当转化次数很多,价格可接受且销售量没有增长甚至下降时,通常会发生这种情况。在此,“每次点击之前的利润”分析不再足以找出原因。然后对“从经理那里获利之前”的分析进行了挽救。因为无论多么理想地设置广告,客户都首先与经理互动,然后才做出决定。企业的成功取决于员工的工作质量。
传统的分析系统使用CRM记录销售事实/与经理联系。但是,这种方法只能部分解决问题:“在底线”评估员工的效率。也就是说,它显示了销售和转换,但与客户的沟通“完全”。但是结果取决于沟通水平。
为了填补空白,我们开发了一种工具,该工具将自动将每个呼叫链接到处理该呼叫的经理。您不必使用CRM和第三方服务。实际上,我们的系统在每个来电中都添加了一个标签“ manager's name”。
因此,销售/客户服务部门的负责人将控制工作质量,发现问题区域并进行分析。这将有助于快速将呼叫细分给那些收到呼叫的经理。
问题的提法
我们为自己设置的任务如下:让系统知道所有可以接听电话的经理的语音模式。然后,对于新呼叫,您需要标记经理,该经理的声音在会话中是已知联系人中最“相似”的。
在这种情况下,可以认为新的电话成功是先验的。就是说,经理和客户之间的对话实际上是在进行。非正式地讲,该任务可以归因于“与老师一起教学”的任务类别,即分类。
作为对象-以某种方式进行矢量化(数字化)录音,其中只有管理者的声音在响。响应是类标签(经理名称)。那么标记算法的任务是:
- 从音频文件中提取有意义的功能
- 选择最合适的分类算法
- 学习算法并保存经理模型
- 评估算法的质量并修改其参数
- 标记(分类)新呼叫
其中一些任务属于单独的子任务。这是由于算法必须在其中运行的条件的具体情况造成的。电话通常很吵。一个对话中的客户可以与多个经理进行沟通。此外,它根本不会发生,并且呼叫通常包括IVR等
。例如,标记新呼叫的任务可以分为:
- 检查通话是否成功(有通话的事实)
- 将立体声拆分为单声道
- 噪音过滤
- 识别带有语音的区域(过滤音乐和其他外来声音)
将来,我们将分别讨论每个此类子任务。同时,我们将制定对输入数据,所得解决方案以及分类算法本身施加的技术约束。
解决方案约束
对限制的需求部分地由实现的复杂性的技术和要求以及算法的通用性和其操作精度之间的平衡所决定。
输入文件和训练样本文件的限制:
- 格式-WAV或Wave(您可以进一步将其编码为mp3)
- 立体声随后必须分为2个音轨-运营商和客户
- 采样率-16,000 Hz及以上
- 位深度-16位及以上
- 训练模型的文件必须至少30秒长,并且仅包含特定经理的声音
- , , ,
除最后一个条件外,上述所有要求都是在设置算法阶段进行的一系列实验的结果。就最小化错误概率(即在简单调整条件下的错误分类)而言,这种组合已显示出最有效的方法。
例如,很明显训练集中的文件越长,分类器将越准确。但是,在呼叫日志(我们的训练样本)中找到这样的文件更加困难。因此,30秒的持续时间是设置的准确性和复杂性之间的折衷。最后一个要求(成功)是必要的。系统不应将管理员标记为实际上没有通话的呼叫。
该算法的局限性导致了以下解决方案:
- , . « ». . - , .
- . , , .
