要以指定的频率生成所需的报告,编写相应的自定义报告资源就足够了。
使用场景
例如,在以下情况下,需要自定义计数报告:
- OpenShift, , (worker nodes) . . CPU , , -, , .
- OpenShift. Metering, , , , . , , , .
- 此外,在具有共享集群的情况下,运营部门将能够按团队和部门的pod的总运行时间(或在其上花费多少CPU或内存资源)将记录保存在团队和部门的上下文中。换句话说,我们再次对有关谁拥有该子实体的信息感兴趣。
要解决集群中的这些问题,创建某些自定义资源就足够了,我们接下来将做这些。安装Metering运算符不在本文讨论范围之内,因此如有必要,请参考安装文档。您可以在相关文档中了解有关如何使用标准计量报告的更多信息。
计量方式
在创建自定义资产之前,让我们先看一下计量。安装后,它将创建六种类型的自定义资源,我们将重点关注以下几种:
- ReportDataSources(RDS) -此机制允许您指定哪些数据将可用并可以在ReportQuery或自定义Report资源中使用。RDS还允许您从多个来源提取数据。在OpenShift中,数据是从Prometheus以及自定义ReportQuery(RQ)资源中提取的。
- ReportQuery (rq) – SQL- , RDS. RQ- Report, RQ- , . RQ- RDS-, RQ- Metering view Presto ( Metering) .
- Report – , , ReportQuery. , , , Metering. Report .
开箱即用,有许多RDS和RQ。由于我们主要对节点级报告感兴趣,因此我们将考虑其中的那些有助于您编写自定义查询的报告。在“ openshift-metering”项目中运行以下命令:
$ oc project openshift-metering
$ oc get reportdatasources | grep node
node-allocatable-cpu-cores
node-allocatable-memory-bytes
node-capacity-cpu-cores
node-capacity-memory-bytes
node-cpu-allocatable-raw
node-cpu-capacity-raw
node-memory-allocatable-raw
