
DBMS在这方面的工作遵循相同的原则-“他们说要挖,而我要挖”。您的请求不仅会减慢相邻进程的速度,不断占用处理器资源,而且还会完全“丢弃”整个数据库,“消耗”所有可用内存。因此,开发人员有责任防止无限递归。
在PostgreSQL中,
WITH RECURSIVE自从8.4版本开始就使用递归查询的能力已经出现,但是您仍然可以经常遇到潜在的易受攻击的“无防御”查询。如何使自己免受这类问题的困扰?
不要编写递归查询
并写成非递归的。恭喜您实际上,PostgreSQL提供了大量功能,可用于避免递归。
对工作使用根本不同的方法
有时,您可以“从另一侧”看问题。我在文章“ SQL HowTo:1000和一种聚合方式”中给出了这种情况的示例-将一组数字相乘而不使用自定义聚合函数:
WITH RECURSIVE src AS (
SELECT '{2,3,5,7,11,13,17,19}'::integer[] arr
)
, T(i, val) AS (
SELECT
1::bigint
, 1
UNION ALL
SELECT
i + 1
, val * arr[i]
FROM
T
, src
WHERE
i <= array_length(arr, 1)
)
SELECT
val
FROM
T
ORDER BY --
i DESC
LIMIT 1;此类请求可以用数学专家的变体代替:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
exp(sum(ln(prime)))::integer val
FROM
src;使用generate_series而不是循环
假设我们面临着为字符串生成所有可能的前缀的任务
'abcdefgh':
WITH RECURSIVE T AS (
SELECT 'abcdefgh' str
UNION ALL
SELECT
substr(str, 1, length(str) - 1)
FROM
T
WHERE
length(str) > 1
)
TABLE T;确实,您是否需要在此处进行递归?..如果使用
LATERAL和generate_series,那么甚至不需要CTE:
SELECT
substr(str, 1, ln) str
FROM
(VALUES('abcdefgh')) T(str)
, LATERAL(
SELECT generate_series(length(str), 1, -1) ln
) X;更改数据库结构
例如,您有一个论坛帖子表,其中包含指向谁回答某人或某个社交网络上的话题的链接:
CREATE TABLE message(
message_id
uuid
PRIMARY KEY
, reply_to
uuid
REFERENCES message
, body
text
);
CREATE INDEX ON message(reply_to);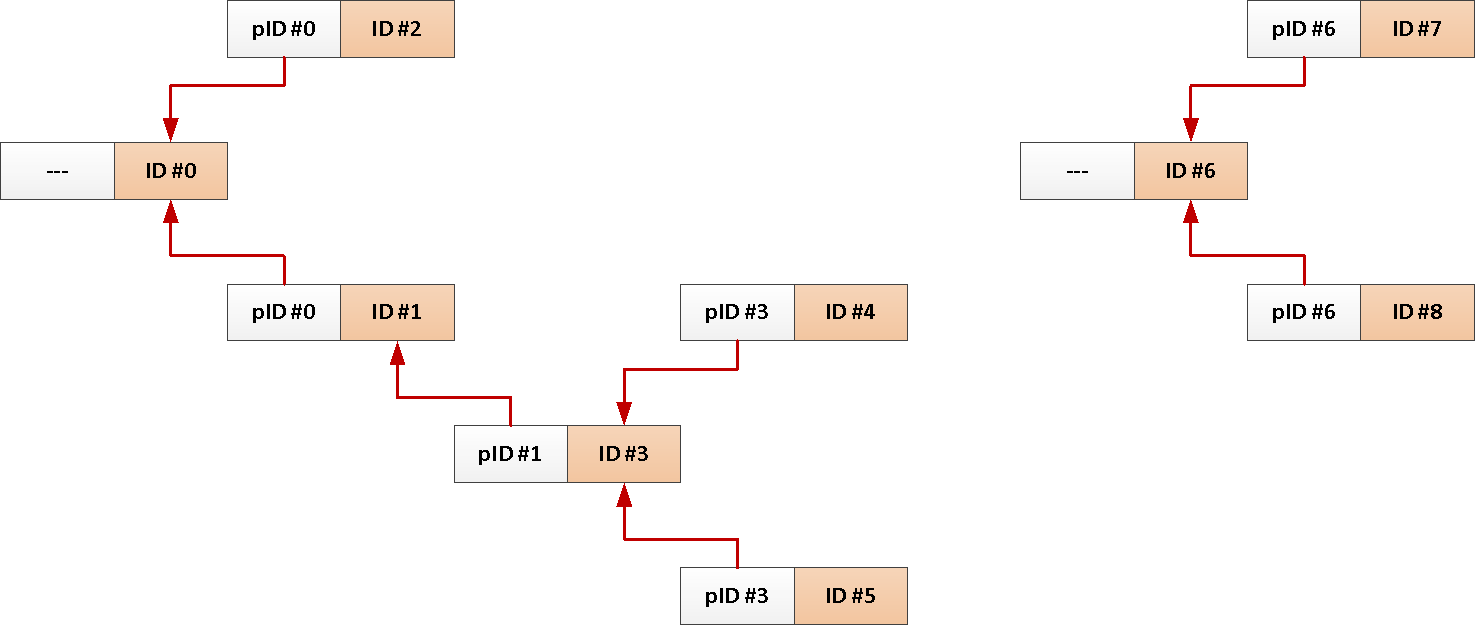
好吧,一个典型的下载一个主题的所有消息的请求看起来像这样:
WITH RECURSIVE T AS (
SELECT
*
FROM
message
WHERE
message_id = $1
UNION ALL
SELECT
m.*
FROM
T
JOIN
message m
ON m.reply_to = T.message_id
)
TABLE T;但是,由于我们始终需要根消息中的整个主题,所以为什么不将其标识符自动添加到每个帖子中呢?
