
我们实现并比较了4种流行的神经网络训练优化器:脉冲优化器,均方根传播,小批量梯度下降和自适应扭矩估计。仓库,大量的Python代码及其输出,可视化和公式均已削减。
介绍
模型是机器学习算法在某些数据上运行的结果。该模型表示该算法已掌握的知识。这是在训练数据上运行算法后仍然存在的“事物”,代表规则,数字以及该算法特有的,预测所需的任何其他数据结构。
什么是优化器?
在继续之前,我们需要知道什么是损失函数。损失函数用于衡量您的预测模型对预期结果(或价值)的预测程度。损失函数也称为成本函数(此处有更多信息)。
在训练过程中,我们会尽量减少功能损失并更新参数以提高准确性。神经网络参数通常是链接权重。在这种情况下,将在训练阶段研究参数。因此,算法本身(和输入数据)会调整这些参数。在这里可以找到更多信息。
因此,优化器是一种获得更好结果,有助于加快学习速度的方法。换句话说,它是一种算法,用于对权重和学习率等参数进行较小的调整,以保持模型正确,快速地运行。这是深度学习中使用的各种优化器的基本概述,以及了解该模型的实现的简单模型。我强烈建议克隆此存储库并通过观察行为模式进行更改。
一些常用术语:
- 反向传播
反向传播的目标很简单:根据网络中每个权重对整体误差的影响来调整每个权重。如果您反复减少每个权重的误差,最终会得到一系列权重,它们可以提供良好的预测。我们为损失函数找到每个参数的斜率,并通过减去斜率来更新参数(此处有更多信息)。

- 梯度下降
梯度下降是一种优化算法,用于通过迭代移向由负梯度值定义的最陡下降来最小化函数。在深度学习中,我们使用梯度下降来更新模型参数(此处提供更多信息)。
- 超参数
模型超参数是模型外部的配置,无法从数据中估计其值。例如,隐藏神经元的数量,学习率等。我们无法从数据中估算学习率(更多信息,请参见)。
- 学习率
学习率(α)是优化算法中的调整参数,它决定每次迭代的步长,同时朝着损失函数的最小值移动(此处有更多信息)。
热门优化器

以下是一些最受欢迎的SEO:
- 随机梯度下降(SGD)。
- 动量优化器。
- 均方根传播(RMSProp)。
- 自适应扭矩估算(Adam)。
让我们详细考虑它们中的每一个。
1.随机梯度下降(尤其是小批量生产)
我们在训练模型(使用纯SGD)并更新参数时一次使用一个示例。但是我们必须为循环使用另一个。这将花费很多时间。因此,我们使用小批量SGD。
小型批量梯度下降旨在平衡随机梯度下降的鲁棒性和批量梯度下降的效率。这是深度学习中最常用的梯度下降实现。在小批量SGD中,在训练模型时,我们会使用一组示例(例如32、64个示例等)。这种方法效果更好,因为微型批处理只需要一个循环,而不是每个示例。每次迭代都会随机选择迷你包装,但是为什么呢?当随机选择迷你数据包时,然后当卡在局部最小值中时,一些嘈杂的步骤可能会导致偏离这些最小值。为什么需要此优化器?
- 参数更新速率比简单的批量梯度下降方法更高,这可以避免局部最小值,从而实现更可靠的收敛。
- 批次更新提供了比随机梯度下降更有效的计算过程。
- 如果您的RAM很少,那么迷你包装是最好的选择。由于内存和算法实现中没有所有训练数据,因此批处理非常有效。
如何生成随机迷你包装?
def RandomMiniBatches(X, Y, MiniBatchSize):
m = X.shape[0]
miniBatches = []
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation, :]
shuffled_Y = Y[permutation, :].reshape((m,1)) #sure for uptpur shape
num_minibatches = m // MiniBatchSize
for k in range(0, num_minibatches):
miniBatch_X = shuffled_X[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch_Y = shuffled_Y[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
#handeling last batch
if m % MiniBatchSize != 0:
# end = m - MiniBatchSize * m // MiniBatchSize
miniBatch_X = shuffled_X[num_minibatches * MiniBatchSize:, :]
miniBatch_Y = shuffled_Y[num_minibatches * MiniBatchSize:, :]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
return miniBatches
模型的格式是什么?
