
寻找目标
我们进入专题网站miniclip.com,寻找目标。选择权属于“拼图”部分的颜色拼图“ Coloruid 2”,在该区域中,我们需要以给定的移动次数用一种颜色填充一个圆形的运动场。
屏幕底部选择的颜色填充了任意区域,而相同颜色的相邻区域合并为一个区域。

训练
我们将使用Python。该机器人仅用于教育目的。本文面向的是我本人,是计算机视觉的初学者。
游戏位于此处
bot的GitHub
为了使bot正常工作,我们需要以下模块:
- OpenCV的Python
- 枕头
- 硒
该机器人是在Ubuntu 20.04.1上针对Python 3.8编写和测试的。我们将必要的模块安装到您的虚拟环境中或通过pip安装。此外,为了使Selenium正常工作,我们需要FireFox的geckodriver,您可以在此处下载github.com/mozilla/geckodriver/releases
浏览器控制
我们正在处理在线游戏,因此首先我们将组织与浏览器的交互。为此,我们将使用Selenium,它将为我们提供用于管理FireFox的API。检查游戏页面的代码。难题是画布,画布又位于iframe中。
我们等待id = iframe-game的框架加载并切换驱动程序上下文。然后我们等待画布。它是框架中唯一的一个,可通过XPath / html / body / canvas获得。
wait(self.__driver, 20).until(EC.frame_to_be_available_and_switch_to_it((By.ID, "iframe-game")))
self.__canvas = wait(self.__driver, 20).until(EC.visibility_of_element_located((By.XPATH, "/html/body/canvas")))接下来,我们的画布将通过self .__ canvas属性可用。使用浏览器的所有逻辑归结为对画布进行截图并在给定坐标处单击它。
Browser.py的完整代码:
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait as wait
from selenium.webdriver.common.by import By
class Browser:
def __init__(self, game_url):
self.__driver = webdriver.Firefox()
self.__driver.get(game_url)
wait(self.__driver, 20).until(EC.frame_to_be_available_and_switch_to_it((By.ID, "iframe-game")))
self.__canvas = wait(self.__driver, 20).until(EC.visibility_of_element_located((By.XPATH, "/html/body/canvas")))
def screenshot(self):
return self.__canvas.screenshot_as_png
def quit(self):
self.__driver.quit()
def click(self, click_point):
action = webdriver.common.action_chains.ActionChains(self.__driver)
action.move_to_element_with_offset(self.__canvas, click_point[0], click_point[1]).click().perform()游戏状态
让我们开始游戏本身。所有机器人逻辑都将在Robot类中实现。让我们将游戏玩法分为7种状态,并为它们分配处理它们的方法。让我们分别选择培训级别。它包含一个大的白色光标,指示要单击的位置,这将导致游戏无法正确识别。
- 欢迎屏幕
- 等级选择画面
- 教程级别的颜色选择
- 在教学层面选择区域
- 颜色选择
- 区域选择
- 搬家的结果
class Robot:
STATE_START = 0x01
STATE_SELECT_LEVEL = 0x02
STATE_TRAINING_SELECT_COLOR = 0x03
STATE_TRAINING_SELECT_AREA = 0x04
STATE_GAME_SELECT_COLOR = 0x05
STATE_GAME_SELECT_AREA = 0x06
STATE_GAME_RESULT = 0x07
def __init__(self):
self.states = {
self.STATE_START: self.state_start,
self.STATE_SELECT_LEVEL: self.state_select_level,
self.STATE_TRAINING_SELECT_COLOR: self.state_training_select_color,
self.STATE_TRAINING_SELECT_AREA: self.state_training_select_area,
self.STATE_GAME_RESULT: self.state_game_result,
self.STATE_GAME_SELECT_COLOR: self.state_game_select_color,
self.STATE_GAME_SELECT_AREA: self.state_game_select_area,
}为了提高机器人的稳定性,我们将检查游戏状态是否已成功更改。如果self.state_next_success_condition在self.state_timeout期间未返回True,则我们将继续处理当前状态,否则将切换到self.state_next。我们还将将从Selenium收到的屏幕截图转换为OpenCV可以理解的格式。
import time
import cv2
import numpy
from PIL import Image
from io import BytesIO
class Robot:
def __init__(self):
# …
self.screenshot = []
self.state_next_success_condition = None