--
ALTER TABLE message
ADD COLUMN theme_id uuid;
CREATE INDEX ON message(theme_id);
--
CREATE OR REPLACE FUNCTION ins() RETURNS TRIGGER AS $$
BEGIN
NEW.theme_id = CASE
WHEN NEW.reply_to IS NULL THEN NEW.message_id --
ELSE ( -- ,
SELECT
theme_id
FROM
message
WHERE
message_id = NEW.reply_to
)
END;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER ins BEFORE INSERT
ON message
FOR EACH ROW
EXECUTE PROCEDURE ins();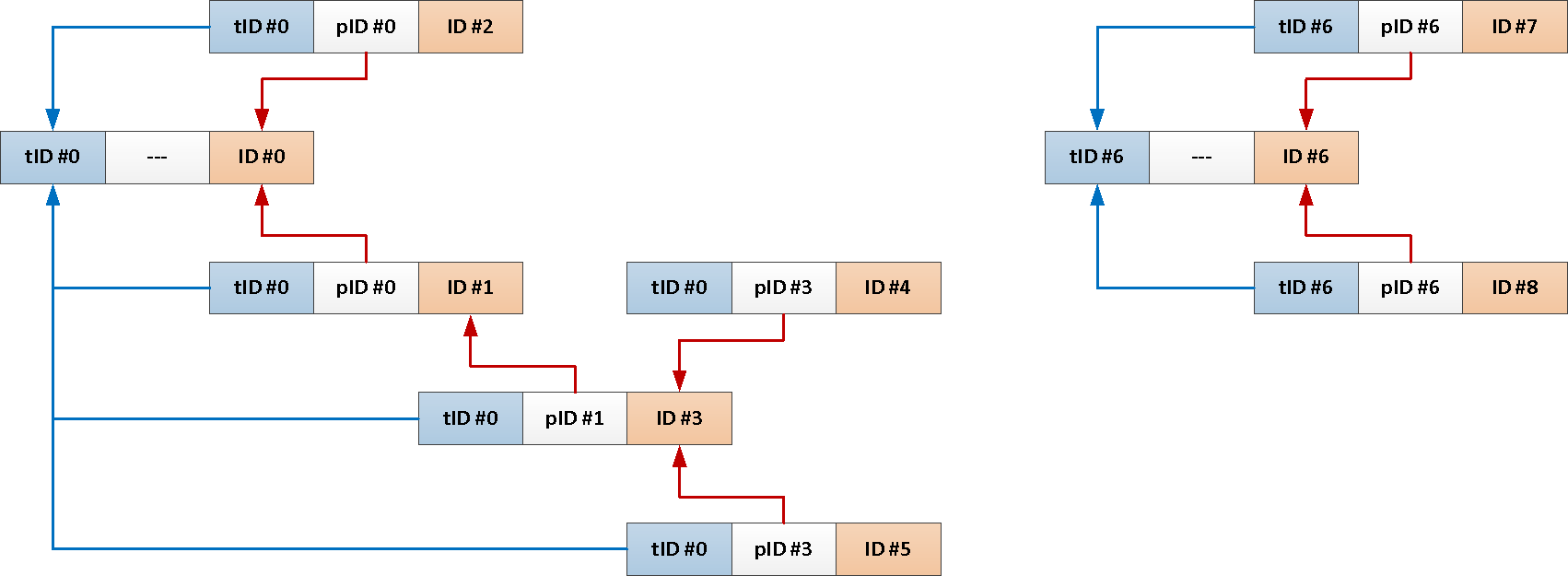
现在我们的整个递归查询可以简化为:
SELECT
*
FROM
message
WHERE
theme_id = $1;使用应用的“约束”
如果由于某种原因我们无法更改数据库的结构,请看看我们可以依靠什么,以便即使数据中存在错误也不会导致无限递归。
递归“深度”计数器
我们仅在递归的每一步将计数器增加一个,直到达到极限为止,我们认为这是不适当的:
WITH RECURSIVE T AS (
SELECT
0 i
...
UNION ALL
SELECT
i + 1
...
WHERE
T.i < 64 --
)优点:当我们尝试循环时,我们仍然不会超过“深”迭代的指定限制。
相反:不能保证我们不会再次处理相同的记录-例如,在深度15和25处,然后每+10有一个。没有人答应有关“宽度”的任何事情。
从形式上讲,这种递归不会是无限的,但是如果每一步记录的数量成倍增加,我们都知道它如何结束...

守护之道
我们将递归路径上遇到的所有对象标识符一个一个地添加到一个数组中,该数组是它的唯一“路径”:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) --
)优点:如果数据中存在循环,我们绝对不会在同一路径中重新处理同一记录。
相反:但同时,我们可以从字面上绕开所有记录,而无需重复。
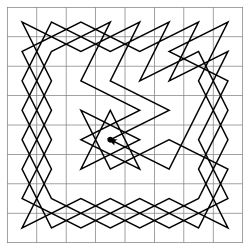
路径长度限制
为了避免递归“徘徊”在无法理解的深度,我们可以将前面两种方法结合起来。或者,如果我们不想支持额外的字段,请使用路径长度的估计值补充递归连续条件:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) AND
array_length(T.path, 1) < 10
)选择适合您口味的方法!