我们如何知道该算法有效?
在开发算法之前,您需要考虑我们如何评估其性能。假设我们写了一个算法,说“此图像具有以下颜色”-他的决定正确吗?那甚至意味着什么-“正确”?
为解决此问题,我们选择了两个重要的维度-原色的正确标记和正确的颜色数量。我们将此设置为算法预测的前景色与实际前景色之间的距离CIEDE 2000(色差公式),并且还计算了颜色数量的平均绝对误差。出于以下原因,我们做出了此选择:
- 这些参数很容易计算。
- 随着度量标准数量的增加,选择“最佳”算法将更加困难。
- 通过减少指标数量,我们可能会错过两种算法之间的重要区别。
- 无论如何,大多数服装都有一种或两种原色,而我们的许多流程都依赖于原色。因此,正确计算基色比正确计算第二或第三色重要得多。
那么“真实”数据呢?我们的采购员团队为我们提供了标签,但是我们的工具仅允许他们选择最常用的颜色,例如“灰色”或“蓝色”,因此无法将它们称为精确值。这样的一般定义包括许多不同的阴影,因此不能用作真实颜色。我们必须构建自己的数据集。
你们中有些人可能已经在考虑诸如Mechanical Turk之类的服务。但是我们不需要标记太多图像,因此描述此任务可能比仅完成它还要困难。此外,创建数据集有助于您更好地理解它。我们迅速将HTML / Javascript应用程序弄乱了,随机选择了1000张图像,为代表其原色的每个像素选择了图像,并标记了我们在图像中看到的颜色数量。此后,很容易获得两个数字来评估我们算法的质量(到主色CIEDE的距离和颜色MAE的数量)。
有时,我们手动检查程序,在一幅图像上运行两种算法并显示两种颜色列表。然后,我们手动对200张图像进行评级,选择公认的“最佳”颜色。以这种方式密切处理数据非常重要-不仅要获得结果(“算法B在70%的情况下比算法A更好”,而且要了解每种情况下发生的情况(“算法B通常选择过多的组,但是算法A错过了浅色”)。

毛衣和颜色由两种不同的算法选择
我们的颜色提取算法
在处理图像之前,我们将它们转换为CIELAB(或仅LAB)色彩空间,而不是更常见的RGB。结果,我们的三个数字将不代表红色,绿色和蓝色的数量。 LAB空间的点(L * a * b *会更正确,但为简单起见,我们将其写为LAB)指定三个不同的轴。 L表示从黑色0到白色100的亮度,A和B表示颜色:A表示从-128绿色到127红色范围内的位置,B表示从-128蓝色到127黄色范围内的位置,此空间的主要优点是均匀性。如果空间中两点之间的欧几里德距离也相同,则在LAB空间中两点之间的距离或差异将被视为相同。
自然,LAB还存在其他问题:例如,我们考虑使用设备特定RGB空间的计算机屏幕上的图像。而且,LAB色域比RGB的色域更宽,也就是说,在LAB中,您可以表达无法通过RGB表示的颜色。因此,从LAB到RGB的转换不能是双向的-通过在一个方向上转换点然后在相反方向上转换点,您可以获得不同的值。从理论上讲,存在这些缺点,但实际上该方法仍然有效。
通过将图片转换为LAB,我们可以获得一组可以视为点的像素(L,A,B,X,Y)。该算法的其余部分与这些点的分组有关,其中第一阶段的组使用所有五个维度,第二阶段的组忽略X和Y维度。
空间分组
我们从没有像素分组的图像开始,该图像经过了上一篇文章中描述的颜色调整,压缩为320x200并转换为LAB。

首先,让我们应用Quickshift算法,该算法将附近的像素分组为“超像素”。

这已经将我们的60,000像素的图像减少到数百个超像素,从而消除了不必要的复杂性。通过将附近的超像素合并在一起,使它们之间的色距较小,可以进一步简化这种情况。为此,我们绘制了它们的区域邻近图-该图中表示两个不同超像素的节点如果它们的像素接触,则通过一条边连接。

– (Regional Adjacency Graph, RAG) . , , , , . , , , , . – , .
图的节点是我们计算出的超像素,边缘是它们在色彩空间中的距离。连接附近两个具有相似颜色的超像素的边缘将具有较低的权重(暗线),具有非常不同的颜色的超像素之间的边缘将具有较高的权重(亮线以及不存在线-如果其权重大于20则不会绘制)。有很多方法可以合并附近的超像素,但是10个简单的阈值就足够了。
在我们的案例中,我们设法将60,000个像素缩小到100个区域,每个区域包含相同颜色的像素。这具有计算上的优势:首先,我们知道背景几乎是白色的大超像素可以被去除。我们删除所有L> 99且A和B在-0.5至0.5范围内的超像素。其次,我们可以在下一步中大大减少像素数。我们将无法将其数量减少到100,因为我们需要根据它们包含的像素数来权衡面积。但是我们可以轻松地从每个组中删除90%的像素,而不会丢失太多细节,并且几乎不会对下一个组造成失真。
不占用空间即可分组
在这一步,我们有几千个具有坐标(L,A,B)的像素。有许多技术可以很好地将这些像素分组。我们选择k-means方法是因为它快速,易于理解,我们的数据只有3维,并且LAB空间中的欧几里得距离是有意义的。
我们不太聪明,并且分组为K = 8。如果某组的点数少于3%,我们将再次尝试,这次是K = 7,然后是6,依此类推。结果,我们得到了1到8个分组中心的列表以及属于每个中心的点数的比例。它们由上一篇文章中描述的colornamer算法命名。
结果和遗留问题
在CIEDE 2000等级上,我们预测的和“真实的”颜色之间的平均距离为5.86 。正确解释该指标相当困难。在简单的CIE76距离度量中,我们的平均距离为7.82。在此度量标准上,值2.3表示微小的差异。因此,可以说我们的结果略高于3,表明存在细微差别。
此外,我们的MAE为2.28色。但这又是一个辅助指标。下文所述的许多算法可减少此错误,但以增加色距为代价。忽略第五或第六位的假色比忽略错误的第一色要容易得多。

