开始一个例子
下面我们将用Java语言编写一个简单的应用程序(作者使用了Java 14,但Java 8也很好),使用应用程序内部的计数器来衡量其性能,并尝试通过在多个线程中执行代码来改善结果。重现该示例所需的全部是任何Java开发环境,或者只是jdk和visualvm实用程序,它们将帮助我们诊断出现的问题。该示例有意不使用各种基准来衡量性能和其他高级工具-在这种情况下,它们是多余的。该测试用例在Windows上的具有4个物理和8个逻辑内核的Intel Core i7处理器上运行。
因此,让我们创建一个简单的应用程序,该应用程序将循环执行一个负担处理器的计算任务,即阶乘的计算。此外,循环中的每个任务也将计算一个从1到25范围内的数字的阶乘。采用浮动范围可使示例更接近实际。以下是work()函数的代码:
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(RandomUtils.nextInt(1, 25));
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
该函数接收输入的用于计算阶乘的循环数,该循环数由常量指定:
private static final int POWER_BASE = 1000000;完成变量中指定的一定数量的任务后
private static final int LOG_STEP = 10;记录已完成任务的数量及其执行的总时间。work
()函数还使用:
//
private long startTime;
//
private AtomicLong counter = new AtomicLong();
//
private long factorial(int power) {
if (power == 1) return power;
else return power * factorial(power - 1);
}
应该注意的是,在一个线程中一次执行work()函数大约需要20毫秒,因此最后对共享计数器变量的同步调用(可能是瓶颈)不会产生问题,因为每个线程发生的次数不超过20次ms,这大大超过了counter.incrementAndGet()的执行时间。换句话说,与访问同步计数器相关联的线程之间的争用不应显着影响实验结果,因此可以忽略。
让我们在一个线程中运行以下代码,然后查看结果:
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
work(POWER_BASE);
}
在控制台中,我们看到以下输出:
10个任务在0秒内完成
...
100个任务在2秒内完成
...
500个任务在10秒内完成
因此,在一个线程中,我们获得的性能等于每秒50个任务或每个任务20 ms。
并行化代码
如果在一个线程中获得的性能为X,那么在没有附加负载的情况下在4个处理器上获得的性能,我们可以预期性能约为4 * X,即它将提高4倍。看来很合逻辑。好吧,让我们尝试!
让我们介绍一个具有固定线程数的简单池:
private ExecutorService executorService = Executors.newFixedThreadPool(POOL_SIZE);
不变:
private static final int POOL_SIZE = 1;我们将在1到16的范围内更改并修复结果。
重新设计启动代码:
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executorService.execute(() -> work(POWER_BASE));
}
默认情况下,线程池中任务队列的大小为Integer.MAX_VALUE,我们向线程池添加的任务最多为Integer.MAX_VALUE个任务,因此任务队列不应溢出。
走!
首先,让我们将POOL_SIZE常量设置为8个线程:
private static final int POOL_SIZE = 8;运行应用程序并查看控制台:
10在3秒内
完成的任务20在6秒内
完成的任务30在8秒内
完成的任务40在10秒内
完成的任务50在14秒内
完成的任务60在16秒内
完成的任务70在19秒内完成的任务
80在20秒内
完成的任务90在23秒内
完成的任务100在24秒内
完成的任务110在26秒内
完成的任务120在28秒内
完成的任务130在29秒内
完成的任务140在31秒内
完成的任务150在33秒内
完成的任务160在36秒内
完成170个任务在46秒内完成
我们看到了什么?而不是性能的预期提高,它从每个任务的20ms下降到270ms下降了十倍以上。但这还不是全部!关于170个已完成任务的消息是日志中的最后一条消息。然后,该应用程序似乎已完全停止。
在处理造成程序异常行为的原因之前,让我们了解动态情况,并通过将POOL_SIZE常量设置为适当的值来依次删除4和16个线程的日志。
记录4个线程:
10在2秒内
完成的任务20在4秒内
完成的任务30在6秒内
完成的任务40在8秒内
完成的任务50在10秒内
完成的任务60在13秒内
完成的任务70在15秒内完成的任务
80个任务在18秒内
完成90个任务在21秒内
完成100个任务在33秒内完成
第一个90个任务与8个线程在大约同一时间完成,然后又需要12秒才能完成另外10个任务,并且应用程序挂起。
记录16个线程:
10在2秒内
完成的任务20在3秒内
完成的任务30在6秒内
完成的任务40在8秒内 完成的任务
...
