《旧约》有一个传说,传说古城巴比伦的人们如何开始建造塔楼,但是全能者混合了他们的语言,塔楼还没有建成。不过,由于该塔楼是由数百个小团体共同建造的,这些小团体在一起互不了解。没有彼此的了解,就不可能进行互动。确实,用不同的话语称相同的事物,暗示相同的事物只是疯狂。这里没有什么奇怪的。
旧约的传说可以很容易地转移到实施现代IT解决方案的现代大型公司中。毫无疑问,这类公司的一个例子可以归结为现代俄罗斯银行,这些银行拥有数十个甚至数百个业务部门,这些业务部门具有自己的沟通亚文化,建立在自己的规则和独特的营业额风格基础上。自然,在形成IT基础结构时,会考虑团队中已建立的业务实体的命名方式。在过去的十年中,出现了许多有关此主题的作品,例如,这一部[1]。那些在银行中进行过信息系统分析的人都知道进行所谓的“数据映射”是什么意思,特别是如果最终系统是由分析师,开发人员,客户或供应商的不同团队组成的。通常,映射的60%编制是对传输数据的本质和语义的理解。
当前的趋势是使用一组敏捷方法。每个人都在谈论有关敏捷。您可以争论到声音嘶哑,这是对企业还是有害。但是一件事不会使任何人拒绝。在敏捷过程中,银行内和来自不同供应商的许多不同的团队创建了各种业务的IT解决方案,并且通常在彼此不交互的情况下,团队创建了自己完善的术语。并且当融合确实发生时,旧约中描述的情况也发生了。它与成千上万的商人,商店,商品,愚人节,骗子和吞食者的巴比伦集市有何不同?因此,所有这些拥有不同思想和想法的人开始建造塔楼。
在sprint的最后,我们总是有一组XSD模式(或JSON消息示例),其中的字段需要以某种方式明确地相互关联。争论的去向无关紧要,也许是一组带有映射的“ excel”表,也许是Confluence中的数百条评论,或者是Zoom或Webex中的会议时间,但是花一些时间来整理这种“语义疯狂”的东西神经,最重要的是-金钱。
当然,使用ESB的概念(银行的单一服务集成总线)和全球业务对象模型(例如,在某些欧洲银行中使用的模型),这是信息系统之间的一种“通用语言”,应该使我们摆脱这种情况。但是...说实话,并非所有公司都能负担得起,也不是每个人都需要它。银行业瞬息万变,以至于许多客户都接受了可互操作的微服务平台的概念,该平台在像Kafka这样的消息代理上运行。结果,我们没有一个数据模型,而是通常由一个单独的团队为每种服务创建的一组数据模型。该平台内的交互是由银行分析师不太熟悉的XML进行的消息是基于由一组分析人员,律师,业务代表在设计期间开发的刚性XSD方案的使用,这些方案由几个世纪以来使用,以及更简单和更具描述性的JSON,这些消息已从前端开发人员和决定将“前端”更改为“后端”的开发人员一起推向了银行。 ”。不用说,JSON无法承载严格的架构。对于敏捷方法论来说,这只是更加方便。可以通过添加或删除几个属性来更正它。而且,它与使用特定编写规则所涉及的钢筋混凝土XSD模式没有任何绑定。JSON更易于编辑和修改。更改它更容易访问。
? , - . , ?
.
- . , . MS Excel, , , «» . ( JSON path), — . «». . , :
« »
« »
«20- »
«12- »
« , »
, , , , -. , : , . – “ ”. , , , , , , .
, , , PIP! xslx , . , , Python, .
, – Python. , Python. , , - . , , . – , , . : « , ». — - PyQt Tkinter. , . .
, JSONpath , . , , , Python. , .
. JSON.
. “” 33- . 33 ? – “33” . «». . , , , [2]. . «» . : , , 33- . . . , ABC :
其中在相应位置的每个x坐标是excel文件中字段注释的相应字母的编号。例如,我们有注释“个人帐号”。让我们为它比较一个从笛卡尔系统的坐标原点出现在一个33字母字母空间中的向量,它看起来像这样:坐标X A-对应于字母“ a”的数量。它等于二。X B-在这种情况下,它将等于零,因为该语句中没有字母“ b”。x B同样适用-字母“ B ”丢失。但是x AND-等于3,因为注释中的字母“ and”出现3次。

