
让我们谈谈使用深度学习和强化学习来玩Snake的神经网络。您可以在Github上找到代码,错误分析,AI演示以及在其下进行的实验。
自从我在AlphaGo上观看Netflix纪录片以来,我一直对强化学习着迷。这样的学习可与人类的学习相提并论:您看到某件事,您做某事,并且您的行动有后果。是好是坏。您可以从后果和正确的行动中学习。强化学习有许多应用程序:自动驾驶,机器人技术,交易,游戏。如果您熟悉强化学习,请跳过接下来的两个部分。
强化学习
原理很简单。代理通过与环境的交互来学习。他选择一个动作,并以状态(或观察)和奖励的形式从环境中接收响应。该循环持续进行或直到被中断。然后新的情节开始。示意图如下所示:

代理商的目标是获得每集最大的回报。在培训开始时,代理会检查环境:在相同状态下尝试不同的操作。随着学习的进行,代理人的研究越来越少。相反,他根据自己的经验选择了最有价值的操作。
深度强化学习
深度学习使用神经网络从输入生成输出。只需一个隐藏层,深度学习就可以放大任何功能。怎么运行的?神经网络是具有节点的层。第一层是输入数据层。隐藏的第二层使用权重和激活函数来转换数据。最后一层是预测层。

顾名思义,深度强化学习是深度学习和强化学习的结合。代理学习使用状态作为输入,将动作的值作为输出,并奖励在正确方向上调整权重的方法来预测给定状态的最佳动作。让我们使用深度强化学习来编写Snake。

定义行动,奖励和条件
为了为代理商准备游戏,我们将问题形式化。定义动作很容易。座席可以选择方向:上,右,下或左。奖励和空间状态要复杂一些。有很多解决方案,一个会更好,而另一个会更糟。我将在下面描述其中之一,让我们尝试一下。
如果Snake拿起一个苹果,她的奖励是10分。如果蛇死了,请从奖励中减去100分。为了帮助代理,当Snake靠近苹果时增加1点,当Snake离开苹果时减少1点。
该州有很多选择。您可以获取蛇和苹果的坐标或苹果的方向。重要的是添加障碍物的位置,即蛇的墙壁和身体,以便特工学会生存。以下是行动,条件和奖励的摘要。稍后我们将看到状态调整如何影响性能。

创建环境和代理
通过向Snake程序添加方法,我们创建了强化学习环境。该方法如下:
reset(self),step(self, action)和get_state(self)。此外,应在代理商的每个步骤中计算奖励。看一看run_game(self)。
该代理与Deep Q网络配合使用以找到最佳操作。型号参数如下:
# epsilon sets the level of exploration and decreases over time
params['epsilon'] = 1
params['gamma'] = .95
params['batch_size'] = 500
params['epsilon_min'] = .01
params['epsilon_decay'] = .995
params['learning_rate'] = 0.00025
params['layer_sizes'] = [128, 128, 128]
如果您有兴趣查看代码,可以在GitHub上找到它。
特工打蛇
现在-关键问题!经纪人会学玩吗?让我们看看它如何与环境交互。以下是第一批游戏。代理什么都不懂:

第一个苹果!但是看起来神经网络仍然不知道它在做什么。

找到第一个苹果……然后撞墙。第十四场比赛开始:

经纪人得知:他通往苹果的路并不是最短,但他找到了苹果。以下是第三十场比赛:

仅经过30场比赛,Snake就避免了与自己的碰撞,并找到了通往苹果的快速途径。
让我们玩太空
可以更改状态空间并获得类似或更好的性能。以下是可能的选项。
- 无方向:请勿告诉代理蛇的移动方向。
- 用坐标表示状态:用苹果(x,y)和蛇(x,y)的坐标替换苹果的位置(上,右,下和/或左)。坐标值的范围是0到1。
- 方向0或1状态。
- 仅墙状态:仅在有墙时报告。但与身体的位置无关:下方,上方,右侧或左侧。

