对于搜索IT专家而言,这种方案尚未特别适用,因为该领域是特定的,此处招聘人员使用其他工具。至于其余的,这是一个很热门的话题,尤其是当有超过一百个空缺的受访者时。
亚历山大·巴拉巴什(Alexander Barabash)向我们介绍了该服务的工作方式以及人事官员的逻辑是什么。他正式是GoRecruit的董事,但与此同时,他与开发直接相关。
REM AI-. Awtor (https://habr.com/ru/company/leader-id/blog/521378/), iPavlov (https://habr.com/ru/company/leader-id/blog/522624/) OpenTalks.AI (https://habr.com/ru/company/leader-id/blog/523448/).-什么是GoRecruit,它如何运作?
-这是一个基于对来自简历和包括社交网络在内的开源数据的分析来支持人员决策的系统。它计算出申请某种职业的申请人的等级,从而减少了招聘人员的人工成本。
与类似物的根本区别在于,为了参与评估,申请人必须对空缺做出回应,并独立地将其简历上传至该空缺,或者通过社交网络上的个人资料登录。我认为,这是非常重要的逻辑。一些服务为求职者提供了冷搜索工具:他们从毫无戒心的人们的个人资料中获取开放数据,这有时与社交媒体政策相抵触。这是不对的。我们仅在获得授权(即用户同意)后才收集数据,并以简历和公开来源(例如联邦法警局,内政和税务部的总部)为数据进行补充。该系统的最终任务是通过为人事部门和安全人员生成详细的报告来丰富有关申请人的数据。
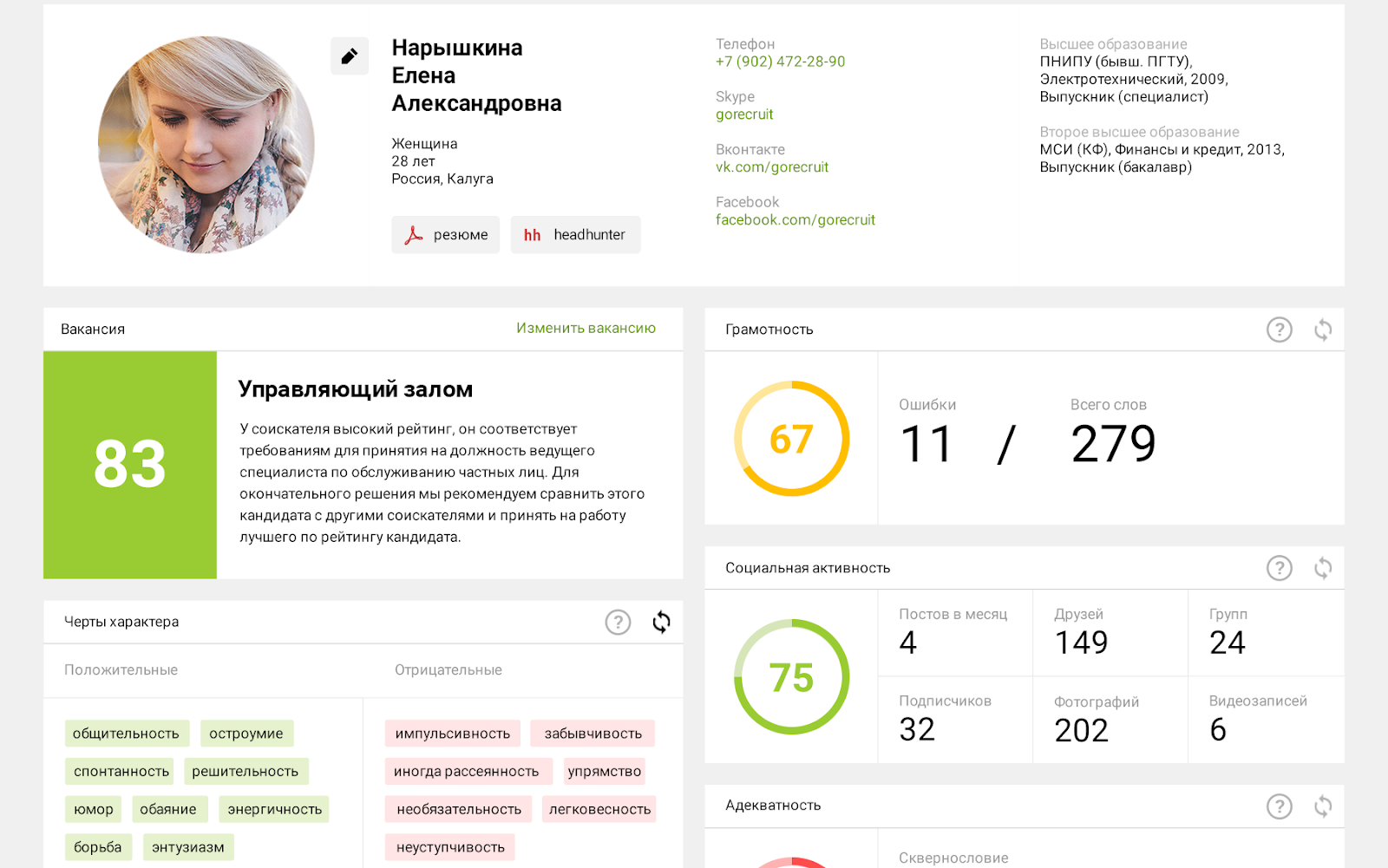