290在51秒内
完成的任务300在52秒
内
完成的任务310在63秒内完成的任务对于310个任务,该应用程序被冻结,并且像以前的情况一样,最后10个任务花费了10秒钟以上才能完成。
让我们总结一下:
并行执行任务会导致性能下降10
倍或更多倍。在所有情况下,应用程序挂起,线程越少挂起速度越快(我们将回到这一事实)
寻找问题
显然,我们的代码有问题。但是,您如何找到原因呢?为此,我们将使用visualvm实用程序。我们将在执行应用程序之前启动它,并在启动应用程序后在visualvm界面中切换到所需的Java进程。该应用程序可以直接从开发环境中启动。当然,这通常是错误的,但是在我们的示例中,它不会影响结果。
首先,我们查看“监视器”选项卡,发现内存有问题。
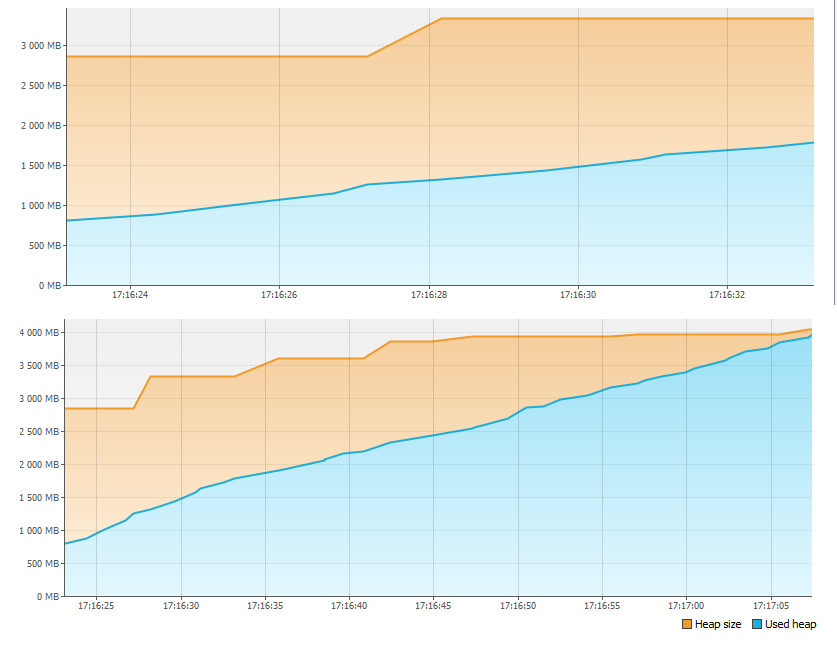
在不到一分钟的时间内,4GB的内存就耗尽了!因此,该应用程序停止了。但是记忆去了哪里?
重新启动该应用程序,然后按“监视器”选项卡上的“堆转储”按钮。删除并打开内存转储后,我们看到:

在“按实例大小划分的类”部分中,LinkedBlockingQueue $ Node类占用了1 GB以上的空间。它不过是线程池任务队列的顶部。第二大类是将任务本身添加到线程池中。为此,在“按实例数划分的类”部分中,我们看到了第一类和第二类的实例数之间的对应关系(该匹配并不完全准确,这显然是由于首先创建了一个任务,然后才创建了新的队列顶部,并且由于时差)乘以线程数,我们在实例数上会有细微的差异)。
现在让我们数一数。我们在一个循环(Integer.MAX_VALUE)中创建大约20亿个任务,即大约2GB的任务。任务的执行速度比创建任务慢,因此队列大小不断增长。即使每个任务仅需要8个字节的内存,最大队列大小也将是:
8 * 2GB = 16GB
总堆大小为4GB,没有足够的内存也就不足为奇了。实际上,如果我们不中断应用程序的执行(该应用程序的日志停止了),过一会儿,我们将看到著名的OutOfMemoryError甚至没有visualvm,只需查看代码,我们就可以猜测内存的运行方向。
让我们记住,运行任务的线程数量越少,应用程序停止的速度就越快。我们现在可以尝试解释这一点。线程数越少,应用程序运行的速度就越快(为什么-我们尚未发现),任务队列填满和内存已满的速度也就越快。
好了,解决内存溢出问题非常简单。让我们创建一个常量而不是Integer.MaxValue:
私有静态最终int MAX_TASKS = 1024 * 1024;
让我们如下更改代码:
startTime = System.currentTimeMillis();
for (int i = 0; i < MAX_TASKS; i++) {
executorService.execute(() -> work(POWER_BASE));
}
现在剩下的是启动应用程序,并确保一切与内存保持一致:

我们继续分析
我们再次启动我们的应用程序,逐渐增加线程数并修复结果。
1个线程-10秒内
执行500个任务2个线程-21秒内执行500个任务
4个线程-37秒内执行500个任务
8个线程-49秒内执行
500个任务16个线程-57秒内
执行500个任务如我们所见,增加时500个任务的执行时间线程数不会减少,但会增加,而10个任务的每个部分的执行速度是一致的,并且线程不再冻结。
让我们再次使用visualvm实用程序,并在应用程序运行时进行线程转储。为了获得最准确的图像,最好在16个线程上进行转储。有很多用于分析线程转储的实用程序,但是在我们的情况下,您可以在visualvm界面中滚动浏览所有名称为“ pool-1-thread-1”,“ pool-1-thread-2”等的线程,并查看以下内容:

在转储时,大多数线程会生成下一个随机数以计算阶乘。事实证明,这是最耗时的功能。那为什么?为了弄清楚,让我们进入Random.next()的源代码,然后看以下内容:
private final AtomicLong seed;
