
- 到底消耗了多少内存?
- 有什么办法可以避免这种情况?
在这里,我想谈谈我如何寻找这些问题的答案。我计划在需要剖析Python代码时将其用作参考。
我从程序入口点(
pylint/__main__.py)开始分析Pylint,并进入了for在检查许多文件的程序中期望的“基本”循环:
def _check_files(self, get_ast, file_descrs):
# pylint/lint/pylinter.py
with self._astroid_module_checker() as check_astroid_module:
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
首先,我只是在此循环中放置一条语句
print(«HI»)以确保这确实是我执行命令时开始的循环pylint my_code。该实验运行顺利。
接下来,我决定找出在Pylint工作期间存储在内存中的确切内容。因此,我使用它
heapy并做了一个简单的“堆转储”,希望分析此转储中是否有异常:
from guppy import hpy
hp = hpy()
i = 0
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
print("HEAP")
print(hp.heap())
if i == 100:
raise ValueError("Done")
堆概要文件最终几乎完全由调用堆栈帧(
types.FrameType)组成。由于某种原因,我期望这样的事情。转储中有如此多的此类对象,使我认为它们似乎比应有的数量更多。
Partition of a set of 2751394 objects. Total size = 436618350 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 429084 16 220007072 50 220007072 50 types.FrameType
1 535810 19 30005360 7 250012432 57 types.TracebackType
2 516282 19 29719488 7 279731920 64 tuple
3 101904 4 29004928 7 308736848 71 set
4 185568 7 21556360 5 330293208 76 dict (no owner)
5 206170 7 16304240 4 346597448 79 list
6 117531 4 9998322 2 356595770 82 str
7 38582 1 9661040 2 366256810 84 dict of astroid.node_classes.Name
8 76755 3 6754440 2 373011250 85 tokenize.TokenInfo
正是在这一刻,我找到了Profile Browser工具,该工具可让您方便地处理此类数据。
我配置了转储引擎,以便每10次循环迭代将数据写入文件中。然后,我建立了一个图表,显示了程序在运行期间的行为。
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
hp.heap().stat.dump("/tmp/linting.stats")
if i == 100:
hp.pb("/tmp/linting.stats")
raise ValueError("Done")
我结束了下面显示的内容。此图确认对象
type.FrameType和type.TracebackType(跟踪信息)在调查的Pylint运行期间消耗了大量内存。

数据分析研究
的下一阶段是对象分析
types.FrameType。由于Python中的内存管理机制基于对对象引用的计数,因此只要有人引用数据,数据就会保存在内存中。我决定找出到底是什么“保留”了内存中的数据。
在这里,我使用了一个出色的库
objgraph,利用Python内存管理器的功能,它提供了有关内存中哪些对象的信息,并允许您找出确切地指代这些对象的内容。
实际上,很高兴我们能够进行这种软件研究。也就是说,如果有对某个对象的引用,则可以找到所有引用该对象的内容(对于C扩展名,所有内容都不那么平滑,但是通常,
objgraph提供合理准确的信息)。摆在我们面前的是调试代码的出色工具,它可以访问许多有关CPython内部机制的信息。对我来说,这是将Python视为一种令人愉快的语言的另一个原因。
一开始,我偶然发现了一个对象搜索,因为该团队
objgraph.by_type('types.TracebackType')根本找不到任何东西。尽管我知道有很多这样的对象,但事实并非如此。原来,应该使用字符串作为类型名称traceback。对于我来说,其原因尚不完全清楚,而是什么。最后,正确的命令如下所示:
random.choice(objgraph.by_type('traceback'))
该构造随机选择对象
traceback。借助帮助,objgraph.show_backrefs您可以构建一个引用这些对象的图表。
最后,我决定不只是引发异常,而是决定研究100次迭代后循环
for(import pdb; pdb.set_trace())中发生的情况。我开始研究随机选择的对象traceback。
def exclude(obj):
return 'Pdb' in str(type(obj))
def f(depth=7):
objgraph.show_backrefs([random.choice(objgraph.by_type('traceback'))],
max_depth=depth,
filter=lambda elt: not exclude(elt))
最初,我只看到物体链
traceback,所以我决定爬到100个物体的深度...