node-memory-capacity-raw
在这里,我们对两个RDS感兴趣:node-capacity-cpu-core和node-capput-capacity-capacity-raw,因为我们想获取有关CPU消耗的报告。让我们从node-capacity-cpu-core开始,并运行以下命令以查看其如何从Prometheus收集数据:
$ oc get reportdatasource/node-capacity-cpu-cores -o yaml
<showing only relevant snippet below>
spec:
prometheusMetricsImporter:
query: |
kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)
在这里,我们看到一个Prometheus请求,该请求从Prometheus提取数据并将其存储在Presto中。让我们在OpenShift指标控制台中执行相同的请求,然后查看结果。我们有一个OpenShift集群,其中有两个工作程序节点(每个具有16个核心)和三个主节点(每个具有8个核心)。最后一列,值,包含分配给该节点的核心数。

因此,数据被接收并存储在Presto表中。现在,让我们看看reportquery(RQ)定制资源:
$ oc project openshift-metering
$ oc get reportqueries | grep node-cpu
node-cpu-allocatable
node-cpu-allocatable-raw
node-cpu-capacity
node-cpu-capacity-raw
node-cpu-utilization
在这里,我们对以下RQS感兴趣:node-cpu-capacity和node-cpu-capacity-raw。顾名思义,这些指标既包含描述性数据(节点运行了多长时间,节点已分配了多少处理器,等等),也包含聚合数据。
我们感兴趣的两个RDS和两个RQS通过以下链相互连接:
node-cpu-capacity (rq) <b>uses</b> node-cpu-capacity-raw (rds) <b>uses</b> node-cpu-capacity-raw (rq) <b>uses</b> node-capacity-cpu-cores (rds)
可自定义的报告
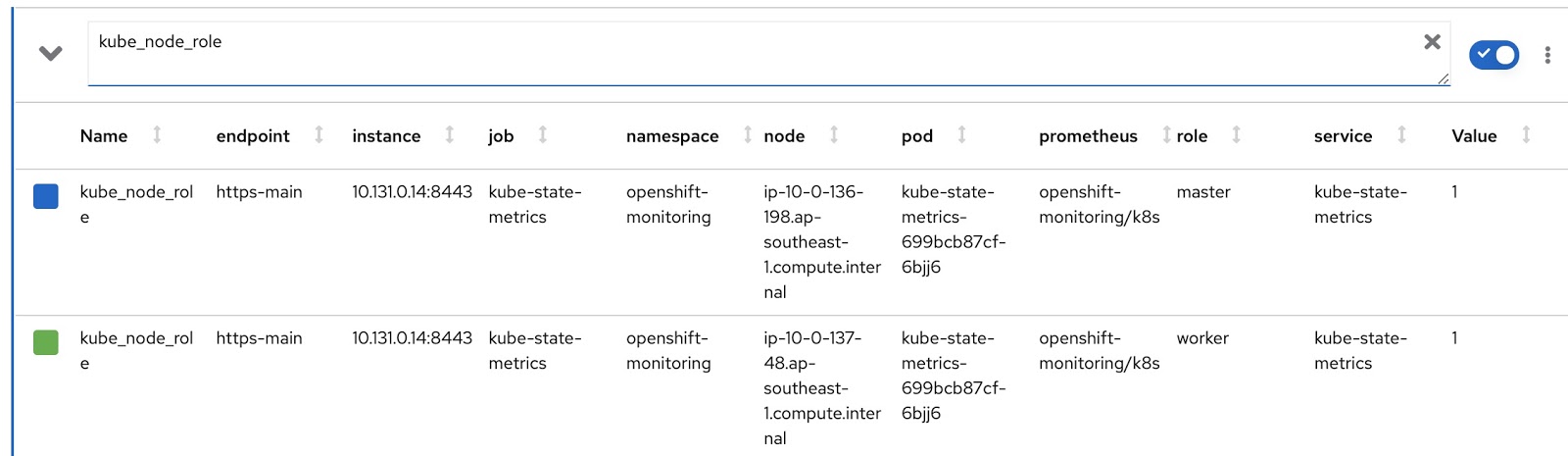