除其他信息外,该报告还包含一个等级,该等级表征了给定候选人在选定空缺中的预期成功。招聘人员决定下一步如何处理此等级。
-您如何描述空缺以便进行比较?人工智能在哪里?
-实际上,现在经常被谈论的人工智能是一种推断统计数据的方法。但是,要进行推断,您需要有足够的初始信息。对于有人员流动统计的大型企业,我们使用神经网络基于此数据构建空缺模型。
实际上,我们分析有关在给定职位上成功的公司员工的信息。结果,将基于公司的经验(基于与该公司类似职位的其他人的比较)计算报告中的候选人评分。
对于统计数据不足以建立模型的中小型企业,我们使用专家系统。该系统的数学模型基于专家的专家意见,它取代了决策过程中人类思维的过程。当企业缺乏自己的统计信息时,这种方法是合理的。随着时间的流逝,我们将开发这些模型-根据需要进行调整。
-如果我们谈论一个神经网络模型,那么在这个位置或那个位置如何评估一个人的“成功”?
-这是我们工作的精妙之处之一。这些标准因公司而异。最简单的选择是一段时间后的就业状态。例如,如果某个人在受雇一年后仍在这个职位上工作,那么他就可以被认为是成功的,因为最终目的是找到一个能够在公司中长期工作的,毫无问题的人。
更高级的公司具有内部HR KPI。我们以他们为基础-我们认为具有指标(例如70%以上)的成功人士。我们选择有关人员流动的数据,并分别为每个职业训练数学模型。
-这种方法的适用性有哪些局限性?
-没有硬性限制。但这是一种统计方法。显然,数据越多(样本越丰富),预测越准确,即我们将更准确地说出应聘者将有多成功。因此,该解决方案最适合某些大众职业。我们尚未准备好为高职位或独特职位提出建议。
-系统在寻找人的过程中占据什么位置?
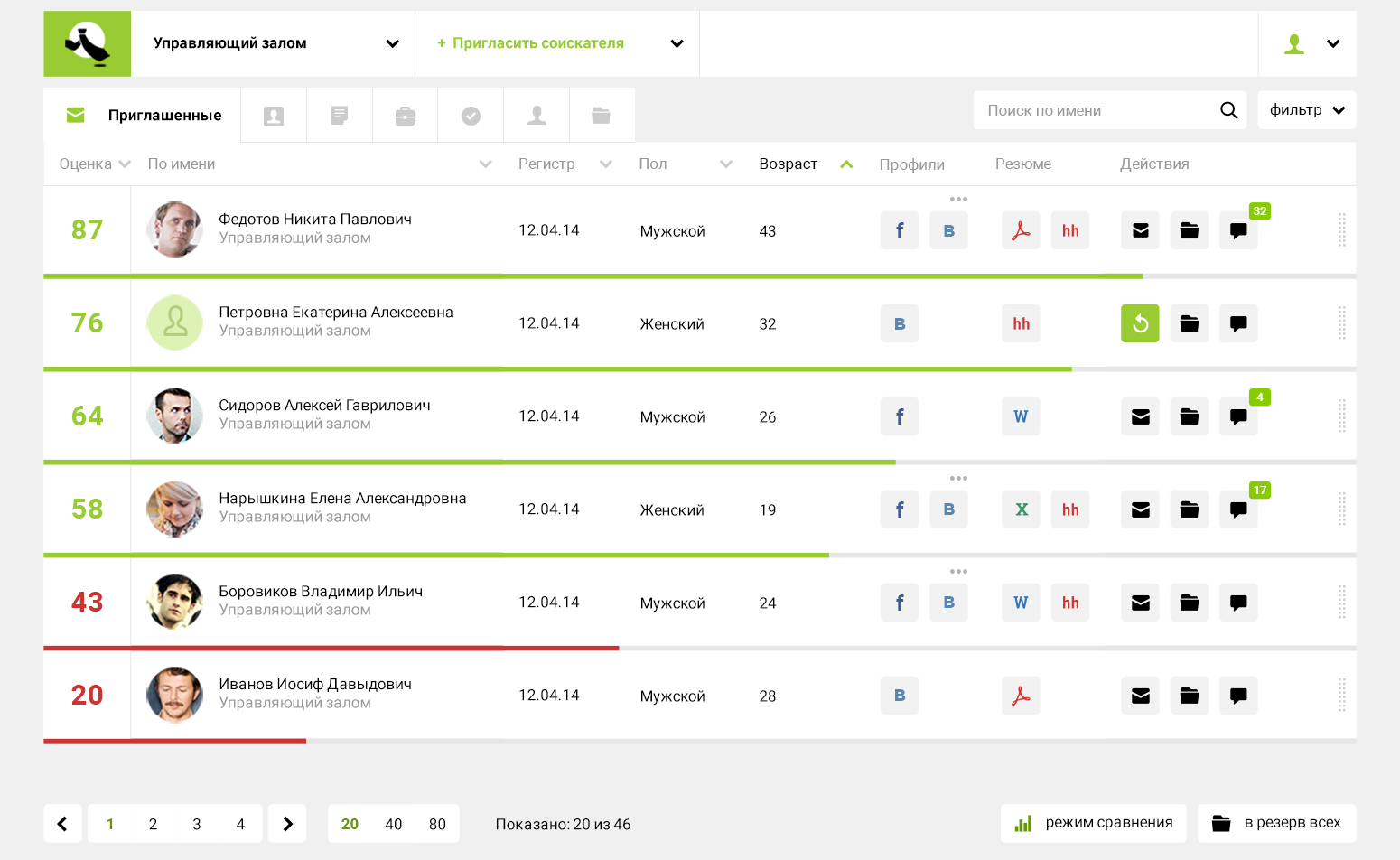
-我们不从事搜索。我们占据了一个不同的利基市场-当我们收到许多关于空缺的答复时,我们会进行评估,并且有必要确定谁要求面试。
: . 600 . 5 , 50 , , , , .我们的系统会在5秒钟内给出答案:它会计算评分,并以此对600个简历进行排名。您可以立即进入下一个阶段-邀请面试或发送测试任务,具体取决于公司内部人事决定的方式。
实际上,这是与人事决策相关的动作链中最耗时的初始筛选器。比较三个人是一回事。但是不可能记住和比较有条件的600份简历-这超出了人的身体能力。在阅读了十几本之后,您已经忘记了开始时发生的事情。我们的心理学家喜欢重复一遍,即人类的大脑会记住并可以在大脑中快速存储约7-10个参数。因此,最大的问题是招聘人员将在一周内手动研究600份简历的情况。
-此评级的准确度如何?您从简历中获取什么数据?
-我们使用一种组合方法-我们将本体工程方法与神经网络相结合。系统从简历文本中提取语义,这是我们随后进行等级评估所需的。该人之前在哪里工作,担任什么职位,担任什么职位,是否有工作中断,取得了什么成就,从事了哪些工作,接受了什么样的教育,他的职业是否与教育背景相对应,等等。
此外,如果重要的话,我们会突出显示年龄,性别和其他其他信息-常规人力资源官在阅读简历时会查看的所有内容。这些项目都是参数。通常,招聘人员会比较它们,我们只是将这种比较算法化。
-您还会使用哪些其他信息来源?
-除了上述内务部,FSSP等基地外,我们现在正在使用社交网络VKontakte。我们也有针对Facebook和Twitter的开发,但VKontakte是主要来源。当我们为多功能中心的PC操作员的职位制定人事决策模型时,我们发现大约97%的候选人在此社交网络上都有个人资料。顺便说一句,当时客户当时怀疑是否可以使用VKontakte的数据来丰富个人资料,但97%的指标使他放心。
-您的系统对您的社交网络个人资料到底有什么兴趣?
-首先,我们采用某人在其页面上发布的文字来确定其心理特征。

宾夕法尼亚大学和剑桥大学联合研究的用于评估心理型的关键字示例。 这是一种数据预处理。我们通过帖子中使用的单词和短语来评估个人素质(您可以在此处(pdf)和此处阅读有关在Facebook上分析帖子的类似技术的更多信息)。
使用Myers-Briggs类型,我们将一个人归因于16种心理型之一。这些信息也会影响最终评级:心理型完全不同的人适合不同的职业。
另外,我们当然对个人资料中的信息感兴趣。 VKontakte提供了大约70个参数-一个人在页面上写的关于自己的信息:年龄,性别,教育程度,偏好,孩子等。
-系统可以评估一个人多少个职位?如果只有猫的照片发布在社交网络上怎么办?
-该系统不提供奇迹-它的行为就像普通的招聘人员。
假设某候选人申请了一份工作,但没有写任何简历。我们(像招聘人员一样)查看开放数据-假设那里也什么也没有。社交网络本身上没有个人资料,或者它是空的。
. , , .这是做出人事决定的普遍逻辑。如果您看不到有关候选人的信息,并且无法使用开放源代码进行检查,请转到下一份简历。
在比较两个人时-具有丰富的经验,良好的教育和知识,或某种隐身方式,您很可能会选择一个您所了解的人。
我们的系统在这里解释人的逻辑。数据不足也是以某种方式表征一个人的信息,但通常,它的评分较低。
-因此,从系统的角度来看,理想的候选人是在社交网络上公开“散布自己的生活”的人吗?
-不社交媒体只是一个附加组件,基本数据可从简历中获取。
-您是否分析了Habré上的文章文本或GitHub上的代码以进一步丰富您的个人资料?
-不 这些主要是IT人员的资源,我们没有重点。在此部分中,还有一些其他工具可用于搜索和评估IT专家。
-从系统的角度来看,是否有任何因素明确地记入候选人的正负值?
-这正是GoRecruit的独特功能:没有这些因素。收集的所有数据都会影响最终决定。但是,对于每个行业,每个公司而言,每个因素的影响程度都会有所不同。
数学模型的含义在于以下事实:这些参数根据训练的进行方式而改变-为此使用了什么数据。
-在制作模型的过程中,数百张简历必须已经通过。您能确定几代人的典型特征吗?
-大概不是,除了一个。一个人年龄越大,他的背景就越丰富。通常,随着年龄的增长,他的职业道路开始追寻,并且通常会有关于他的更多信息。
但我可以注意到另一个功能:简历作为一种格式,比乍一看看起来要多样化得多。尽管存在诸如HeadHunter之类的模板,但是人们在履历表和措辞上都写出了截然不同的东西。由于所有算法部分取决于简历的结构,因此在这里我们面临识别语义的问题。这是一项具有挑战性和挑战性的任务。
-您已经申请了Archipelago 20.35加速器... 你想从他那里得到什么?
-我认为这是一个全方位发展我们产品的有趣机会。根据我对群岛的了解,它提供了多方面的机会,因此我们不会将这次活动视为单方面的-寻找投资者或其他。在这里,我们正在等待开发问题,新联系人,产品推广的解决方案,甚至还会寻找客户。一起。
-谁在您的团队中?招聘人员,开发人员,数学家?
-我们拥有一个由数学家,程序员和心理学家组成的团队-技术和人文科学(心理学和数学)交汇处的人们,大数据领域的专家,人工智能(机器学习)。