今天,我们与MIPT神经网络实验室负责人Mikhail Burtsev进行了物理和技术对话。他的研究兴趣包括神经网络学习模型,神经认知和神经混合系统,自适应系统和进化算法的演化,神经控制器和机器人技术。所有这些都将被讨论。

-Phystech的神经网络和深度学习实验室的历史是如何开始的?
-在2015年,我参加了战略计划署(ASI)的一项名为“远见舰队”的计划-这是国家技术计划下讨论的多日平台。关键主题是需要开发的技术,以便公司在俄罗斯出现并具有在全球市场上占据领先地位的潜力。主要信息是,进入已形成的市场极其困难,但是技术开辟了新领域和新市场,而正是我们需要进入它们。
因此,我们沿着伏尔加河航行,并讨论了哪些技术可以帮助建立此类市场并打破当前的技术障碍。在关于未来的讨论中,与个人助手的话题已经增长。显然,我们已经开始使用它们-Alexa,Alice,Siri ...,很明显,在人与计算机之间的理解上存在技术障碍。另一方面,例如在强化学习领域,自然语言处理领域,已经积累了许多研究进展。很明显:借助神经网络,许多困难的任务正在得到越来越好的解决。
我只是在研究神经网络算法。根据前瞻性舰队讨论的结果,我们制定了不久的将来的技术开发项目的概念,该概念后来被转换为iPavlov项目。这是我与Phystech互动的开始。
更详细地说,我们制定了三个任务。基础架构-创建一个开放库以与用户进行对话。二是开展自然语言处理研究。加上特定业务问题的解决方案。
Sberbank是合作伙伴,该项目本身是在国家技术计划的支持下成立的。
, 2015 -: deephack.me — , , - , . Open Data Science.
在2018年初,我们发布了我们的开放库DeepPavlov的第一个存储库,并且在过去两年中,我们看到其用户稳步增长(侧重于俄语和英语):我们大约有50%的安装来自美国,有20-30%的安装来自俄罗斯。总的来说,它是一个相当成功的开源项目。
我们不仅在开发而且还在努力为对话式AI的全球研究议程做出贡献。意识到这一领域学术竞争的必要性,我们推出了对话式AI挑战赛系列,作为领先的机器学习会议NeuIPS的一部分。
此外,我们不仅组织比赛,还参加比赛。因此,去年我们实验室的团队参加了来自亚马逊的一项名为Alexa Prize的竞赛-创造了一个聊天机器人,人们可以与它聊天20分钟。
下一届比赛将于11月开始。
这是一次大学比赛,参与者的核心是学生和大学职员。总共有350支队伍,根据去年的结果选出了7支,并邀请了3支-我们已经晋升到了最高。
我们的对话系统与美国用户进行了大约10万次对话,最终获得了5分(约3.35-3.4)的评分,相当不错。这表明我们在很短的时间内就在MIPT上组建了世界一流的团队。
