
公司可以通过多种方式帮助他们的开发人员最大化生产力,从改变办公空间到获得更好的工具并清理源代码。但是,哪些决定将产生最大的影响?利用有关软件开发和产业/组织心理学的文献,我们确定了与生产力相关的因素,并采访了三家公司的622名开发人员。我们对上述因素以及人们自己如何评估自己的生产力感兴趣。我们的发现表明,自尊受非技术因素的影响最大:工作热情,同事对新想法的支持以及对生产力的有用反馈。与其他知识工作者相比,软件开发人员对其生产力的评估更多地取决于任务的种类和远程工作的能力。
1.简介
重要的是提高开发人员的生产率。按照定义,当他们完成任务时,可以将空闲时间花在其他有用的任务上:引入新功能和新检查。但是,什么可以帮助开发人员提高生产力呢?
公司需要针对哪些因素进行操作以提高生产率的实用指南。例如,开发人员应该花时间寻找更好的工具和方法,还是应该白天关闭通知?领导者应该投资重构以降低代码复杂性,还是赋予开发人员更多的自治权?老板应该投资于更好的开发工具还是更舒适的办公室?在理想的世界中,我们会投资各种因素来提高生产率,但是时间和金钱是有限的,因此我们必须选择。
本文是迄今为止最广泛的软件开发人员生产力预测研究。如第3.1节所述,可以客观(例如,按每月代码行)或主观(由开发人员自己估算)来衡量生产率。尽管两种方法都不可取,但我们试图通过主观判断广泛地涵盖该主题,以回答三个问题:
- 哪些因素是开发人员如何评估其生产力的最佳预测因素?
- 这些因素在公司之间如何变化?
- 是什么能预测开发人员对他们的生产力的评估,特别是与其他知识工作者相比?
为了回答第一个问题,我们在一家大型软件公司进行了研究。
为了回答第二个问题,这有助于理解所获得的结果可以推广到什么程度,我们对来自不同行业的两家公司进行了研究。
为了回答第三个问题,这有助于了解开发人员与其他开发人员的不同之处,我们在其他专业的代表中进行了一项研究,并将其与研究开发人员的结果进行了比较。
我们的结果表明,在我们研究的公司中,他们的生产力的自尊心受到工作热情,对新想法的同伴支持以及对他们的生产力的有用反馈的强烈影响。与其他知识工作者相比,软件开发人员对其生产力的评估更多地取决于任务的多样性和远程工作的能力。公司可以使用我们的发现来确定与生产力相关的计划的优先级(第4.7节)。
第2节介绍了我们研究的公司。第三部分描述了研究方法。第4节描述并分析了获得的结果。第5节介绍了与此主题相关的其他工作。

2.研究的公司
2.1。谷歌
Google在全球拥有约40个开发办公室,雇用数万名开发人员。公司重视团队内部的紧密合作,而办公室通常是开放式的,以使团队成员之间的联系更加紧密。该公司还比较年轻(成立于1990年代后期),其组织结构相当扁平,并且开发人员拥有很多自主权。晋升过程包括来自同级的反馈,开发人员无需过渡到管理职位即可晋升。开发人员自己计划时间,他们的日历显示在公司网络上。 Google使用通常应用于整个团队的敏捷开发流程(例如Agile)。
谷歌重视开放性。大多数开发人员都在一个通用的整体代码库上工作,因此鼓励他们更改其他人项目的代码。该公司具有严格的测试和代码审查文化:提交给存储库的代码由另一位开发人员通常使用测试来审查。大多数写服务器端代码的频率很高,因此发布修订程序相对容易。开发工具包在很大程度上是统一的(不包括编辑器),并且在内部构建,包括分析和持续集成工具以及发布基础结构。
2.2。ABB
ABB在全球拥有超过100,000名员工。作为一家工程集团,该公司拥有广泛的职业。使用特定于行业的视觉和文字语言构建工业系统的大约4,000个普通软件开发人员和10,000多个应用程序开发人员。为了运营其大型IT基础架构,公司拥有大量员工,其职责包括脚本编制和简化编程。
尽管ABB接管了许多较小的公司,但它有一个中央组织负责统一软件开发流程。因此,尽管部门之间存在差异,但大多数工具和方法都是一致的。对于大多数职业道路而言,情况都是如此:对于技术人员,从初级到高级开发人员,对于高管,从组长到部门主管和中央管理人员。
2.3。国家仪器
National Instruments成立于1970年代。软件开发主要集中在四个国际研发中心。员工日历对整个公司都是可见的,任何人都可以与任何其他员工约会。
工作职责促进了开发过程。开发人员无法独立选择项目,但可以承担特定的任务或功能。大多数使用通用的整体代码库,其不同的逻辑部分具有特定的所有者。输入的代码必须由“所有者”批准。最好由技术负责人分析代码。此策略是可选的,但很多人都遵循它。
开发人员在选择工具时有很多自由。除非能立即受益,否则没有通用工具。例如,IDE的选择高度依赖于任务。有许多可用的自定义构建和测试工具。公司的不同部门已经标准化了用于源代码管理和分析的不同系统。软件更新通常每季度或每年发布一次,稀有的重要补丁除外。
表1.研究的三家公司的概况:
| 谷歌 | ABB | 国家仪器 | |
| 规模 | 大。 | 大。 | 娇小。 |
| 办事处 | 开设办事处。 | 开放式和封闭式办公室。 | 开设办事处。 |
| 工具类 | 主要是统一的开发工具。 | 相同的工具。 | 灵活的工具选择 |
| 开发类型 | 主要是服务器端代码和移动代码。 | Web开发,嵌入式和桌面软件的组合。 | 主要是嵌入式和桌面软件。 |
| 资料库 | 整体存储库。 | 单独的存储库。 | 整体存储库。 |
| 坡 | 软件开发。 | 工程集团。 | 开发软件和设备。 |
3.方法论
我们的目标:找出哪些因素可以预测软件开发人员的生产力。为此,我们进行了一项研究,其中包含一组问题,一组生产率因素和一组人口统计变量。
3.1评估生产力
首先,让我们描述一下如何衡量生产力。 Ramírez和Nembhard提出了文献中描述的绩效评估技术的分类,包括功能点分析,自我评估,同伴评估,成果和努力的比例以及时间的专业使用[2]。这些技术可以分为客观的(例如,每周编写几行代码)和主观的(例如,自我评估或同行评审)。
两种技术都不是首选;两种类别都有缺点。客观测量缺乏灵活性和趣味性。让我们以每周的代码行数为单位。富有成效的开发人员可以为难以发现的错误编写单行修复程序。效率低下的开发人员很容易增加行数。另一方面,由于认知偏差,主观测量可能不准确。进行同行评等:他们可能不喜欢有生产力的开发人员,因此即使同行为求客观而努力,他们的评等也会变差。
就像由迈耶(Meyer)领导的研究团队分析软件开发人员的生产力[3]一样,我们将研究问题用作生产力的主观衡量指标。有两个主要原因。首先,正如Ramirez和Nembhardt所指出的那样,研究是“一种简单且流行的方法来衡量[知识工作者]的生产率。” 其次,研究会提供来自不同角色的开发人员的反馈,并且还允许受访者在其绩效评估中添加不同的信息。
数字:1.研究方法:

我们询问了受访者他们是否同意以下说法:
我经常实现高生产率。
有了它,我们希望尽可能广泛地衡量生产力。我们首先为该问题提出了八个选项,然后通过与五名Google开发人员非正式地讨论了他们对该词组的解释,将其简化为上述选项(图1,左下)。我们出于三个原因在问题中添加了“高”和“定期”两个词。首先,我们想捕捉一个人们可以比较自己的状态。其次,我们希望此状态很高,以避免在受访者的答案中达到上限的影响。第三,我们希望受访者关注生产率的两个具体指标-强度和频率。将来,研究人员可以通过将强度和频率划分为两个单独的问题来应用更详细的度量。
我们通过要求Google的三名高管将其发送给他们的团队来进行测试,以询问:“您在回应生产率声明时考虑了什么?”我们收到了23位开发人员的回复(图1,底部中心)。对于我们的目的,该选项被认为是可以接受的,因为受访者的考虑与我们对生产力价值的期望相符。这些考虑因素包括工作流程问题,工作结果,处于区域或流程中,幸福感,实现的目标,编程效率,进度以及最大程度地减少了浪费的精力。我们没有在本文中分析这些响应,但是该研究还包括从以前的工作[2],[4],[5]中获得的另外四个精细的生产率指标。
