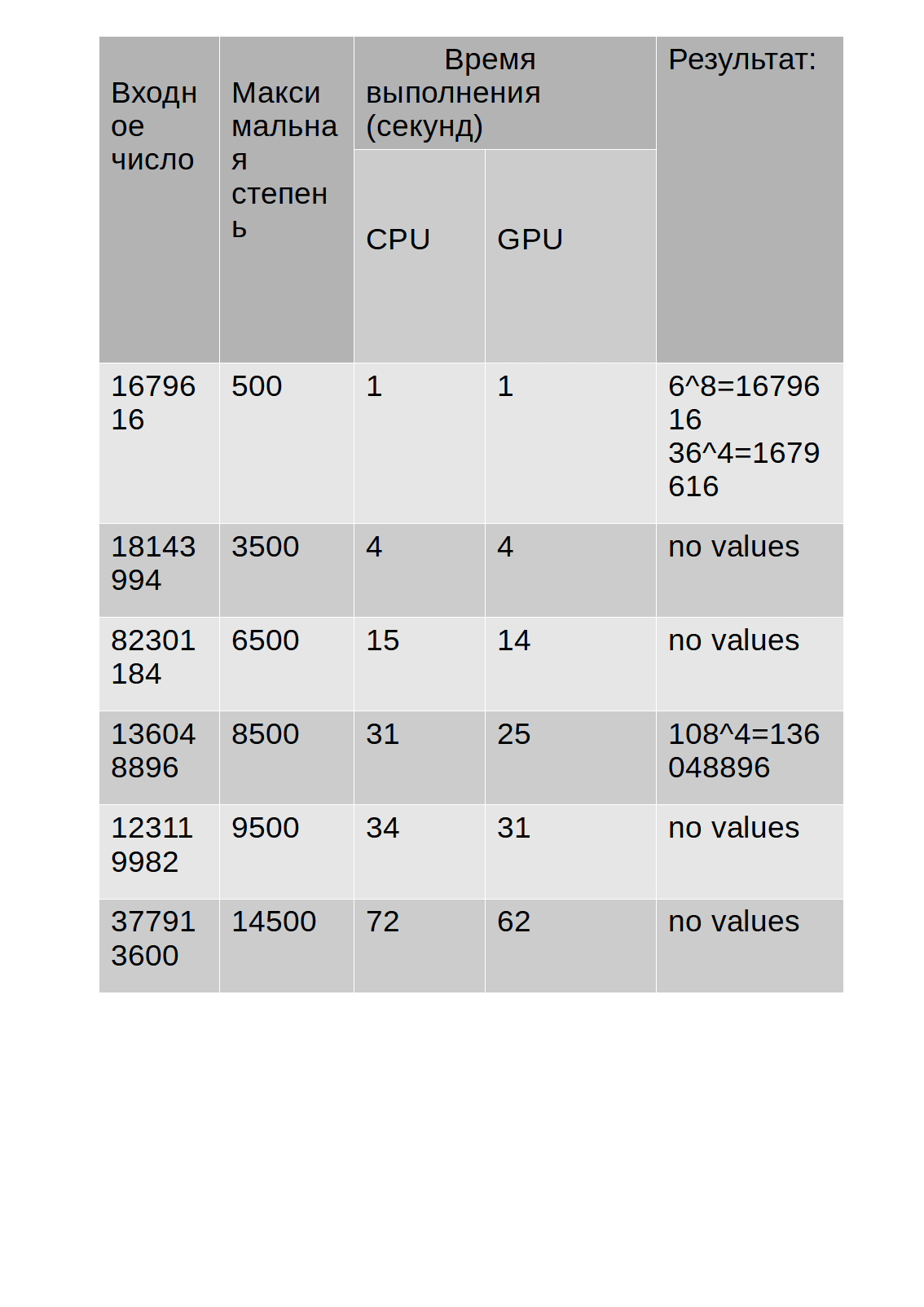
测试结果显示在表中:

从表中可以看到,算法在GPU上的执行时间比在CPU上的执行时间略长。
但是,我注意到在使用GPU进行算法运算的过程中,任务管理器中显示的CPU负载未超过30%,而使用CPU进行运算的算法将其负载在68-85%这有时会减慢其他应用程序的速度。另外,下图显示了
CPU和GPU的执行时间(Y轴)与输入数量(X轴)的差异。
时间表

然后,我决定测试装有其他应用程序的处理器。加载了处理器,以便在应用程序中启动的测试所占用的资源不超过处理器资源的55%。测试结果如下:
时间表
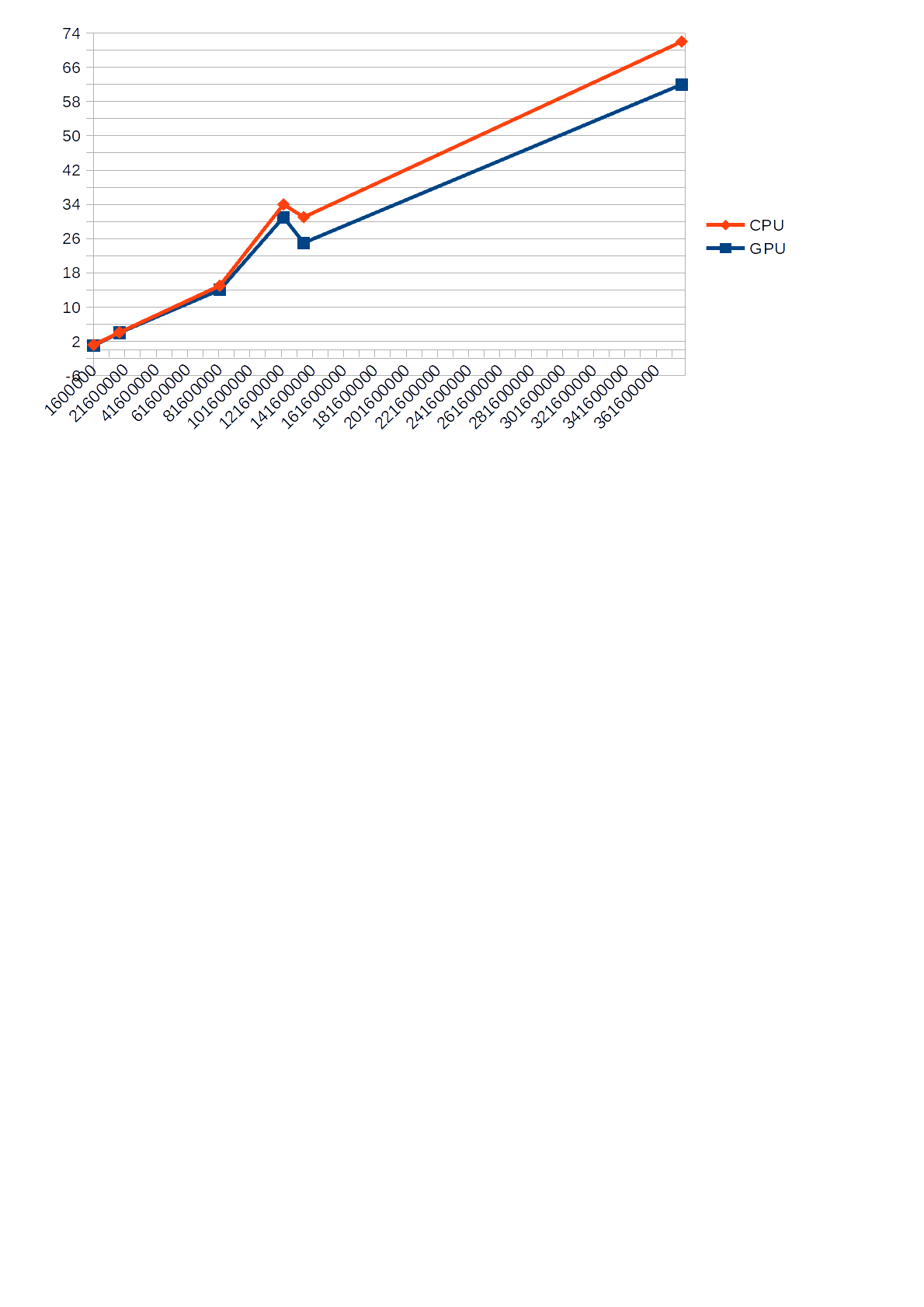
从表中可以看出,在CPU负载的情况下,在GPU上执行计算可以提高性能,因为30%的处理器负载在55%的限制之内,并且在使用CPU进行计算的情况下,其负载为68-85%,如果CPU装载了其他应用程序,则会减慢算法的运行速度。
我认为GPU落后于CPU的原因可能是CPU具有更高的核心性能(3400 MHz CPU,1680 MHz GPU)。在处理器内核加载其他进程的情况下,性能将取决于在特定时间间隔内处理的线程数,在这种情况下,GPU会更快,因为它能够同时处理更多线程(1024 GPU,8 CPU)。
因此,我们可以得出结论,使用GPU进行计算并不一定必须加快算法的运行速度,但是,它可以卸载CPU,如果将CPU加载到其他应用程序中,则可以发挥作用。