
神话般的犀牛独角兽。 MS TECH / PIXABAY
通过少于一次的尝试学习就可以帮助模型识别出比其所训练的示例数量更多的对象。
通常,机器学习需要很多示例。为了使AI模型能够识别马匹,您需要向她展示成千上万匹马的图像。这就是为什么技术在计算上如此昂贵并且与人类学习有很大不同的原因。一个孩子常常只需要看一个物体的几个例子,甚至一个,就可以学会终身认出它。
实际上,孩子有时不需要任何示例来识别任何东西。显示一匹马和犀牛的照片,告诉他们独角兽在它们之间,并且他们在第一次看到它时,就会在画册中识别出神话中的生物。

嗯...不是真的! MS TECH / PIXABAY
现在,安大略省滑铁卢大学的一项研究表明,人工智能模型也可以做到这一点-研究人员称此过程为“少于一次”的尝试。换句话说,人工智能模型可以清楚地识别出比其经过训练的实例数量更多的对象。这在随着使用的数据集的增长而变得越来越昂贵且难以访问的领域中至关重要。
« »
研究人员首先通过试验流行的称为MNIST的计算机视觉训练数据集来证明了这一想法。 MNIST包含从0到9的60,000张手写数字图像,该集合通常用于测试该领域的新想法。
在上一篇文章中,麻省理工学院的研究人员提出了一种将大型数据集“提取”为小型数据集的方法。作为概念证明,他们将MNIST压缩为10张图像。没有从原始数据集中采样图像。它们经过精心设计和优化,以包含等效的完整信息集。结果,当在这10张图像上训练时,AI模型获得的精度几乎与在整个MNIST集合上训练的精度相同。

来自MNIST集合的样本图像。维基

10描绘,从MNIST“蒸馏”,可以训练的AI模式来实现94%的手写体数字的识别精度。 Wang Tongzhou等人
,Wotrelu大学的研究人员希望继续进行蒸馏过程。如果可以将60,000张图像缩小到10张,为什么不将它们压缩到5张呢?他们意识到,诀窍是在一个图像中混合多个数字,然后将它们输入带有所谓的混合或“软”标签的AI模型中。 (想象一下,马和犀牛具有独角兽的特征。)
