
Amazon SageMaker不仅提供在Jupyter中管理笔记本的功能,还提供可配置的服务,使您可以创建,训练,优化和部署机器学习模型。一个普遍的误解,尤其是在使用SageMaker入门时,是您需要SageMaker Notebook实例或SageMaker(Studio)Notebook才能使用这些服务。实际上,您可以直接从本地计算机甚至您喜欢的IDE运行所有服务。
在继续进行之前,让我们看一下如何与Amazon SageMaker服务进行交互。您有两个API:
SageMaker Python SDK-一种高级Python API,该API抽象化用于构建,训练和部署机器学习模型的代码。特别是,它提供了一流或内置算法的评估器,还支持TensorFlow,MXNET等框架。在大多数情况下,您将使用它与交互式机器学习任务进行交互。
AWS开发工具包是一种低级API,用于与所有受支持的AWS服务进行通信,而不必与SageMaker进行通信。AWS开发工具包可用于大多数流行语言,例如Java,Javascript,Python(boto)等。在大多数情况下,您将使用此API来进行诸如创建自动化资源或与SageMaker Python SDK不支持的其他AWS服务进行交互的操作。
为什么要本地环境?
首先要考虑成本,但是使用本机IDE的灵活性以及脱机工作和准备就绪后在AWS云中运行任务的能力也很重要。
当地环境如何运作
您编写代码来构建模型,但不是在SpyMake Notebook或SageMaker Studio Notebook的实例中而是在Jupyter的本地计算机上或从IDE中进行操作。然后,当一切准备就绪时,您将开始在AWS上进行SageMaker实例的培训。训练后,模型将存储在AWS中。然后,您可以从本地计算机运行部署或批量转换。
用conda搭建环境
建议设置一个Python虚拟环境。在我们的案例中,我们将使用conda来管理虚拟环境,但是您可以使用virtualenv。Amazon SageMaker再次使用conda来管理环境和软件包。假定您已经安装了conda,否则请转到此处。
创建一个新的conda环境
conda create -n sagemaker python=3我们激活并验证环境

安装所需的软件包
要安装软件包,请使用命令
conda或pip。让我们用conda选择选项。
conda install -y pandas numpy matplotlib安装AWS软件包
安装适用于Python的AWS开发工具包(boto),awscli和SageMaker Python开发工具包。SageMaker Python SDK不能作为conda软件包使用,因此我们将在这里使用它
pip。
pip install boto3 awscli sagemaker如果这是您第一次使用awscli,则需要对其进行配置。在这里,您可以看到操作方法。
默认情况下将安装SageMaker Python SDK的第二个版本。确保检查第二个版本的SDK中是否有重大更改。
安装Jupyter并构建核心
conda install -c conda-forge jupyterlab
python -m ipykernel install --user --name sagemaker我们验证环境并检查版本
通过jupyter实验室启动Jupyter,然后选择
sagemaker我们在上面创建的核心。
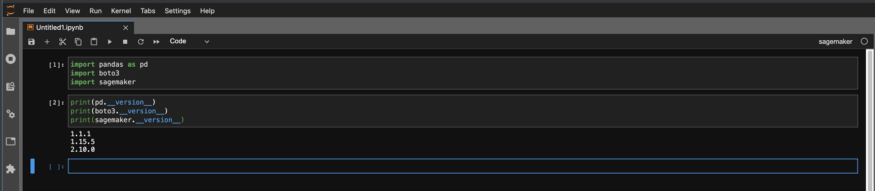
然后检查笔记本中的版本,以确保它们是您想要的版本。
我们创造和训练
现在,您可以开始在本地构建模型,并在准备就绪时开始在AWS上学习。
导入包
导入所需的软件包并指定角色。这里的主要区别是您需要直接指定
arn角色,而不是get_execution_role()。由于您正在使用AWS凭证而不是具有角色的笔记本实例从本地计算机运行所有内容,因此该功能get_execution_role()将无法使用。
from sagemaker import image_uris # Use image_uris instead of get_image_uri
from sagemaker import TrainingInput # Use instead of sagemaker.session.s3_input
region = boto3.Session().region_name
container = image_uris.retrieve('image-classification',region)
bucket= 'your-bucket-name'
prefix = 'output'
SageMakerRole='arn:aws:iam::xxxxxxxxxx:role/service-role/AmazonSageMaker-ExecutionRole-20191208T093742'创建评估师
创建一个评估程序并像往常一样设置超参数。在下面的示例中,我们使用内置的图像分类算法训练图像分类器。您还可以指定Stagemaker实例的类型以及要用于训练的实例数。
s3_output_location = 's3://{}/output'.format(bucket, prefix)
classifier = sagemaker.estimator.Estimator(container,
role=SageMakerRole,
instance_count=1,
instance_type='ml.p2.xlarge',
volume_size = 50,
max_run = 360000,
input_mode= 'File',
output_path=s3_output_location)
classifier.set_hyperparameters(num_layers=152,
use_pretrained_model=0,
image_shape = "3,224,224",
num_classes=2,
mini_batch_size=32,
epochs=30,
learning_rate=0.01,
num_training_samples=963,
precision_dtype='float32')
学习渠道
指定学习方式的方式与以前一样,与在笔记本电脑上进行的方式相比也没有任何变化。
train_data = TrainingInput(s3train, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data = TrainingInput(s3validation, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
train_data_lst = TrainingInput(s3train_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data_lst = TrainingInput(s3validation_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
data_channels = {'train': train_data, 'validation': validation_data,
'train_lst': train_data_lst, 'validation_lst': validation_data_lst}我们开始训练
通过调用fit方法在SageMaker中启动培训任务,该方法将开始在您的SageMaker AWS实例上进行培训。
classifier.fit(inputs=data_channels, logs=True)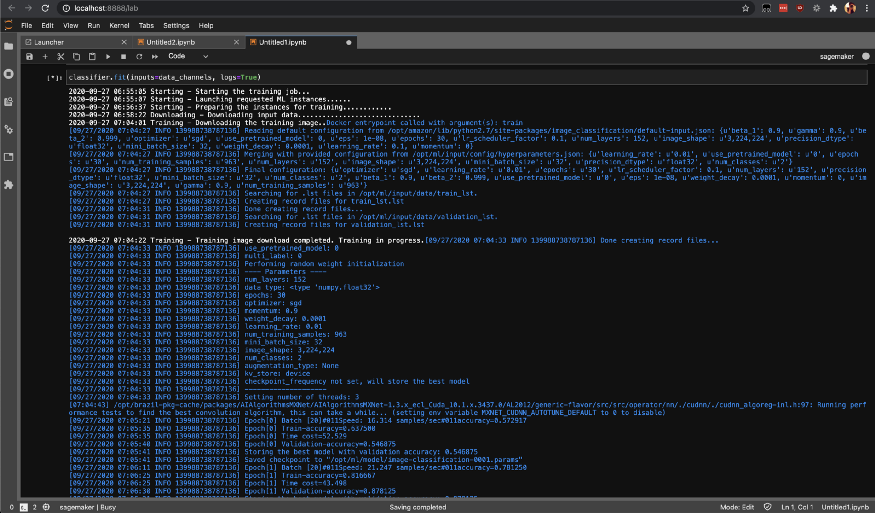
您可以使用list-training-jobs检查培训工作的状态。
就这样。今天,我们想出了如何在本地使用Jupyter在本地计算机上设置SageMaker环境和构建机器学习模型的方法。除了Jupyter,您还可以从自己的IDE中执行相同的操作。
学习愉快!