protected int next(int bits) {
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
oldseed = seed.get();
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed));
return (int)(nextseed >>> (48 - bits));
}
所有线程共享种子变量的单个实例,可以使用AtomicLong类同步对其进行访问。这意味着在生成每个随机数时,线程会排队访问该变量,而不是并行执行。因此,生产率不会提高。但是她为什么跌倒?答案很简单。在并行化执行时,会花费额外的资源来支持并行处理,特别是在线程之间切换处理器上下文时。事实证明,已经出现了额外的开销,并且线程仍然无法并行工作,因为它们竞争对种子变量值的访问,并在调用seed.compareAndSet()时排队。线程之间争夺有限资源,也许并行计算时性能下降的最常见原因。
让我们如下更改work()函数的代码:
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(20);
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
并再次检查在不同的线程数的性能:
1个螺纹- 1000个任务17秒
2个线程-在10秒1000个任务
4个线程-在5秒内1000个任务
8个线程-在4秒1000个任务
16个线程-在4秒1000级的任务
现在结果接近我们的预期。4个线程上的性能提高了约4倍。此外,由于并行化受到处理器资源的限制,因此性能的提高实际上已停止。让我们看一下在4和8个线程上通过visualvm捕获的处理器负载图。

从图中可以看到,有4个线程,超过50%的处理器资源是空闲的,有8个线程,几乎100%的处理器都在使用。这意味着在此示例中,限制为8个线程,进一步的性能只会降低。在我们的示例中,性能增长已经在4个线程上停止,但是如果这些线程执行了同步I / O而不是计算阶乘,那么很可能会显着提高其提供性能提升的并行化极限。读者可以自己检查这一点,并将结果写在文章的评论中。
如果我们谈论实践,那么可以指出两个重要点:
并行化通常在线程数最多达到处理器核心数的2倍时有效(当然,在没有其他处理器负载的情况下)
,实际上CPU利用率不应超过80%以确保容错能力
减少线程之间的竞争
谈论性能变得无所适从,我们忘记了一件事。通过将对代码中对RandomUtils.nextInt()的调用更改为常量,我们更改了应用程序的业务逻辑。让我们回到旧算法,同时避免性能问题。我们发现调用RandomUtils.nextInt()会导致每个线程使用相同的种子变量来生成随机数,同时,这是完全可选的。在我们的示例中使用代替
RandomUtils.nextInt(1, 25)ThreadLocalRandom类:
ThreadLocalRandom.current().nextInt(1, 25)将解决竞争问题。现在,每个线程将使用其自己的内部变量实例来生成下一个随机数。
为每个线程使用单独的变量,而不是同步访问线程之间共享的类的单个实例,是一种通过减少线程之间的争用来提高性能的常用技术。尽管有更高级的工具,例如Mapped Diagnostic Context,但java.lang.ThreadLocal类可用于在线程上下文中存储变量的值。
最后,我想指出的是,减少线程之间的竞争不仅是一项技术任务,而且还是一项逻辑任务。在我们的示例中,每个线程都可以使用自己的变量实例而不会出现任何问题,但是如果我们需要一个实例来共享所有实例,例如共享计数器,该怎么办?在这种情况下,您将不得不重构算法本身。例如,在每个流的上下文中存储一个计数器,并根据每个流的计数器的值定期或根据请求计算总计数器的值。
结论
因此,有3点会影响并行处理的性能:
- CPU资源
- 线程之间的竞争
- 其他间接影响整体结果的因素