即使是颜色相同的东西(如这些短裤),也会由于
阴影而显得暗得多,阴影问题仍然存在。织物无法完美均匀地放置,因此图像的一部分将始终保留在阴影中,并且看起来像是另一种颜色。查找最简单的方法(例如查找具有相同阴影和不同亮度的颜色的副本)不起作用,因为从“无阴影的像素”到“阴影中的像素”的过渡并不总是相同。将来,我们希望使用更复杂的技术,例如DeshadowNet或自动阴影识别。

我们只专注于衣服的颜色。珠宝和鞋子有其自身的问题:我们的珠宝照片太小,而鞋子的照片通常会显示它们的内部。在上面的示例中,我们将在照片中指出勃艮第和o石的存在,尽管只有第一个很重要。
我们还尝试了什么
最后一个算法看起来很简单,但是要想起来却并不容易!在本节中,我将描述我们尝试和学习的选项。
清除背景
我们已经尝试了背景去除算法,例如Lyst的算法。非正式评估表明,它们不能像简单去除白色背景那样准确地工作。但是,我们计划在处理照片工作室无法处理的图像时更深入地研究它。
散列像素
一些颜色提取库选择了一个解决此问题的简单解决方案:通过将像素散列到几个足够宽的容器中来对像素进行分组,然后返回像素数量最大的LAB容器的平均值。我们试用了Colorgram.py库;尽管它很简单,但效果却出奇的好。此外,它的工作速度很快-每个图像不超过一秒钟,而我们的算法每个图像花费数十秒。但是,Colorgram.py与基色的平均距离比我们的算法大-主要是因为其结果取自与大容器的平均距离。但是,有时在速度比准确性更重要的情况下使用它。
另一种超像素分割算法
我们使用Quickshift算法将图像分割成超像素,但是有几种可能的算法-例如SLIC,Watershed和Felzenszwalb。在实践中,Quickshift由于使用小零件而表现出最佳效果。例如,SLIC存在条纹之类的问题,它们占用了图片中的大量空间。这是使用不同设置的SLIC算法的指示性结果:

原始图像

压缩度= 1

压缩度= 10

压缩度= 100
为了处理我们的数据,Quickshift具有一个理论上的优势:它不需要连续的超像素通信。研究人员指出,这可能会导致算法出现问题,但是在我们的案例中,这是一个优势-我们经常遇到一些小细节,希望将它们带到一个小组中。格仔

衬衫

的Quickshift
对其Superpixel分组尽管Quickshift的Superpixel分组看起来很混乱,但实际上它会将所有红色条纹与其他红色,蓝色与蓝色等进行分组。
计算组数的不同方法
使用k-means方法时,出现最常见的问题:如何制作“ k”?也就是说,如果我们需要将点分成一定数量的组,我们应该做多少个?已经开发出几种方法来回答这个问题。最简单的方法是“肘方法”,但是它需要手动处理图形,因此我们需要一种自动解决方案。 Gap Statistic将该方法形式化,使用它,我们在“颜色数”度量标准上获得了最佳结果,但以基色的准确性为代价。由于主要颜色是最重要的,因此我们没有在工作程序中使用它,但是我们计划进一步研究此问题。
最后,轮廓法是另一种流行的k选择方法。它产生的结果比我们的算法稍差,并且有一个严重的缺点:它至少需要2组。但是许多衣物只有一种颜色。
数据库扫描
选择k的一个潜在解决方案是使用不需要您选择此参数的算法。一个流行的例子是DBSCAN,它在数据中搜索密度大致相等的组。

多彩多姿的衬衫
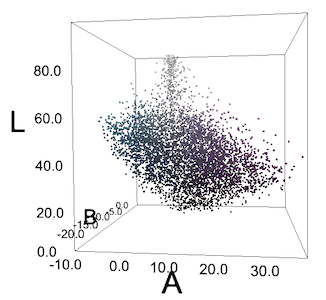
她图像的所有像素都在LAB空间中。像素不形成清晰的青色和紫色基团。
通常我们没有得到这样的群体,或者我们仅仅由于人类感知的特殊性而看到类似群体的东西。对于我们来说,衬衫上的绿蓝色“黄瓜”在紫色背景下显得突出,但是如果我们以RGB或LAB坐标绘制所有像素,它们将不会形成组。但是我们还是尝试使用不同的epsilon值来尝试DBSCAN,但结果可想而知。
来自阿尔及利亚的解决方案
研究人员的良好原则之一是查看是否有人已经解决了您的问题。Algolia网站的Leo Ercolanelli于三年前发布了解决此问题的详细方法说明。由于他们慷慨地分配资源,我们能够自己尝试解决方案。但是,结果比我们的结果稍差,因此我们放弃了算法。他们没有解决与我们相同的问题:他们在模型上有产品图片,并且背景不是白色,因此它们的结果与我们的结果有所不同是有道理的。
色彩协调
该算法完成了我们上一篇文章中描述的过程。提取分组中心后,我们使用Colornamer对其命名,然后将这些颜色导入我们的内部工具中。这有助于我们通过颜色轻松地可视化我们的产品;我们希望将这些数据整合到购买推荐算法中。这个过程并不完美,它可以帮助我们获取数千种产品的更好数据,从而有助于实现我们的主要目标,即帮助人们找到自己喜欢的样式。
采访第一部分的翻译