我们选择了两种方便的生产率衡量标准,以添加客观数据来关联自尊,然后在Google上将它们相互关联。第一个客观指标是开发人员每周更改的代码行数-这是一种流行但极富挑战性的生产率指标[6],[7]。第二个指标是开发人员每单位时间对主要Google代码库所做的更改数量。这几乎等于瓦西莱斯库(Vasilescu)领导的团队所使用的每月拉动请求[8]。为了评估我们的生产力,我们使用了对Google进行的类似调查的答复(n = 3344答复)。我们无法将研究中的数据用于此分析,因为回复中没有参与者ID。可以用来比较生产率的客观指标。在该研究中,他们提出了类似的问题:“您多久觉得自己的工作效率很高?”参与者可以回答“很少或永远不会”,“有时”,“大约一半的时间”,“大部分时间”和“总是或几乎总是”。然后,我们创建了具有自我报告性能的线性回归作为序数因变量(分别编码为1、2、3、4和5)。线性回归假设生产率等级之间的距离相等。给定问题中使用的词语,我们认为这种假设是合理的。对于有序逻辑回归,不需要此假设。此技术在此处的应用可提供可靠的结果:相同的系数在线性,并在有序模型中
我们将对数目标测度用作自变量,因为它们都存在正偏斜。对于控制,我们将作业代码(例如,软件工程师,研究工程师等)作为分类变量,并将等级(初级,中级,高级等)作为数字(例如,软件为3) Google的入门级工程师)。在每个线性模型中,对于两个工作人员角色,工作代码在统计上都很重要。一共有三种模型:两种采用一种客观指标,一种采用两种客观指标。

数字:2:基于两个客观指标来预测主观绩效估计的模型。ns表示统计学上无关紧要的因素,其中p> 0.05,**表示p <0.01,***表示p <0.001。补充材料中提供了模型的完整说明。
情境化结果如图5所示。 2.每个模型都显示出具有统计学上显着性水平的负面评价,我们将其解释为:排名较高的开发人员倾向于将自己的评价为生产力略低。对于等级控制,这是一个有力的论据(第3.7节)。前两个模型证明了生产力的客观和主观度量之间的重要正相关关系。也就是说,编写更多的代码行或进行更改,开发人员认为自己的生产效率更高。由此产生的组合模型和前两个模型的估计值表明,相比于所写的行数,所做更改的数量是生产力的更重要指标。但请注意,在所有模型中,参数R 2,代表所解释的方差的比例,相当低-每种模型都小于3%。
通常,获得的结果表明,代码行的数量和所做的更改会影响开发人员对其生产力的评估,但影响不大。
3.2。生产力因素
然后,在研究过程中,我们向参与者询问了其他研究中被认为与生产力相关的因素。我们从四个来源收集了问题(图1,左中)。之所以选择这些资源,是因为据我们所知,它们代表了程序员和其他知识工作者研究中各个生产力因素的最全面概述。
第一来源是由Palvalin领导的团队创建的工具,用于审核知识型员工的生产率指标[4]。该工具名为SmartWoW,已被四家公司使用,涵盖了物理,虚拟和社交工作区,个人工作习惯和工作幸福感等方面。我们更改了一些问题,以更好地反映当前的开发人员术语并更好地匹配美国英语。例如,SmartWoW询问:
我经常进行远程办公以执行需要不间断专注的任务。
我们的解释是:
我经常远程工作以执行需要不间断专注的任务。
我们首先从SmartWoW中选择了38个问题进行研究。
第二个来源是Hernaus和Mikulić对工作环境特征对知识工作者生产力的影响的回顾[9]。他们经过验证的工作反映了以前的生产力研究:工作环境设计调查表[10],诊断性工作环境研究[11],小组协作评估[12]和“任务性质”评估[13]。我们已将问题简短而一致地更改了。出于相同的目的,我们直接从工作中提出问题[12],该工作专门针对工作组,而这些工作组很少考虑个人生产力。
第三来源-对Wagner和Ruhe在软件开发中的生产率因素进行了结构化的综述[14]。与其他来源不同,这项工作尚未得到科学界的充分验证,并且不包含原始的实证研究。但是据我们所知,这是对编程生产力研究的最全面的调查。 Wagner和Rouet提出的因素分为技术因素和不可量化因素,然后重点强调环境,企业文化,项目,产品和开发环境,能力和经验等因素。
第四个来源是由Meyer领导的团队领导的Microsoft开发人员研究。从中,我们得出了进行富有成效的工作日的五个主要原因,包括目标设定,工作会议和下班休息[15]。
我们还添加了三个因素,我们认为这些因素在先前的作品中并未得到适当考虑,但对于Google而言却显得尤为重要。一种是知识工作者的生产率评估[16],这是SmartWoW尚未发布的前身。我们这样修改它:
提供给我的信息(错误报告,用户脚本等)是准确的。
第二个因素来自工作环境设计调查表,并作如下调整:
我收到有关工作效率的有用反馈。
我们创建了在ABB环境中非常重要的第三个因素:
我需要直接访问某些硬件才能测试我的软件。
首先,我们选择了127个因素。为了将它们简化为回答者可以在不引起明显疲劳的情况下回答的大量问题[17],我们使用了图中心所示的标准。1:
- 删除重复项。例如,在SmartWoW [4]和Meyer与同事的工作[15]中,目标设定被认为是提高生产率的重要因素。
- 相似因素相加。例如,Hernaus和Mikulich描述了工作组之间交互的不同方面,这些工作组可以提高生产率,但是我们已将它们减少为一个因素[9]。
- 优先考虑具有明显效用的因素。例如,SmartWoW [4]具有以下因素:
员工有机会查看彼此的日历。
在Google,这是无处不在的,而且不太可能改变,因此该因素的实用性较低。
我们已经联合和迭代地应用了这些标准。首先,打印了用于该研究的所有候选问题的大海报。然后,我们在办公室旁边贴了一张Google海报。然后,我们每个人都根据上述标准独立分析了问题。海报挂了几个星期,我们定期对列表进行补充和修订。最后,草拟了最终的问题清单。
我们的研究以陈述的形式包括了48个因素(图4,左栏)。受访者表示他们对这些表述的同意程度为五点,从“完全不同意”到“完全同意”。可以将因素分为与方法论,重点,经验,工作,机会,人员,项目,软件和环境有关的块。我们还询问了一个开放式问题,即受访者认为我们可能错过了哪些因素。补充材料中提供了我们研究的完整问卷。

数字:3:来自研究的示例问题。
3.3。人口统计学
我们询问了有关几个人口因素的问题,如图1所示:
- 地板。
- 位置。
- 秩。
先前工作的作者建议,性别与软件开发人员的生产力因素有关,例如,与调试的成功有关[18]。因此,该研究有一个关于性别的可选问题(男性,女性,拒绝回答,我自己)。未回答问题的受访者被分配到“拒绝回答”组(Google n = 26 [6%],ABB n = 4 [3%],National Instruments n = 5 [6%])。我们将此数据视为分类数据。
至于职位,我们在人事部门担任Google的职位。 ABB和National Instruments无法做到这一点,因此我们在研究中添加了一个可选问题。在ABB,没有答复(n = 4 [3%])时,我们花费了12年的经验,这是所收集数据的平均值。在National Instruments,出于同样的原因,我们花了9年的时间(n = 1 [1%])。例如,使用替代基于可用数据来预测缺失值可能会变得更加困难[19]。假设可以根据职位和性别准确地填写缺失的等级信息。但是,由于人口因素对我们而言并不是最重要的因素,因此我们仅替换了平均统计值,它们只是控制的附带信息。我们将此数据处理为数字。
在排名方面,我们在Google上要求参与者将其级别表示为数字。遗漏的答案(n = 26 [6%])是最常见的值。
在ABB,贡献者可以选择表示“初级或高级软件开发人员”,尽管许多人表示“不同”的标题。如果答案中包含以下单词:
- 年长的
- 领导
- 经理
- 建筑师
- 研究员
- 主要
- 科学家
然后我们将此类答案称为“高级”答案。其余被称为“初级”。遗漏的答案(n = 4 [3%])是我们最常见的含义-“高级”。
National Instruments有以下选择:
- 挑战者
- 员工
- 年长的
- 首席建筑师/工程师
- 首席建筑师/工程师
- 荣誉工程师
- 参加者
- 其他
唯一的“其他”原来是实习生,我们将其转移给“申请人”。遗漏的答案(n = 3 [4%])是我们最常见的含义-“高级”。
我们已经按编号对所有公司的排名进行了编码。
3.4。与非开发人员的比较
接下来,我们对究竟能使我们如何预测开发人员如何评估其生产力感兴趣。例如,我们假设生产力受到工作中断的影响,但是对于任何知识工作者来说都是如此。因此,产生了一个自然的问题:这是否以某种特殊的方式影响开发人员的生产率?
