
越来越多的客户收到以下请求:“我们希望像Amazon RDS一样,但价格更便宜”;“我们希望它像RDS一样,但在任何基础架构中的任何地方都一样。” 为了在Kubernetes上实现这样的托管解决方案,我们查看了PostgreSQL最受欢迎的运算符(Stolon,来自Crunchy Data和Zalando的运算符)的当前状态,并做出了选择。
本文是我们从理论角度(对解决方案的回顾)和从实践角度(选择了什么以及从中得出的结果)的经验。但是首先,让我们确定可能替代RDS的一般要求是什么...
什么是RDS
当人们谈论RDS时,根据我们的经验,他们指的是一种托管DBMS服务:
- 易于定制;
- 具有处理快照并从快照中恢复的能力(最好是在PITR支持下);
- 允许您创建主从拓扑;
- 有丰富的扩展列表;
- 提供审核和用户/访问管理。
一般而言,执行任务的方法可以有很大不同,但是有条件Ansible的道路离我们很近。(2GIS的同事试图创建“基于Postgres的快速部署故障转移群集的工具” ,从而得出了类似的结论。)
运营商是解决Kubernetes生态系统中此类问题的公认方法。Flant技术部门已经告知了有关它们在Kubernetes中运行的数据库的更多详细信息,迪斯托尔,在他的一份报告中。
注意:为了快速创建简单的运算符,我们建议您注意我们的开源shell-operator实用程序。使用它,您可以在不了解Go的情况下执行此操作,但是可以使用系统管理员更熟悉的方式:Bash,Python等。
PostgreSQL有几种流行的K8s运算符:
- 斯托隆;
- 松散数据PostgreSQL运算符;
- Zalando Postgres运算符。
让我们仔细看看它们。
操作员选择
除了上面已经提到的重要功能外,作为Kubernetes的基础架构运营工程师,我们还期望运营商提供以下服务:
- 从Git和定制资源部署;
- 吊舱反亲和力支持;
- 安装节点亲缘关系或节点选择器;
- 设定容忍度;
- 是否有调优机会;
- 可理解的技术甚至命令。
在没有详细介绍每个要点的情况下(如果在阅读整篇文章后有任何疑问,请在评论中提问),我通常会注意到,对于集群节点的专业性的更精细的描述,需要这些参数才能对特定的应用程序进行排序。这样,我们可以在性能和成本之间实现最佳平衡。
现在是PostgreSQL运算符本身。
1.斯托隆
匍匐茎从意大利公司Sorint.lab中已经提到的报告被认为是运营商之间的DBMS一定的标准。这是一个相当老的项目:它的首次公开发布于2015年11月(!),而GitHub存储库拥有近3000个星星和40多个贡献者。