如果您是深度学习的新手,我将对模型进行概述。看起来像这样:
def model(X,Y,learning_rate,num_iter,hidden_size,keep_prob,optimizer):
L = len(hidden_size)
params = initilization(X.shape[1], hidden_size)
for i in range(1,num_iter):
MiniBatches = RandomMiniBatches(X, Y, 64) # GET RAMDOMLY MINIBATCHES
p , q = MiniBatches[2]
for MiniBatch in MiniBatches: #LOOP FOR MINIBATCHES
(MiniBatch_X, MiniBatch_Y) = MiniBatch
cache, A = model_forward(MiniBatch_X, params, L,keep_prob) #FORWARD PROPOGATIONS
cost = cost_f(A, MiniBatch_Y) #COST FUNCTION
grad = backward(MiniBatch_X, MiniBatch_Y, params, cache, L,keep_prob) #BACKWARD PROPAGATION
params = update_params(params, grad, beta=0.9,learning_rate=learning_rate)
return params
在下图中,您可以看到SGD的波动很大。垂直移动不是必需的:我们只希望水平移动。如果减少垂直运动并增加水平运动,模型将学习得更快,您是否同意?

如何减少不必要的振动?以下优化器将它们最小化,并有助于加快学习速度。
2.脉冲优化器
SGD或梯度下降中有很多摆动。您需要前进,而不是上下移动。我们需要在正确的方向上提高模型的学习率,我们将使用动量优化器来做到这一点。

如您在上图中所看到的,Pulse Optimizer的绿线比其他的更快。当您拥有大型数据集和许多迭代时,可以看出快速学习的重要性。如何实现此优化器?

β的正常值约为0.9,您
可以看到我们从反向传播参数中创建了两个参数-vdW和vdb。考虑值β= 0.9,则等式采用以下形式:
vdw= 0.9 * vdw + 0.1 * dw
vdb = 0.9 * vdb + 0.1 * db如您所见,vdw更依赖于vdw的先前值,而不是dw。当渲染为图形时,您可以看到Momentum Optimizer考虑了过去的渐变以平滑更新。这就是为什么可以使波动最小化的原因。当使用SGD时,小批量梯度下降所采用的路径朝着收敛方向振荡。动量优化器有助于减少这些波动。
def update_params_with_momentum(params, grads, v, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
v["dW" + str(l + 1)] = beta * v["dW" + str(l + 1)] + (1 - beta) * grads['dW' + str(l + 1)]
v["db" + str(l + 1)] = beta * v["db" + str(l + 1)] + (1 - beta) * grads['db' + str(l + 1)]
#updating parameters W and b
params["W" + str(l + 1)] = params["W" + str(l + 1)] - learning_rate * v["dW" + str(l + 1)]
params["b" + str(l + 1)] = params["b" + str(l + 1)] - learning_rate * v["db" + str(l + 1)]
return params
仓库在这里
3.均方根差
均方根(RMSprop)是指数衰减的均值。RMSprop的基本属性是您不仅限于过去的梯度之和,而且还限于最后一个时间步的梯度。RMSprop有助于过去“平方律梯度”的指数衰减均值。在RMSProp中,我们尝试使用均值来减少垂直运动,因为通过取均值它们的总和大约为0。RMSprop提供更新的平均值。

来源

看下面的代码。这将使您对如何实现此优化器有基本的了解。一切都与SGD相同,我们必须更改更新功能。
def initilization_RMS(params):
s = {}
for i in range(len(params)//2 ):
s["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
s["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
return s
def update_params_with_RMS(params, grads,s, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
s["dW" + str(l)]= beta * s["dW" + str(l)] + (1 - beta) * np.square(grads['dW' + str(l)])
s["db" + str(l)] = beta * s["db" + str(l)] + (1 - beta) * np.square(grads['db' + str(l)])
#updating parameters W and b
params["W" + str(l)] = params["W" + str(l)] - learning_rate * grads['dW' + str(l)] / (np.sqrt( s["dW" + str(l)] )+ pow(10,-4))
params["b" + str(l)] = params["b" + str(l)] - learning_rate * grads['db' + str(l)] / (np.sqrt( s["db" + str(l)]) + pow(10,-4))
return params
4.亚当优化器
Adam是神经网络训练中最有效的优化算法之一。它结合了RMSProp和Pulse Optimizer的思想。Adam并没有像RMSProp中那样根据第一矩的平均值(平均值)来调整参数的学习率,而是使用了梯度第二矩的平均值。特别地,该算法计算梯度和二次梯度的指数移动平均值,并计算参数
beta1并beta2控制这些移动平均值的衰减率。怎么样?