“考虑数字3,它看起来像数字8,而不是数字7,”滑铁卢大学的研究生,文章的主要作者伊利亚·萨科霍洛茨基(Ilya Sukholutsky)说。-软标记试图捕捉这些相似之处。因此,我们没有告诉汽车:“此图像为3号”,而是说:“此图像为60%3号,30%8号和10%0号”。
新教学方法的局限性
在研究人员成功地使用软标签以少于一次的尝试使MNIST适应学习之后,他们开始怀疑这个想法能走多远。 AI模型可以从少量示例中学习识别的类别数量是否有限制?
令人惊讶的是,似乎没有限制。使用精心设计的软标签,理论上甚至两个示例都可以编码任意数量的类别。 “只有两个点,您就可以划分一千个类,一万个类或一百万个类,” Sukholutsky说。
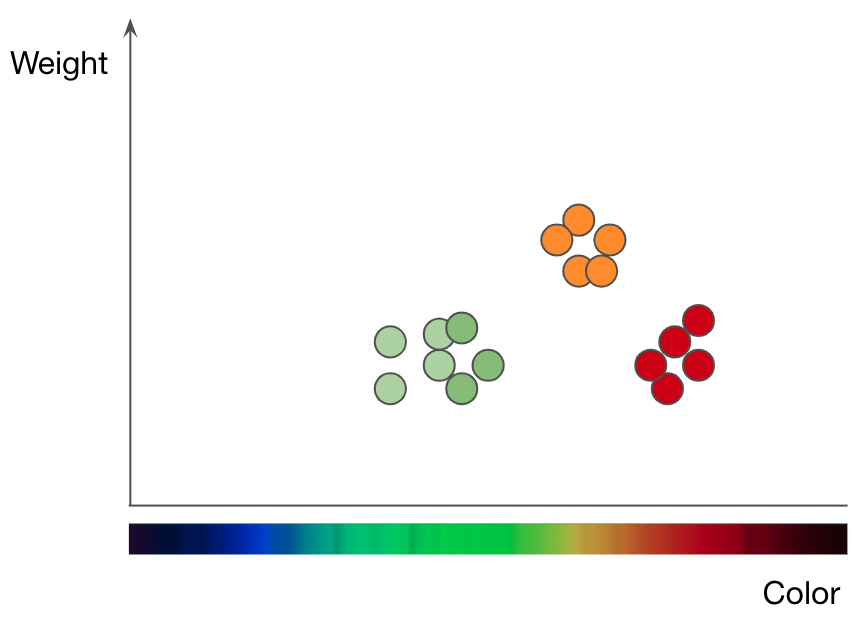
按重量和颜色分类的苹果(绿色和红色点)和橙色(橙色点)分类。改编自Jason Mace的演讲《机器学习101》
这就是科学家在他们最新的文章中通过纯数学研究得出的结果。他们使用称为k最近邻居(kNN)的最简单的机器学习算法之一实现了这一概念,该算法使用图形方法对对象进行分类。
为了了解kNN方法的工作原理,我们以一个水果分类问题为例。要训练kNN模型以了解苹果和橙子之间的区别,您首先需要选择要用于表示每个水果的函数。如果选择颜色和重量,则为每个苹果和橙子输入一个数据点,其中水果颜色为x值,重量为y值...然后,kNN算法在2D图表中绘制所有数据点,并在苹果和橘子之间绘制一条直线。现在,将图整齐地分为两类,并且算法可以确定新数据点是代表苹果还是橘子-取决于该点位于线条的哪一侧。
为了使用kNN算法以不到一次的尝试来学习学习,研究人员创建了一系列微小的合成数据集,并仔细考虑了它们的软标签。然后,他们让kNN算法绘制了所看到的边界,并发现它成功地将图分成了比数据点更多的类。研究人员还很大程度上控制了边界的运行位置。通过对软标签进行各种修改,他们迫使kNN算法以花朵的形式绘制出精确的图案。
