
要创建语音助手,您不需要在编程方面有很多知识,主要是要了解其应具有的功能。为了方便,优化工作流程和最佳呼叫分类,许多公司都在与客户进行第一线通信时创建了它们。本文介绍了一个程序,该程序可以成为您自己的聊天机器人的基础,或更准确地说,可以成为语音识别和后续命令执行的语音助手的基础。有了它的帮助,我们将能够了解最常用的语音助手的工作方式。
首先,让我们声明所需的库:
import speech_recognition as sr
import os
import sys
import webbrowser
import pyttsx3 as p
from datetime import datetime
import time
import datetime
import random另外,别忘了保留一个日志文件,如果我们仍然决定改进该机器人以使用神经网络,则需要它。许多公司在其语音助手中使用神经网络来理解和响应客户的情绪。
另外,不要忘记通过分析日志,我们将能够了解bot算法的弱点并改善与客户的互动。
#
chat_log = [['SESSION_ID', 'DATE', 'AUTHOR', 'TEXT', 'AUDIO_NUM']]
#
i = 1
exit = 0
while exit == 0:
session_id = str(i)
if session_id not in os.listdir():
os.mkdir(session_id)
exit = 1
else:
i = i + 1
# bot
author = 'Bot'
text = '! ?'在日志文件中,我们写出消息的时间,作者(机器人或用户)和实际文本本身。
#
def log_me(author, text, audio):
now = datetime.datetime.now()
i = 1
exit = 0
while exit == 0:
audio_num = str(i)+'.wav'
if audio_num not in os.listdir(session_id):
exit = 1
else:
i = i + 1
os.chdir(session_id)
with open(audio_num , "wb") as file:
file.write(audio.get_wav_data())
chat_log.append([now.strftime("%Y-%m-%d %H:%M:%S"), author, text, audio_num])我们显示该机器人编写的第一条消息:您好!我怎么帮你?
#
print("Bot: "+ text)
log_me(author, text, audio)通过Jupyter Notebook中的此过程,我们可以通过默认的播放设备说出话语:
# words
def talk(words):
engine.say(words)
engine.runAndWait()上面我们讨论了如何为文本配音,但是如何将声音转换为文本呢?在这里,来自Google的语音识别以及麦克风的一些操作将为我们提供帮助。
#
def command():
rec = sr.Recognizer()
with sr.Microphone() as source:
#
print('Bot: ...')
#
rec.pause_threshold = 1
#
rec.adjust_for_ambient_noise(source, duration=1)
audio = rec.listen(source)
try:
# GOOGLE
text = rec.recognize_google(audio, language="ru-RU").lower()
#
print(': ' + text[0].upper() + text[1:])
log_me('User', text, audio)
#
except sr.UnknownValueError:
text = ' . .'
print('Bot: ' + text)
talk(text)
#
text = command()
log_me('Bot', text, , Null)
return text我们的助手除了听我们还能做什么?一切都受到我们的想象力的限制!让我们看一些有趣的例子。
让我们从一个简单的例子开始,让他使用命令打开站点-他将打开站点(您不期望吗?)。
# ,
def makeSomething(text):
if ' ' in text:
print('Bot: NewTechAudit.')
talk(' NewTechAudit.')
log_me('Bot',' NewTechAudit.', Null)
webbrowser.open('https://newtechaudit.ru/')有时候听别人说是有用的,但要听别人的话。让机器人仍然可以在我们之后重复:
#
elif '' in text or '' in text or '' in text:
print('Bot: ' + text[10].upper() + text[11:])
talk(text[10:])
log_me('Bot', text[10].upper() + text[11:] , Null)让他也作为对话者,但现在我们仅从相识开始:
#
elif ' ' in text or ' ' in text or ' ' in text:
print('Bot: Bot.')
talk(' Bot')
log_me('Bot', ' Bot', Null)我们还可以要求语音助手以我们选择的格式命名一个随机数,其格式为:从(第一个数字)到(第二个数字)命名一个随机数字。
#
elif ' ' in text:
ot=text.find('')
do=text.find('')
f_num=int(text[ot+3:do-1])
l_num=int(text[do+3:])
r=str(random.randint(f_num, l_num))
print('Bot: ' + r)
talk(r)
log_me('Bot', r, Null)为了完成程序,您只需要向机器人说再见:
#
elif '' in text or ' ' in text:
print('Bot: !')
talk(' ')
log_me('Bot', ' ', Null)
os.chdir(session_id)
log_file = open( session_id + ".txt", "w")
for row in chat_log:
np.savetxt(log_file, row)
log_file.close()
sys.exit()为了使它们连续不断地工作,我们创建了一个无限循环。
#
while True:
makeSomething(command())让我们进行一次测试对话:

在创建的会话文件夹中,存储了我们语音的所有音频记录文件和一个文本日志文件:
编写了文本日志文件:
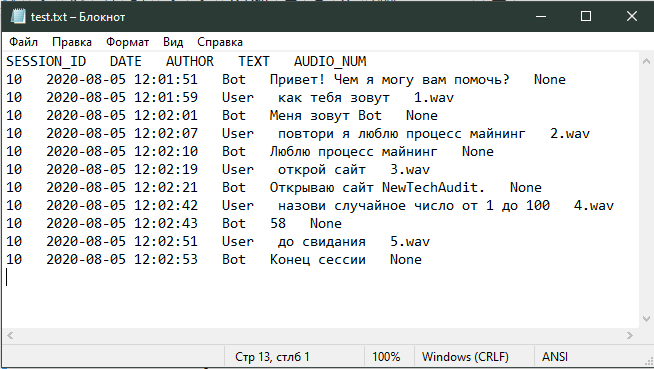
在本文中,我们研究了最简单的语音机器人以及该机器人进一步与神经网络配合使用的主要有用功能。为了分析所提供帮助的质量并进一步进行改进,我们将能够检查日志文件。
该机器人可以成为您自己的Jarvis的基础!