但是,如果您开始使用某些非SAP产品,最好是使用OpenSource产品作为存储设备,该怎么办?X5零售集团的我们选择了GreenPlum。当然,这解决了成本问题,但与此同时,立即出现的问题是,在使用SAP BW时,几乎默认情况下已解决。

特别是如何从主要是SAP解决方案的源系统获取数据?
HR Metrics是第一个解决此问题的项目。我们的目标是建立一个人力资源数据仓库,并在与员工的工作领域建立分析报告。在这种情况下,主要数据源是SAP HCM事务处理系统,其中进行了所有人员,组织和薪资活动。
数据提取
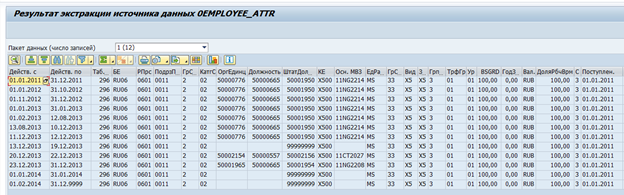
SAP BW中有用于SAP系统的标准数据提取器。这些提取器可以自动收集必要的数据,跟踪其完整性,并确定变化的增量。例如,这是员工属性0EMPLOYEE_ATTR的标准数据源:

一次从一位员工那里提取数据的结果:
如有必要,可以修改这样的提取器以满足您自己的需求,或者可以创建自己的提取器。
第一个想法是关于它们可重复使用的可能性。不幸的是,这被证明是不可能完成的任务。大多数逻辑是在SAP BW端实现的,因此不可能从源头轻松地将提取程序与SAP BW分开。
很明显,有必要开发一种自定义机制来从SAP系统中提取数据。
SAP HCM中的数据存储结构
要了解这种机制的要求,您首先需要确定我们需要哪种数据。
SAP HCM中的大多数数据存储在平面SQL表中。基于这些数据,SAP应用程序可以向用户可视化组织结构,员工和其他人力资源信息。例如,这就是在SAP HCM中的组织结构:
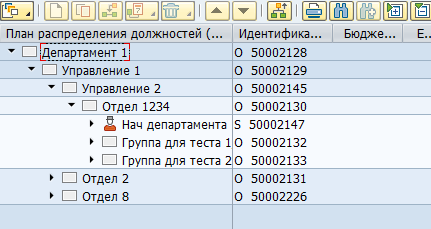
物理上,这样的树存储在两个表中-hrp1000对象和这些对象之间的hrp1001链接。
对象“部门1”和“办公室1”:

对象之间的关系:

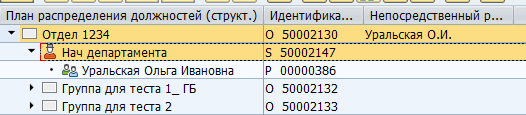
对象的类型以及它们之间的通信类型都可能非常多。对象之间既有标准链接,也有针对您自己的特定需求而定制的链接。例如,组织单位和全职职位之间的标准B012关系表示部门主管。
SAP中的经理映射:
存储在数据库表中:

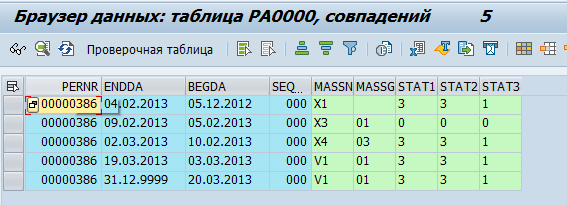
员工数据存储在pa *表中。例如,有关员工人员配备活动的数据存储在pa0000表中,
我们决定GreenPlum将采用“原始”数据,即只需从SAP表复制它们。并且已经直接在GreenPlum中对其进行处理并将其转换为物理对象(例如,部门或员工)和指标(例如,平均人数)。
已经定义了大约70个表,必须将这些表中的数据传输到GreenPlum。之后,我们开始研究一种传输此数据的方法。
SAP提供了大量的集成机制。但是最简单的方法-由于许可限制,禁止直接访问数据库。因此,所有集成流程都必须在应用服务器级别实现。
下一个问题是SAP数据库中缺少有关已删除记录的数据。在数据库中删除一行后,该行将被物理删除。那些。不可能随时间变化形成变化增量。
当然,SAP HCM具有提交数据更改的机制。例如,对于后续向系统的传输,接收者具有记录所有更改的更改指针,并以此为基础形成Idoc(用于传输至外部系统的对象)。
为人员编号为1251445的员工更改信息类型0302的IDoc示例:
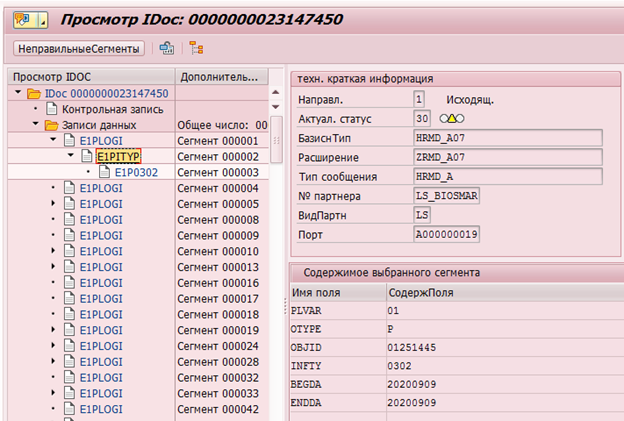
或在表DBTABLOG中维护数据更改日志。
用于从hrp1000表中删除带有QK53216375键的条目的日志示例:

但是,这些机制并不适用于所有必需的数据,它们在应用程序服务器级别的处理会消耗大量资源。因此,将所有必要表上的日志大量包含在内会导致系统性能的显着下降。
集群表是下一个主要问题。 SAP HCM的RDBMS版本中的时间估算和工资数据存储为一组逻辑表,每个员工每个工资单。这些逻辑表作为二进制数据存储在pcl2表中。
薪资集群:
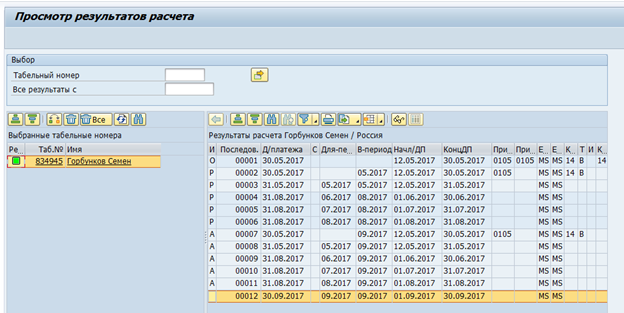
集群表中的数据无法通过SQL命令读取,并且需要使用SAP HCM宏或特殊功能模块。因此,读取此类表的速度将非常低。另一方面,此类群集存储每月仅需要一次的数据-最终工资和时间估计。因此,在这种情况下,速度并不是那么关键。
通过评估数据变化增量来评估选件,我们决定还考虑完全卸载选件。每天在系统之间传输千兆字节的不变数据的选项看起来并不漂亮。但是,它也具有许多优点-既不需要在源侧实现增量,也无需在接收器侧实现此增量的嵌入。因此,降低了成本和实现时间,并且提高了集成可靠性。同时,已确定SAP HR的几乎所有更改都发生在当前日期之前的三个月之内。因此,决定停止在当前日期前几个月每月从SAP HR N每日完全下载数据,并停止每月完全下载。 N参数取决于特定表
,范围为1到15。
对于数据提取,提出了以下方案:

外部系统生成一个请求,并将其发送到SAP HCM,在SAP HCM中检查该请求的数据完整性和访问表的授权。如果检查成功,SAP HCM将运行一个程序,该程序收集必要的数据并将其传输到Fuse集成解决方案。保险丝在Kafka中定义了必需的主题,并在其中传递数据。接下来,来自Kafka的数据被传输到舞台区域GP。
在此链中,我们对从SAP HCM提取数据的问题感兴趣。让我们更详细地讨论它。
SAP HCM-FUSE交互图。
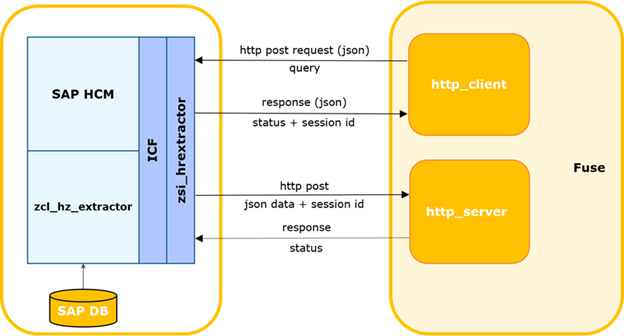
外部系统确定上次成功向SAP请求的时间。
该过程可以通过计时器或其他事件开始,包括等待来自SAP数据的响应的超时和发起重复请求。然后,它生成增量请求,并将其发送到SAP。
请求数据以json格式在正文中传递。
http:POST方法。
样本请求:

SAP服务检查请求的完整性,是否符合当前的SAP结构以及是否具有访问所请求表的权限。
发生错误时,服务将返回带有适当代码和描述的响应。如果控件成功,它将创建一个后台进程以生成选择,生成并同步返回唯一的会话ID。
发生错误时,外部系统将对其进行记录。如果响应成功,它将发送会话ID和为其提出请求的表的名称。
外部系统将当前会话注册为打开状态。如果此表还有其他会话,则将关闭它们并记录警告。
SAP后台作业根据指定的参数和指定大小的数据包生成游标。数据包大小-进程从数据库读取的最大记录数。默认情况下,假定为2000。如果数据库样本包含的记录多于使用的数据包大小,则在传输第一个数据包之后,将形成具有相应偏移量和递增的数据包编号的下一个块。这些数字加1并严格按顺序发送。
接下来,SAP将数据包作为输入传递到外部系统Web服务。它是控制传入数据包的系统。具有接收到的ID的会话必须在系统中注册,并且必须处于打开状态。如果程序包号> 1,则系统必须记录先前程序包(package_id-1)的成功接收。
在成功控制的情况下,外部系统将解析并保存表数据。
此外,如果包中存在最终标志并且序列化成功,则会向集成模块通知会话处理已成功完成,并且模块会更新会话状态。
如果出现控制/解析错误,则会记录该错误,并且该会话的数据包将被外部系统拒绝。
同样,在相反的情况下,当外部系统返回错误时,将记录错误并停止传输数据包。
已实施集成服务以在SAPHM端请求数据。该服务在ICF框架(SAP Internet通信框架-help.sap.com/viewer/6da7259a6c4b1014b7d5e759cc76fd22/7.01.22/zh-CN/488d6e0ea6ed72d5e10000000a42189c.html)上实现。它使您可以从SAP HCM系统中的特定表中查询数据。在形成数据请求时,可以指定特定字段和过滤参数的列表,以便获得必要的数据。同时,服务的实现并不意味着任何业务逻辑。用于计算增量,请求参数,完整性控制等的算法也在外部系统方面实现。
这种机制使您可以在几个小时内收集和传输所有必要的数据。该速度接近可接受的水平,因此我们认为该解决方案是暂时的,这使得有可能满足项目上对提取工具的需求。
在解决数据提取问题的目标图中,正在制定使用CDC系统(如Oracle Golden Gate)或ETL工具(如SAP DS)的选项。