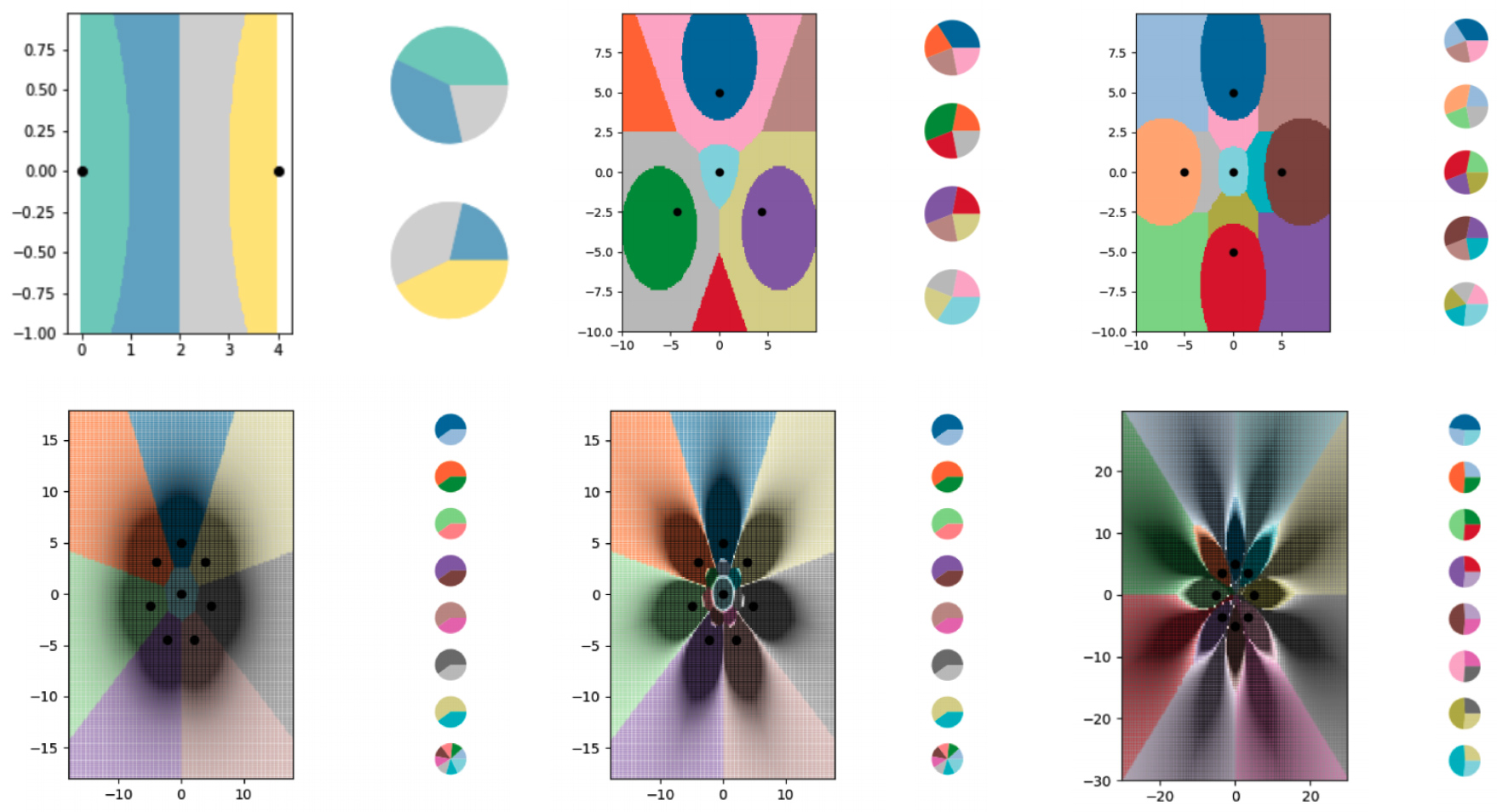
研究人员使用软标签示例来训练kNN算法,以对日益复杂的边界进行编码,并将图分成比其数据点更多的类别。每个彩色区域代表一个单独的类,每个图侧面的饼图显示每个数据点的软标签的分布。
Ilya Sukholutsky等人,
各种图表显示了使用kNN算法构造的边界。每个图表都有越来越多的边界线编码在微小数据集中。
当然,这些理论研究有一些局限性。从``少于一个''尝试中学习的想法可能会转移到更复杂的算法上,但是开发带有``软''标签的示例的任务变得更加复杂。 kNN算法经过解释和可视化,使人们可以创建标签。神经网络是复杂且不可渗透的,这意味着它们对神经网络可能并非如此。数据蒸馏对开发神经网络的软标签示例很有帮助,但它也有一个明显的缺点:它要求您从庞大的数据集入手,将其缩小到更有效的水平。
Sukholutsky说,他正在尝试寻找其他方式来创建这些小型合成数据集-手动或使用其他算法。尽管存在这些额外的研究复杂性,本文还是提出了学习的理论基础。他说:“无论您拥有什么数据集,都可以显着提高效率。”
这就是麻省理工学院研究生通州王的兴趣。他指导了有关蒸馏数据的先前研究。他说:“本文基于一个真正新的重要目标:从小型数据集中训练功能强大的模型。”
蒙特利尔人工智能伦理研究所的研究员Ryan Hurana同意这种观点:“更重要的是,只需进行不到一次尝试就可以学习,从而大大减少了构建功能模型所需的数据。” 这可能使迄今为止受到该领域数据要求所困扰的公司和行业更容易使用AI。由于还需要从人们那里接收更少的信息来训练实用新型,因此它也可以改善数据的隐私性。
Sukholutsky强调说,这项研究尚处于初期阶段。尽管如此,它已经激发了想象力。每当作者开始向其他研究人员介绍他的论文时,他们的第一个反应就是争辩说这种想法超出了可能性范围。当他们突然意识到自己错了时,就会打开一个全新的世界。