实际上,Stolon是经过深思熟虑的体系结构的一个很好的例子:
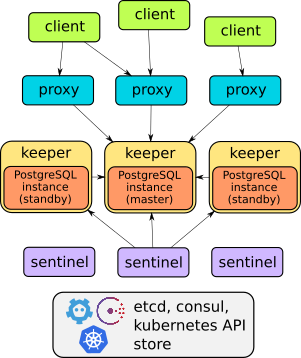
该操作员设备的详细信息可以在报告或项目文档中找到。通常,只要说他可以完成所描述的一切即可:故障转移,用于透明客户端访问的代理,备份...此外,代理通过一个端点服务提供访问权限-与进一步考虑的其他两种解决方案不同(它们有两种用于访问的服务)基础)。
但是,Stolon没有“自定义资源”,这就是为什么不能以“像热蛋糕”那样在Kubernetes中轻松,快速地创建DBMS实例的方式部署它的原因。通过实用程序进行管理
stolonctl,通过Helm-chart进行部署,并在ConfigMap中定义用户设置。
一方面,事实证明操作员不是非常多的操作员(毕竟,它不使用CRD)。但另一方面,它是一个灵活的系统,可让您以自己喜欢的方式自定义K8s中的资源。
总而言之,对于我们个人而言,这似乎并不是为每个数据库创建单独图表的最佳方法。因此,我们开始寻找替代方案。
2.松散的数据PostgreSQL运算符
一家年轻的美国初创公司Crunchy Data的运营商看起来很合乎逻辑。它的公开历史始于2017年3月的第一个版本,此后GitHub存储库收到了将近1300星和50多个贡献者的信息。经过测试,9月以来的最新版本可与Kubernetes 1.15-1.18,OpenShift 3.11+和4.4 +,GKE和VMware Enterprise PKS 1.3+一起使用。
Crunchy Data PostgreSQL Operator架构还满足以下要求:
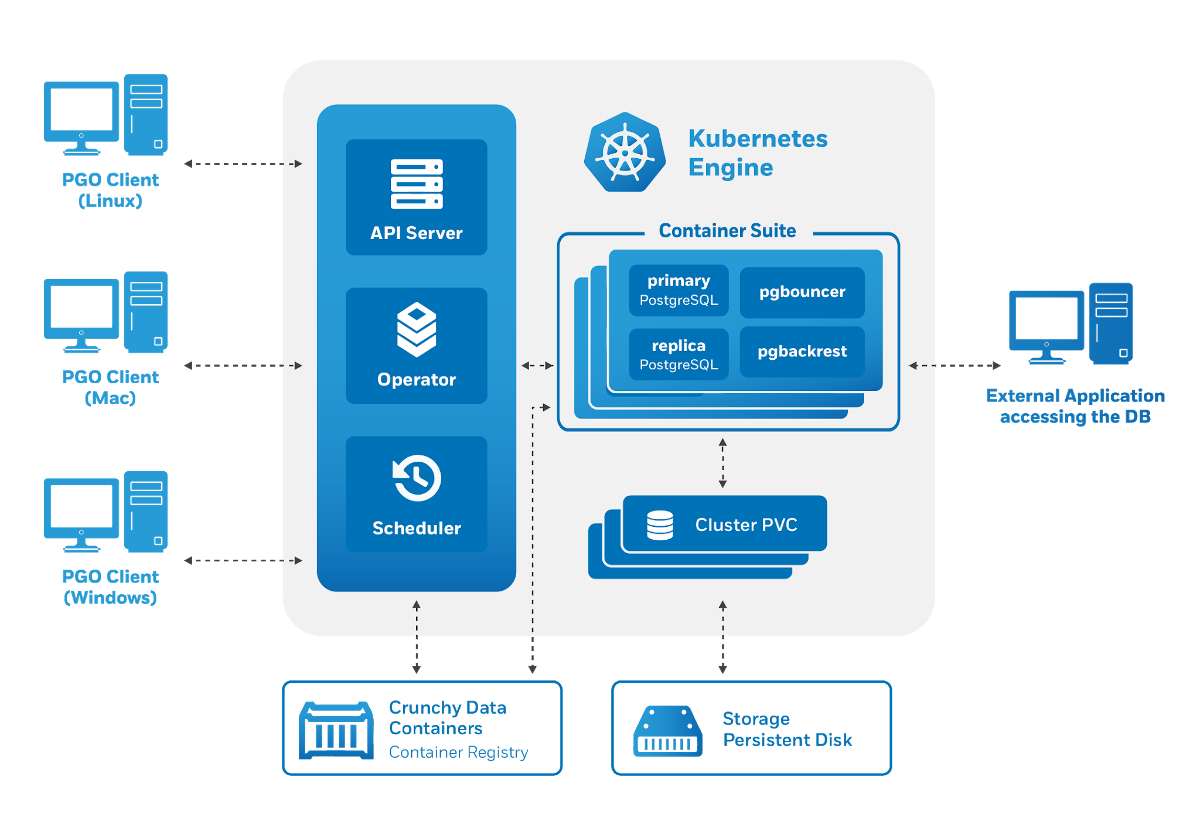
通过实用程序进行管理
pgo,但是反过来,它会为Kubernetes生成自定义资源。因此,运营商希望我们成为潜在用户:
- 通过CRD进行控制;
- 方便的用户管理(也通过CRD);
- 与Crunchy Data Container Suite的其他组件集成-用于PostgreSQL的容器图像的专用集合以及使用它的实用程序(包括pgBackRest,pgAudit,contrib扩展等)。
但是,尝试从Crunchy Data开始使用运算符时发现了一些问题:
- 没有容忍的可能性-仅提供了nodeSelector。
