根据普遍的看法,从PDF中提取文本应该没有那么困难。毕竟,这里的文字,就摆在我们眼前,人们不断地,并取得了巨大的成功,就意识到了PDF的内容。自动文本提取的困难从何而来?
事实证明,就像由于多种情况和不正确的假设而使人的名字难以使用算法一样,由于PDF格式的极高灵活性,使用PDF也很困难。
主要问题是PDF并非旨在用作数据输入的格式-它是作为输出通道开发的,可以对最终文档的外观进行微调。
基本上,PDF格式由一系列说明如何在页面上创建图像的指令流组成。特别是,文本数据不是存储为段落-甚至是单词-而是存储在页面上特定位置绘制的字符。结果,将文本或Word文档转换为PDF时,大多数内容的语义都丢失了。文本的整个内部结构变成了漂浮在页面上的无定形字符集。
通过填充FilingDB,我们从成千上万的PDF文档中提取了文本数据。在此过程中,我们观察到所有关于PDF文件结构的假设都被证明是错误的。我们的任务特别困难,因为我们必须处理来自不同来源的PDF文件,这些文件的样式,字体和外观完全不同。
以下内容描述了PDF文件的哪些功能使得很难甚至无法从其中提取文本。
PDF阅读保护
您可能遇到过禁止从其中复制文本内容的PDF文件。例如,这是SumatraPDF程序在尝试从受复制保护的文档中复制文本时产生的结果:

有趣的是,该文本是可见的,但是查看器拒绝将所选文本传输到剪贴板。
这可以通过几个“访问权限”标志来实现,其中一个标志控制复制权限。重要的是要理解PDF文件本身不会强制这样做-它的内容不会因此而改变,并且其实现任务完全由查看者承担。
自然,这并不能真正防止从PDF中提取文本,因为任何足够高级的用于处理PDF的库都将允许用户更改这些标志或忽略它们。
页面外的字符
通常,PDF包含的文本数据比页面上显示的要多。摘自雀巢《 2010年年度报告》。
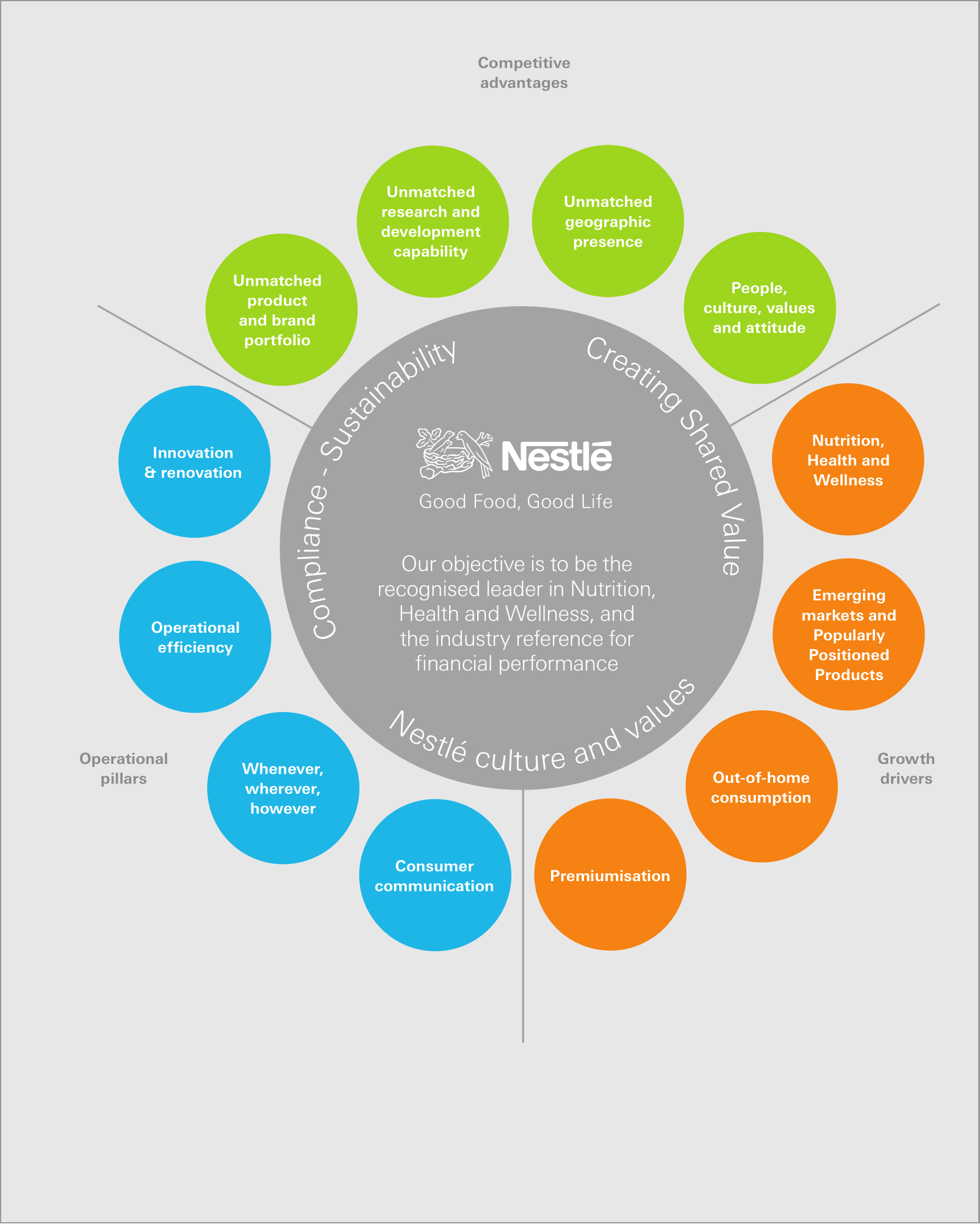
此页面上附加的文本多于可见的文本。特别是,可以在与之关联的内容中找到以下内容:
KitKat于2010年庆祝其75岁生日,但仍然保持年轻时尚,拥有超过250万Facebook粉丝。其产品销往70多个国家,并且在发达国家和中东,印度和俄罗斯等新兴市场的销售增长良好。日本是该公司的第二大市场。
该文本不在页面上,因此大多数PDF查看器都不会显示。但是,数据在那里并且可以以编程方式检索。
有时是由于在批准过程中最后一刻决定替换或删除文本而发生的。
小或看不见的字符
有时,在PDF页面上可以找到很小甚至不可见的字符。例如,这是2012雀巢报告中的页面。