现在,让我们编写我们自己的RDS和RQ定制版本。我们需要更改Prometheus请求,以便它显示节点的模式(主/工作者)和相应的节点标签,该标签指示该节点属于哪个团队。节点操作模式包含在kube_node_role Prometheus指标中,请参阅角色列:
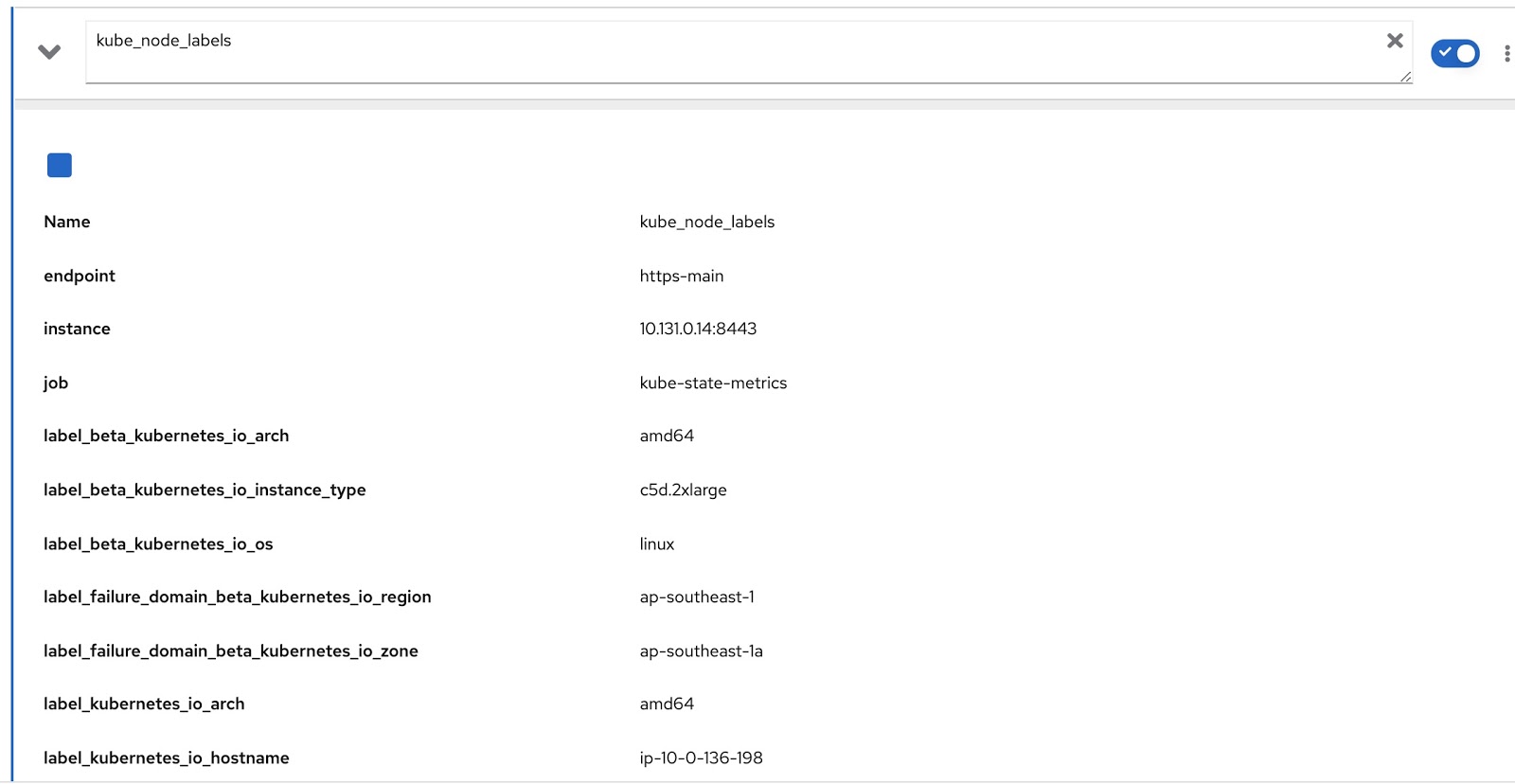
分配给该节点的所有标签都包含在Prometheus度量kube_node_labels中,在其中使用label_模板形成。例如,如果节点具有标签node_lob,则它将在Prometheus指标中显示为label_node_lob。
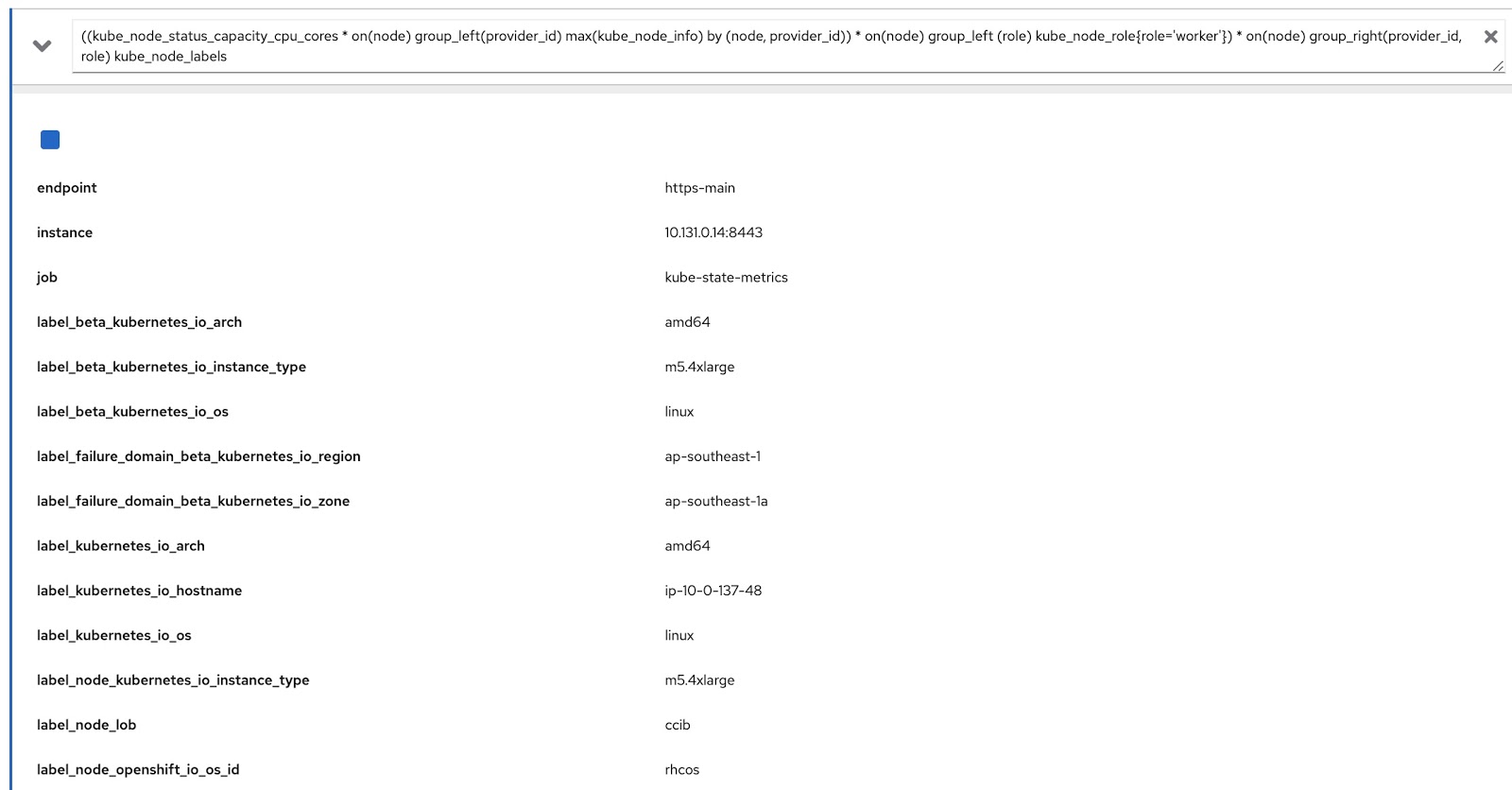
现在,我们只需要使用这两个Prometheus查询修改原始查询即可获取所需的数据,如下所示:
((kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)) * on(node) group_left (role) kube_node_role{role='worker'}) * on(node) group_right(provider_id, role) kube_node_labels
现在,让我们在OpenShift指标控制台中运行此查询,并确保它按标签(node_lob)和角色返回数据。在下面的图片中,首先是label_node_lob以及角色(它在那里,它只是没有出现在屏幕截图中):
因此,我们需要编写四个自定义资源(您可以从下面的列表中下载它们):
- rds-custom-node-capacity-cpu-cores.yaml-指定Prometheus请求。
- rq-custom-node-cpu-capacity-raw.yaml-引用来自步骤1的请求并输出原始数据。
- rds-custom-node-cpu-capacity-raw.yaml-引用步骤2中的RQ,并在Presto中创建视图对象。
- rq-custom-node-cpu-capacity-with-cpus-labels.yaml-引用条款3中的RDS,并考虑输入的报告开始日期和结束日期输出数据。此外,角色和标签列将提取到同一文件中。
创建了这四个yaml文件后,转到openshift-metering项目并执行以下命令:
$ oc project openshift-metering