现在,该实验室正在与多家公司合作开展项目,包括华为和Sberbank。不同方向的项目:AutoML,神经网络理论,当然还有我们的主要方向-NLP。
-关于过去机器学习难以完成的任务:为什么深度学习在解决这些问题上大放异彩?
-很难说。我现在将以稍微简化的方式描述我的直觉。关键是,如果模型具有很多参数,那么令人惊讶的是,它可以很好地将结果概括为新数据。从某种意义上说,参数的数量可以与示例的数量相称。出于同样的原因,经典的ML长期以来一直抵抗神经网络的压力-在这种情况下,似乎没有什么好用的。
深度学习模型中参数的增加(来源)
令人惊讶的是,事实并非如此。我们实验室的Ivan Skorokhodov显示(.pdf),几乎可以在神经网络损失函数的空间中找到任何二维模式。
您可以选择一个平面,使该平面上的每个点都对应于一组神经网络参数。而且它们的损失将对应于任意模式,因此,您可以选择这样的神经网络,使它们直接落在这张照片上。
一个非常有趣的结果。这表明,即使有如此荒谬的限制,神经网络仍可以学习分配给它的任务。这就是这里的直觉。

Ivan Skorokhodov文章中的模式示例
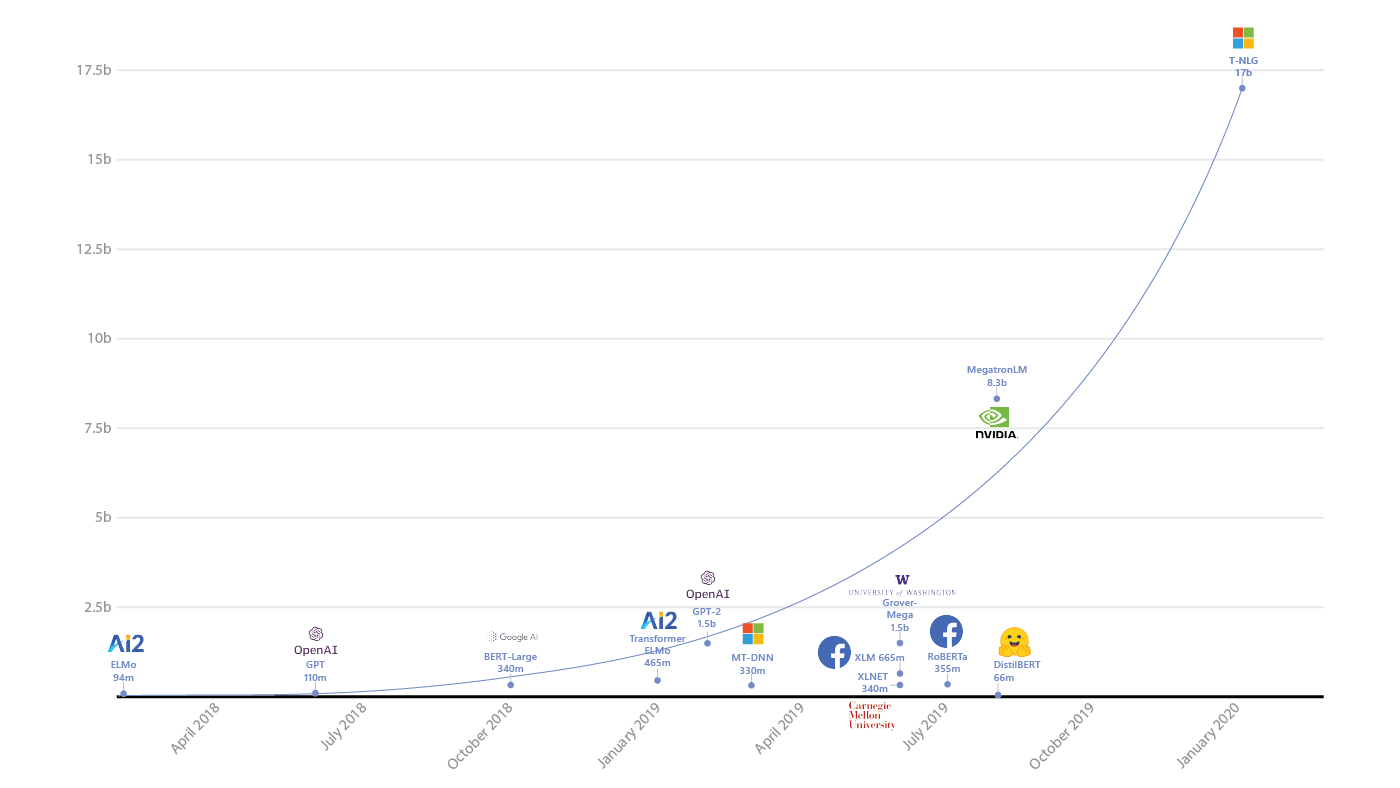
-近年来,深度学习领域取得了显着进步,但是在我们将自己埋入指标极限的视野是否已经可见?

人工智能模型的规模及其消耗的资源的增长(来源:openai.com/blog/ai-and-compute/)
-在我们的自然语言处理中,虽然似乎在增强学习中似乎已经开始了一些事情,但尚未达到极限滑。也就是说,过去几年没有质的变化。从Atari到AlphaGo,以及与Monte Carlo Tree Search的杂交都取得了巨大的发展,但是现在没有直接的突破。
但是在NLP中则相反:递归网络,卷积网络,最后是转换器架构和GPT本身(一种最新,最有趣的转换器模型之一,通常用于生成文本-作者的注释)已经是一个纯粹的广泛发展。在这里,似乎还有一些余地可以实现新的目标。因此,在NLP中,上方的条仍然不可见。当然,尽管几乎不可能在这里进行任何预测。
-如果我们想象机器学习的语言和框架的发展,那么我们就从(有条件地)以纯粹的numpy,scikit-learn编写到tensorflow,keras-抽象水平不断提高。我们接下来要做什么?
— , : - . , , low level high level code: numpy . , , NLP : .
- Tensorflow / Pytorch — : .
- : NLP- — DeepPavlov.
- : — DeepPavlov Dream .