- 即使我们部署了有状态的应用程序,我们创建的Pod还是Deployment的一部分。与StatefulSets不同,Deployment无法创建磁盘。
最后一个缺点导致了有趣的时刻:在测试环境中,可以使用一个本地存储磁盘运行3个副本,因此操作员报告3个副本正在工作(尽管并非如此)。
该操作员的另一个特点是与各种辅助系统的现成集成。例如,安装pgAdmin和pgBounce很容易,并且文档涵盖了预先配置的Grafana和Prometheus。最新版本4.5.0-beta1分别指出了与pgMonitor项目的改进的集成,因此,操作员可以直接使用可视化的方式查看PgSQL的指标。
但是,生成的Kubernetes资源的奇怪选择使我们找到了另一种解决方案。
3. Zalando Postgres运算符
我们已经知道Zalando产品很长时间:我们使用Zalenium经验,当然,我们试图佩特罗尼-对PostgreSQL其受欢迎的高可用性解决方案。其作者之一Aleksey Klyukin谈到了该公司在Postgres-星期二#5上创建Postgres Operator的方法,我们对此很满意。 这是本文中讨论的最年轻的解决方案:第一个版本于2018年8月发布。但是,尽管正式发布的数量很少,但该项目已经走了很长一段路,已经超过了Crunchy Data解决方案的普及程度,该解决方案在GitHub上有1300多个星级,贡献者数量最多(超过70个)。 在该操作员的支持下,使用了久经考验的解决方案:
- Patroni和Spilo用于控制,
- WAL-E-用于备份,
- PgBouncer-作为连接池。
Zalando的操作员体系结构就是这样呈现的:
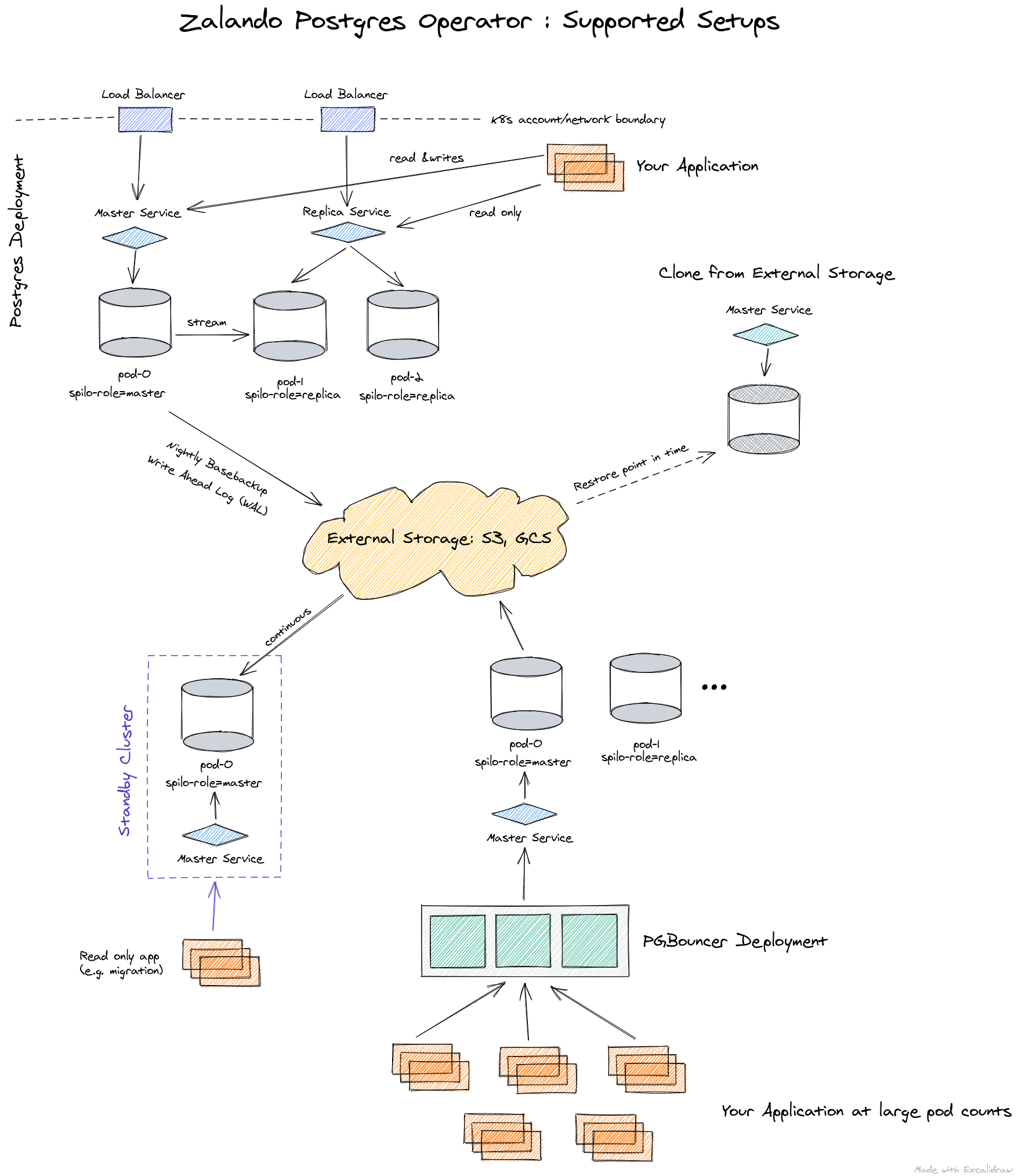
通过“自定义资源”对操作员进行全面管理,从容器自动创建StatefulSet,然后可以通过向吊舱添加各种边车进行自定义。与Crunchy Data的运营商相比,所有这些都是一个重要的优势。
由于是Zalando的解决方案,我们在考虑的三个选项中选择了一个,因此下面将在应用实践的同时,立即介绍其功能。
与Zalando的Postgres运算符一起练习
部署操作员非常简单:只需从GitHub下载当前版本,然后从manifests目录应用YAML文件。或者,您也可以使用OperatorHub。
安装后,您应该担心为日志和备份设置存储。这是通过
postgres-operator安装语句的名称空间中的ConfigMap完成的。配置了存储库后,您可以部署第一个PostgreSQL集群。
例如,我们的标准部署如下所示:
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: staging-db
spec:
numberOfInstances: 3
patroni:
synchronous_mode: true
postgresql:
version: "12"
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
sidecars:
- env:
- name: DATA_SOURCE_URI
value: 127.0.0.1:5432
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
key: password
name: postgres.staging-db.credentials
- name: DATA_SOURCE_USER
value: postgres
image: wrouesnel/postgres_exporter
name: prometheus-exporter
resources:
limits:
cpu: 500m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
teamId: staging
volume:
size: 2Gi
此清单以postgres_exporter的形式部署了一个带有sidecar的3个实例的集群,我们从中获取应用程序指标。如您所见,一切都非常简单,并且您可以根据需要创建无限数量的集群。
这是值得关注的网络管理面板- Postgres的运营商的用户界面。它随操作员一起提供,允许您创建和删除群集,以及使用操作员进行的备份。
PostgreSQL群集列表
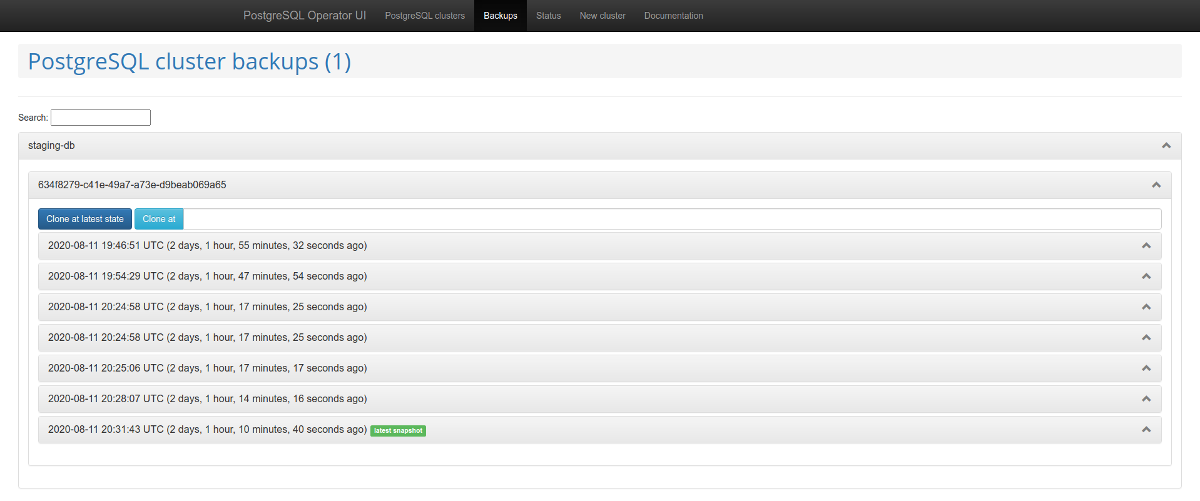
备份管理
另一个有趣的功能是Teams API支持。该机制在PostgreSQL中自动创建角色根据用户名的结果列表。之后,API允许您返回为其自动创建角色的用户列表。
问题与解决方案
但是,使用该运算符很快显示出几个明显的缺点:
- 缺乏对nodeSelector的支持;
- 无法禁用备份;
- 使用数据库创建功能时,默认权限不会出现;
- 周期性地没有足够的文档或文档已过期。
幸运的是,其中许多问题都可以解决。让我们从最后开始-文档问题。
您很可能会遇到一个事实,即并不总是很清楚如何注册备份以及如何将备份存储桶连接到Operator UI。该文档顺便谈到了这一点,但真正的描述在PR中:
- 您需要保密;
-
pod_environment_secret_nameCRD ConfigMap ( , ).
但是,事实证明,这目前是不可能的。这就是为什么我们将自己的运营商版本与一些其他第三方开发放在一起。请参阅下面的更多细节。
如果您将备份的参数(即
wal_s3_bucketAWS S3中的访问密钥)传递给操作员,那么他将备份所有内容:不仅是生产中的基础,而且还包括登台。它不适合我们。
在Spilo的参数说明中,它是使用运算符时PgSQL的基本Docker包装器,事实证明您可以将参数传递为
WAL_S3_BUCKET空,从而禁用备份。此外,非常高兴的是,发现了现成的PR,我们立即将其接受到我们的分叉中。现在,只需将enableWALArchiving: falsePostgreSQL集群添加到资源中就足够了。
是的,有机会通过运行两个操作员来进行不同的操作:一个操作员用于暂存(无备份),第二个操作员用于生产。但是,我们能够与他人融洽相处。
好的,我们学习了如何转移对S3数据库的访问权限,并且备份开始进入存储。如何使备份页面在Operator UI中工作?

在Operator UI中,您需要添加3个变量:
-
SPILO_S3_BACKUP_BUCKET -
AWS_ACCESS_KEY_ID -
AWS_SECRET_ACCESS_KEY
之后,将可以管理备份,在我们的情况下,这将简化登台工作,使您无需额外的脚本即可从生产环境中交付片。
另一个优点是与Teams API一起工作,以及使用操作员工具创建数据库和角色的广泛可能性。但是,创建的角色没有默认权限。因此,具有读取权限的用户无法读取新表。
这是为什么?尽管该代码包含必需的代码
GRANT,但并非始终使用它们。有2种方法:syncPreparedDatabases和syncDatabases。 B-syncPreparedDatabases尽管该部分中preparedDatabases 存在条件,defaultRoles并且defaultUsers要创建角色,不会应用默认权限。我们正在准备补丁程序,以便自动应用这些权利。
与我们相关的改进的最后一刻是一个补丁,该补丁将Node Affinity添加到创建的StatefulSet中。我们的客户通常更喜欢通过使用竞价型实例来降低成本,并且他们显然不应该托管数据库服务。这个问题可以通过容忍来解决,但是Node Affinity的存在给人很大的信心。
发生了什么?