以下是不同状态的性能图:
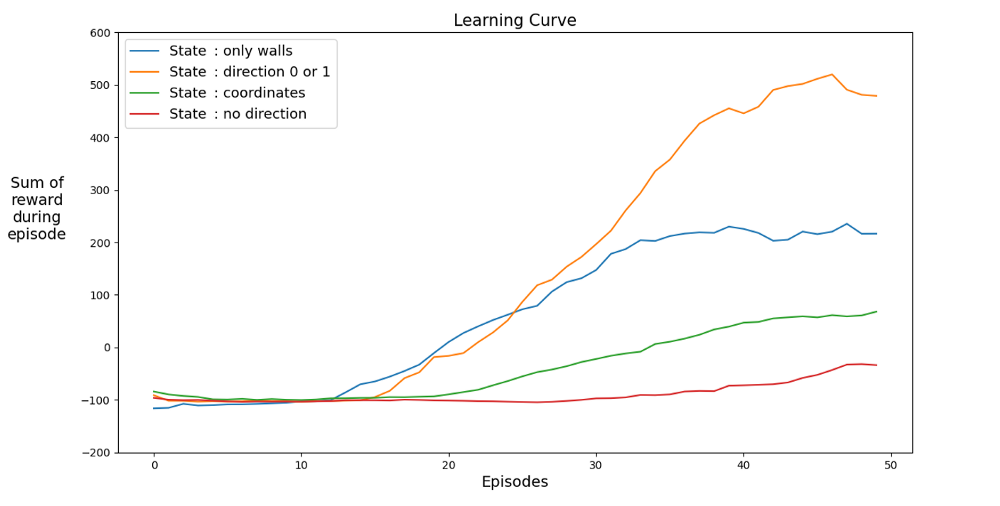
让我们找到一个加速学习的空间。该图显示了不同状态下最近12场比赛的平均成绩。
显然,当状态空间有指示时,代理会快速学习,从而获得最佳结果。但是带有坐标的空间更好。也许可以通过培训更长的时间来获得更好的结果。缓慢学习的原因可能是可能的状态数:20 * 2 * 4 = 1,024,000。20 x 20航向,64个障碍物选项和4个当前航向选项。对于原始变量空间,3²*2⁴* 4 =576。这比1,024,000小1700倍,当然会影响学习。
让我们一起玩大奖
有更好的内部奖励逻辑吗?让我提醒您,蛇是这样获得的:

第一个错误。绕圈行走
如果将-1更改为+1怎么办?这可能会减慢学习曲线,但最终Snake不会死。这对于游戏非常重要。特工迅速学会避免死亡。

在某个时间点,代理会获得一个生存点。
第二个错误。撞墙
让我们将绕过苹果的点数更改为-1。让我们将苹果本身的奖励设置为100点。会发生什么?特工每次动作都会受到惩罚,因此他会尽快移至苹果。这可能发生,但是还有另一种选择。

AI沿着最近的墙走以最大程度地减少损失。
经验
您只需要30场比赛。人工智能的秘密是先前游戏的体验,将其考虑在内,以便神经网络学习更快。在每个常规步骤,执行一系列重播步骤(参数
batch_size)。之所以如此行之有效,是因为对于给定的动作和状态对,奖励与下一个状态之间的差异很小。
错误号码3。没有经验经验
真的那么重要吗?让我们把它拿出来。并为苹果获得100点奖励。以下是没有经验的代理商,曾玩2500场比赛。

尽管该代理人玩了2500次(!)游戏,但他没有玩蛇。游戏很快结束。否则,将需要10,000场比赛。经过3000场比赛,我们只有3个苹果。经过10,000场比赛之后,苹果仍然是3。是运气还是学习成果?
确实,经验有很大帮助。至少要考虑到奖励和空间类型的经验。您每步需要重播多少次?答案可能令人惊讶。为了回答这个问题,让我们玩一下batch_size参数。在原始实验中,将其设置为500。具有不同经验的结果概述:

200种不同经验的游戏:1个游戏(无经验),2和4。平均20个游戏。
即使有2场游戏的经验,代理人也已经开始学习游戏了。在图表中,您可以看到Impact
batch_size,如果使用4而不是2,则100场游戏可以获得相同的性能。本文中的解决方案给出了结果。该代理学会了玩蛇游戏并取得了不错的成绩,在50场游戏中收集了40至60个苹果。
细心的读者可能会说:蛇中的苹果最大数量为399。为什么AI不能赢?实际上,60与399之间的差异很小。这是真的。这里有一个问题:蛇回绕时不能避免碰撞。
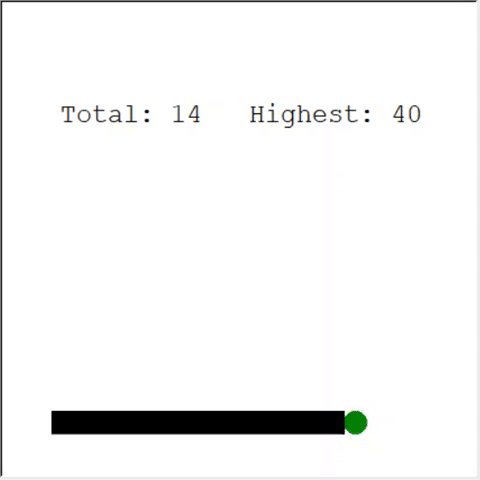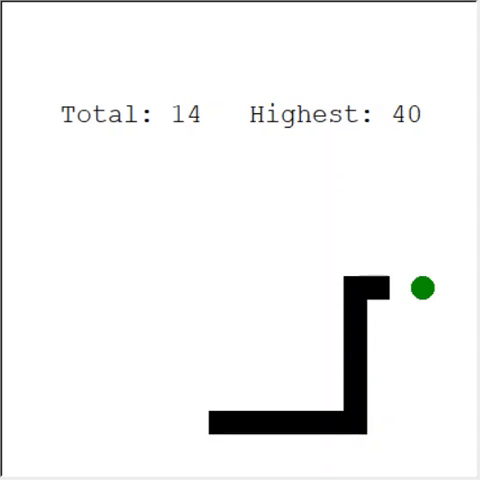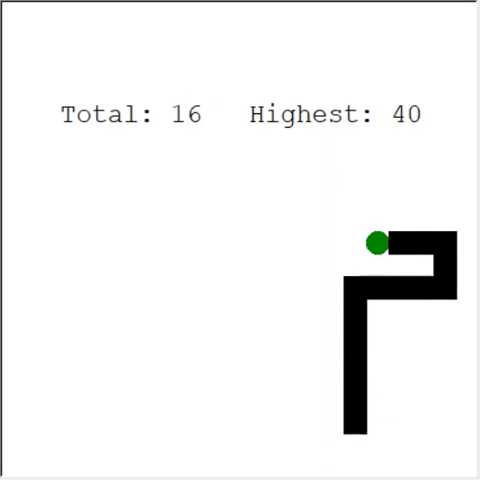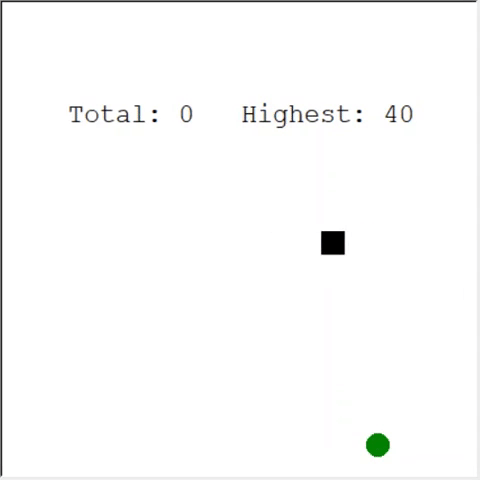
解决该问题的一种有趣方法是将CNN用于比赛场地。这样AI可以看到整个游戏,而不仅仅是附近的障碍物。他将能够识别赢得比赛所需去的地方。
参考书目
[1] K. Hornik, M. Stinchcombe, H. White, Multilayer feedforward networks are universal approximators (1989), Neural networks 2.5: 359–366
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
, Level Up , - SkillFactory:
- Machine Learning (12 )
- « Machine Learning Data Science» (20 )
- «Machine Learning Pro + Deep Learning» (20 )
- Data Science (12 )
E
- - (8 )
- - Data Analytics (5 )
- (6 )
- (18 )
- «Python -» (9 )
- DevOps (12 )
- Java- (18 )
- JavaScript (12 )
- UX- (9 )
- Web- (7 )