$ oc create -f rds-custom-node-capacity-cpu-cores.yaml
$ oc create -f rq-custom-node-cpu-capacity-raw.yaml
$ oc create -f rds-custom-node-cpu-capacity-raw.yaml
$ oc create -f rq-custom-node-cpu-capacity-with-cpus-labels.yaml
现在只需编写一个自定义Report对象,该对象将引用步骤4中的RQ对象。例如,您可以按如下所示进行操作,以便报表立即运行并返回9月15日至30日的数据。
$ cat report_immediate.yaml
apiVersion: metering.openshift.io/v1
kind: Report
metadata:
name: custom-role-node-cpu-capacity-lables-immediate
namespace: openshift-metering
spec:
query: custom-role-node-cpu-capacity-labels
reportingStart: "2020-09-15T00:00:00Z"
reportingEnd: "2020-09-30T00:00:00Z"
runImmediately: true
$ oc create -f report-immediate.yaml
执行此报告后,可以从以下URL下载结果文件(csv或json)(只需将DOMAIN_NAME替换为您自己的URL):
metering-openshift-metering.DOMAIN_NAME / api / v1 / reports / get?名称= custom-role-node-cpu-每小时容量和名称空间= openshift-metering和格式= csv
如CSV文件的屏幕截图所示,它同时包含role和node_lob。要以秒为单位获取节点的正常运行时间,请将node_capacity_cpu_core_seconds除以node_capacity_cpu_cores:

结论
对于部署在任何地方的OpenShift群集,“计量”运算符都是一件很酷的事情。通过提供可扩展的框架,它使您可以创建自定义资源来生成所需的报告。本文中使用的所有源代码都可以在这里下载。