第一个要求来自实验。结果证明,“未知”管理器使解决方案的体系结构复杂化。为此,必须选择阈值,在此之后,员工将被归类为“无法识别”。同样,“未知”管理器将准确性降低了10个百分点。
另外,当已知管理者被分类为未知时,会出现第二种错误。根据已知错误的数量,发生这种错误的可能性为7-10%。可以将此要求称为基本要求。它要求算法调谐器指示培训样本中的所有管理人员。并在那里介绍新员工的模型,并删除离职的员工。
第二个要求来自实际考虑和我们使用的算法的体系结构。简而言之,该算法将分析后的音频拆分为语音片段,并与所有训练有素的经理人一个一个地“比较”每个片段。
结果,“微型标签”被分配给每个微型片段。使用这种方法,很可能会错误地识别某些片段。例如,如果它们保持嘈杂或长度太短。
然后,如果所有“迷你标签”都显示在最终解决方案中,那么除了真实经理的标签外,还将显示很多“垃圾”标签。因此,仅显示最“频繁”的标签。
输入/输出数据说明
我们将输入数据分为两种类型:
用于生成管理者模型的算法输入的数据(用于训练的数据):
- 音频文件+类标签
标记算法输入处的数据(用于测试/正常运行的数据):
- 外部数据(音频文件)
- 内部数据(保存的模型)
输出也分为两种类型:
- 模型生成算法的输出数据
- 训练有素的经理模型
- 标记算法的输出
- 经理标签
在算法输入时,在其任何操作模式下,都会接收满足要求的音频文件。它们在“限制”部分中。
在模型生成算法的输入处,允许多个输入文件对应于一个类(管理器)。但是一个文件不能对应多个管理器。可以将类标签名放在文件名中。或者只是为每个员工创建一个单独的目录。
基于输入数据的模型训练算法会生成许多可以在训练期间加载的模型。它们的数量与音频文件集中不同标签的数量相对应。
因此,如果有M个文件标有n 不同的类别标签,然后在训练阶段的算法会创建n个管理者模型:
- Model_manager_1.pkl
- Model_manager_2.pkl
- ...
- Model_manager_n.pkl
类的名称 代替“ manager _... ”。
标记算法的输入是未标记的音频文件,其中先验地存在经理和客户之间的对话以及n个员工模型。结果,该算法返回一个标记-最“合理”的管理器的类的名称。
数据预处理
音频文件已经过预处理。它是顺序的,并且可以在标记模式和模型训练模式下运行:
- 检查通话是否成功-仅在标记阶段
- 将立体声分为2个单声道轨道,并且仅在操作员的轨道上进一步工作
- 数字化-提取音频信号参数
- 噪音过滤
- 消除“长时间”停顿-用声音识别片段
- 过滤非语音片段-删除音乐,背景等。
- 片段与语音的融合(仅在训练阶段)
我们将不讨论成功检查阶段。这是另一篇文章的主题。简而言之,该阶段的本质是根据呼叫中是否存在“在世人士”对话对呼叫进行分类。“活着的人”是指客户和经理,而不是语音助手,音乐等
。使用具有外部阈值(“在此之后通话被视为成功的最短通话时间”)的经过专门培训的分类器,可以检查通话是否成功。
在第二阶段,立体声文件分为两个轨道:管理器和客户端。仅针对员工的跟踪进行进一步处理。
在数字化阶段,“特征”的参数是从操作员跟踪中提取的,这些参数是信号的数字表示。我们在Calltouch中使用了粉笔倒谱分量。此外,参数是在非常小的片段上提取的,这称为窗口宽度(0.025秒)。所有功能都在同一时间标准化。
nfft=2048 //
appendEnergy = False
def get_MFCC(sr,audio): // , sr=16000 -
features = mfcc.mfcc(audio, sr, 0.025, 0.01, 13, 26, nfft, 0, 1000, appendEnergy)
features = preprocessing.scale(features)
return features
count = 1
features = np.asarray(()) //
for path in file_paths: //
path = path.strip()
sr,audio = read(source + path) //
vector = get_MFCC (sr, audio) #
if features.size == 0:
features = vector
else:
features = np.vstack((features, vector))在输出处,每个音频文件变成一个数组,其中每个0.025秒片段的mel倒谱特性逐行记录。