为了回答这个问题,我们选择了与软件开发人员相当的职业。首先,我们尝试根据Google中的职位进行选择。尽管有些职位表明他们是知识工作者,但在我们看来,合适的非开发人员最常见,最可靠的指示是该职位中存在“分析师”一词。我们决定将Google分析师和开发人员进行比较,而不是将Google分析师与这三家公司的开发人员进行比较。我们认为,这将使我们能够控制公司的特定特征(例如,如果突然之间Google员工在统计上比其他公司的员工对中断的敏感程度更高或更低)。
然后,我们为分析师调整了我们的研究。删除了与软件开发明确相关的问题,例如“我的软件需求经常更改”。我们已经针对分析师重新提出了其他问题。例如,我们写了“我使用最好的工具和方法来完成工作”,而不是“我使用最好的工具和技术来开发软件”。
生产力得分的衡量方法与开发人员相同。评估性别,职位和等级也是如此。我们在五名分析师的方便样本中测试了该研究的“分析”版本,他们说该研究总体上很清楚,并且做了一些小调整。我们接受了他们,并对非开发人员进行了全面的研究。

3.5。控制问题
为了排除那些漫不经心地给出的答案,在大约70%的研究开始之后,我们插入了一个专心的问题[20]:“回答这个问题,” 我们没有考虑没有包含该问题答案的表格。
3.6。分享回应
在Google,我们从人力资源中随机挑选了1,000名担任软件工程职位的全职员工。我们从他们那里收到了436份完整的表格,即答复率为44%,这对于开发人员来说是一个非常高的指标[21]。在删除对安全性问题有错误答案的表格(n = 29 [7%])后,剩下407个答案。
为了对知识型员工进行调查,我们选择了200名随机的全职Google员工,其职位中均带有“ analyst”一词。我们决定不研究太多分析师,因为我们的目标是软件开发人员。 94人(占47%)回答了我们的问题。删除对安全性问题有错误答案的问卷(n = 6 [6%])后,剩下88个人。
我们向大约2200名ABB随机选择的软件开发人员发送了问卷,并收到176份答复。这是8%,是此类研究的下限[21]。删除了错误的调查表后(n = 39 [22%]),剩下137个;
最后,我们向美国国家仪器公司的约350名软件开发人员发送了调查表,并收到了91份答复(26%)。删除了错误的调查表(n = 13 [14%])后,剩下78份。
3.7。分析
对于每个公司中的每个因素,我们都应用了单独的线性回归模型,将因素用作自变量(例如,“我的项目时间表紧迫”),而对生产率的估计作为因变量。为了隐私起见,我们为每个公司运行单独的模型,这样就不会混淆来自不同公司的原始数据。为了减少附带变量的影响,我们向每个回归模型添加了现有的人口统计学变量。在解释结果时,我们集中在生产力因子比率的三个方面:
- 评估。表示在维持人口统计常数的同时每个因素的影响程度。值越高,影响越大。
- . . , .
- . p < 0,05. 48 , p -, [22].
在解释结果时,我们将重点更多地放在影响(评估)的程度上,而不是统计意义上,因为即使实际意义很低,也可以从足够大的数据集中提取出来。正如我们将在下面看到的那样,具有统计意义的结果通常是在Google上找到的,响应率最高;最不重要的是-在National Instruments中,响应率较低。我们认为,这种差异在很大程度上归因于统计能力。我们敦促您对具有统计意义的结果更有信心。
为了提供背景,我们还分析了人口统计因素与绩效评级之间的关系。为此,我们对每个公司进行了多元线性回归,将人口变量作为自变量,并将生产力的估计值作为因变量。然后,我们分析了所得模型的总体预测价值以及每个解释变量的影响。
3.8。关于因果关系
我们的方法使我们能够评估生产率因素与其自身生产率的评估之间的关系,尽管从本质上讲,我们对每个因素对生产率变化的影响程度感兴趣。相信因素和生产率之间存在因果关系有多正确?
正确性主要取决于先前工作中因果关系证据的强度。而且此权力因不同因素而异。例如,由Guzzo领导的一个团队对26篇关于评估和反馈的文章进行了荟萃分析,结果提供了极好的证据,表明反馈的确提高了工作场所的生产率[23]。但是,确定每个调查因素的证据强度需要大量工作,这超出了本文的范围。
总结:尽管我们的研究不允许建立因果关系,但是基于以前的工作,我们可以确信地相信这些因素会影响生产率,但是要谨慎解释我们的结果。

4.结果
首先,我们描述了在控制人口统计特征时所有生产率因素及其对生产率的评估之间的关系。这些数据将用于回答每个调查答复,然后讨论结果。然后,我们将讨论人口统计特征与绩效衡量之间的关系。最后,让我们讨论其中的含义和风险。
4.1。生产力因素
在图。图4显示了第3.7节所述的分析结果。第一列以陈述的形式列出了向参与者提出的因素;然后是分析完成后分配的因子标签(F1,F2等)。数据不足意味着这些因素是特定于开发人员的,并不建议分析人员使用(例如F10)。
数字:4:48个因素之间的关系以及开发人员和分析人员如何评估三家公司的生产率:
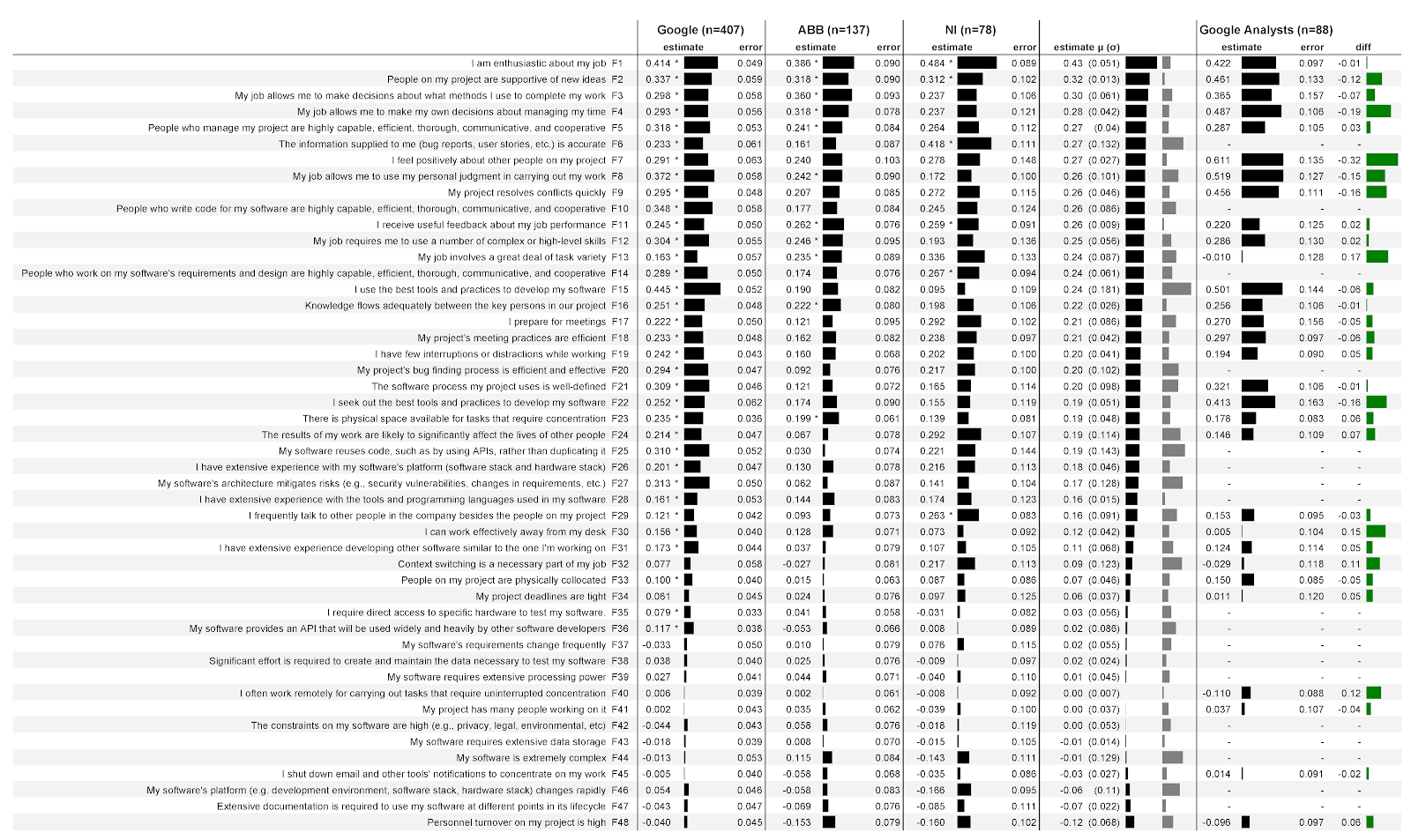
以下三列显示了三家公司的数据以及Google分析师的数据。这些列中的每列都分为两个子列。
子列估算(分数)包含回归系数,该系数用于量化因子与生产率估算值之间的关联强度。数字越大,关联越强。例如,在Google的第一列中,估算值为0.414。在这种情况下,这意味着对于每个与工作热情声明(F1)一致的观点,该模型预测在控制人口统计学变量的情况下,受访者的生产率等级将提高0.414点。评级可以为负。例如,在所有三个公司中,团队中的员工流动率越高(F48),对其生产率的评估就越低。每个分数旁边都有一个指标,可以清楚地反映出分数。
请注意,分数并不意味着因素的等级较高,而是因素与您的生产率等级之间的较高相关性。例如,National Instruments(F1)的热情比其他公司高。这并不意味着开发人员会有更多的热情:在这家公司中,他是预测他们的生产力评估的一个更重要的因素。我们不提供评级,因为合作条款禁止这样做。没有完整的上下文,评级可能会被误解。例如,如果我们报告说一家公司的开发人员对工作的热情不如另一家公司的开发人员,那么您可能会觉得最好不要在另一家公司工作。
第二个子列错误(误差)包含每个因子模型的标准误差。值越低越好。直观地,较低的值似乎表明当因素改变时,该模型更可靠地预测其性能。各个因素之间的总体误差值相当稳定,尤其是在拥有大量受访者的Google上。
星号(*)表示该因素在模型中具有统计学意义。例如,在所有三家公司中,工作热情(F1)在统计上都很重要,而会议准备(F17)仅在Google中很重要。
下一列包含所有三家公司的平均(μ)得分,括号中为标准差(σ)。第一个指标清楚地显示了平均分的值,第二个指标-标准差的值。例如,工作热情的平均分数(F1)为0.43,标准差为0.051。该表按平均评分排序。
最后一列包含Google的软件开发人员与分析师评级之间的差异。正值表示较高的开发人员评级,负值表示较高的分析师评级。例如,就热情(F1)而言,分析师的评级比开发商低一些。
4.2。哪些因素是开发人员如何评估其生产力的最佳预测因素?