self.state_start_time = 0
self.state_timeout = 0
self.state_current = 0
self.state_next = 0
def run(self, screenshot):
self.screenshot = cv2.cvtColor(numpy.array(Image.open(BytesIO(screenshot))), cv2.COLOR_BGR2RGB)
if self.state_current != self.state_next:
if self.state_next_success_condition():
self.set_state_current()
elif time.time() - self.state_start_time >= self.state_timeout
self.state_next = self.state_current
return False
else:
try:
return self.states[self.state_current]()
except KeyError:
self.__del__()
def set_state_current(self):
self.state_current = self.state_next
def set_state_next(self, state_next, state_next_success_condition, state_timeout):
self.state_next_success_condition = state_next_success_condition
self.state_start_time = time.time()
self.state_timeout = state_timeout
self.state_next = state_next
让我们在状态处理方法中实现检查。我们正在等待开始屏幕上的“播放”按钮,然后单击它。如果在10秒钟内仍未收到级别选择屏幕,则返回上一级self.STATE_START,否则我们将继续处理self.STATE_SELECT_LEVEL。
# …
class Robot:
DEFAULT_STATE_TIMEOUT = 10
# …
def state_start(self):
# Play
# …
if button_play is False:
return False
self.set_state_next(self.STATE_SELECT_LEVEL, self.state_select_level_condition, self.DEFAULT_STATE_TIMEOUT)
return button_play
def state_select_level_condition(self):
#
# …
机器人视觉
图像阈值
让我们定义游戏中使用的颜色。这是本教程级别的5种可播放颜色和光标颜色。如果需要查找所有对象,无论颜色如何,都将使用COLOR_ALL。首先,我们将考虑这种情况。
COLOR_BLUE = 0x01
COLOR_ORANGE = 0x02
COLOR_RED = 0x03
COLOR_GREEN = 0x04
COLOR_YELLOW = 0x05
COLOR_WHITE = 0x06
COLOR_ALL = 0x07
要找到对象,您首先需要简化图像。例如,让我们使用符号“ 0”并对它应用阈值,即,将对象与背景分离。在此阶段,我们不在乎该符号是什么颜色。首先,让我们将图像转换为黑白,使其成为1通道。具有第二个参数cv2.COLOR_BGR2GRAY的cv2.cvtColor函数将帮助我们完成此任务,该函数负责转换为灰度。接下来,我们使用cv2.threshold进行阈值处理。图像中低于特定阈值的所有像素均设置为0,大于等于255的所有像素。cv2.threshold函数的第二个参数负责阈值。在我们的例子中,任何数字都可以存在,因为我们使用的是cv2.THRESH_OTSU 然后函数会根据图像直方图通过Otsu方法本身确定最佳阈值。
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(image, 0, 255, cv2.THRESH_OTSU)

颜色分割
更有趣。让我们复杂化任务,并在级别选择屏幕上找到所有红色符号。

默认情况下,所有OpenCV映像都以BGR格式存储。HSV(色相,饱和度,值-色相,饱和度,值)更适合颜色分割。它比RGB的优势在于HSV可以将色彩与其饱和度和亮度区分开。色相由一个色相通道编码。让我们以浅绿色矩形为例,逐步降低其亮度。
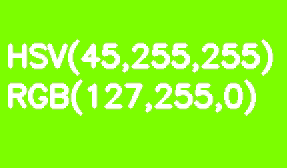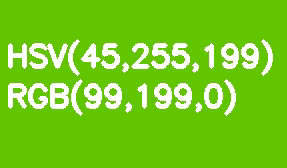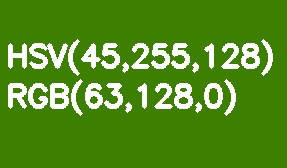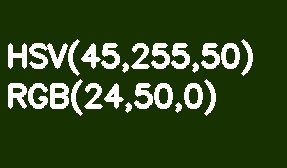
与RGB不同,此转换在HSV中看起来很直观-我们只是减小“值”或“亮度”通道的值。在此应注意,在参考模型中,色相阴影范围在0-360°范围内变化。我们的浅绿色对应于90°。为了使该值适合8位通道,应将其除以2。
颜色分段适用于范围,而不是单一颜色。您可以凭经验确定范围,但是编写小脚本更容易。
import cv2
import numpy as numpy
image_path = "tests_data/SELECT_LEVEL.png"
hsv_max_upper = 0, 0, 0
hsv_min_lower = 255, 255, 255
def bite_range(value):
value = 255 if value > 255 else value
return 0 if value < 0 else value
def pick_color(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
global hsv_max_upper
global hsv_min_lower
global image_hsv
hsv_pixel = image_hsv[y, x]
hsv_max_upper = bite_range(max(hsv_max_upper[0], hsv_pixel[0]) + 1), \