分析回溯对象
事实证明,某些对象
traceback引用了相同类型的其他对象。好,好而且有很多这样的连锁店。
一段时间以来,我的业务并没有太大的成功,我研究了它们,然后继续研究我感兴趣的第二种对象-
FrameType(frame)。他们看起来也很可疑。经过分析,我得出了类似于以下的图表。

解析框架对象
事实证明,对象包含
traceback对象frame(因此,存在类似数量的此类对象)。当然,所有这些看起来都很混乱,但是对象frame至少指向特定的代码行。所有这些使我意识到一个荒谬的简单事情:我从不费心使用如此大量的内存来查看数据。我绝对应该看物体本身traceback。
我朝着这个目标迈进了,似乎是所有可能的道路中最曲折的。即,它识别出由创建的转储中的地址
objgraph,然后查看内存中的地址,然后在Internet上搜索“如何在知道其地址的情况下获取Python对象”。经过所有这些实验,我想出了以下行动方案:
ipdb> import ctypes
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object)
py_object(<traceback object at 0x7f187d22b880>)
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object).value
<traceback object at 0x7f187d22b880>
ipdb> my_tb = ctypes.cast(0x7f187d22b880, ctypes.py_object).value
ipdb> traceback.print_tb(my_tb, limit=20)
实际上,您可以对Python说:“看看这个内存。这里肯定至少有一个常规的Python对象。”
后来我意识到,由于有了,我已经可以链接到我感兴趣的对象
objgraph。那是-我可以使用它们。
感觉像库
astroid(在Pylint中使用的AST解析器)正在traceback通过异常处理代码在各处创建对象。我的猜测是,当某人在某个地方使用可以被称为“有趣技巧”的东西时,他们会忘记如何更轻松地完成同一件事。因此,我并不是真的对此抱怨。
对象
traceback有许多与相关的数据astroid。我的研究取得了一些进展!图书馆astroid因为它解析文件,所以它与能够在内存中存储大量数据的程序非常相似。
我翻遍了代码,发现文件中的以下几行
astroid/manager.py:
except Exception as ex:
raise exceptions.AstroidImportError(
"Loading {modname} failed with:\n{error}",
modname=modname,
path=found_spec.location,
) from ex
我想:“就是这样,这正是我想要的!”这是一系列异常,导致对象链最长
traceback。在这里,除其他外,文件被解析,因此这里也可以遇到递归机制。类似于构造的东西将它们raise thing from other_thing联系在一起。
我移走了
from ex……什么都没发生。程序消耗的内存量几乎保持不变,对象traceback也没有丢失。
我知道异常将它们的本地绑定存储在对象中
traceback,因此您可以使用ex。结果,它们的存储器不能被清除。
我做了一些大规模的代码重构,试图从根本上摆脱该块
except,或至少从链接到ex。但是,我什么也没得到。即使
我很忙,我也无法“激发”对象上的垃圾收集器
traceback,即使考虑到没有对这些对象的引用也是如此。我认为其原因是某处还有其他链接。
实际上,那时我走错了路。我不知道这是否是导致内存泄漏的原因,因为有一次我开始意识到我没有证据支持我的“异常链理论”。我只有一堆猜测和数百万个对象
traceback。
然后,我开始随机观察这些物体,以寻找其他线索。我尝试手动“爬上”链接链,但最终我发现只有空虚。
然后它突然降临在我身上:所有这些对象
traceback都位于“一个在另一个之上”的位置,但是必须有一个在所有其他对象“之上”的对象。任何其他此类对象都未引用的对象。
链接是通过属性创建的
tb_next,此类链接的顺序很简单。因此,我决定看一下traceback各个链末端的对象:
bottom_tbs = [tb for tb in objgraph.by_type('traceback') if tb.tb_next is None]
用一根衬里刺穿五十万个物体并找到所需物品,这真是不可思议。
总的来说,我找到了想要的东西。找到了Python必须将所有这些对象保留在内存中的原因。

找到问题的根源
一切都与文件缓存有关!