最强的预测因素是绝对平均分最高的陈述。最弱的预测因素是绝对平均得分最低的那些。换句话说,在图的表顶部的因素。4是最好的预测指标。为了了解哪个因素对结果最有信心,我们重点介绍了对所有三家公司都具有统计意义的结果:
- 工作热情(F1)
- 同行对新想法的支持(F2)
- 关于工作绩效的有用反馈(F11)
讨论。请注意,前10个生产率因素不是技术因素。鉴于我们估计,软件开发人员的大部分研究都集中在技术方面,因此这令人惊讶。因此,对人为因素的积极调整可能会导致研究人员对该行业的影响显着增加。例如,以下问题的答案可能会特别有用:
- 是什么使软件开发人员对他们的工作充满热情?什么解释了热情上的差异?哪些干预措施可以提高热情?本文可以补充关于幸福[24]和动机[25]的研究。
- ? , ? ?
- , ? ? ?
另一个重要特征是来自COCOMO II研究线的因素排名。这些因素是在对行业软件项目进行实证研究的过程中获得的,并通过对83个项目的数值分析得到了验证[26],这些因素最初是用来估算软件开发成本的。例如,COCOMO II的生产率因素包括基础平台的波动性和产品复杂性。奇怪的是,在我们的研究中考虑到的COCOMO II因素(F5,F10,F14,F16,F24,F26,F28,F32,F33,F34,F36,F38,F39,F43,F44,F46,F47,F48)的收受率较低价值观。可以假设它们使预测生产率变差成为可能。预测因子的上半部分(F1-F24)仅包含5个COCOMO II,下半部分为14个因子。我们可以提供两种不同的解释。第一:COCOMO II缺少几个重要的生产力因素,如果公司引入了我们调查的更多因素,例如对工作方法自主性的支持,则COCOMO II的未来迭代可能更具预测性。另一种解释:COCOMO II适合当前任务-将生产率固定在项目级别[6],[27],[28],[29],[30],[31]-但不太适合固定单个开发人员级别的生产率。这种解释强调了我们结果的重要性和新颖性。COCOMO II适用于当前任务-将生产率固定在项目级别[6],[27],[28],[29],[30],[31]-但不太适合固定单个开发人员级别的生产率。这种解释强调了我们结果的重要性和新颖性。COCOMO II适用于当前任务-将生产率固定在项目级别[6],[27],[28],[29],[30],[31]-但不太适合固定单个开发人员级别的生产率。这种解释强调了我们结果的重要性和新颖性。
另外,所有三个公司的所有COCOMO II因素都相对较低,并且对生产率没有统计学意义的预测因素。例如:
- 我的软件需要大量处理能力(F39)。
- 我的软件需要一个大型数据存储(F43)。
- 我的软件平台(例如开发环境,软件或硬件堆栈)正在快速变化(F46)。
一种解释:自创建和测试COCOMO II以来的20年中,平台在生产率方面的差异已经越来越小。标准化的操作系统现在很可能保护开发人员免受硬件更改(例如,移动开发中的Android)导致的生产力损失。同样,云平台可以保护开发人员避免由于过程扩展和存储需求而导致的生产力损失。更不用说,现代框架和云平台易于使用。此外,自创建COCOMO II以来,处理大量数据和少量数据时生产率的差异可能已经消失。
4.3。这些因素在公司之间有何不同?
要回答这个问题,您可以查看三家公司的估算中的标准差。这是变化最小的三个因素,即整个公司的价值最稳定的三个因素:
- 使用远程办公进行对焦(F40)。
- 关于工作绩效的有用反馈(F4)。
- 对新想法的同伴支持(F2)。
我们认为,这些因素的稳定性使其成为可推广性的良好候选者。其他公司可能会在这些因素上看到类似的结果。
以下是三个具有最大可变性的因素,即在整个公司中价值分布最大的三个因素:
- 使用最佳工具和方法(F15)。
- 代码重用(F25)。
- 传入信息的准确性(F6)。
讨论。三个最小可变因素(F40,F4和F2)具有一个共同的特征-它们与技术无关,但与社会和环境有关。也许这表明开发人员无论在哪里工作,都同样受到远程工作,反馈和对新想法的同行支持的影响。改变这三个因素可能是最大的影响。
为什么不同公司的F15,F25和F6因素如此不同?对于他们每个人,我们都会根据对这些公司的了解做出可能的解释。
使用最佳工具和方法(F15)与Google的性能得分密切相关,但与National Instruments的关系并不明显。可能的解释:Google的代码库更大。因此,使用更好的工具和方法来有效地导航和理解更大的代码库对生产率有重大影响。在National Instruments,由于代码库更小,更清晰,因此生产力对工具的依赖性也较小。
代码重用(F25)与Google的性能得分密切相关,但在ABB上却没有显着关系。可能的解释:Google使重用代码更加容易。代码库是整体的,所有开发人员几乎可以检查公司中的每一行代码,因此重用并不需要太多工作。而且ABB有很多存储库,您必须访问。在这家公司中,生产力的提高(通过重用)可以抵消生产力的降低(通过查找和检索正确的代码)。
信息准确性(F6)与National Instruments的性能得分密切相关,但与ABB无关。可能的解释:ABB的开发人员可以更好地避免信息不准确的影响。特别是在ABB,几级支持团队致力于从客户那里获得有关错误的正确信息。如果开发人员收到的信息不正确,则其生产力可能会下降,因为他必须将精炼数据的任务委托给支持团队。
4.4。是什么使得可以预测开发人员对他们的生产力的评估,尤其是与其他知识工作者相比的评估?
要回答这个问题,请转到图5的最后一列。4.如果您查看最大额定值之间的几种关系,您会发现分析师对他们的生产率的评估与以下方面更紧密相关:
- 对队友的正面看法(F7)。
- 自主安排工作时间(F4)。
另一方面,开发人员对其生产力的评估与以下方面更紧密相关:
- 在工作中执行各种任务(F13)。
- 在工作场所外有效工作(F30)。
讨论。总体而言,结果表明开发人员与其他知识工作者有些相似,但有所不同。例如,开发人员的工作效率最好通过工作热情来预测,而分析师的工作原理却与此相同。我们相信公司可以利用我们的发现来选择针对开发人员的生产力计划,或者选择更广泛的计划。
Google的统一开发工具包可能解释了为什么任务多样性的增加与开发人员而不是分析师的较高生产率等级相关联。任务的多样性可以减少两个团队的无聊并提高工作效率,但是Google统一的开发工具可能意味着开发人员可以将相同的工具用于不同的任务。分析人员可能需要针对不同任务使用不同的工具,这会增加上下文切换中的认知工作量。
外出工作可能可以解释为什么,对于开发人员而言,与分析人员相比,改善工作场所以外的工作效率与提高生产率的关系更大。我们认为,在编程期间比在分析工作中休息更有害。
Parnin和Rugaber发现,中断后恢复工作是开发人员经常遇到的持久问题[32],导致他们需要更好的工具来帮助他们重新解决问题[33]。

4.5。其他生产力因素
在调查表的结尾,受访者可以指出他们认为会影响生产率的其他因素。在大多数情况下,这些补充内容是对我们48个因素的相同或更详细的描述。我们放弃了这些添加,但在必要时创建了新的因素。补充材料包含新因素的描述,以及我们最初提出的那些因素的更新描述。准研究人员可能有一个新的混合团队问题要开展项目,或者针对因素F15,F16和F19完善或提出更具体的问题细分。
4.6。人口统计学
在Google和National Instruments,既不是一般的人口统计模型,也不是个人附带的变量,在统计上是其绩效得分的重要指标。
为ABB,人口统计模型被证明是显著(˚F = 3 , 406 ,DF =(5 , 131),P <0.007)。性别也是统计上的重要因素(p = 0.007);女性估计自己的生产率比男性高0.83个百分点。其他性别(“其他”)的参与者的评估比男人高1.6点(p = 0.03)。位置(p= 0.04),则公司每增加一年就将其绩效估算提高0.02点。据我们所知,ABB与其他两家公司之间的差异不能解释为什么仅预测了这些人口统计学因素在ABB中的重要性,而在其他任何地方都没有。
4.7。在实践和研究中的应用
如何在实践中使用我们的结果?我们提供了预测生产率中最重要因素的排名列表,可用于对计划进行优先级排序。举措的示例可以在以前的研究论文中找到。