- 一个在技能/管道之间切换的系统,包括我们的DeepPavlov代理。
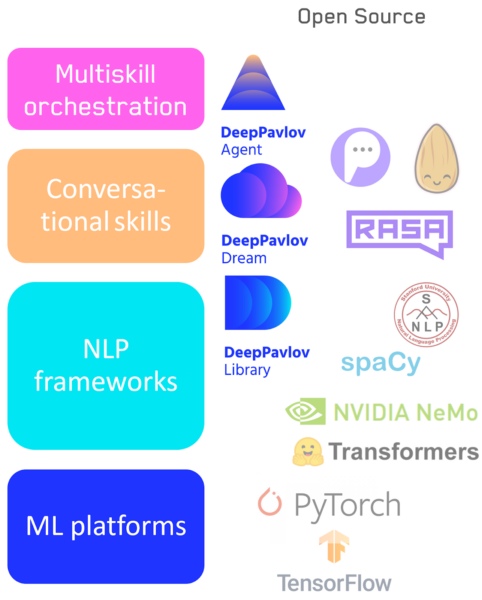
会话式AI技术堆栈
不同的应用程序和任务需要不同的工具灵活性,因此,我认为该层次结构中的任何元素都不会消失。底层和高层系统都将在需要时发展。例如,对于程序员而言不可用的可视库,对开发人员而言低级的库将无处不在。
-现在是否正在以类似于经典图灵测试的方式进行社会实验,人们必须了解神经网络是在他们面前还是在人面前?
-定期进行此类实验。在Alexa挑战赛中,一个人必须评估对话的质量,而他却不知道自己在跟谁说话-机器人还是一个人。到目前为止,从实时对话的角度来看,机器和人之间的差异是巨大的,但是每年都在减少。顺便说一句,关于这一点的 文章刚刚发表在AI Magazine上。
在科学界之外,这是定期进行的。最近,有人训练了GPT模型,为她建立了一个Twitter帐户,并开始发布回复。很多人报名参加,该帐户获得了普及,而且没人知道这是一个神经网络。
这样的简短格式(例如在Twitter上)是通用且“深刻”的公式,非常适合神经网络推理系统。
-您认为最有希望的领域是什么?
-(笑)我可以说,这是我所有喜欢的方向的统一。我将尝试在问题化框架内更详细地描述。我们有基于电流互感器的GPT模型-它们在生活中没有目的,它们只是生成类似于人类的文字,完全没有目标。他们不能将它与世界本身的情况和目标联系在一起。
其中一种方法是将世界的逻辑视图绑定到GPT,GPT已经阅读了很多文本,并且其中确实已经存在许多逻辑联系。例如,通过与Wikidata的杂交(这是描述有关世界的知识的图表,其顶部是Wikipedia文章)。
如果我们可以将两者联系在一起,以便GPT可以使用知识库,那将是一个飞跃。
NLP模型的无目标性问题的第二种方法是基于将人类目标的理解整合到其中。如果我们有一个模型可以驱动与知识图相关的生成式语言模型,那么我们可以训练它来帮助一个人实现他们的目标。这样的助手必须通过NLP了解人员,人员的目标和情况-然后他需要计划行动。在计划中,强化学习效果最好。
如何结合和优化所有这些是一个悬而未决的问题。
最后一个是寻找神经网络架构。例如,当使用进化方法时,我们正在寻找对给定任务而言最佳的体系结构空间。但是,今天还不能决定所有这一切-搜索空间太大。
好消息是:硬件发展非常迅速,也许这将使我们在5到10年内将神经网络语言模型,知识图和强化学习结合起来。然后,我们将在机器对人的理解上有了巨大的飞跃。
在这样的助手的帮助下,将有可能启动其他任务的解决方案:图像分析,病历或经济状况分析,商品选择。
因此,我要说的是,从科学的角度来看,在未来五年中,我们将看到杂交领域的飞速发展-任务很多。
伙计们,人员短缺将是巨大的,有很大的机会获得新的有趣的结果,并影响行业的发展。建立联系-您必须抓住时机!(作者积极支持此答案,因为他只处理此类系统。)
-如何开始深入学习?
-在我看来,最简单的方法是在深度学习学校上课:最初是为高中生设计的,但它非常适合学生。总的来说,这是一项了不起的工作,我帮助安排了工作并在那里进行了入门讲座。
我还建议您观看大学的入门课程,完成任务-Internet上有很多东西。所有“播放”工具中最好的是Google的Colab,有数百万个任务示例,您可以弄清楚并运行最现代的解决方案-根本无需在计算机上安装任何软件。
另一种方法是在Kaggle上竞争。并加入开放数据科学-俄语为俄语的数据科学社区,那里有几个深度学习渠道。那里总是有人愿意提供建议和代码。
这些是主要方法。
Leader-ID:朋友们,对于现在推出的用于促进AI项目的加速器的选择,我们已经考虑了进入独立开发者的选项。不,这不会改变仅团队参加强化训练的基本条件。但是我们有很多问题,这些人现在还没有自己的项目,但想参与(这些不仅是程序员,而且设计师对AI项目也很感兴趣)。我们找到了一个解决方案:我们将通过免费的在线黑客马拉松帮助聚集一支团队和志趣相投的人。该活动将于10月10日12:00开始,并将恰好在一天后结束。在该机器人上,机器人会将您分配到团队中,然后在他的指导下,您将经历项目开发的主要阶段,并将其提交给Archipelago 20.35。所有详细信息都在您的个人帐户中,您只需要及时注册。