文件的进一步处理包括过滤噪声,消除长时间的停顿(不是声音之间的停顿)以及搜索语音。这些任务可以使用各种工具来完成。在我们的解决方案中,我们使用了pyaudioanalysis库中的方法:
clear_noise(fname,outname,ch_n) # .- fname-输入文件
- outname-输出文件
- ch_n-通道数
在输出中,我们从文件fname中获取文件outname,其中包含消除了噪音的声音。
silenceRemoval(x, Fs, stWin, stStep) # « »- x-输入数组(数字信号)
- Fs-采样率
- stWin-特征提取窗口的宽度
- stStep-偏移步长
在输出中,我们得到以下形式的数组:
[l_1,r_1]
[l_2,r_2]
[l_3,r_3]
…
[l_N,r_N]
其中l_i是第i个分段的开始时间(秒),r_i是第i个分段的结束时间(秒)。
detect_audio_segment(x,thrs) # .- x-输入数组(数字信号)
- hrs-检测到的语音片段的最小长度(以秒为单位)
在输出中,我们得到那些片段[l_i,r_i],其中包含从thrs秒开始持续的语音。
作为预处理的结果,输入的音频文件将转换为数组的形式:
[l_1,r_1]
[l_2,r_2]
[l_3,r_3]
…
[l_N,r_N],
其中每个片段都是清除的语音文件的时间间隔。
因此,我们可以将每个这样的片段与特征矩阵(小倒谱特性)匹配,这些特征矩阵将用于训练模型和在标记阶段。
使用的方法/算法
如上所述,我们的解决方案基于以Python 2.7编写的pyaudioanalysis.py库。考虑到我们的通用解决方案是在Python 3.7中实现的,因此某些库函数已针对该版本的语言进行了修改和调整。
通常,用于标记管理器的工具的算法可分为两部分:
- 模型经理培训
- 标记
每个部分的详细说明如下。
模型经理培训:
- 加载训练样本
- 数据预处理
- 计算班数
- 为每个类创建一个经理模型
- 保存模型
标记:
- 通话加载
- 检查通话是否成功
- 预处理成功的呼叫
- 加载所有训练有素的经理模型
- 已处理呼叫的每个片段的分类
- 寻找最可能的经理人模型
- 标记
我们已经详细讨论了数据预处理的任务。现在,让我们看一下创建管理器模型的方法。
我们使用GMM(高斯混合模型)算法作为模型。他在假设我们的数据是随机变量的实现的情况下建模,这些变量的分布由高斯混合描述-每个变量都有其自己的方差和自己的数学期望。
众所周知,用于找到这种混合物的最佳参数的最常见算法是EM算法(期望最大化)。他将使多维随机变量的可能性最大化的难题分解为一系列较低维的最大化问题。
经过一系列实验,我们得出了GMM算法的以下参数:
gmm = GMM(n_components = 16, n_iter = 200, covariance_type='diag',n_init = 3)将为每个经理创建这样的模型,然后对其进行训练-将其参数调整为特定数据。
gmm.fit(features)接下来,保存模型以在标记阶段使用:
picklefile = path[path.find('/')+1:path.find('.')]+".gmm"
pickle.dump(gmm,open(dest + picklefile,'wb'))在标记阶段,我们加载以前保存的模型:
gmm_files = [os.path.join(modelpath,fname) for fname in
os.listdir(modelpath) if fname.endswith('.gmm')]modelpath是我们保存模型的目录。
models = [pickle.load(open(fname,'rb'),encoding='latin1') for fname in gmm_files]并加载模型的名称(这些是我们的标签):
speakers = [fname.split("/")[-1].split(".gmm")[0] for fname
in gmm_files]您需要为其标记的上载音频文件已被矢量化和预处理。此外,将每个带有语音的片段与训练有素的模型进行比较,并根据最大似然对数确定获胜者:
log_likelihood = np.zeros(len(models)) #
for i in range(len(models)):
gmm = models[i] #
scores = np.array(gmm.score(vector))
log_likelihood[i] = scores.sum() # i –
winner = np.argmax(log_likelihood) #