例如,为了提高工作热情,Markos和Sridevi建议通过技术和人际交流研讨会帮助工人专业成长[34]。此外,研究人员建议引入对优秀作品的欣赏实践。例如,ABB正在尝试对开发人员实施公众赞赏,这些开发人员已经实施了用于导航结构化代码的工具和技术[35]。
为了增加对新想法的支持,Brown和Duguid提出了正式和非正式的方法来共享最佳实践[36]。在Google上,知识的单向传播是通过“厕所测试”计划进行的:开发人员编写有关测试或其他区域的简短新闻报道,然后将这些注释张贴在整个公司的厕所中。
为了提高对工作效率的反馈质量,伦敦和史密瑟建议将重点放在非判断性的,基于行为的,可解释的和面向结果的反馈上[37]。在Google上,可以通过无害的验尸获得这些反馈:在重大负面事件(例如服务下降)之后,工程师共同撰写了一份报告,说明了影响问题根源的措施,而没有责怪特定的员工。
根据我们的工作,我们看到了未来研究的几个方向。
首先,对本文讨论的每种生产率因素的影响和证据背景进行特征描述的文章的系统综述,将通过建立因果关系来改善我们工作的可用性。在它们较弱的地方,可以通过进行一系列确定因果关系的实验来提高适用性。
其次,如第4.5和4.6节所述,准研究人员可以使用我们的受访者建议的其他因素,并研究性别和其他人口因素对开发人员生产力的影响。
第三,生产力研究对软件开发的影响可以通过一组多维的指标和工具进行改进,这些指标和工具已通过经验研究和三角剖分得到了验证。
第四,如果研究人员可以计算影响生产力的变化因素的成本,则企业可以做出更明智的投资决策。
4.8。风险性
在解释这项研究的结果时,必须考虑其有效性的若干风险。
4.8.1。数据可靠性风险
首先,我们只讨论一种测量-对您的生产力的评估。还有其他方面,包括客观的衡量标准,例如每天编写的代码行数,Facebook使用的一种方法[38]。正如我们在第3.1节中指出的那样,所有生产率指标都有缺陷,包括测量自己的生产率。例如,由于社会上的偏见,开发人员可能过于轻率地评估了他们的生产力,或者人为地高估了他们的评估[39]。尽管存在这些缺点,但Zelenski领导的团队还是在先前的工作基础上争论了绩效评估的有效性[40],本文也使用了该评估。
其次,我们仅用一个问题来衡量我们的生产力,这个问题几乎无法涵盖开发人员生产力的整个范围。例如,问题集中在频率和强度上,而不考虑质量。我们也没有要求受访者将他们的回答限制在特定的时间范围内,因此一些参与者可能会根据过去一周的经验做出回应,而另一些参与者则会评估他们过去一年的经历。回想起来,这项研究应该以固定的时间间隔进行。
第三,由于问题数量有限,我们仅依靠先前工作中研究的那些因素。我们选择的48个问题可能未涵盖与生产力相关的行为的所有方面。或者,在某些情况下,我们选择的因素可能过于笼统。例如,回想起来,如果我们将工具与方法分开,则与最佳“工具和方法”(F14)相关的因素可能会更有效。
4.8.2。内部可靠性风险
第四,正如我们在3.8节中提到的那样,我们已经利用以前的工作来建立因素与生产率之间的因果关系,但是关系的证据强度可能会有所不同。可能会发现,某些因素只是通过其他因素间接地影响对其生产率的评估,或者它们之间的联系通常具有相反的方向。例如,生产率的主要因素,即对工作的热情(F1)的提高,可能实际上是由于生产率的提高。
4.8.3。可靠性的外部风险
第五,尽管我们研究了三个完全不同的公司,但是与其他类型的公司,其他组织和其他类型的知识工作者的通用性受到限制。在本文中,我们选择了分析师作为非开发人员的代表,但是这一类别包括几种类型的知识工作者:医生,建筑师和律师。可靠性的另一个风险是由于缺乏回应而产生的偏见:回答问卷的人是自行选择的。
第六,我们分别分析了生产率的每个因素,但是许多因素可以相互伴随。这不是分析问题,而是结果的适用性。如果这些因素是相互依存的,那么改变一个因素可能会对另一个因素产生不利影响。
4.8.4。建构
可信度的风险第七,在创建本研究时,我们担心受访者可能认识到我们的分析方法而不是如实回答的可能性。我们试图通过将生产率问题与其影响因素分开来降低这种可能性,但受访者可能已经能够得出有关我们的分析方法的结论。
最后,我们改写了一些问题以使分析适合研究人员,这可能会不希望地改变问题的含义。因此,开发人员和分析人员之间的差异可能是由于问题而不是专业上的差异而引起的。
5.相关工作
许多研究人员已经为软件开发人员研究了个人生产力因素。例如,Moser和Nierstrasz分析了36个软件开发项目,并探讨了面向对象技术对提高开发人员生产力的潜在影响[41]。
另一个例子是DeMarco和Lister对来自35个组织的166位程序员进行的为期一天的编程研究。作者发现工作场所和组织与生产力相关[42]。
第三个例子是Kersten和Murphy与16位开发人员进行的实验室实验。原来,那些使用该工具专注于任务的人比其他人生产力更高[43]。
此外,对Wagner和Rouet的系统分析对单个因素与生产率之间的关系提供了一个很好的想法[14]。由梅耶(Mayer)领导的团队对生产力因素的概述进行了更近期的分析[3]。总的来说,我们的工作是基于对个体因素的这些研究以及对它们的多样性的更广泛研究。
Petersen的系统评价指出,有七篇论文量化了预测软件开发人员生产率的因素[44]。在每项工作中,都使用数值方法进行预测,通常这是回归,我们也在研究中使用了回归。最常见的因素与项目规模有关,在7个因素中,有6个是根据COCOMO II生产率驱动因素([6],[27],[28],[29],[30],[31])明确制定的。 Petersen研究中最复杂的预测模型使用16个因素[6]。
我们的工作有两个主要区别。首先,与以前的工作相比,我们估计了更多的因素(48),并且它们的范围更广。我们根据行业和组织的心理选择因素。其次,我们有不同的分析主题:以前的研究人员研究了在项目框架内可以预测生产力的因素,并且我们对人们的个人生产力感兴趣。
除软件开发外,以前的研究还比较了预测其他行业,特别是工业和组织心理学领域的生产率的因素。尽管这些研究集中于公司一级的生产率[45]和诸如制造业之类的体力劳动[46],但最接近的焦点是知识型工人的生产率。也就是说,人们通常在计算机上积极地在工作中使用知识和信息[47]。在两个主要著作中对这些职业的因素进行了比较。第一个是由Palwalin领导的团队研究,其中涉及先前研究与生产率相比的38个因素。这些因素包括物理,虚拟和社交工作空间,个人工作方法和工作幸福感[4]。第二个是Hernaus和Mikulich对512名知识工作者的研究。作者研究了14个因素,分为三类[9]。在准备我们的研究时,我们依靠这两项工作(第3.2节)。
但是,针对知识型员工的生产率因素进行比较的研究并未关注软件开发人员。这有两个主要原因。首先,尚不清楚将获得的总体结果投射到开发人员的程度。其次,此类研究通常是从开发人员特定的因素中抽象出来的,例如软件重用和代码库复杂性[48]。因此,在理解允许预测开发人员生产率的因素的文献中存在空白。填补这一空白是切实可行的。我们在三个公司中创建了三个研究团队,以提高生产率。弥合这种知识鸿沟有助于我们的团队进行研究,而公司也可以投资于开发人员的生产力。
六,结论
许多因素都会影响开发人员的生产力,但是组织的资源有限,无法专注于提高生产力。我们在三家公司中创建并进行了一项研究,以对不同因素进行排名和比较。开发人员和领导者可以使用我们的发现来确定他们的工作重点。简而言之,以前的论文提出了许多提高软件开发人员生产力的方法,并且我们还建议了如何优先考虑这些方法。

问题块
是什么使开发人员高效?
这份一页纸的匿名研究将花费您15分钟,将帮助我们更好地了解是什么影响了开发人员的工作效率。请坦诚回答。
研究将询问有关您,您的项目和软件的问题。请记住:
我的软件是指您在ABB开发的核心软件,包括产品和基础架构。如果您正在使用其他程序,则仅在主要程序上回答。
我的项目属于创建软件的团队。请回答有关ABB其他软件开发人员的任何相关问题。
一些问题涉及潜在的敏感主题。填写答案,以便没有人可以窥视您的肩膀,并在填写调查表后清除浏览器历史记录和cookie。
请使用以下声明对您的协议进行评分。
研究问题清单





这些问题旨在对可能影响生产率的因素进行全面评估。我们错过了什么吗?
性别(可选)
您的名字是?(可选)
您是哪一年加入ABB的?