该页面在白色背景上带有白色小文字,上面写着:
惠氏营养徽标标识市场指导
Vevey Octobre 2012 RCC / CI&D
有时这样做是为了提高可访问性,其目的与HTML中的alt标签相同。
太多空间
有时,PDF中的单词字母之间会插入其他空格。这样做可能是为了字距调整(更改字符之间的间距)。
例如,2013年Hikma Pharma报告包含以下文本:

如果将其复制,我们将获得:
ch a i r m a n ' s s tat em en t通常,很难解决原始文本的重构问题。我们最成功的方法是使用光学字符识别OCR。
空间不足
有时,PDF缺少空格或已被替换为其他字符。
示例1:以下摘录摘自SEB 2017年年度报告。

摘录文本:
Tenyearsafterthefinancialcrisisstarted示例2:Eurobank 2013报告包含以下内容:

提取的文本:
On_April_7,_2013,_the_competent_authorities同样,OCR是这些页面的最佳选择。
内置字体
PDF的字体处理起来很复杂,但要适度。要了解文本数据如何存储在PDF中,我们首先需要了解字形,字形名称和字体。
- 字形是描述如何绘制字符或字母的一组指令。
- – , . , « » ™ «» «».
- – . , , , «», .
在PDF中,字符存储为数字,字符代码[codepoints]。要了解需要在屏幕上显示的内容,渲染器必须遵循从字符代码到字形名称,再到字形本身的链。
例如,PDF可能包含一个字符代码116,它映射到字形“ t”的名称,该字形又映射到描述如何显示字符“ t”的字形。
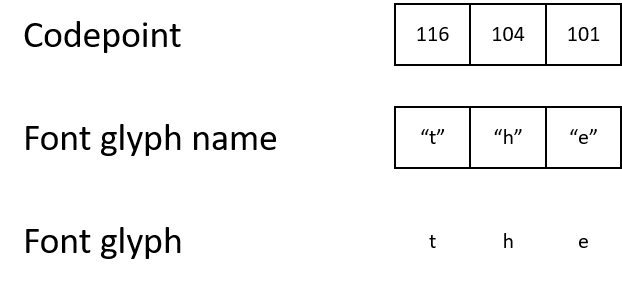
大多数PDF使用标准字符编码。字符编码是一组为字符代码本身分配含义的规则。例如:
- ASCII和Unicode使用字符代码116表示字母“ t”。
- Unicode将字符代码9786映射到显示为☺的字形“白色笑脸”,但是ASCII并未定义这样的代码。
但是,PDF文档有时会使用其自己的字符编码和特殊字体。听起来可能有些奇怪,但文档中可能会使用字符代码1表示字母“ t”。它将字符代码1映射到字形名称“ c1”,字形名称将“ c1”映射到描述如何显示字母“ t”的字形。
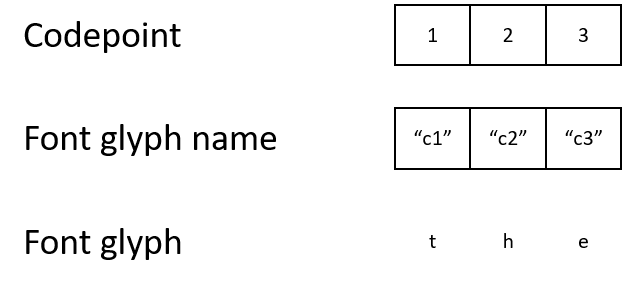
虽然最终结果与人类没有什么不同,但是机器会被这些字符代码弄糊涂。如果字符代码与标准编码不匹配,则几乎不可能以编程方式理解1、2或3号编码的含义,
为什么PDF会包含非标准字体和编码?
- 原因之一是使提取文本更加困难。
- – . , PDF . PDF , .
解决此问题的一种方法是从文档中提取字体字形,通过OCR运行它们,然后将字体映射到Unicode。这样,您就可以将与字体相关的编码转换为Unicode,例如:字符代码1对应于名称“ c1”,根据字形,该名称应表示“ t”,对应于Unicode代码116