print("\tdetected as - ", speakers[winner])结果,我们的算法大致得出以下结论:
起始于:1.92终止于:8.72
[-10400.93604115 -12111.38278205]
检测为-Olga
起始于:9.22终止于:15.72
[-10193.80504138 -11911.11095894]
检测为-Olga
起始于:26.7终止于:29.82
[-4867.97641331 -5506.44233563]
检测为-伊万
开始于:33.34结束于:47.14
[-21143.02629011 -24796.44582627]
检测为-伊凡
开始于:52.56终止于:59.24
[-10916.83282132 -12124.26855 starts538]被
检测为-奥尔加开始
538 in:116.32结束于:134.56
[-36764.94876054 -34810.38959083]被
检测为-Olga
起始于:151.18结束于:154.86
[-8041.33666572 -6859.14253903]
检测为-Olga
开始于:159.7结束于:162.92
[-6421.72235531 -5983.90538059]
检测为
-Olga开始于:185.02结束于:208.7
…
开始于:442.04结束于:445.5
[-7451.0289772 -6286.6619 ]
检测为-Olga
*******
WINNER-Olga
此示例假设至少有2个类- [Olga,Ivan]。音频文件被切成段[1.92、8.72],[9.22、15.72],…,[442.04、445.5],并为每个段确定最合适的模型。
累积似然对数显示在每个块旁边的括号中:[-10400.93604115 -12111.38278205],第一个元素是奥尔加的可能性,第二个元素是伊万。由于第一个自变量大于第二个自变量,因此将该段分类为Olga。最终的获胜者取决于片段的大多数“票数”。
结果
最初,我们是基于以下假设设计算法的:传入呼叫中可能存在“未知”管理者-也就是说,训练样本中不存在他的模型。
为了检测这样的用户,我们需要在log_likelihood向量上输入一些度量。这样的某些值将表明该片段很可能没有被任何现有模型充分描述。我们建议使用以下指标作为测试:
Leukl=(log_likelihood-np.min(log_likelihood))/(np.max(log_likelihood)-np.min(log_likelihood))
-sorted(-np.array(Leukl))[1]<T该值指示得分在log_likelihood向量中的分布“平均”程度。估算值的统一性(它们彼此之间的接近性)意味着所有模型的行为都相同,并且没有明确的领导者。
这表明所有模型很可能都是错误的,并且我们有一位不在培训阶段的经理。图中示出了T与分类质量之间的关系。
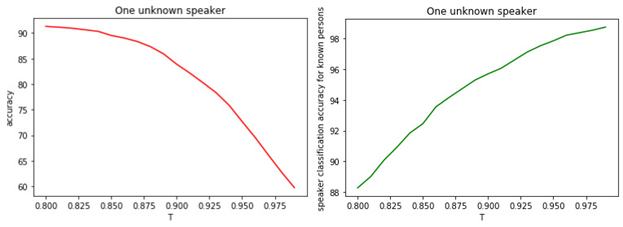
数字: 1.
a)已知和未知管理器的二进制分类的准确性。
b)知名经理人分类的准确性。

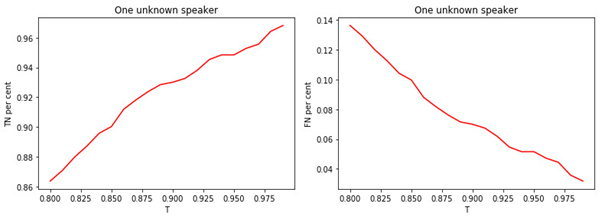
数字: 2.
a)分配到知名经理类别中的知名经理的比例。
b)分配给已知类别的未知管理者的比例。
数字: 3。
a)分配给未知类别的未知管理者的份额。
b)分配给未知类别的知名经理的比例。
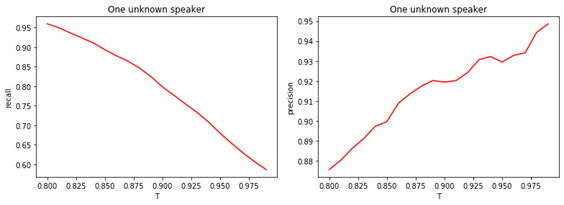
数字: 4.
a)二进制分类的完整性(召回)。
b)二进制分类的精度(精度)。
阈值T的值与分类(标记)质量之间的关系是显而易见的。T越大(将管理者分配给未知类的条件越严格),知名管理者被分类为未知的可能性就越小。但是,更有可能“错过”一位未知的经理。
最佳阈值为0.8。因为我们将知名经理分类的准确性约为90%并以81%的准确度确定“未知” 。如果我们假设所有经理都对我们“熟悉”,那么准确性将达到98%左右。
结论
在本文中,我们描述了用于识别呼叫中经理的工具功能的一般思路。当然,我们不假装我们的算法是最优的并且不能改进。
它基于许多在实践中并不总是满足的假设。例如,如果没有关于他的数据,我们可能会遇到一个未知的经理。或者两个或多个经理可以与客户“平均分配”进行对话。从算法的角度来看,可以提出以下进一步改进的方向:
- 选择与GMM不同的算法模型
- 优化GMM参数
- 选择其他指标以检测新经理
- 搜索语音信号的最重要特征
- 各种音频预处理工具的组合以及这些方法的参数优化