WITH TIES的SQL:2008标准中的选项:
OFFSET start { ROW | ROWS }
FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } { ONLY | WITH TIES }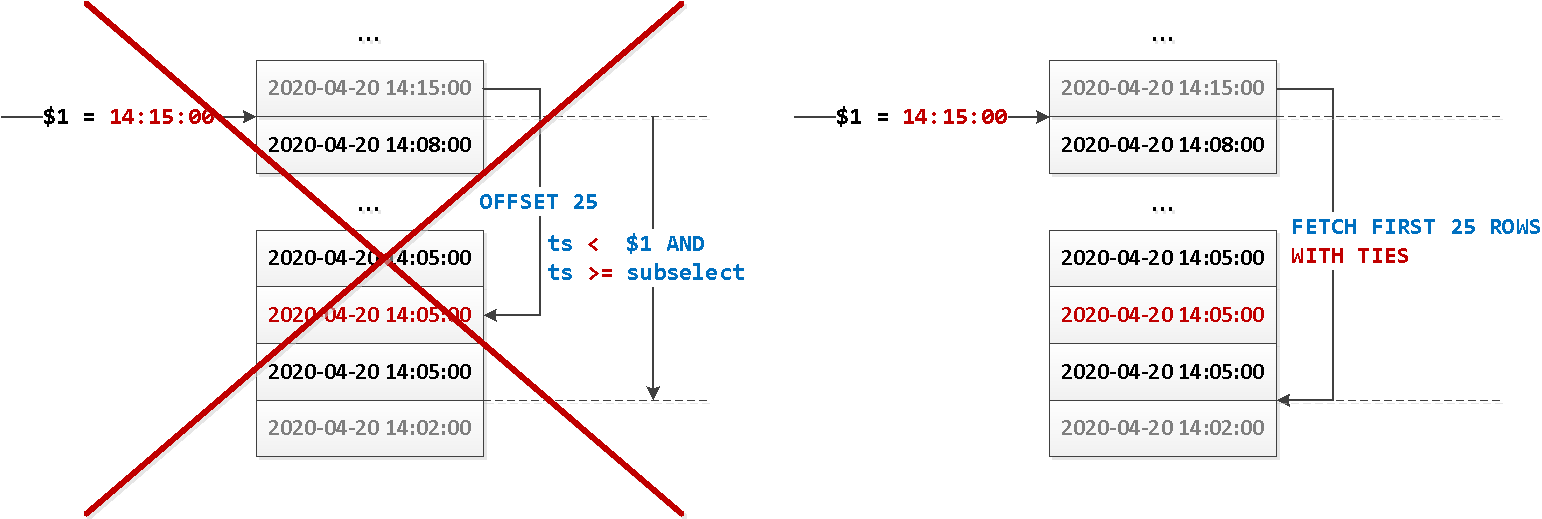
让我提醒您,在那篇文章中,我们停下来说,如果我们有这样的标志:
CREATE TABLE events(
id
serial
PRIMARY KEY
, ts
timestamp
, data
json
);
INSERT INTO events(ts)
SELECT
now() - ((random() * 1e8) || ' sec')::interval
FROM
generate_series(1, 1e6);...然后通过它(按
ts DESC)组织按时间顺序进行的分页,使用以下索引最有效:
CREATE INDEX ON events(ts DESC);...以及此查询模型:
SELECT
...
WHERE
ts < $1 AND
ts >= coalesce((
SELECT
ts
FROM
events
WHERE
ts < $1
ORDER BY
ts DESC
LIMIT 1 OFFSET 25
), '-infinity')
ORDER BY
ts DESC;好老子查询
如果要从今年年初开始获得下一个细分,请看一下此类查询的计划:
EXPLAIN (ANALYZE, BUFFERS)
SELECT
*
FROM
events
WHERE
ts < '2020-01-01'::timestamp AND
ts >= coalesce((
SELECT
ts
FROM
events
WHERE
ts < '2020-01-01'::timestamp
ORDER BY
ts DESC
LIMIT 1 OFFSET 25
), '-infinity')
ORDER BY
ts DESC;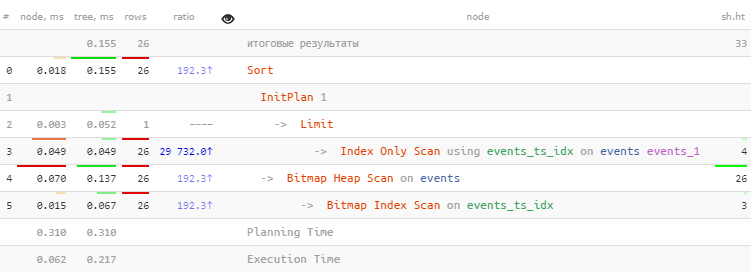
[看explain.tensor.ru]
为什么这里有嵌套查询?正是为了避免出现该文章中描述的问题,即在所请求的段之间``跳过''相同的排序键值:

尝试与领带“牙齿”
但这正是需要的功能
WITH TIES-一次选择具有相同边界键值的所有记录!
EXPLAIN (ANALYZE, BUFFERS)
SELECT
*
FROM
events
WHERE
ts < '2020-01-01'::timestamp
ORDER BY
ts DESC
FETCH FIRST 26 ROWS WITH TIES;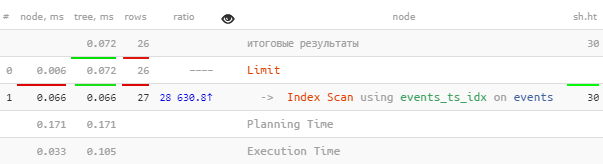
[看一下explain.tensor.ru]
查询看起来简单得多,速度快了将近2倍,而且只用了一个
Index Scan-很好的结果!
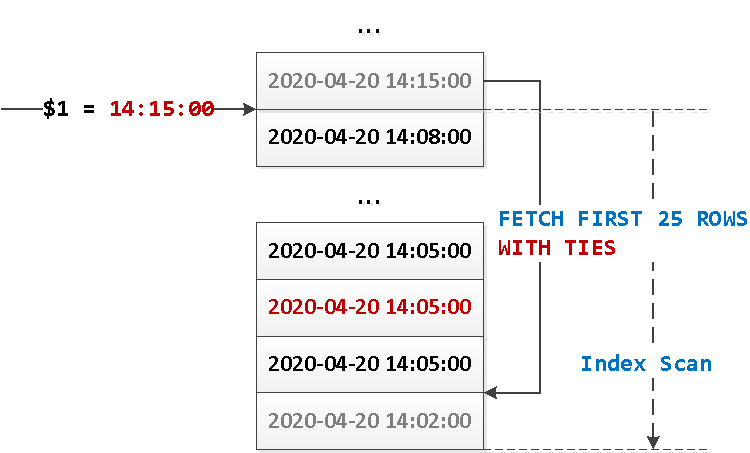
请注意,即使我们仅“订购”了26条记录,我还是
Index Scan提取了另一条记录-只是为了确保“下一条”记录不再适合我们。
好吧,我们正在等待PostgreSQL 13的正式发布,该版本计划于明天发布。