bite_range(max(hsv_max_upper[1], hsv_pixel[1]) + 1), \
bite_range(max(hsv_max_upper[2], hsv_pixel[2]) + 1)
hsv_min_lower = bite_range(min(hsv_min_lower[0], hsv_pixel[0]) - 1), \
bite_range(min(hsv_min_lower[1], hsv_pixel[1]) - 1), \
bite_range(min(hsv_min_lower[2], hsv_pixel[2]) - 1)
print('HSV range: ', (hsv_min_lower, hsv_max_upper))
hsv_mask = cv2.inRange(image_hsv, numpy.array(hsv_min_lower), numpy.array(hsv_max_upper))
cv2.imshow("HSV Mask", hsv_mask)
image = cv2.imread(image_path)
cv2.namedWindow('Original')
cv2.setMouseCallback('Original', pick_color)
image_hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
cv2.imshow("Original", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
让我们用我们的截图启动它。

单击红色,然后查看生成的蒙版。如果输出不适合我们,我们选择红色阴影,以增加蒙版的范围和面积。该脚本基于cv2.inRange函数,该函数充当滤色器并返回给定颜色范围的阈值图像。
让我们关注以下范围:
COLOR_HSV_RANGE = {
COLOR_BLUE: ((112, 151, 216), (128, 167, 255)),
COLOR_ORANGE: ((8, 251, 93), (14, 255, 255)),
COLOR_RED: ((167, 252, 223), (171, 255, 255)),
COLOR_GREEN: ((71, 251, 98), (77, 255, 211)),
COLOR_YELLOW: ((27, 252, 51), (33, 255, 211)),
COLOR_WHITE: ((0, 0, 159), (7, 7, 255)),
}寻找轮廓
让我们回到级别选择屏幕。让我们应用刚刚定义的红色范围滤色器,然后将找到的阈值传递给cv2.findContours。该功能将为我们找到红色元素的轮廓。我们将cv2.RETR_EXTERNAL指定为第二个参数-我们只需要外部轮廓,而将第三个cv2.CHAIN_APPROX_SIMPLE指定为-我们对直线轮廓感兴趣,节省内存并仅存储它们的顶点。
thresh = cv2.inRange(image, self.COLOR_HSV_RANGE[self.COLOR_RED][0], self.COLOR_HSV_RANGE[self.COLOR_RED][1])
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
消除噪音
生成的轮廓包含大量背景噪声。要删除它,让我们使用数字的属性。它们由与坐标轴平行的矩形组成。我们遍历所有路径,并使用cv2.minAreaRect将每个路径拟合到最小矩形中。矩形由4个点定义。如果我们的矩形与轴平行,则每对点的坐标之一必须匹配。这意味着如果我们将矩形的坐标表示为一维数组,则最多将有4个唯一值。此外,让我们过滤掉长宽比大于3到1的矩形。为此,请使用cv2.boundingRect查找其宽度和长度。
squares = []
for cnt in contours:
rect = cv2.minAreaRect(cnt)
square = cv2.boxPoints(rect)
square = numpy.int0(square)
(_, _, w, h) = cv2.boundingRect(square)
a = max(w, h)
b = min(w, h)
if numpy.unique(square).shape[0] <= 4 and a <= b * 3:
squares.append(numpy.array([[square[0]], [square[1]], [square[2]], [square[3]]]))

组合轮廓
现在好多了。现在,我们需要将找到的矩形合并为符号的通用轮廓。我们需要一个中间图像。让我们用numpy.zeros_like创建它。该函数创建图像矩阵的副本,同时保持其形状和大小,然后用零填充。换句话说,我们得到的原始图像是黑色背景的副本。我们将其转换为1通道,并使用cv2.drawContours应用找到的轮廓,并用白色填充它们。我们得到一个二进制阈值,可以将cv2.dilate应用于该阈值。该功能通过连接单独的矩形来扩大白色区域,矩形之间的距离在5个像素以内。我再次调用cv2.findContours并获取红色数字的轮廓。
image_zero = numpy.zeros_like(image)
image_zero = cv2.cvtColor(image_zero, cv2.COLOR_BGR2RGB)
cv2.drawContours(image_zero, contours_of_squares, -1, (255, 255, 255), -1)
_, thresh = cv2.threshold(image_zero, 0, 255, cv2.THRESH_OTSU)
kernel = numpy.ones((5, 5), numpy.uint8)
thresh = cv2.dilate(thresh, kernel, iterations=1)
dilate_contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)

使用cv2.contourArea通过轮廓区域过滤剩余的噪声。删除所有小于500像素²的东西。
digit_contours = [cnt for cnt in digit_contours if cv2.contourArea(cnt) > 500]
