
图片来源
自然语言处理的两次革命
NLP的第一个革命与基于语言语义矢量表示的模型的成功相关,该模型是使用无监督学习方法获得的。这些模型的兴起始于博士生Yoshua Bengio(现代深度学习的创始者之一,图灵奖获得者之一)TomášMikolov的研究成果的发表。),以及流行的word2vec工具的出现。第二次革命是从递归神经网络中注意力机制的发展开始的,这导致了人们的理解,即注意力机制是自给自足的,并且在没有递归网络本身的情况下也可以很好地使用。所得的神经网络模型称为“变压器”。它是由Google Brain和Google Research的一组研究人员在2017年题为“注意力就是全部”的文章中提交给科学界的。基于变压器的网络的快速发展导致了诸如OpenAI的Generative Pre-trained Transformer 3(GPT-3)之类的巨型语言模型能够有效解决许多NLP问题。
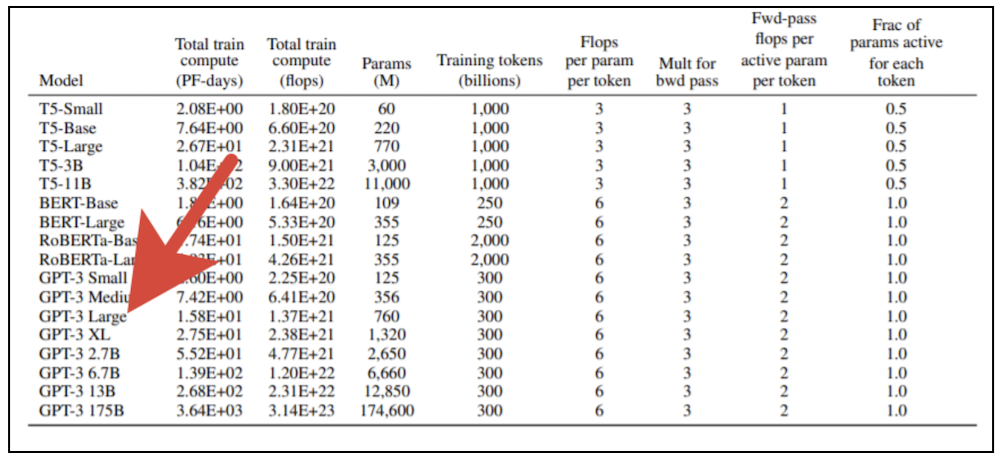
训练巨型变压器模型需要大量的计算资源。您不能只拿一张现代图形卡在家用计算机上训练这样的模型。在原始的OpenAI出版物中,提供了该模型的8个变体,如果您采用最小的变体(GPT-3 Small)并具有1.25亿个参数,并尝试使用配备有强大张量核心的专业视频卡NVidia V100进行培训,则大约需要六个月的时间。如果我们采用具有1750亿个参数的模型的最大版本,那么结果将不得不等待近500年。以提供现代计算设备出租的云服务的速度训练模型的最大版本的成本,超过10亿卢布(而且随着所涉及的处理器数量的增加,这仍然受到线性性能扩展的限制,这在原则上是无法实现的)。
超级计算机万岁!
显然,此类实验仅适用于拥有大量计算资源的公司。为了解决此类问题,Sberbank于2019年启用了Christophari超级计算机,该系统在性能方面在我国可用的超级计算机中排名第一。通过基于Infiniband技术的超高速总线连接的75个DGX-2计算节点(每个节点有16个NVidia V100卡)让您在短短几个小时内即可训练GPT-3小号。但是,即使对于这样的机器,训练模型的较大变体的任务也不是简单的。首先,机器的一部分正忙于培训其他模型,这些模型旨在解决计算机视觉,语音识别和合成以及来自Sberbank生态系统的各个公司感兴趣的许多其他领域中的问题。其次,学习过程本身是非标准的,学习过程本身在模型权重不适合一张卡的内存的情况下同时使用许多计算节点。
总的来说,我们发现自己处于这样一种情况,即许多人都熟悉的散发的火炬不适合我们的目的。我们没有太多选择,因此我们转向了NVidia Megatron-LM的“本机”实现。以及微软新的创意产品DeepSpeed,它需要在Christophari上创建自定义docker容器,而来自SberCloud的同事很快就提供了帮助。首先,DeepSpeed为我们提供了用于模型并行训练的便捷工具,即,将模型扩展到多个GPU并在GPU之间分片优化程序。这使您可以使用更大的批次,以及重量超过15亿的火车模型,而无需添加大量代码。
令人惊讶的是,过去半个世纪以来,技术的发展描述了下一轮螺旋式增长-看来大型机(具有终端访问功能的强大计算机)时代正在重新出现。我们已经习惯了主要的开发工具是分配给开发人员专用的个人计算机这一事实。在1960年代末和1970年代初,一小时的大型机操作成本与计算机操作员一个月的工资大致相同!看来这些时代已经一去不复返了,“铁”变得比工作时间便宜得多。但是,看起来硬件已经卷土重来。现代机器学习专家的日常生活再次与Strugatsky兄弟的故事“星期一从星期六开始”的故事类似Sasha Privalov的日常生活。,唯一不同的是,在我们的案例中,“ Aldan”的位置由“ Christofari”取代,而魔术和魔法的作用则是通过深度学习的方法来实现的。
来自SberDevices的经验
过去很多次,我们不得不学习基于变压器的其他模型-这些模型是BERT和编码器/解码器模型的各种继承者,例如Google的T5。由SberDevices为各种表面创建的虚拟助手,从最新的SberBox和SberPortal开始并以熟悉的Sberbank Online应用程序结尾,他们在工作中使用了几种类似的模型来解决与用户交流过程中的各种问题。例如,虚拟助手Joy在聊天模式下使用GPT-2中型模型,在大量俄罗斯文学作品上接受训练,在特殊的对话数据集上“完成”,并配备了旨在选择最有趣答案的特殊排名机制。这样的模型能够与用户进行对话,而不是从预先准备的答案库中选择线索,而是“即时”制作自己的短语,这使与他们的交流更加多样化和娱乐性。
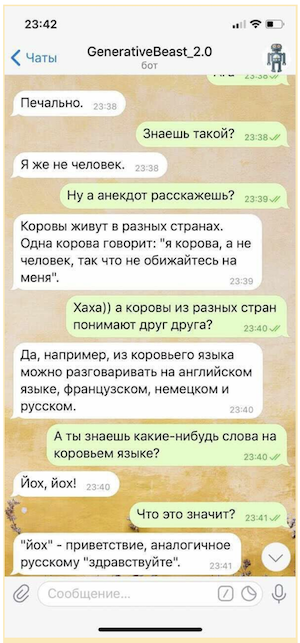

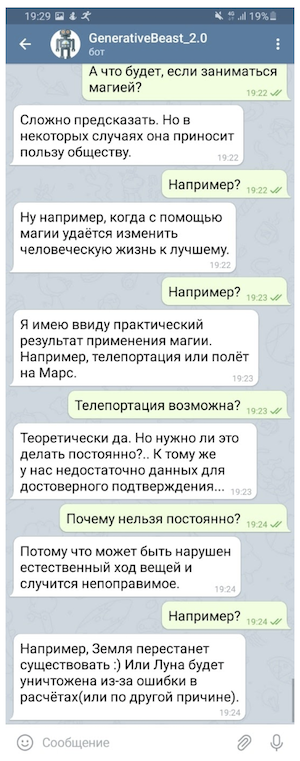
当然,如果没有某种保证,就不能以微观意图系统(旨在为一些最敏感问题提供受控答案的规则)和旨在躲避挑衅性问题的单独模型的形式使用这种“颤抖”,即使这种形式也很有限“生成”,“颤抖”能够显着提高对话者的情绪。
简而言之,当Sberbank的管理层决定为研究项目培训GPT-3时分配计算资源时,我们在教授大型变压器模型方面的经验便派上了用场。这样的项目需要同时结合多个部门的努力。在SberDevices方面,实验机器学习系统部(在其他团队的许多专家的参与下)在此过程中发挥了领导作用,在Sberbank.AI方面则由AGI NLP团队承担。支持Christophari的SberCloud同事也积极加入了该项目。
我们与AGI NLP团队的同事一起,成功组装了第一版俄语培训语料库,总容量超过600 GB。它包括大量的俄罗斯文学作品,俄语和英语的Wikipedia快照,新闻和问答网站的快照,Pikabu的公共栏目,流行科学门户网站22century.ru和银行门户网站banki.ru的完整材料集,以及Omnia Russica语料库。另外,由于我们想尝试处理程序代码的能力,因此我们在训练语料库中包含了github和StackOverflow的快照。... AGI NLP团队在数据清理和重复数据删除以及为模型验证和测试准备数据集方面做了很多工作。如果在OpenAI使用的原始语料库中,英语与其他语言的比例为93:7,那么在我们的案例中俄语与其他语言的比例约为9:1。
我们选择了GPT-3中型(3.5亿个参数)和GPT-3大型(7.6亿个参数)架构作为第一个实验的基础。为此,我们将模型训练为稀疏的交流变压器块以及密集的注意力机制和模型,其中所有注意力模块均已完成。事实是,OpenAI的原始作品谈论的是交错块,但没有提供它们的特定顺序。如果模型中的所有注意框都完整,则会增加训练的计算成本,但会确保充分利用模型的预测潜力。当前,科学界正在积极研究各种注意力模型,旨在减少训练模型的计算成本并提高准确性。在短时间内,研究人员提出了具有自适应注意力跨度的longformer,改革者,变压器。,压缩变压器,块状变压器,BigBird,linformer和许多其他类似模型。我们也在这一领域进行研究,而仅由密集块组成的模型是一种基准,它使我们能够评估模型的各种“加速”版本的准确性下降的程度。
竞赛“ AI 4人文学科:ruGPT-3”
今年,在AI Journey的框架内,Sberbank.AI团队组织了AI 4 Humanities:ruGPT-3竞赛。作为整体测试的一部分,邀请参与者提交使用预训练的ruGPT-3模型创建的任何企业或社会问题的解决方案原型。邀请特别提名“ AIJ Junior”的参与者创建解决方案,以ruGPT-3为基础,根据ruGPT-3为作业的给定主题/课文在11年级(USE)的四个人道主义主题(俄语,历史,文学,社会研究)上生成有意义的论文。
尤其是在这些比赛中,我们训练了三种版本的GPT-3模型:1)GPT-3中型,2)GPT-3大型,具有交替的稀疏和密集变压器模块,3)最强大的GPT-3大型,仅由密集的块。所有模型的训练数据集和令牌生成器都是相同的-使用了BBPE令牌生成器和我们自定义的Large1数据集(容量为600 GB)(其组成在上面的文本中给出)。
所有这三种模型都可以在竞赛资料库中下载。
以下是有关第三个模型如何工作的一些有趣示例:



像GPT-3这样的模型将如何改变我们的世界?
重要的是要理解,像GPT-1 / 2/3这样的模型实际上只能解决一个问题-它们试图按先前序列的顺序预测下一个标记(通常是单词或单词的一部分)。这种方法可以使用“未标记”的数据进行训练,即无需“老师”就可以进行训练,另一方面,它可以解决NLP领域中相当广泛的问题。确实,例如在对话文本中,答复-答复是交流历史的延续;在小说作品中-每个段落的文本都接续先前的文本,在问答环节中,答复的文本紧随问题的文本之后。因此,大容量模型无需特殊的额外培训即可解决许多此类问题-它们仅需要适合“模型上下文”的示例其中GPT-3令人印象深刻-多达2048个令牌。
GPT-3不仅能够生成文本(包括诗歌,笑话和文学模仿),而且还可以纠正语法错误,进行对话甚至(出于状态!)编写或多或少有意义的程序代码。 GPT-3的许多有趣用途可以在独立研究员Gwern Branwen的网站上找到。 Branuen,在开发一个笑话表达的想法鸣叫从安德烈Karpathy,问一个有趣的问题:我们看到一种新的编程模式的出现?
这是Karpaty原始推文的文字:
我喜欢软件3.0的想法。编程从准备数据集到准备查询,这些查询使元学习系统可以“理解”它需要完成的任务。大声笑“ [[爱软件3.0的想法。从策划数据集到策划提示的编程,使元学习者“获得”它应该做的任务。大声笑]。
Branuen提出了Karpaty的想法,他写道:
« GPT-3 [ ] , : , , , ( GPT-2); , , , [prompt], , , «» - , , . , , «» «», GPT-3 . « » , : , , , , , , , , , ».
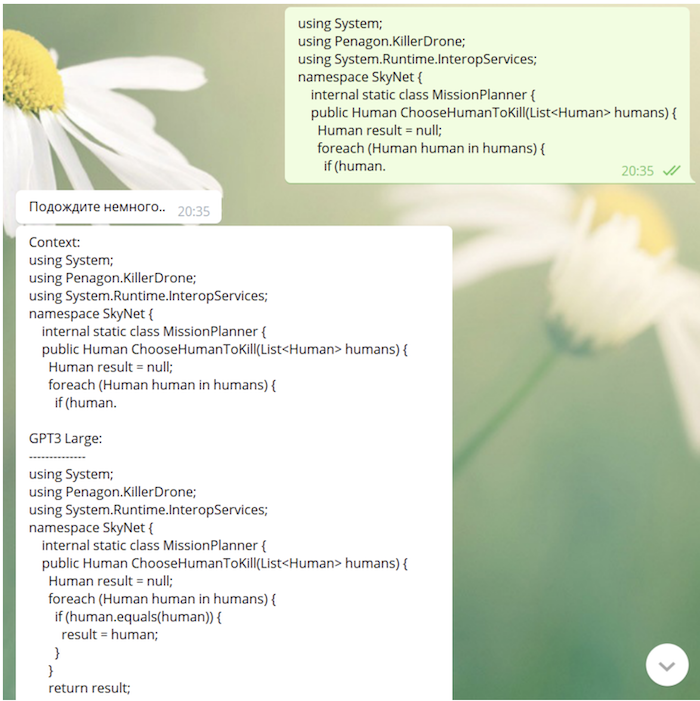
由于我们的模型在学习过程中“看到”了github和StackOverflow,因此它具有编写代码的能力(有时并没有很深的含义):
下一步是什么
今年,我们将继续研究大型变压器模型。进一步的计划与数据集的进一步扩展和清理有关(特别是,将包括用于科学出版物和PubMed Central研究库的arxiv.org预印本服务的快照,专门的对话数据集和有关符号逻辑的数据集),增加经过训练的模型的大小以及改进的令牌生成器。
我们希望,经过训练的模型的发布将刺激需要超强大语言模型的俄罗斯研究人员和开发人员的工作,因为在ruGPT-3的基础上,您可以创建自己的原始产品,解决各种科学和商业问题。尝试使用我们的模型,进行实验,并确保与您获得的所有结果共享。科学进步使我们的世界变得越来越美好,让我们共同改善世界!