def initilization_Adam(params):
s = {}
v = {}
for i in range(len(params)//2 ):
v["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
v["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
s["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
s["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
return v, s
def update_params_with_Adam(params, grads,v, s, beta1,beta2, learning_rate,t):
epsilon = pow(10,-8)
v_corrected = {}
s_corrected = {}
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
v["dW" + str(l)] = beta1 * v["dW" + str(l)] + (1 - beta1) * grads['dW' + str(l)]
v["db" + str(l)] = beta1 * v["db" + str(l)] + (1 - beta1) * grads['db' + str(l)]
v_corrected["dW" + str(l)] = v["dW" + str(l)] / (1 - np.power(beta1, t))
v_corrected["db" + str(l)] = v["db" + str(l)] / (1 - np.power(beta1, t))
s["dW" + str(l)] = beta2 * s["dW" + str(l)] + (1 - beta2) * np.power(grads['dW' + str(l)], 2)
s["db" + str(l)] = beta2 * s["db" + str(l)] + (1 - beta2) * np.power(grads['db' + str(l)], 2)
s_corrected["dW" + str(l)] = s["dW" + str(l)] / (1 - np.power(beta2, t))
s_corrected["db" + str(l)] = s["db" + str(l)] / (1 - np.power(beta2, t))
params["W" + str(l)] = params["W" + str(l)] - learning_rate * v_corrected["dW" + str(l)] / np.sqrt(s_corrected["dW" + str(l)] + epsilon)
params["b" + str(l)] = params["b" + str(l)] - learning_rate * v_corrected["db" + str(l)] / np.sqrt(s_corrected["db" + str(l)] + epsilon)
return params
超参数
- β1(β1)值几乎为0.9
- β2(beta2)-接近0.999
- ε-防止被零除(10 ^ -8)(不会影响学习太多)
为什么使用此优化器?
优点:
- 实现简单。
- 计算效率。
- 内存需求低。
- 梯度的对角线缩放不变。
- 就数据和参数而言,非常适合大型任务。
- 适用于非固定目的。
- 适用于非常嘈杂或稀疏梯度的任务。
- 超参数很简单,通常不需要任何调整。
让我们建立一个模型,看看超参数如何加速学习
让我们动手演示如何加速学习。在这篇文章中,我们将不能说明其他的事情(初始化,放映,
forward_prop,back_prop,梯度下降,等等。D.)。培训所需的功能已经内置在NumPy中。如果您想看一下,这里是链接!
开始吧!
我正在创建一个通用模型函数,该函数适用于此处讨论的所有优化器。
1.初始化:
我们使用初始化函数初始化参数,该函数接受输入(例如
features_size (在我们的示例中为12288)和隐藏的大小数组(我们使用[100,1]))并将此输出作为初始化参数。还有另一种初始化方法。我建议你阅读此文章。
def initilization(input_size,layer_size):
params = {}
np.random.seed(0)
params['W' + str(0)] = np.random.randn(layer_size[0], input_size) * np.sqrt(2 / input_size)
params['b' + str(0)] = np.zeros((layer_size[0], 1))
for l in range(1,len(layer_size)):
params['W' + str(l)] = np.random.randn(layer_size[l],layer_size[l-1]) * np.sqrt(2/layer_size[l])
params['b' + str(l)] = np.zeros((layer_size[l],1))
return params
2.正向传播:
在此函数中,输入为X,以及参数,隐藏层的范围和滤除,在滤除技术中使用。
我将该值设置为1,以便在锻炼中看不到任何效果。如果您的模型过拟合,则可以设置其他值。我只在偶数层上应用辍学。
我们使用函数计算每个层的激活值
forward_activation。
#activations-----------------------------------------------
def forward_activation(A_prev, w, b, activation):
z = np.dot(A_prev, w.T) + b.T
if activation == 'relu':
A = np.maximum(0, z)
elif activation == 'sigmoid':
A = 1/(1+np.exp(-z))
else:
A = np.tanh(z)
return A
#________model forward ____________________________________________________________________________________________________________
def model_forward(X,params, L,keep_prob):
cache = {}
A =X
for l in range(L-1):
w = params['W' + str(l)]
b = params['b' + str(l)]
A = forward_activation(A, w, b, 'relu')
if l%2 == 0:
cache['D' + str(l)] = np.random.randn(A.shape[0],A.shape[1]) < keep_prob
A = A * cache['D' + str(l)] / keep_prob
cache['A' + str(l)] = A
w = params['W' + str(L-1)]
b = params['b' + str(L-1)]
A = forward_activation(A, w, b, 'sigmoid')
cache['A' + str(L-1)] = A
return cache, A
3.反向传播:
这里我们编写反向传播功能。它将返回grad(坡度)。我们
grad在更新参数时使用(如果您不知道的话)。我建议阅读这篇文章。
def backward(X, Y, params, cach,L,keep_prob):
grad ={}
m = Y.shape[0]
cach['A' + str(-1)] = X
grad['dz' + str(L-1)] = cach['A' + str(L-1)] - Y
cach['D' + str(- 1)] = 0
for l in reversed(range(L)):