图1。 , « » . «»= 2, «» =3. – xA=2, x=3.
, , ( ) , 33- « », :
, , « «»» ( , , «» «») « ». :
现在我们找到字母空间的笛卡尔坐标系中向量之间的差异,分别根据解析几何中众所周知的公式找到:
哪里 和 对应于字母的轴的相应矢量坐标。
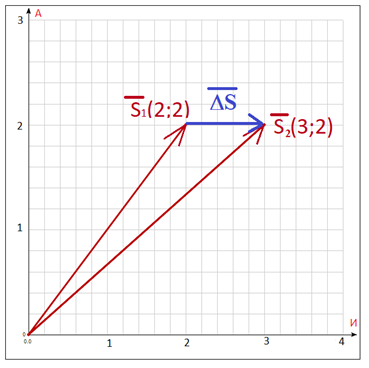
图2. 蓝色显示向量之间的差异在字母空间的字母-的平面上。
因此,对应于语句“个人的帐号”和“物理学家的帐号”之间的差异的向量将如下所示:
,
对应于语句“个人帐号”和“客户帐号”之间差异的向量将如下所示:
此外,通过公式获得的计算出的差矢量的长度为:
如果进行算术计算,则会得到:
这在数学上假设短语“个人帐号”在含义上与“物理学家帐号”比“法人实体帐号”更接近。这由差矢量的长度表示。长度越短,语句之间的含义就越接近。例如,如果我们比较“个人帐户号”和“开设个人帐户的分支机构号”这两个语句,则会得到图6.63。这将表明,如果前两个语句的含义与原始含义相近(分别为向量3.32和4.00的差异),那么尽管词组看似相同,但显然第三个语句甚至具有不同的业务本质。 ...
您可以走得更远,并尝试通过向量化来量化含义上的评论的接近度。为此,我建议使用向量彼此之间的投影。然后找到比较风的长投影与与之比较的风的长度之间的比率。该比率将始终小于或等于1。因此,如果语句彼此相同,则投影将与进行投影的向量合并。被比较的陈述含义越深,则预测将越少。如果将其乘以100%,则可以百分比得出向量化语句的对应程度。因此,向量的投影 比较陈述 在原始陈述的向量上 将通过以下公式找到:
因此,遵守程度 将使用以下公式计算:

图3. 投影图 向量 每个向量 ...
提议将这个参数用作确定语义对应的基础。
该算法在Python中的实现。关于杏子的一些知识。如何设置和处理向量
我将算法命名为Jerdella。没什么奇怪的,我来自顿河畔罗斯托夫。
. , --, , , . , , -, -, -, “”. , .
, , Python , . , . , NumPy. , , NumPy? , – , , - « », . , NumPy. — . , , PIP... 因此,我们的Jerdella将使用PyCharm Community Edition中包含的用于Python 3解释器的标准软件包。
因此,关于Python的好处是它具有实现多种数据结构的能力。为什么我们对记录矢量的列表不满意?您需要在int类型的元素列表中定义字母空间中的向量,并对其进行进一步的操作。
我们已经编写了一些基本程序,下面将简要介绍它们。
如何设置向量?
我使用以下向量过程设置向量:
def vector(self,a):
vector=[]
abc = ["", '', "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "",
"", "", "", "", "", "", "", "", "", "", "", "", ""]
for char in abc:
count=a.count(char)
vector.append(count)
return(vector)也就是说,在先前准备好的列表abc的元素的for循环中,我使用了标准操作来查找计数字符串的附件。之后,使用append方法,我填写了一个新的向量列表,它将用作进一步计算的向量。
如何计算向量差?
为此,我创建了一个增量过程,该过程将两个列表作为输入a和b。
def delta(self, a, b):
delta = []
for char1, char2 in zip(a, b):
d = char1 - char2
delta.append(d)
return (delta)在for循环中,通过遍历两个列表,对差异进行计数,并在每个迭代步骤中将其添加到增量列表的末尾,该过程最终以向量的形式返回。
您如何计算向量的长度,从而估算出差异?
为此,我创建了一个过程len_delta,该过程将一个列表作为输入,并根据查找向量模块的规则遍历该列表的每个元素(它也是字母空间中的坐标),从而计算向量的长度。
def len_delta(self, a):
len = 0
for d in a:
len += d * d
return round(math.sqrt(len), 2)如何计算投影到矢量上的比率,从而估计重合百分比?
为此,创建了一个简化过程,该过程将两个列表作为输入。在其中,我实现了公式(6)。在这里重要的一点是确定哪个向量的长度最大。为了使一致性评估更加清晰,将较小的向量投影到较大的向量上更为方便。
def simplify(self, a, b):
len1 = 0
len2 = 0
scalar = 0
for x in a: len1 += x * x
for y in b: len2 += y * y
for x, y in zip(a, b): scalar += x * y
if len1 > len2:
return (scalar / len1) * 100
else:
return (scalar / len2) * 100讨论获得的结果。我们通过构造语义空间来征服它
, , Jerdella . : 1) , , . 2) -. , CRM Siebel ESB, -. , , , -. , , . … . , , , …
… 2 , Agile, , point-to-point, , .
. , , . 2-3 , , . , , , : « » « », « », « », « », , . , 3000 , 500 ? – ? . , - 3000 ?
. «» , . . Python . «». “” , . « ». , , , – .
, :
{“个人帐号”:[{4.69:“客户的银行帐户””,{6.0:“姓氏”},{4.8:“金属帐号”},{4.8:“客户号码”}]}。
该图也可以图形形式显示。您可以在Python中使用字典做很多事情。为了使结果可视化和演示,我们使用了开放的Internet项目www.graphonline.ru。该平台使您可以快速构建使用GraphML编写的图形。

图4. 实体“个人编号”关系图。实体中“语义对应轨道”的存在的说明。
«» , (3) , , «» , . « » « ». , . , , , . .
? , « » «-». ( ( 3) (5)), . , « » . , « ».
, , , . . .

5. , .
, . … , , . , – ? ? ? — . 80%, , . , . , … - – . , .
, , , , . , , «» ( 6), . «», «», «», - -. , 30% . . , . , , , .

6. «» . , .
. .
«-» . , , - . ? , -.
. - . , . : « - ». , , . « » . , , , . – « ! - »…
, , - , , « », « » « », « », « ». , « ». , . ? ? « »?
, , , , , . – .
, :
[1] . . : . . 2010.
[2]. , . , . . Python. . – . , 2019, — 368 .
P.S. Accenture — ,