附加材料
受访者指出的生产率因素
在本节中,我们列出了受访者在回答开放式问题时所描述的因素。首先,我们将描述几个新因素,然后我们将提供与研究中已经可用的因素相关的因素的描述。我们使用我们的因素在代码中补充了受访者的评论。在这里,我们不讨论或评估人们的答案,也不补充现有因素的描述。
新因素
在评论中,提出了4个主题,这些主题未反映在我们的研究中。六个答复提出了混合项目团队的主题,特别是经理与开发人员的比例;项目中有足够的员工;以及管理层是否能够维持产品的强大所有权。一位受访者指出了这类软件(服务器,客户端,移动设备等)对生产力的影响。另一位注意到生理因素的影响,例如睡眠时间。另一位提到个人成长的机会。
可用因素
F1。五位受访者提到与工作热情相关的因素:两位提到工作动机和认可,一个是道德,另一个是令人沮丧的办公大楼。
F3。四名受访者指出与选择工作方法中的自主权有关的因素。一个提到团队级别的自主权,另一个提到阻止使用良好的开源系统的政策,第三个提到限制公司在团队中使用某些技术的公司采用的优先级。
F4。一位受访者指出,在安排工作时间方面具有自主权,这种自主权仅限于晋升需求所确定的优先事项。
F5。三名受访者指出领导能力。一个人提到领导力时要采用连贯的策略,第二个则是管理层将优先次序相抵触的优先事项,第三个则是员工生产力的管理。
F6。八名受访者表示,他们提供了准确的信息。三位提到了通过文档(和其他渠道)进行跨团队的沟通,另外两位提到了团队目标和计划的明确定义。
F7。两名受访者根据团队和团队的凝聚力对同事表示了积极的看法。
F8。一位受访者指出了工作中的自主权:公司政策规定了可以使用的资源。
F9。一位受访者指出解决冲突的方法,表明队友的个人习惯与社会规范背道而驰。
F10。四名受访者指出了开发商的能力。一个提到了理解代码的困难,另一个提到了对主题领域的了解,第三个提到了对测试态度的严肃性。
F11。一位受访者指出了有关工作效率的反馈:得到同事和管理层,晋升的认可。
F12。一位受访者指出“从我的大脑到发货的产品”软件实施的复杂性。
F13。两名受访者指出了各种任务,特别是代表他们的团队拦截任务和上下文切换。
F14有四位受访者将要求和架构人员评为合格。一个提到对问题的关注不足,另一个提到建筑文档的可读性,第三个提到项目计划的质量,第四个提到“在需求开发中提供了足够的支持”。
F15。 32位受访者报告说使用了最好的工具和方法。十二点提到了工具的性能,特别是构建和测试中的速度和延迟问题。有5个人提到了可用功能,有3个人提到了兼容性和迁移问题,有2个人提到甚至最好的可用工具也可能无法满足需求。关于工具和方法的其他评论提到了工具提供的自动化程度。专业的调试器和模拟器;敏捷方法;片状测试和相关工具;远程工作良好的工具;选择编程语言;过时的工具;将工具的个人偏好与公司采用的工具分开。
F16。 19名答卷者指出人与人之间有足够的知识转移。九个人提到与其他团队沟通的困难:三个-团队之间达成共识的目标,一个-大型团队内部达成共识的目标,另一个-团队之间达成共识。两人指出了在国际或时区团队中协调工作的困难。另外两个提到需要依赖其他团队的文档。两人评论了代码审查的持续时间。另外两个提到了队友的工作设施意识。一个提到了寻找合适的人,另一个提到了互动的延迟,第三个提到了主题领域的工程师和专家之间的沟通。最后,有人提到了明确说明的重要性在某些情况下最好使用哪些沟通渠道。
F18。两名受访者指出了举行会议的方法,其中一位提到会议的有效性取决于会议室的可用性。
F19。 24名受访者指出工作中断和干扰。有十个提到嘈杂的环境,七个表明开放办公室会降低生产力。有四个提到了多任务和上下文切换的困难。另外四个报告说需要集中精力于他们的主要工作或面试等“可选”任务。有两个提到的上下班上下班的困难。
F25。一位受访者指出了代码重用,并指出2-3行API增加了复杂性,而对减少重复的贡献却很小。
F26。一位受访者评论了软件平台的经验,指出当开发人员在项目之间切换时,问题变得更加复杂。
F27。三名受访者指出软件架构和降低风险。有人指出:“产品体系结构的知名度,相互联系的程度,以及它如何支持认识角色,有专心,知道责任和局限以及拥有什么的人们。”另一位代表指出,架构通过模块化可以促进软件组件之间的交换。第三个建议架构应与组织的结构保持一致。
F32。四名受访者提到需要进行上下文切换。两个人提到在项目之间移动时必须进行切换。有人解释说,上下文切换的需求不同于切换的乐趣。另一位代表提到,“生产力项目”本身可能会降低生产力。
F34。五名受访者指出截止日期很紧。一个指出,这助长了技术债务的增长,另一个指出,这样的期限可能导致资源浪费。
F42。三名受访者指出软件的局限性。两人指出了隐私限制,一则指出了关键的安全限制。
F44。11位受访者指出了该软件的复杂性。其中两个提到了遗留代码的特殊复杂性,两个提到了技术债务,每个都提到了版本控制,软件维护和
代码理解。
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.786969 0.111805 24.927 < 0.0000000000000002 ***
log(lines_changed + 1) 0.045189 0.009296 4.861 0.00000122 ***
level -0.050649 0.015833 -3.199 0.00139 **
job_codeENG_TYPE2 0.194108 0.172096 1.128 0.25944
job_codeENG_TYPE3 0.034189 0.076718 0.446 0.65589
job_codeENG_TYPE4 -0.185930 0.084484 -2.201 0.02782 *
job_codeENG_TYPE5 -0.375294 0.085896 -4.369 0.00001285 ***
---
Signif. codes: 0 `***` 0.001 `**` 0.01 `*` 0.05 `.` 0.1 ` ` 1
Residual standard error: 0.8882 on 3388 degrees of freedom
Multiple R-squared: 0.01874, Adjusted R-squared: 0.017
F-statistic: 10.78 on 6 and 3388 DF, p-value: 0.000000000006508
数字:5:模型1:完整的线性回归结果
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.74335 0.09706 28.265 < 0.0000000000000002
log(changelists_created + 1) 0.11220 0.01608 6.977 0.00000000000362
level -0.04999 0.01574 -3.176 0.00151
job_codeENG_TYPE2 0.27044 0.17209 1.571 0.11616
job_codeENG_TYPE3 0.02451 0.07644 0.321 0.74847
job_codeENG_TYPE4 -0.21640 0.08411 -2.573 0.01013
job_codeENG_TYPE5 -0.40194 0.08559 -4.696 0.00000275538534
(Intercept) ***
log(changelists_created + 1) ***
level **
job_codeENG_TYPE2
job_codeENG_TYPE3
job_codeENG_TYPE4 *
job_codeENG_TYPE5 ***
---
Signif. codes: 0 `***` 0.001 `**` 0.01 `*` 0.05 `.` 0.1 ` ` 1
Residual standard error: 0.885 on 3388 degrees of freedom
Multiple R-squared: 0.02589, Adjusted R-squared: 0.02416
F-statistic: 15.01 on 6 and 3388 DF, p-value: < 0.00000000000000022
数字:6:模型2:完整的线性回归结果
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.79676 0.11141 25.102 < 0.0000000000000002
log(lines_changed + 1) -0.01462 0.01498 -0.976 0.32897
log(changelists_created + 1) 0.13215 0.02600 5.082 0.000000394
level -0.05099 0.01578 -3.233 0.00124
job_codeENG_TYPE2 0.27767 0.17226 1.612 0.10706
job_codeENG_TYPE3 0.02226 0.07647 0.291 0.77102
job_codeENG_TYPE4 -0.22446 0.08452 -2.656 0.00795
job_codeENG_TYPE5 -0.40819 0.08583 -4.756 0.000002057
(Intercept) ***
log(lines_changed + 1)
log(changelists_created + 1) ***
level **
job_codeENG_TYPE2
job_codeENG_TYPE3
job_codeENG_TYPE4 **
job_codeENG_TYPE5 ***
---
Signif. codes: 0 `***` 0.001 `**` 0.01 `*` 0.05 `.` 0.1 ` ` 1
Residual standard error: 0.885 on 3387 degrees of freedom
Multiple R-squared: 0.02616, Adjusted R-squared: 0.02415
F-statistic: 13 on 7 and 3387 DF, p-value: < 0.00000000000000022
数字:7:模型3:完整的线性回归结果。
参考书目
[1] R. S. Nickerson, “Confirmation bias: A ubiquitous phenomenon in many guises.” Review of general psychology, vol. 2, no. 2, p. 175, 1998.
[2] Y. W. Ramírez and D. A. Nembhard, “Measuring knowledge worker productivity: A taxonomy,” Journal of Intellectual Capital, vol. 5, no. 4, pp. 602–628, 2004.
[3] A. N. Meyer, L. E. Barton, G. C. Murphy, T. Zimmermann, and T. Fritz, “The work life of developers: Activities, switches and perceived productivity,” IEEE Transactions on Software Engineering, 2017.
[4] M. Palvalin, M. Vuolle, A. Jääskeläinen, H. Laihonen, and A. Lönnqvist, “Smartwow–constructing a tool for knowledge work performance analysis,” International Journal of Productivity and Performance Management, vol. 64, no. 4, pp. 479–498, 2015.