现在好极了。让我们在Robot类中实现以上所有内容。
# ...
class Robot:
# ...
def get_dilate_contours(self, image, color_inx, distance):
thresh = self.get_color_thresh(image, color_inx)
if thresh is False:
return []
kernel = numpy.ones((distance, distance), numpy.uint8)
thresh = cv2.dilate(thresh, kernel, iterations=1)
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
return contours
def get_color_thresh(self, image, color_inx):
if color_inx == self.COLOR_ALL:
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(image, 0, 255, cv2.THRESH_OTSU)
else:
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
thresh = cv2.inRange(image, self.COLOR_HSV_RANGE[color_inx][0], self.COLOR_HSV_RANGE[color_inx][1])
return thresh
def filter_contours_of_rectangles(self, contours):
squares = []
for cnt in contours:
rect = cv2.minAreaRect(cnt)
square = cv2.boxPoints(rect)
square = numpy.int0(square)
(_, _, w, h) = cv2.boundingRect(square)
a = max(w, h)
b = min(w, h)
if numpy.unique(square).shape[0] <= 4 and a <= b * 3:
squares.append(numpy.array([[square[0]], [square[1]], [square[2]], [square[3]]]))
return squares
def get_contours_of_squares(self, image, color_inx, square_inx):
thresh = self.get_color_thresh(image, color_inx)
if thresh is False:
return False
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
contours_of_squares = self.filter_contours_of_rectangles(contours)
if len(contours_of_squares) < 1:
return False
image_zero = numpy.zeros_like(image)
image_zero = cv2.cvtColor(image_zero, cv2.COLOR_BGR2RGB)
cv2.drawContours(image_zero, contours_of_squares, -1, (255, 255, 255), -1)
dilate_contours = self.get_dilate_contours(image_zero, self.COLOR_ALL, 5)
dilate_contours = [cnt for cnt in dilate_contours if cv2.contourArea(cnt) > 500]
if len(dilate_contours) < 1:
return False
else:
return dilate_contours
识别数字
让我们添加识别数字的功能。我们为什么需要这个?
# …
class Robot:
# ...
SQUARE_BIG_SYMBOL = 0x01
SQUARE_SIZES = {
SQUARE_BIG_SYMBOL: 9,
}
IMAGE_DATA_PATH = "data/"
def __init__(self):
# ...
self.dilate_contours_bi_data = {}
for image_file in os.listdir(self.IMAGE_DATA_PATH):
image = cv2.imread(self.IMAGE_DATA_PATH + image_file)
contour_inx = os.path.splitext(image_file)[0]
color_inx = self.COLOR_RED
dilate_contours = self.get_dilate_contours_by_square_inx(image, color_inx, self.SQUARE_BIG_SYMBOL)
self.dilate_contours_bi_data[contour_inx] = dilate_contours[0]
def get_dilate_contours_by_square_inx(self, image, color_inx, square_inx):
distance = math.ceil(self.SQUARE_SIZES[square_inx] / 2)
return self.get_dilate_contours(image, color_inx, distance)OpenCV使用cv2.matchShapes函数比较基于Hu矩的轮廓。通过以两条路径作为输入并将比较结果返回为数字,它向我们隐藏了实现细节。它越小,轮廓越相似。
cv2.matchShapes(dilate_contour, self.dilate_contours_bi_data['digit_' + str(digit)], cv2.CONTOURS_MATCH_I1, 0)将当前轮廓digit_contour与所有标准进行比较,并找到cv2.matchShapes的最小值。如果最小值小于0.15,则认为该数字已被识别。根据经验找到最小值的阈值。让我们还将间隔很近的字符组合成一个数字。
# …
class Robot:
# …
def scan_digits(self, image, color_inx, square_inx):
result = []
contours_of_squares = self.get_contours_of_squares(image, color_inx, square_inx)
before_digit_x, before_digit_y = (-100, -100)
if contours_of_squares is False:
return result
for contour_of_square in reversed(contours_of_squares):
crop_image = self.crop_image_by_contour(image, contour_of_square)
dilate_contours = self.get_dilate_contours_by_square_inx(crop_image, self.COLOR_ALL, square_inx)
if (len(dilate_contours) < 1):
continue
dilate_contour = dilate_contours[0]
match_shapes = {}
for digit in range(0, 10):
match_shapes[digit] = cv2.matchShapes(dilate_contour, self.dilate_contours_bi_data['digit_' + str(digit)], cv2.CONTOURS_MATCH_I1, 0)
min_match_shape = min(match_shapes.items(), key=lambda x: x[1])
if len(min_match_shape) > 0 and (min_match_shape[1] < self.MAX_MATCH_SHAPES_DIGITS):
digit = min_match_shape[0]
rect = cv2.minAreaRect(contour_of_square)
box = cv2.boxPoints(rect)
box = numpy.int0(box)
(digit_x, digit_y, digit_w, digit_h) = cv2.boundingRect(box)
if abs(digit_y - before_digit_y) < digit_y * 0.3 and abs(
digit_x - before_digit_x) < digit_w + digit_w * 0.5:
result[len(result) - 1][0] = int(str(result[len(result) - 1][0]) + str(digit))
else:
result.append([digit, self.get_contour_centroid(contour_of_square)])
before_digit_x, before_digit_y = digit_x + (digit_w / 2), digit_y
return result在输出处,self.scan_digits方法将返回一个数组,其中包含识别出的数字和单击它的坐标。单击点将是其轮廓的质心。
# …
class Robot:
# …
def get_contour_centroid(self, contour):
moments = cv2.moments(contour)
return int(moments["m10"] / moments["m00"]), int(moments["m01"] / moments["m00"])我们为收到的数字识别工具感到高兴,但时间不长。除比例外,胡矩也随旋转和镜面反射不变。因此,机器人会将数字6、9 / 2和5混淆。让我们在顶点处对这些符号进行额外的检查。图6和9将由右上角区分。如果它在水平中心以下,则相反的是6和9。对于线对2和5,检查右上点是否在符号的右边界上。
if digit == 6 or digit == 9:
extreme_bottom_point = digit_contour[digit_contour[:, :, 1].argmax()].flatten()
x_points = digit_contour[:, :, 0].flatten()
extreme_right_points_args = numpy.argwhere(x_points == numpy.amax(x_points))
extreme_right_points = digit_contour[extreme_right_points_args]
extreme_top_right_point = extreme_right_points[extreme_right_points[:, :, :, 1].argmin()].flatten()
if extreme_top_right_point[1] > round(extreme_bottom_point[1] / 2):
digit = 6
else:
digit = 9
if digit == 2 or digit == 5:
extreme_right_point = digit_contour[digit_contour[:, :, 0].argmax()].flatten()
y_points = digit_contour[:, :, 1].flatten()
