我们继续在俄罗斯农业银行金融技术开发中心的站点上发表有关内容审核的一系列文章。在上一篇文章中,我们讨论了如何解决农民“自有耕作”生态系统站点之一的文本审核问题。您可以阅读有关网站本身的一些信息以及我们在这里得到的结果。
简而言之,我们使用了一个幼稚的分类器(按字典过滤)和BERT的集合。通过字典过滤器的文本被允许输入BERT,并在此处进行检查。
而且,我们与MIPT实验室一起,继续改善我们的网站,使自己面临更加艰巨的图形信息预审核任务。事实证明,此任务比上一个任务更加困难,因为在处理自然语言时,无需使用神经网络模型就可以完成任务。使用图像,一切都变得更加复杂-大多数任务是使用神经网络及其正确架构的选择来解决的。但是在我们看来,完成这项任务后,我们已经做好了应对!我们从中得到的是,继续读下去。

我们想要什么?
所以走吧!让我们立即定义什么是图像审核工具。类似于文本审核工具,这应该是一种“黑匣子”。通过将商品卖方上传的图像提交到站点作为输入,我们希望了解如何接受该图像在站点上发布。因此,我们得到了任务:确定图像是否适合在网站上发布。
图像预审核的任务很常见,但解决方案通常因站点而异。因此,医学论坛可以接受内部器官的图像,但不适用于社交媒体。或者,例如,在出售动物尸体的网站上可以接受割下的动物尸体的图像,但上网观看Smesharikov的孩子不太可能喜欢它们。对于我们的网站,可以接受农产品(蔬菜/水果,动物饲料,肥料等)的图像。另一方面,很明显,我们市场的主题并不意味着存在具有各种淫秽或令人反感内容的图像。
首先,我们决定熟悉该问题的已知解决方案,并尝试使其适应我们的站点。通常,减少图形内容审核的许多任务以解决NSFW类的问题,对此有一个公开可用的数据集。
为了解决NSFW问题,通常使用基于ResNet的分类器,这些分类器的质量准确度> 93%。
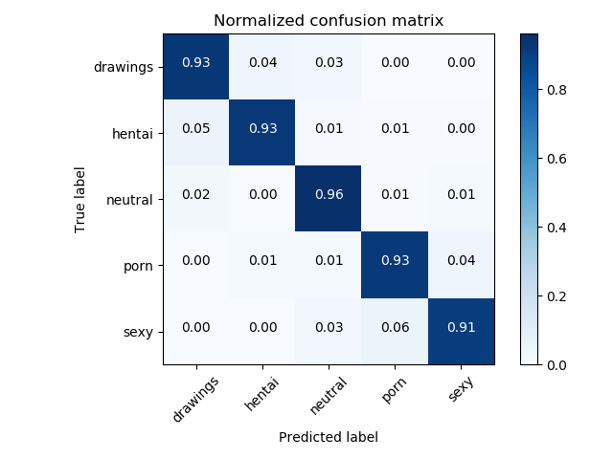
原始NSFW分类器的误差矩阵
好的,假设我们有一个不错的模型和一个现成的NSFW数据集,但是这足以确定站点图像的可接受性吗?事实并非如此。在与网站所有者讨论了NSFW模型的初始方法后,我们意识到有必要定义更多类别,即:
- ( , )
- ( , , , . )
- ( )
也就是说,我们仍然必须组成自己的数据集,并考虑其他哪些模型可能有用。
这是我们遇到的一个常见的机器学习问题:数据不足。这是因为我们的网站是在不久前创建的,并且没有负面示例,也就是标记为不可接受。为了解决这个问题,快速学习方法对我们有所帮助。这种方法的本质是,例如,我们可以在组装的小型数据集上对ResNet进行再训练,其准确性要比仅从头开始并仅使用小型数据集进行分类的情况高。
你是怎么做到的?
下面是我们解决方案的一般方案,如果输入的图像是苹果图像,则从输入图像开始,以检测各种类别的结果结束。

解决方案的一般方案
让我们更详细地考虑方案的每个部分。
阶段1:涂鸦检测器
我们希望包装上带有文本的商品将被加载到我们的网站上,因此,出现了检测铭文和识别其含义的任务。
在第一阶段,我们使用OpenCV文本检测库在包装上查找标签。
OpenCV文本检测是用于Python的光学字符识别(OCR)工具。也就是说,它识别并“读取”图像中嵌入的文本。