[5] C. H. C. Duarte, “Productivity paradoxes revisited,” Empirical Software Engineering, pp. 1–30, 2016.
[6] K. D. Maxwell, L. VanWassenhove, and S. Dutta, “Software development productivity of european space, military, and industrial applications,” IEEE Transactions on Software Engineering, vol. 22, no. 10, pp. 706–718, 1996.
[7] J. D. Blackburn, G. D. Scudder, and L. N. Van Wassenhove, “Improving speed and productivity of software development: a global survey of software developers,” IEEE transactions on software engineering, vol. 22, no. 12, pp. 875–885, 1996.
[8] B. Vasilescu, Y. Yu, H.Wang, P. Devanbu, and V. Filkov, “Quality and productivity outcomes relating to continuous integration in github,” in Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. ACM, 2015, pp. 805–816.
[9] T. Hernaus and J. Mikulic, “Work characteristics and work performance of knowledge workers,” EuroMed Journal of Business, vol. 9, no. 3, pp. 268–292, 2014.
[10] F. P. Morgeson and S. E. Humphrey, “The work design questionnaire (wdq): developing and validating a comprehensive measure for assessing job design and the nature of work.” Journal of applied psychology, vol. 91, no. 6, p. 1321, 2006.
[11] J. R. Idaszak and F. Drasgow, “A revision of the job diagnostic survey: Elimination of a measurement artifact.” Journal of Applied Psychology, vol. 72, no. 1, p. 69, 1987.
[12] M. A. Campion, G. J. Medsker, and A. C. Higgs, “Relations between work group characteristics and effectiveness: Implications for designing effective work groups,” Personnel psychology, vol. 46, no. 4, pp. 823–847, 1993.
[13] T. Hernaus, “Integrating macro-and micro-organizational variables through multilevel approach,” Unpublished doctoral thesis). Zagreb: University of Zagreb, 2010.
[14] S. Wagner and M. Ruhe, “A systematic review of productivity factors in software development,” in Proceedings of 2nd International Workshop on Software Productivity Analysis and Cost Estimation, 2008.
[15] A. N. Meyer, T. Fritz, G. C. Murphy, and T. Zimmermann, “Software developers’ perceptions of productivity,” in Proceedings of the International Symposium on Foundations of Software Engineering. ACM, 2014, pp. 19–29.
[16] R. Antikainen and A. Lönnqvist, “Knowledge work productivity assessment,” Tampere University of Technology, Tech. Rep., 2006.
[17] M. Galesic and M. Bosnjak, “Effects of questionnaire length on participation and indicators of response quality in a web survey,” Public opinion quarterly, vol. 73, no. 2, pp. 349–360, 2009.
[18] L. Beckwith, C. Kissinger, M. Burnett, S. Wiedenbeck, J. Lawrance, A. Blackwell, and C. Cook, “Tinkering and gender in end-user programmers’ debugging,” in Proceedings of the SIGCHI conference on Human Factors in computing systems. ACM, 2006, pp. 231–240.
[19] D. B. Rubin, Multiple imputation for nonresponse in surveys. John Wiley & Sons, 2004, vol. 81.
[20] A. W. Meade and S. B. Craig, “Identifying careless responses in survey data.” Psychological methods, vol. 17, no. 3, p. 437, 2012.
[21] E. Smith, R. Loftin, E. Murphy-Hill, C. Bird, and T. Zimmermann, “Improving developer participation rates in surveys,” in Proceedings of Cooperative and Human Aspects on Software Engineering, 2013.
[22] Y. Benjamini and Y. Hochberg, “Controlling the false discovery rate: a practical and powerful approach to multiple testing,” Journal of the royal statistical society. Series B (Methodological),
pp. 289–300, 1995.
[23] R. A. Guzzo, R. D. Jette, and R. A. Katzell, “The effects of psychologically based intervention programs on worker productivity: A meta-analysis,” Personnel psychology, vol. 38, no. 2, pp.
275–291, 1985.
[24] D. Graziotin, X. Wang, and P. Abrahamsson, “Happy software developers solve problems better: psychological measurements in empirical software engineering,” PeerJ, vol. 2, p. e289, 2014.
[25] J. Noll, M. A. Razzak, and S. Beecham, “Motivation and autonomy in global software development: an empirical study,” in Proceedings of the 21st International Conference on Evaluation
and Assessment in Software Engineering. ACM, 2017, pp. 394–399.
[26] B. Clark, S. Devnani-Chulani, and B. Boehm, “Calibrating the cocomo ii post-architecture model,” in Proceedings of the International Conference on Software Engineering. IEEE, 1998, pp. 477–480.
[27] B. Kitchenham and E. Mendes, “Software productivity measurement using multiple size measures,” IEEE Transactions on Software Engineering, vol. 30, no. 12, pp. 1023–1035, 2004.
[28] S. L. Pfleeger, “Model of software effort and productivity,” Information and Software Technology, vol. 33, no. 3, pp. 224–231, 1991.
[29] G. Finnie and G. Wittig, “Effect of system and team size on 4gl software development productivity,” South African Computer Journal, pp. 18–18, 1994.
[30] D. R. Jeffery, “A software development productivity model for mis environments,” Journal of Systems and Software, vol. 7, no. 2, pp. 115–125, 1987.
[31] L. R. Foulds, M. Quaddus, and M. West, “Structural equation modelling of large-scale information system application development productivity: the hong kong experience,” in Computer and Information Science, 2007. ICIS 2007. 6th IEEE/ACIS International Conference on. IEEE, 2007, pp. 724–731.
[32] C. Parnin and S. Rugaber, “Resumption strategies for interrupted programming tasks,” Software Quality Journal, vol. 19, no. 1, pp. 5–34, 2011.
[33] C. Parnin and R. DeLine, “Evaluating cues for resuming interrupted programming tasks,” in Proceedings of the SIGCHI conference on human factors in computing systems. ACM, 2010, pp. 93–102.
[34] S. Markos and M. S. Sridevi, “Employee engagement: The key to improving performance,” International Journal of Business and Management, vol. 5, no. 12, pp. 89–96, 2010.
[35] W. Snipes, A. R. Nair, and E. Murphy-Hill, “Experiences gamifying developer adoption of practices and tools,” in Companion Proceedings of the 36th International Conference on Software Engineering. ACM, 2014, pp. 105–114.
[36] J. S. Brown and P. Duguid, “Balancing act: How to capture knowledge without killing it.” Harvard business review, vol. 78, no. 3, pp. 73–80, 1999.
[37] M. London and J. W. Smither, “Feedback orientation, feedback culture, and the longitudinal performance management process,” Human Resource Management Review, vol. 12, no. 1,
pp. 81–100, 2002.
[38] T. Savor, M. Douglas, M. Gentili, L. Williams, K. Beck, and M. Stumm, “Continuous deployment at facebook and oanda,” in Proceedings of the 38th International Conference on Software Engineering Companion. ACM, 2016, pp. 21–30.
[39] R. J. Fisher, “Social desirability bias and the validity of indirect questioning,” Journal of consumer research, vol. 20, no. 2, pp. 303–315, 1993.
[40] J. M. Zelenski, S. A. Murphy, and D. A. Jenkins, “The happyproductive worker thesis revisited,” Journal of Happiness Studies, vol. 9, no. 4, pp. 521–537, 2008.
[41] S. Moser and O. Nierstrasz, “The effect of object-oriented frameworks on developer productivity,” Computer, vol. 29, no. 9, pp. 45–51, 1996.
[42] T. DeMarco and T. Lister, “Programmer performance and the effects of the workplace,” in Proceedings of the International Conference on Software Engineering. IEEE Computer Society
Press, 1985, pp. 268–272.
[43] M. Kersten and G. C. Murphy, “Using task context to improve programmer productivity,” in Proceedings of the 14th ACM SIGSOFT international symposium on Foundations of software engineering. ACM, 2006, pp. 1–11.
[44] K. Petersen, “Measuring and predicting software productivity: A systematic map and review,” Information and Software Technology, vol. 53, no. 4, pp. 317–343, 2011.
[45] M. J. Melitz, “The impact of trade on intra-industry reallocations and aggregate industry productivity,” Econometrica, vol. 71, no. 6, pp. 1695–1725, 2003.
[46] M. N. Baily, C. Hulten, D. Campbell, T. Bresnahan, and R. E. Caves, “Productivity dynamics in manufacturing plants,” Brookings papers on economic activity. Microeconomics, vol. 1992, pp. 187–267, 1992.
[47] A. Kidd, “The marks are on the knowledge worker,” in Proceedings of the SIGCHI conference on Human factors in computing systems. ACM, 1994, pp. 186–191.
[48] G. K. Gill and C. F. Kemerer, “Cyclomatic complexity density and software maintenance productivity,” IEEE transactions on software engineering, vol. 17, no. 12, pp. 1284–1288, 1991.
[2] Y. W. Ramírez and D. A. Nembhard, “Measuring knowledge worker productivity: A taxonomy,” Journal of Intellectual Capital, vol. 5, no. 4, pp. 602–628, 2004.
[3] A. N. Meyer, L. E. Barton, G. C. Murphy, T. Zimmermann, and T. Fritz, “The work life of developers: Activities, switches and perceived productivity,” IEEE Transactions on Software Engineering, 2017.