grad['dW' + str(l)] = (1 / m) * np.dot(grad['dz' + str(l)].T, cach['A' + str(l-1)])
grad['db' + str(l)] = 1 / m * np.sum(grad['dz' + str(l)].T, axis=1, keepdims=True)
if l%2 != 0:
grad['dz' + str(l-1)] = ((np.dot(grad['dz' + str(l)], params['W' + str(l)]) * cach['D' + str(l-1)] / keep_prob) *
np.int64(cach['A' + str(l-1)] > 0))
else :
grad['dz' + str(l - 1)] = (np.dot(grad['dz' + str(l)], params['W' + str(l)]) *
np.int64(cach['A' + str(l - 1)] > 0))
return grad
我们已经看到了优化器更新功能,因此我们将在这里使用它。让我们从SGD讨论中对模型函数进行一些小的更改。
def model(X,Y,learning_rate,num_iter,hidden_size,keep_prob,optimizer):
L = len(hidden_size)
params = initilization(X.shape[1], hidden_size)
costs = []
itr = []
if optimizer == 'momentum':
v = initilization_moment(params)
elif optimizer == 'rmsprop':
s = initilization_RMS(params)
elif optimizer == 'adam' :
v,s = initilization_Adam(params)
for i in range(1,num_iter):
MiniBatches = RandomMiniBatches(X, Y, 32) # GET RAMDOMLY MINIBATCHES
p , q = MiniBatches[2]
for MiniBatch in MiniBatches: #LOOP FOR MINIBATCHES
(MiniBatch_X, MiniBatch_Y) = MiniBatch
cache, A = model_forward(MiniBatch_X, params, L,keep_prob) #FORWARD PROPOGATIONS
cost = cost_f(A, MiniBatch_Y) #COST FUNCTION
grad = backward(MiniBatch_X, MiniBatch_Y, params, cache, L,keep_prob) #BACKWARD PROPAGATION
if optimizer == 'momentum':
params = update_params_with_momentum(params, grad, v, beta=0.9,learning_rate=learning_rate)
elif optimizer == 'rmsprop':
params = update_params_with_RMS(params, grad, s, beta=0.9,learning_rate=learning_rate)
elif optimizer == 'adam' :
params = update_params_with_Adam(params, grad,v, s, beta1=0.9,beta2=0.999, learning_rate=learning_rate,t=i) #UPDATE PARAMETERS
elif optimizer == "minibatch":
params = update_params(params, grad,learning_rate=learning_rate)
if i%5 == 0:
costs.append(cost)
itr.append(i)
if i % 100 == 0 :
print('cost of iteration______{}______{}'.format(i,cost))
return params,costs,itr
迷你包装训练
params, cost_sgd,itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='minibatch')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))使用小型包装的结论:
cost of iteration______100______0.35302967575683797
cost of iteration______200______0.472914548745098
cost of iteration______300______0.4884728238471557
cost of iteration______400______0.21551100063345618
train_accuracy------------ 0.8494208494208494
脉冲优化器培训
params,cost_momentum, itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='momentum')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))脉冲优化器输出:
cost of iteration______100______0.36278494129038086
cost of iteration______200______0.4681552335189021
cost of iteration______300______0.382226159384529
cost of iteration______400______0.18219310793752702 train_accuracy------------ 0.8725868725868726RMSprop培训
params,cost_rms,itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='rmsprop')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))RMSprop输出:
cost of iteration______100______0.2983858963793841
cost of iteration______200______0.004245700579927428
cost of iteration______300______0.2629426607580565
cost of iteration______400______0.31944824707807556 train_accuracy------------ 0.9613899613899614与亚当一起训练
params,cost_adam, itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='adam')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))亚当的结论:
cost of iteration______100______0.3266223660473619
cost of iteration______200______0.08214547683157716
cost of iteration______300______0.0025645257286439583
cost of iteration______400______0.058015188756586206 train_accuracy------------ 0.9845559845559846您看到两者之间的准确性差异了吗?我们使用相同的初始化参数,相同的学习率和相同的迭代次数。只有优化器有所不同,但要看结果!