关键是该库
astroid缓存了加载模块的结果。如果代码需要已使用的模块,则库将简单地为其提供已加载该模块的结果。通过存储抛出的异常,这也导致错误的再现。
在这一点上,我做出了一个大胆的决定,其理由如下:“缓存不包含错误的内容是有意义的。但是,我认为,存储
traceback由我们的代码生成的对象毫无意义。
我决定摆脱异常,保留自己的类,
Error并仅在需要时重建异常。细节可以在这里找到公关,但事实证明并不是特别有趣。
结果,在使用我们的代码库时,我能够将内存消耗从500 MB减少到100 MB。
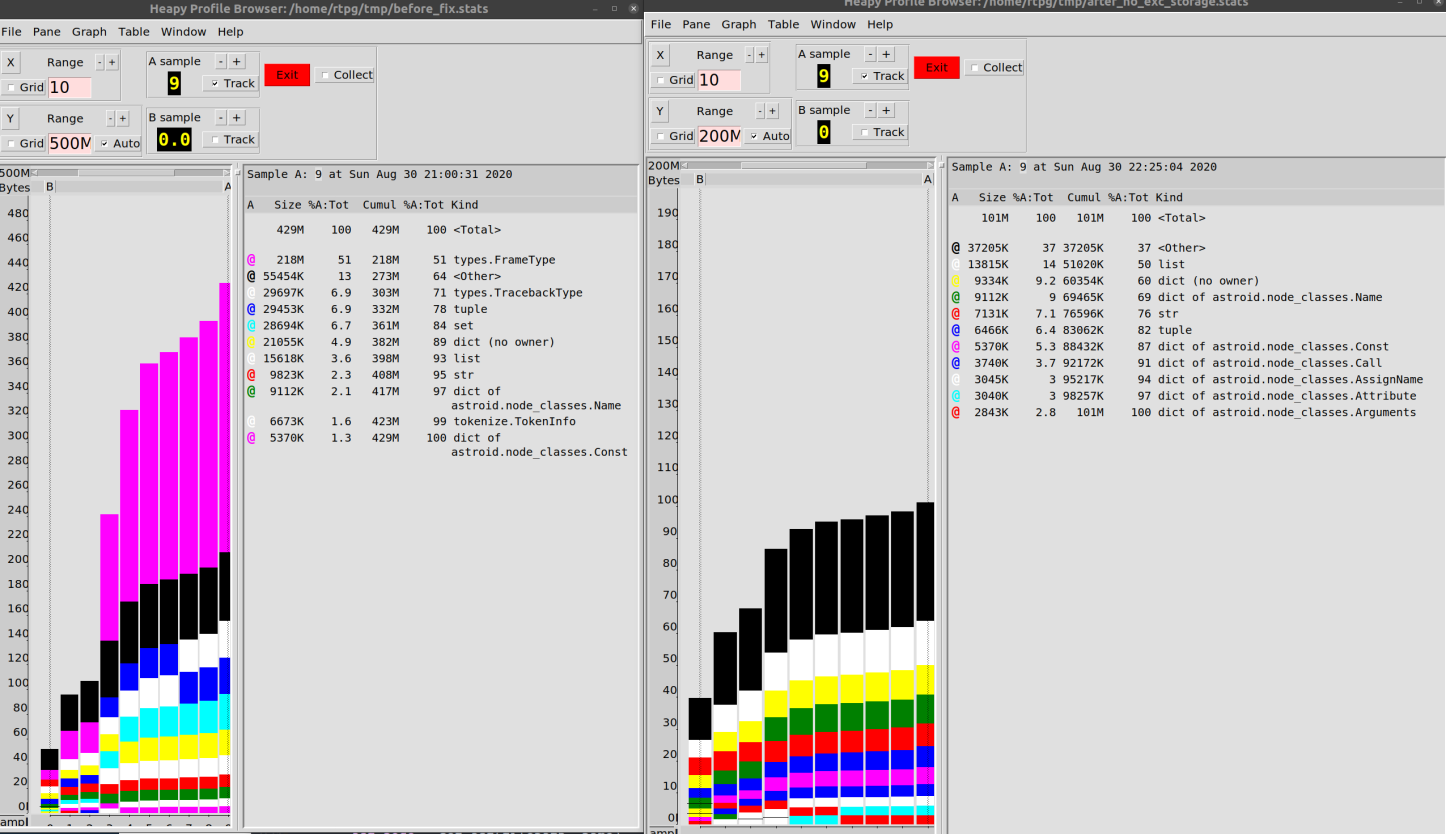
我想说80%的改善
还算不错,说到PR,我不确定它是否会包含在项目中。它本身带来的变化不仅与性能有关。我相信它的工作方式在某些情况下可以减少堆栈跟踪数据的价值。考虑到所有细节,即使此解决方案通过了所有测试,这也是一个相当大的变化。
结果,我为自己得出以下结论:
- Python为我们提供了出色的内存分析功能。在调试代码时,我应该更频繁地使用这些功能。
- , .
- , -, « ». . , , , .
- , (, , Git). , , . , .
在撰写本文时,我意识到我已经忘记了很多可以得出某些结论的东西。因此,我最终再次检查了一些代码片段。然后,我在不同的代码库上进行了测量,发现内存异常仅特定于一个项目。我花了很多时间来查找和解决这种麻烦,但这很可能只是我们所使用工具行为的一个特征,只有少数使用这些工具的人才能体现出来。
即使进行了此类测量,也很难说出明确的性能信息。
我将尝试将我描述的实验中获得的经验转移到其他项目中。我相信开放源代码Python项目中存在许多容易解决的性能问题。事实是,Python开发人员社区通常很少关注此问题(除了-用C语言编写的Python扩展项目外)。
您是否曾经不得不优化Python代码的性能?