[4] M. Palvalin, M. Vuolle, A. Jääskeläinen, H. Laihonen, and A. Lönnqvist, “Smartwow–constructing a tool for knowledge work performance analysis,” International Journal of Productivity and Performance Management, vol. 64, no. 4, pp. 479–498, 2015.
[5] C. H. C. Duarte, “Productivity paradoxes revisited,” Empirical Software Engineering, pp. 1–30, 2016.
[6] K. D. Maxwell, L. VanWassenhove, and S. Dutta, “Software development productivity of european space, military, and industrial applications,” IEEE Transactions on Software Engineering, vol. 22, no. 10, pp. 706–718, 1996.
[7] J. D. Blackburn, G. D. Scudder, and L. N. Van Wassenhove, “Improving speed and productivity of software development: a global survey of software developers,” IEEE transactions on software engineering, vol. 22, no. 12, pp. 875–885, 1996.
[8] B. Vasilescu, Y. Yu, H.Wang, P. Devanbu, and V. Filkov, “Quality and productivity outcomes relating to continuous integration in github,” in Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. ACM, 2015, pp. 805–816.
[9] T. Hernaus and J. Mikulic, “Work characteristics and work performance of knowledge workers,” EuroMed Journal of Business, vol. 9, no. 3, pp. 268–292, 2014.
[10] F. P. Morgeson and S. E. Humphrey, “The work design questionnaire (wdq): developing and validating a comprehensive measure for assessing job design and the nature of work.” Journal of applied psychology, vol. 91, no. 6, p. 1321, 2006.
[11] J. R. Idaszak and F. Drasgow, “A revision of the job diagnostic survey: Elimination of a measurement artifact.” Journal of Applied Psychology, vol. 72, no. 1, p. 69, 1987.
[12] M. A. Campion, G. J. Medsker, and A. C. Higgs, “Relations between work group characteristics and effectiveness: Implications for designing effective work groups,” Personnel psychology, vol. 46, no. 4, pp. 823–847, 1993.
[13] T. Hernaus, “Integrating macro-and micro-organizational variables through multilevel approach,” Unpublished doctoral thesis). Zagreb: University of Zagreb, 2010.
[14] S. Wagner and M. Ruhe, “A systematic review of productivity factors in software development,” in Proceedings of 2nd International Workshop on Software Productivity Analysis and Cost Estimation, 2008.
[15] A. N. Meyer, T. Fritz, G. C. Murphy, and T. Zimmermann, “Software developers’ perceptions of productivity,” in Proceedings of the International Symposium on Foundations of Software Engineering. ACM, 2014, pp. 19–29.
[16] R. Antikainen and A. Lönnqvist, “Knowledge work productivity assessment,” Tampere University of Technology, Tech. Rep., 2006.
[17] M. Galesic and M. Bosnjak, “Effects of questionnaire length on participation and indicators of response quality in a web survey,” Public opinion quarterly, vol. 73, no. 2, pp. 349–360, 2009.
[18] L. Beckwith, C. Kissinger, M. Burnett, S. Wiedenbeck, J. Lawrance, A. Blackwell, and C. Cook, “Tinkering and gender in end-user programmers’ debugging,” in Proceedings of the SIGCHI conference on Human Factors in computing systems. ACM, 2006, pp. 231–240.
[19] D. B. Rubin, Multiple imputation for nonresponse in surveys. John Wiley & Sons, 2004, vol. 81.
[20] A. W. Meade and S. B. Craig, “Identifying careless responses in survey data.” Psychological methods, vol. 17, no. 3, p. 437, 2012.
[21] E. Smith, R. Loftin, E. Murphy-Hill, C. Bird, and T. Zimmermann, “Improving developer participation rates in surveys,” in Proceedings of Cooperative and Human Aspects on Software Engineering, 2013.
[22] Y. Benjamini and Y. Hochberg, “Controlling the false discovery rate: a practical and powerful approach to multiple testing,” Journal of the royal statistical society. Series B (Methodological),
pp. 289–300, 1995.
[23] R. A. Guzzo, R. D. Jette, and R. A. Katzell, “The effects of psychologically based intervention programs on worker productivity: A meta-analysis,” Personnel psychology, vol. 38, no. 2, pp.
275–291, 1985.
[24] D. Graziotin, X. Wang, and P. Abrahamsson, “Happy software developers solve problems better: psychological measurements in empirical software engineering,” PeerJ, vol. 2, p. e289, 2014.
[25] J. Noll, M. A. Razzak, and S. Beecham, “Motivation and autonomy in global software development: an empirical study,” in Proceedings of the 21st International Conference on Evaluation
and Assessment in Software Engineering. ACM, 2017, pp. 394–399.
[26] B. Clark, S. Devnani-Chulani, and B. Boehm, “Calibrating the cocomo ii post-architecture model,” in Proceedings of the International Conference on Software Engineering. IEEE, 1998, pp. 477–480.
[27] B. Kitchenham and E. Mendes, “Software productivity measurement using multiple size measures,” IEEE Transactions on Software Engineering, vol. 30, no. 12, pp. 1023–1035, 2004.
[28] S. L. Pfleeger, “Model of software effort and productivity,” Information and Software Technology, vol. 33, no. 3, pp. 224–231, 1991.
[29] G. Finnie and G. Wittig, “Effect of system and team size on 4gl software development productivity,” South African Computer Journal, pp. 18–18, 1994.
[30] D. R. Jeffery, “A software development productivity model for mis environments,” Journal of Systems and Software, vol. 7, no. 2, pp. 115–125, 1987.
[31] L. R. Foulds, M. Quaddus, and M. West, “Structural equation modelling of large-scale information system application development productivity: the hong kong experience,” in Computer and Information Science, 2007. ICIS 2007. 6th IEEE/ACIS International Conference on. IEEE, 2007, pp. 724–731.
[32] C. Parnin and S. Rugaber, “Resumption strategies for interrupted programming tasks,” Software Quality Journal, vol. 19, no. 1, pp. 5–34, 2011.
[33] C. Parnin and R. DeLine, “Evaluating cues for resuming interrupted programming tasks,” in Proceedings of the SIGCHI conference on human factors in computing systems. ACM, 2010, pp. 93–102.
[34] S. Markos and M. S. Sridevi, “Employee engagement: The key to improving performance,” International Journal of Business and Management, vol. 5, no. 12, pp. 89–96, 2010.
[35] W. Snipes, A. R. Nair, and E. Murphy-Hill, “Experiences gamifying developer adoption of practices and tools,” in Companion Proceedings of the 36th International Conference on Software Engineering. ACM, 2014, pp. 105–114.
[36] J. S. Brown and P. Duguid, “Balancing act: How to capture knowledge without killing it.” Harvard business review, vol. 78, no. 3, pp. 73–80, 1999.
[37] M. London and J. W. Smither, “Feedback orientation, feedback culture, and the longitudinal performance management process,” Human Resource Management Review, vol. 12, no. 1,
pp. 81–100, 2002.
[38] T. Savor, M. Douglas, M. Gentili, L. Williams, K. Beck, and M. Stumm, “Continuous deployment at facebook and oanda,” in Proceedings of the 38th International Conference on Software Engineering Companion. ACM, 2016, pp. 21–30.
[39] R. J. Fisher, “Social desirability bias and the validity of indirect questioning,” Journal of consumer research, vol. 20, no. 2, pp. 303–315, 1993.
[40] J. M. Zelenski, S. A. Murphy, and D. A. Jenkins, “The happyproductive worker thesis revisited,” Journal of Happiness Studies, vol. 9, no. 4, pp. 521–537, 2008.
[41] S. Moser and O. Nierstrasz, “The effect of object-oriented frameworks on developer productivity,” Computer, vol. 29, no. 9, pp. 45–51, 1996.
[42] T. DeMarco and T. Lister, “Programmer performance and the effects of the workplace,” in Proceedings of the International Conference on Software Engineering. IEEE Computer Society
Press, 1985, pp. 268–272.
[43] M. Kersten and G. C. Murphy, “Using task context to improve programmer productivity,” in Proceedings of the 14th ACM SIGSOFT international symposium on Foundations of software engineering. ACM, 2006, pp. 1–11.
[44] K. Petersen, “Measuring and predicting software productivity: A systematic map and review,” Information and Software Technology, vol. 53, no. 4, pp. 317–343, 2011.
[45] M. J. Melitz, “The impact of trade on intra-industry reallocations and aggregate industry productivity,” Econometrica, vol. 71, no. 6, pp. 1695–1725, 2003.
[46] M. N. Baily, C. Hulten, D. Campbell, T. Bresnahan, and R. E. Caves, “Productivity dynamics in manufacturing plants,” Brookings papers on economic activity. Microeconomics, vol. 1992, pp. 187–267, 1992.
[47] A. Kidd, “The marks are on the knowledge worker,” in Proceedings of the SIGCHI conference on Human factors in computing systems. ACM, 1994, pp. 186–191.
[48] G. K. Gill and C. F. Kemerer, “Cyclomatic complexity density and software maintenance productivity,” IEEE transactions on software engineering, vol. 17, no. 12, pp. 1284–1288, 1991.