解决上述问题的结果是,我们将Zagredo的Postgres Operator分叉到我们的存储库中,并在其中存储了有用的补丁程序。为了方便起见,我们还组装了一个Docker映像。
分叉的PR列表:
如果社区支持这些PR,那么它们将成为下一版运营商(1.6)的上游,那就太好了。
奖金!生产迁移成功案例
如果您使用的是Patroni,则可以在最少的停机时间内将现场制作迁移到操作员。当PgSQL二进制日志首先保存到S3,然后由副本下载时,
Spilo允许您使用Wal-E通过S3存储创建备用群集。但是,如果您的旧基础架构中没有Wal-E,该怎么办?哈布雷已经提出了解决这个问题的方案。
PostgreSQL逻辑复制可以解决。但是,由于我们的计划失败,因此我们不会详细介绍如何创建发布和订阅。
事实是,数据库中有几个已装载的表,其中包含数百万行,而且这些表会不断地被补充和删除。简单的订阅与
copy_data,当新副本从母版复制所有内容时,它根本跟不上母版。复制内容可以使用一周,但从未赶上母版。结果,来自Avito同事的一篇文章帮助解决了这个问题:您可以使用来传输数据pg_dump。我将描述此算法的(略作修改的)版本。
这个想法是,您可以将订阅关闭并绑定到特定的复制插槽,然后确定交易号。有用于生产工作的复制品。这很重要,因为副本将帮助创建一致的转储并继续接收来自主服务器的更改。
在以下描述迁移过程的命令中,将使用以下主机符号:
- 主服务器-源服务器;
- 副本1-旧产品上的流副本;
- copy2是一个新的逻辑副本。
迁移计划
1.在向导中,创建对
public数据库模式中所有表的预订dbname:
psql -h master -d dbname -c "CREATE PUBLICATION dbname FOR ALL TABLES;"
2.让我们在主服务器上创建一个复制插槽:
psql -h master -c "select pg_create_logical_replication_slot('repl', 'pgoutput');"
3.停止在旧副本上进行复制:
psql -h replica1 -c "select pg_wal_replay_pause();"
4.从主数据库获取交易号:
psql -h master -c "select replay_lsn from pg_stat_replication where client_addr = 'replica1';"
5.转储旧副本。我们将在多个线程中执行此操作,这将有助于加快流程:
pg_dump -h replica1 --no-publications --no-subscriptions -O -C -F d -j 8 -f dump/ dbname
6.将转储上传到新服务器:
pg_restore -h replica2 -F d -j 8 -d dbname dump/
7.下载转储后,您可以在流复制副本上开始复制:
psql -h replica1 -c "select pg_wal_replay_resume();"
7.让我们在新的逻辑副本上创建预订:
psql -h replica2 -c "create subscription oldprod connection 'host=replica1 port=5432 user=postgres password=secret dbname=dbname' publication dbname with (enabled = false, create_slot = false, copy_data = false, slot_name='repl');"
8.获取
oid订阅:
psql -h replica2 -d dbname -c "select oid, * from pg_subscription;"
9.假设它已收到
oid=1000。让我们将交易编号应用于订阅:
psql -h replica2 -d dbname -c "select pg_replication_origin_advance('pg_1000', 'AA/AAAAAAAA');"
10.让我们开始复制:
psql -h replica2 -d dbname -c "alter subscription oldprod enable;"
11.检查订阅状态,复制应该可以工作:
psql -h replica2 -d dbname -c "select * from pg_replication_origin_status;"
psql -h master -d dbname -c "select slot_name, restart_lsn, confirmed_flush_lsn from pg_replication_slots;"
12.复制开始并且数据库同步后,可以切换。
13.禁用复制后,必须更正序列。wiki.postgresql.org上的一篇文章对此进行了很好的记录。
由于有了这个计划,切换过程得以最小延迟。
结论
Kubernetes运算符允许您通过减少创建K8s资源的方式来简化各种活动。但是,在他们的帮助下实现了卓越的自动化,值得记住的是,它可以带来许多意想不到的细微差别,因此请明智地选择您的操作员。
在审查了PostgreSQL的三种最受欢迎的Kubernetes运算符之后,我们选择了Zalando的一个项目。而且我不得不克服一些困难,但是结果真的很令人满意,因此我们计划将此经验扩展到其他一些PgSQL安装中。如果您有使用类似解决方案的经验,我们将很高兴看到评论中的详细信息!
聚苯乙烯
另请参阅我们的博客: