悲痛的是,我注意到天秤座(这就是我!)排在最后。不知何故小天秤座!
第1部分。解析和获取初始数据
Wikipedia
在输出列表列表中,您需要一个带有全名+出生日期+(如果还有其他符号-例如,m / f,国家/地区等)的基础,则有一个API。
事实证明,该站点使用Python Scrapy库进行了抓取(收获/接收/提取(提取)/收集从Web资源获取的数据)站点。 首先获得
详细的说明
链接(来自Wikipedia的人的工作表,然后是数据)。
在其他情况下,他们像这样成功解析。
结果:BD文件wiki.zip
第2部分。关于预处理(作者:斯坦尼斯拉夫·科斯滕科夫-以下联系方式)
许多人面临着处理输入数据的复杂性。因此,在此任务中,有必要从42,000多篇文章中提取出生数据,并在可能的情况下确定出生国家。一方面,这是一个简单的算法任务,另一方面,Excel&BI系统的工具不允许“直接”完成它。
这时,编程语言(Python,R)得以解救,大多数BI系统都提供了这种语言的启动。值得注意的是,例如,在Power BI中,在Python中执行脚本(程序)的时间限制为30分钟。因此,在启动BI系统之前,例如在数据湖中,已经进行了许多“繁重的”处理。
问题如何解决
加载并检查无效值后,我要做的第一件事是将每篇文章变成单词列表。
在这项任务中,我很幸运能使用英语。这种语言的特点是句子结构刻板,极大地方便了搜索出生日期。此处的关键字是“ born”,然后查找并分析其后的内容。
另一方面,所有文章均取自一个来源,这也使任务更加容易。所有文章的结构和速度都大致相同。
此外,所有年份均为4个字符,所有日期均为1-2个字符,而月份则为文字。出生日期的拼写只有3-4种可能的变化,这可以通过简单的逻辑解决。也可以通过正则表达式进行解析。
实际代码未优化(未设置此类任务,可能变量名称中存在缺陷)。
正如该国所预测的,我很幸运地找到了国家和国籍的往来表。通常,文章不是描述国家,而是描述国家。例如,俄罗斯-俄语。因此,我们搜索了国籍的出现,但是由于一篇文章中可能有5个以上的不同国籍,因此我做出了一个假设,即所需单词将最接近关键字“ burn”。因此,标准是-文章中必要单词之间的最小索引距离。然后在一行中将其从国籍重命名为国家。
什么都没做
在文章中,很多单词都有垃圾,也就是说,某些代码片段与单词相连,或者两个单词合并在一起。因此,未检查以此类词找到期望值的可能性。您可以使用相似性算法清除这些单词。
没有分析“ burn”关键字所属的实体。在几个例子中,关键字与亲戚的出生有关。这些例子可以忽略不计。这些示例可以追溯到关键字距本文开头很远的事实。您可以计算找到关键字的百分位数并确定剪切标准。
清理数据时预处理的有用性
在常见的情况下,我们可以确切地猜出应该用什么来代替差距。但是,在某些情况下,例如,存在基于商店买方性别的遗漏,并且存在有关其购买行为的数据。在BI系统中,没有解决此问题的标准技术,但是与此同时,在预处理级别,您可以创建“轻型”模型并查看用于填补空白的各种选项。有基于简单机器学习算法的填充选项。值得使用。不难
源代码(Python)可在链接
结果中找到:文件out_data_fin.xls
Stanislav Kostenkov / CBS Consulting(俄罗斯伊热夫斯克)staskostenkov@gmail.com
第3部分。Qlik Sense应用程序
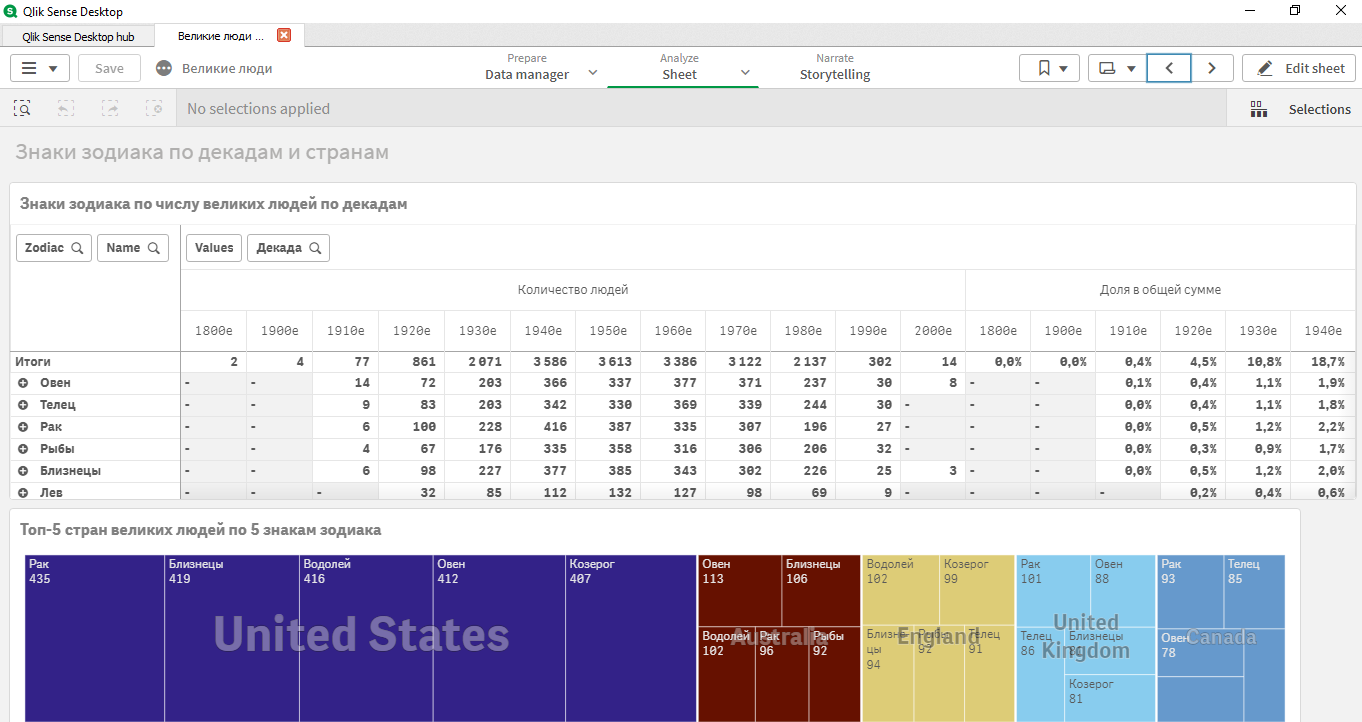
然后制作了一个经典应用程序,其中揭示了数据集的一些异常情况:
- 从1920年至1980年只选择几十年才有意义;
- 根据星座的迹象,在不同的国家有不同的领导人。
- 前兆:巨蟹座,白羊座,双子座,金牛座,摩Cap座。
所有数据(Qlik Sense应用程序接收到的用于数据分析的数据集,原始数据)均通过引用定位。