Mini-batch accuracy : 0.8494208494208494
momemtum accuracy : 0.8725868725868726
Rms accuracy : 0.9613899613899614
adam accuracy : 0.9845559845559846模型的图形可视化

如果对代码有疑问, 可以检查存储库。
概要
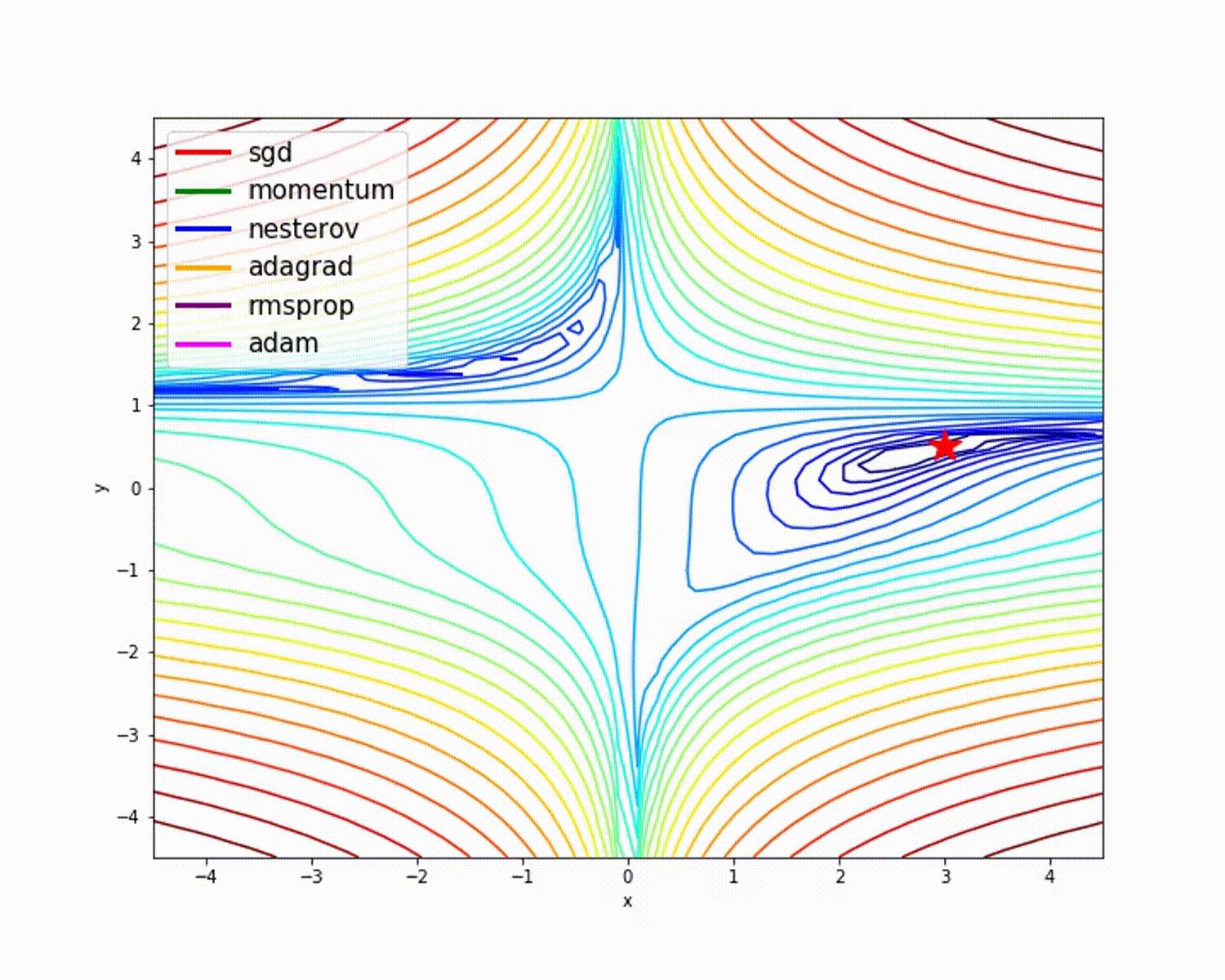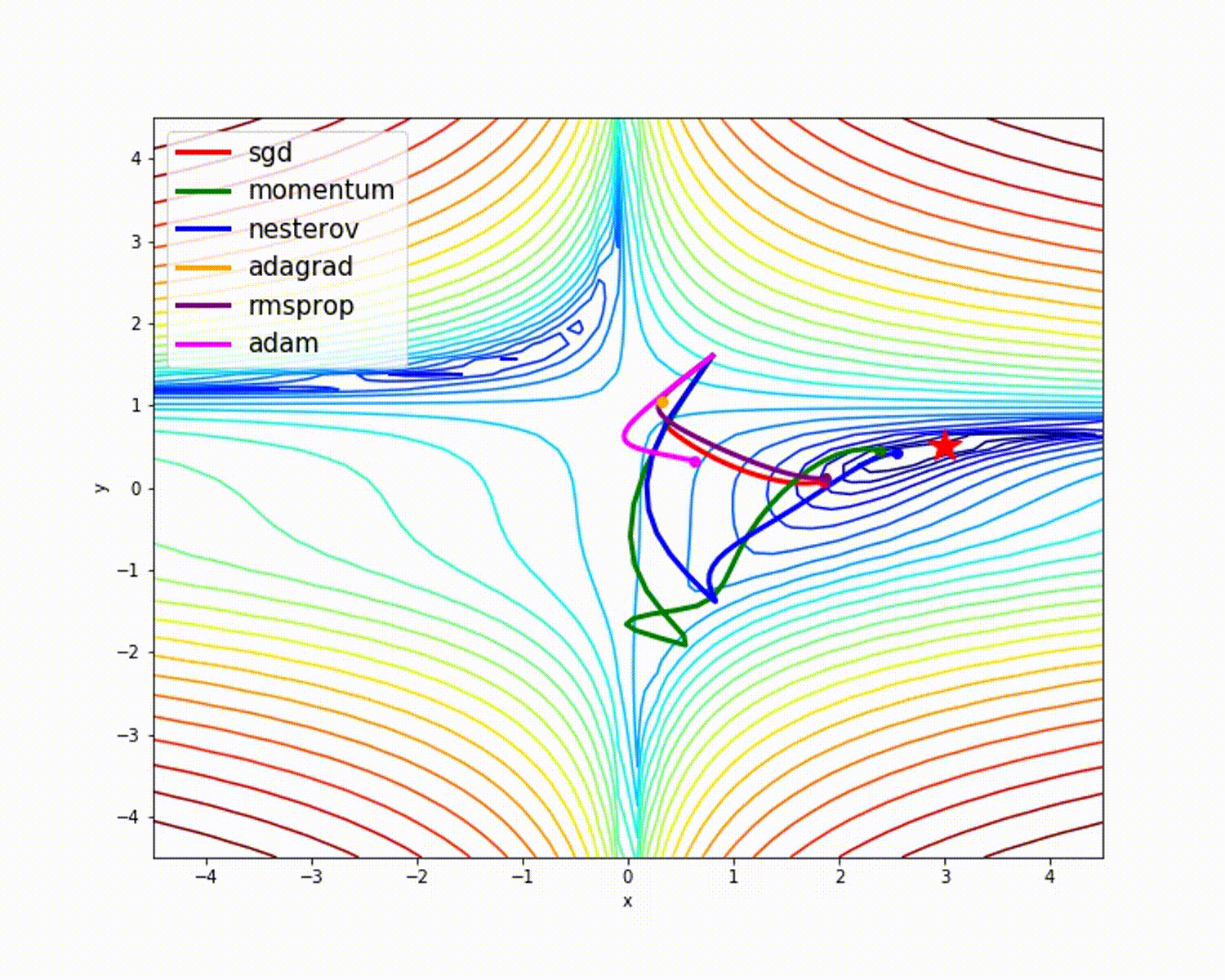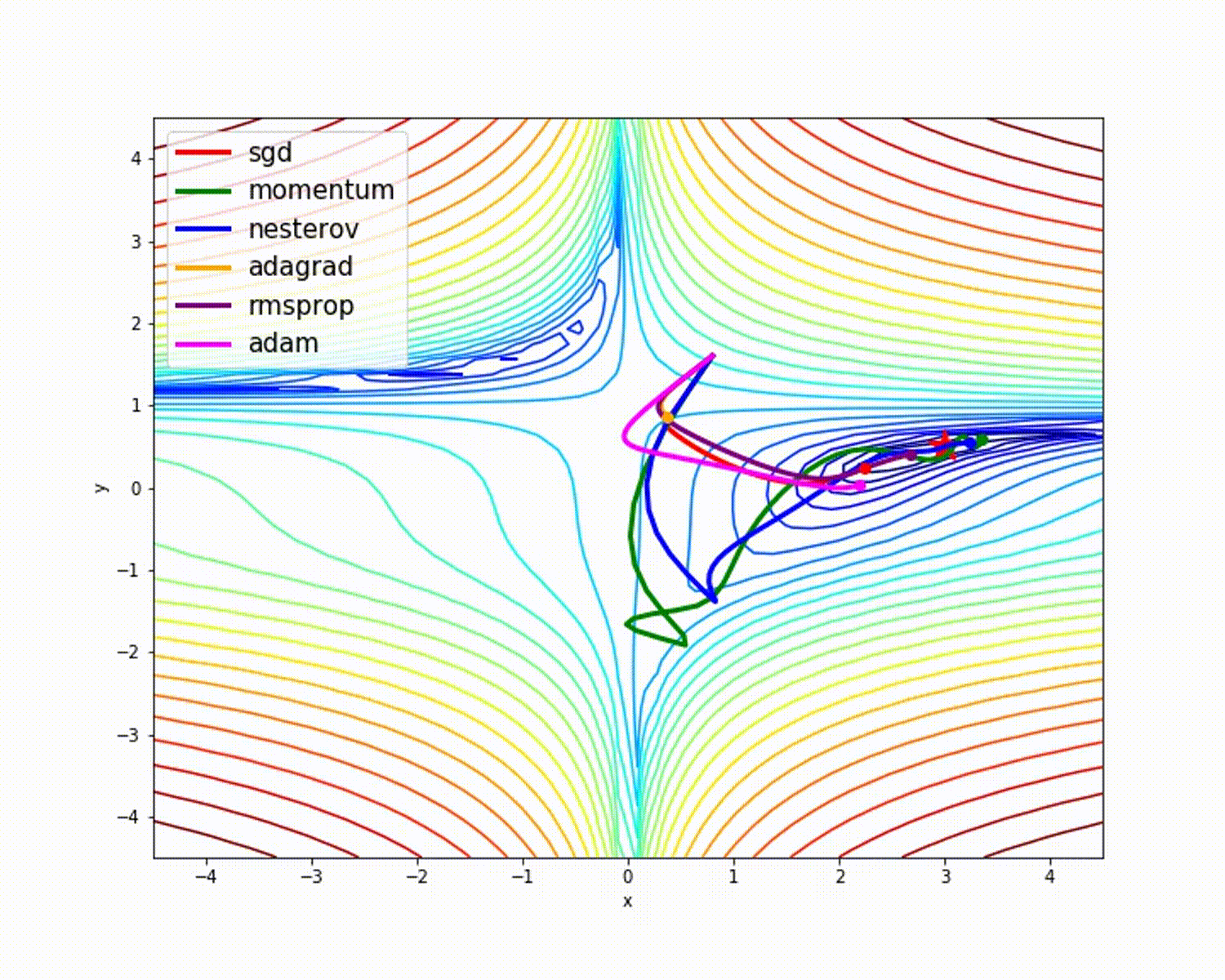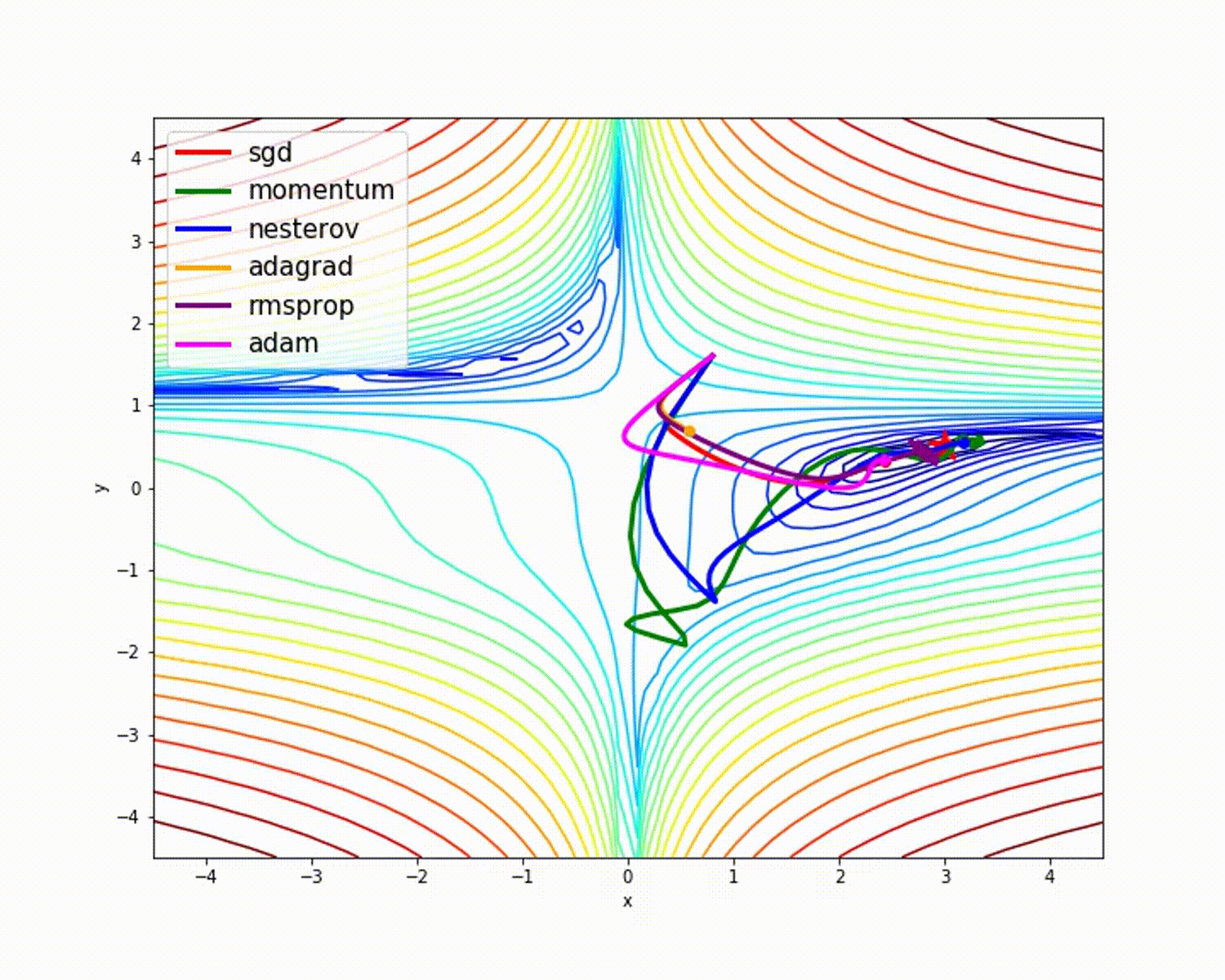
来源
正如我们所看到的,与其他优化器相比,Adam优化器具有良好的准确性。上图显示了模型如何通过迭代学习。动量给出SGD速度,而RMSProp给出更新参数的权重的指数平均值。在上述模型中,我们使用的数据较少,但是在处理大型数据集和进行多次迭代时,我们将从优化器中获得更多收益。我们已经讨论了优化器的基本概念,希望这能给您一些动力来学习更多关于优化器的知识并使用它们!
资源资源
神经网络和深度机器学习的前景是巨大的,按照最保守的估计,它们对世界的影响与19世纪电力对工业的影响大致相同。那些在其他任何人之前评估这些前景的专家都有机会成为进步的领导者。对于这样的人,我们制作了促销代码HABR,将横幅广告上的培训折扣额外给予10%的折扣。

- 机器学习课程
- 课程“数据科学的数学和机器学习”
- 高级课程“机器学习专业版+深度学习”
- 数据科学在线训练营
- 从头开始培训Data Analyst专业
- 数据分析在线训练营
- 从零开始教数据科学专业
- 适用于Web开发的Python