extreme_top_points_args = numpy.argwhere(y_points == numpy.amin(y_points))
extreme_top_points = digit_contour[extreme_top_points_args]
extreme_top_right_point = extreme_top_points[extreme_top_points[:, :, :, 0].argmax()].flatten()
if abs(extreme_right_point[0] - extreme_top_right_point[0]) > 0.05 * extreme_right_point[0]:
digit = 2
else:
digit = 5

分析运动场
让我们跳过培训级别,它是通过单击白色光标并开始播放来编写的。
让我们想象一下运动场是一个网络。每个彩色区域将是一个链接到相邻邻居的节点。让我们创建一个用于描述颜色区域/节点的self.ColorArea类。
class ColorArea:
def __init__(self, color_inx, click_point, contour):
self.color_inx = color_inx #
self.click_point = click_point #
self.contour = contour #
self.neighbors = [] # 让我们定义一个self.color_areas节点列表和一个颜色出现在运动场self.color_areas_color_count上的频率列表。从画布屏幕截图中裁剪运动场。
image[pt1[1]:pt2[1], pt1[0]:pt2[0]]其中pt1,pt2是框架的端点。我们遍历游戏的所有颜色,并将self.get_dilate_contours方法应用于每种颜色。查找节点的轮廓类似于我们寻找符号的一般轮廓的方式,不同之处在于运动场上没有噪音。节点的形状可以是凹形的或有孔的,因此质心会落在形状之外,不适合用作单击的坐标。为此,找到最高点并将其下降20个像素。该方法不是通用的,但在我们的情况下它是有效的。
self.color_areas = []
self.color_areas_color_count = [0] * self.SELECT_COLOR_COUNT
image = self.crop_image_by_rectangle(self.screenshot, numpy.array(self.GAME_MAIN_AREA))
for color_inx in range(1, self.SELECT_COLOR_COUNT + 1):
dilate_contours = self.get_dilate_contours(image, color_inx, 10)
for dilate_contour in dilate_contours:
click_point = tuple(
dilate_contour[dilate_contour[:, :, 1].argmin()].flatten() + [0, int(self.CLICK_AREA)])
self.color_areas_color_count[color_inx - 1] += 1
color_area = self.ColorArea(color_inx, click_point, dilate_contour)
self.color_areas.append(color_area)
链接区域
如果轮廓之间的距离在15个像素以内,我们会将区域视为邻居。我们对每个节点进行迭代,如果它们的颜色匹配,则跳过比较。
blank_image = numpy.zeros_like(image)
blank_image = cv2.cvtColor(blank_image, cv2.COLOR_BGR2GRAY)
for color_area_inx_1 in range(0, len(self.color_areas)):
for color_area_inx_2 in range(color_area_inx_1 + 1, len(self.color_areas)):
color_area_1 = self.color_areas[color_area_inx_1]
color_area_2 = self.color_areas[color_area_inx_2]
if color_area_1.color_inx == color_area_2.color_inx:
continue
common_image = cv2.drawContours(blank_image.copy(), [color_area_1.contour, color_area_2.contour], -1, (255, 255, 255), cv2.FILLED)
kernel = numpy.ones((15, 15), numpy.uint8)
common_image = cv2.dilate(common_image, kernel, iterations=1)
common_contour, _ = cv2.findContours(common_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if len(common_contour) == 1:
self.color_areas[color_area_inx_1].neighbors.append(color_area_inx_2)
self.color_areas[color_area_inx_2].neighbors.append(color_area_inx_1)
我们正在寻找最佳举措
我们拥有有关比赛场地的所有信息。让我们开始选择一个动作。为此,我们需要节点和颜色索引。移动选项的数量可以由以下公式确定:
移动选项=节点数量*颜色数量-1
对于上一个游戏场地,我们有7 *(5-1)= 28个选项。它们不多,因此我们可以遍历所有步法并选择最佳步法。让我们将选项定义为矩阵
select_color_weights,其中行将是节点索引,颜色索引列和移动权重单元格。我们需要将节点的数量减少到一个,因此我们将优先考虑板上具有独特颜色的区域,这些区域在您移至它们之后会消失。让我们为所有具有唯一颜色的节点行赋予+10权重。颜色先前在运动场上出现的频率是多少?self.color_areas_color_count
if self.color_areas_color_count[color_area.color_inx - 1] == 1:
select_color_weight = [x + 10 for x in select_color_weight]
接下来,让我们看一下相邻区域的颜色。如果该节点具有color_inx的邻居,并且其数目等于运动场上此颜色的总数,则将+10分配给像元权重。这还将从字段中删除color_inx颜色。
for color_inx in range(0, len(select_color_weight)):
color_count = select_color_weight[color_inx]
if color_count != 0 and self.color_areas_color_count[color_inx] == color_count:
select_color_weight[color_inx] += 10让我们给相同颜色的每个邻居的单元格权重+1。也就是说,如果我们有3个红色邻居,那么红色单元格将获得+3的权重。