。完成-与数字1和116匹配的数字-在PDF标准中称为ToUnicode卡。PDF文档可以包含自己的ToUnicode卡,但这不是必需的。
单词和段落的识别
从PDF的无定形符号汤中重构段落甚至单词是一项艰巨的任务。
PDF文档包含页面上的字符列表,并且消费者可以识别单词和段落。人类自然是有效的,因为阅读是一项常见技能。
最常用的分组算法是比较字符的大小,位置和对齐方式,以确定什么是单词或段落。
这种算法的最简单实现很容易达到O(n²)复杂度,这可能需要很长时间才能处理密集打包的页面。
文字和段落的顺序
由于两个原因,识别文本和段落顺序具有挑战性。
首先,有时根本没有正确的答案。虽然带有一列规则印刷的文档具有自然的阅读顺序,但是元素的排列较粗的文档更难确定。例如,下一个插入片段是否应该在其所在的文章的之前,之后或中间尚不完全清楚:

第二,即使答案很明确,计算机也很难确定段落的确切顺序-即使使用AI。您可能会发现此语句有点大胆,但是在某些情况下,只有通过理解文本的内容才能确定正确的段落顺序。
考虑在两列中这种成分的排列方式,它们描述了蔬菜沙拉的制备。

在西方世界,可以合理地假设阅读是从左到右,从上到下。因此,无需研究文本的内容,我们就可以将所有选项都减少为两个选项:ABCD和ACB D.
在研究了内容,了解其内容之后以及知道蔬菜在切片前已经洗净之后,我们可以理解正确的顺序将是ACB D.在算法上很难确定这一点。
在这种情况下,“在大多数情况下”有效的方法依赖于文本在PDF文档中存储的顺序。通常遵循创建时插入文本的顺序。当大块文本包含许多段落时,它们通常遵循作者预期的顺序。
嵌入式图片
通常,文档内容的一部分(或整个文档)是扫描图像。在这种情况下,其中没有文本数据,因此您必须求助于OCR。
例如,“ 2011年年度报告”仅作为扫描提供:

为什么不仅仅识别一切?
尽管OCR可以帮助解决上述某些问题,但也有其缺点。
- 处理时间长。从PDF扫描运行OCR通常比直接从PDF提取文本要花费一个数量级(甚至更长)的时间。
- 具有非标准字符和字形的困难。OCR算法很难使用新字符-表情符号,星号,圆圈,正方形(在列表中),上标,复杂的数学符号等。
- . , PDF-, , . .
到目前为止,我们还没有提到确认文本是否正确提取或按预期提取是多么困难。我们发现最好运行一组广泛的测试,以研究基本指标(文本长度,页面长度,单词与空格的比率)和更复杂的测试(英语单词的百分比,无法识别的单词的百分比,数字的百分比)以及监控警告,例如可疑或意外字符。
我们建议从PDF提取文本有哪些建议?首先,请确保文本没有更方便的来源。
如果您感兴趣的数据仅是PDF格式,那么很重要的一点是要理解,这个问题乍一看似乎很简单,并且可能无法100%地解决。