EAST检测器操作示例
您可以在照片中看到检测题字的示例。为了识别边界框,我们使用了EAST模型,但是在这里读者可能会感到有些难受,因为该模型经过训练可以识别英文文本,并且在我们的图像上这些文本是俄语的。这就是为什么还要使用基于ResNet的二进制分类模型(涂鸦/非涂鸦)的原因,该模型已针对我们的数据进行了训练,以达到要求的质量。我们选择了ResNet-18,因为事实证明该模型是选择架构时最好的模型。
在我们的任务中,我们想区分一张图片,上面的铭文是涂鸦上商品包装上的铭文。因此,我们决定将所有带文字的照片分为两类:涂鸦和非涂鸦
。在预延迟样本中获得的模型精度为95%:
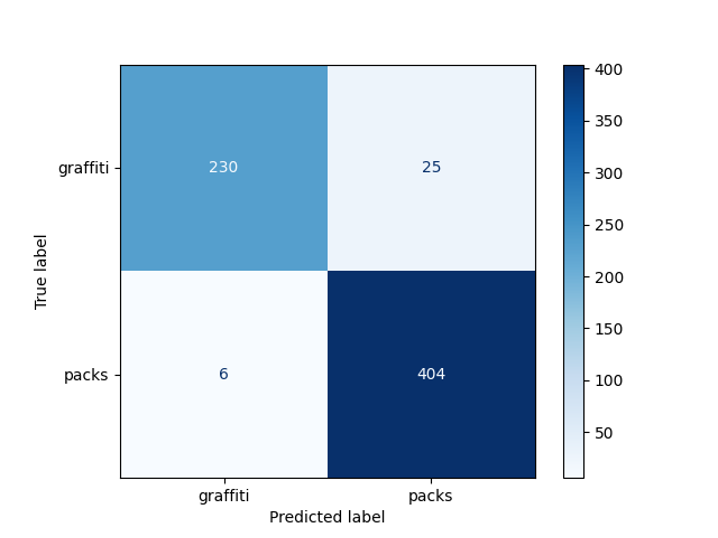
涂鸦检测器错误矩阵
不错!现在,我们可以隔离照片中的文本,并且很有可能了解它是否适合发布。但是,如果照片中没有文字怎么办?
阶段2:NSFW检测器
如果我们在图片中找不到文字,这并不意味着它是不可接受的,因此,我们还要评估图片上的内容如何与网站主题相对应。
在此阶段,任务是将图像分配给以下类别之一:
- 毒品
- 色情(色情)
- 动物
- 可能导致拒绝的照片(包括图纸)(gore / drawing_gore)
- 无尽的(无尽的)
- 中性图片(中性)
重要的是,模型不仅要返回类别,而且还要返回算法对其的置信度。
基于NSFW的模型用于分类。她的培训方式是将照片分为7个班级,我们只希望其中一个能在现场看到。因此,我们只留下中性的照片。
这种模型的结果是97%(就准确度而言)

NSFW检测器误差矩阵
阶段3:人物检测器
但是,即使我们已经学会了如何过滤NSFW,仍然不能认为该问题已解决。例如,某人的照片既不属于NSFW类别也不属于带文字的照片类别,但我们也不希望在网站上看到此类图像。然后,我们在我们的架构中添加了人类检测模型-单发检测器(以下简称SSD)。
选择人员或其他一些先前已知的对象也是广泛应用中的热门任务。我们使用了pytorch提供的现成的nvidia_ssd模型。

SSD算法的示例
该模型的结果较低(准确性-96%):

人为检测器误差矩阵
结果
我们使用加权F1,精度,召回率指标评估了仪器的质量。结果显示在下表中:
| 指标 | 获得的精度 |
| 加权F1 | 0.96 |
| 加权精度 | 0.96 |
| 加权召回 | 0.96 |
这里是其工作的更多说明性示例:
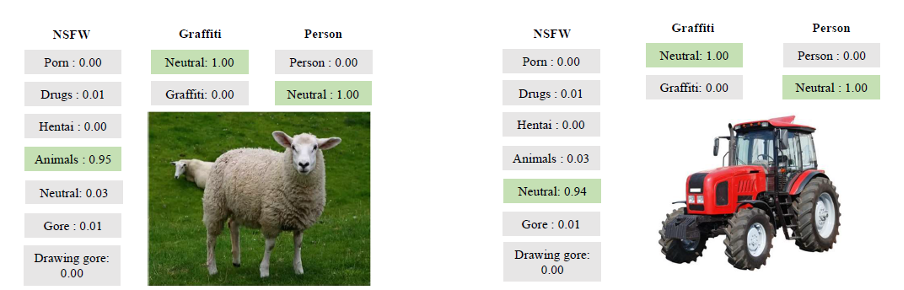
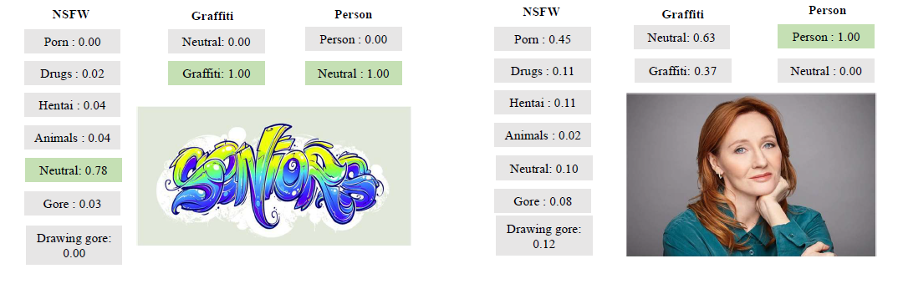
该工具的示例
结论
在求解过程中,我们使用了通常用于计算机视觉任务的完整“模型”模型。我们学会了“读取”照片中的文字,寻找人并区分不适当的内容。
最后,我想指出的是,从获得经验和使用改进的经典模型的角度来看,所考虑的问题很有用。以下是我们获得的一些见解:
- 您可以使用几次学习方法来解决数据短缺问题:大型模型可以根据自己的数据训练到所需的精度
- : ,
- , ,
- , , . , , ,
- 尽管图像审核的任务非常普遍,但其解决方案(如文本)在每个站点可能有所不同,因为它们每个都是针对不同的受众而设计的。例如,在我们的案例中,除了内容不当之外,我们还发现了动物和人
感谢您的关注,并在下一篇文章中见!