for select_color_weight_inx in color_area.neighbors:
neighbor_color_area = self.color_areas[select_color_weight_inx]
select_color_weight[neighbor_color_area.color_inx - 1] += 1收集所有重量后,我们找到最大重量的移动。让我们定义哪个节点以及它属于什么颜色。
max_index = select_color_weights.argmax()
self.color_area_inx_next = max_index // self.SELECT_COLOR_COUNT
select_color_next = (max_index % self.SELECT_COLOR_COUNT) + 1
self.set_select_color_next(select_color_next)完成代码以确定最佳移动。
# …
class Robot:
# …
def scan_color_areas(self):
self.color_areas = []
self.color_areas_color_count = [0] * self.SELECT_COLOR_COUNT
image = self.crop_image_by_rectangle(self.screenshot, numpy.array(self.GAME_MAIN_AREA))
for color_inx in range(1, self.SELECT_COLOR_COUNT + 1):
dilate_contours = self.get_dilate_contours(image, color_inx, 10)
for dilate_contour in dilate_contours:
click_point = tuple(
dilate_contour[dilate_contour[:, :, 1].argmin()].flatten() + [0, int(self.CLICK_AREA)])
self.color_areas_color_count[color_inx - 1] += 1
color_area = self.ColorArea(color_inx, click_point, dilate_contour, [0] * self.SELECT_COLOR_COUNT)
self.color_areas.append(color_area)
blank_image = numpy.zeros_like(image)
blank_image = cv2.cvtColor(blank_image, cv2.COLOR_BGR2GRAY)
for color_area_inx_1 in range(0, len(self.color_areas)):
for color_area_inx_2 in range(color_area_inx_1 + 1, len(self.color_areas)):
color_area_1 = self.color_areas[color_area_inx_1]
color_area_2 = self.color_areas[color_area_inx_2]
if color_area_1.color_inx == color_area_2.color_inx:
continue
common_image = cv2.drawContours(blank_image.copy(), [color_area_1.contour, color_area_2.contour],
-1, (255, 255, 255), cv2.FILLED)
kernel = numpy.ones((15, 15), numpy.uint8)
common_image = cv2.dilate(common_image, kernel, iterations=1)
common_contour, _ = cv2.findContours(common_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if len(common_contour) == 1:
self.color_areas[color_area_inx_1].neighbors.append(color_area_inx_2)
self.color_areas[color_area_inx_2].neighbors.append(color_area_inx_1)
def analysis_color_areas(self):
select_color_weights = []
for color_area_inx in range(0, len(self.color_areas)):
color_area = self.color_areas[color_area_inx]
select_color_weight = numpy.array([0] * self.SELECT_COLOR_COUNT)
for select_color_weight_inx in color_area.neighbors:
neighbor_color_area = self.color_areas[select_color_weight_inx]
select_color_weight[neighbor_color_area.color_inx - 1] += 1
for color_inx in range(0, len(select_color_weight)):
color_count = select_color_weight[color_inx]
if color_count != 0 and self.color_areas_color_count[color_inx] == color_count:
select_color_weight[color_inx] += 10
if self.color_areas_color_count[color_area.color_inx - 1] == 1:
select_color_weight = [x + 10 for x in select_color_weight]
color_area.set_select_color_weights(select_color_weight)
select_color_weights.append(select_color_weight)
select_color_weights = numpy.array(select_color_weights)
max_index = select_color_weights.argmax()
self.color_area_inx_next = max_index // self.SELECT_COLOR_COUNT
select_color_next = (max_index % self.SELECT_COLOR_COUNT) + 1
self.set_select_color_next(select_color_next)
让我们添加在关卡之间移动并享受结果的功能。该机器人可以稳定运行,并在一个会话中完成游戏。
输出量
创建的机器人没有实际用途。但是,本文的作者真诚地希望,对OpenCV基本原理的详细描述将有助于初学者在初始阶段了解该库。