
我叫Ilya Gulyaev,我是DINS部署后验证小组的一名测试自动化工程师。
在DINS中,我们在许多过程中使用Jenkins:从构建构建到运行的部署和自动测试。在我的团队中,我们将Jenkins用作从开发环境到生产部署我们的每项服务之后,统一运行烟雾检查的平台。
一年前,其他团队决定使用我们的管道,不仅在更新一项服务后检查一项服务,而且还在运行大型测试批处理之前检查整个环境的状态。我们平台上的负载已增加了十倍,詹金斯已经停止应付手头的任务,而只是开始下降。我们很快意识到添加资源和调整垃圾收集器只会延迟问题,而不能完全解决问题。因此,我们决定找到Jenkins瓶颈并对其进行优化。
在本文中,我将解释Jenkins管道的工作原理,并分享我的发现,这可能有助于您加快管道的速度。该材料对于已经与Jenkins合作并且希望更好地了解该工具的工程师很有用。
真是詹金斯的野兽管道
Jenkins Pipeline是功能强大的工具,可让您自动执行各种流程。 Jenkins Pipeline是一组插件,允许您以Groovy DSL的形式描述动作,并且是Build Flow插件的后继产品。
Build Flow插件的脚本直接在运行Groovy代码的单独Java线程中的主服务器上运行,而没有障碍,无法访问Jenkins内部API。这种方法带来了安全风险,后来成为放弃构建流程的原因之一,并成为创建安全且可扩展的运行脚本工具-Jenkins Pipeline的先决条件。
您可以从作者的文章Build Flow或以下文章中进一步了解Jenkins Pipeline创建的历史。Oleg Nenashev在Jenkins中关于Groovy DSL的演讲。
詹金斯管道如何运作
现在让我们从内部弄清楚管道是如何工作的。他们通常说Jenkins Pipeline是Jenkins的一种完全不同的工作,与可以在Web界面中单击的老式的旧式自由职业不同。从用户的角度来看,它可能看起来像这样,但是从Jenkins方面来看,管道是一组插件,可让您将操作的描述转移到代码中。
管道和自由式作业的相似之处
- 作业描述(不是步骤)存储在config.xml文件中
- 参数存储在config.xml中
- 触发器也存储在config.xml中
- 甚至一些选项都存储在config.xml中
所以。停止。在官方文件说,参数,触发器和选项可以直接在管道中设置。真相在哪里?
事实是,作业开始时,管道中描述的参数将自动添加到Web界面的配置部分中。您可以信任我,因为我在最新版本中编写了此功能,但是在本文的第二部分中对此进行了更多介绍。
管道作业和自由式作业之间的区别
- 在工作开始时,Jenkins对执行工作的代理一无所知
- 这些动作在一个常规脚本中进行了描述。
启动Jenkins声明式管道
Jenkins Pipeline启动过程包括以下步骤:
- 从config.xml文件加载作业描述
- 启动一个单独的线程(轻量级执行者)以完成任务
- 加载管道脚本
- 建立和检查语法树
- 作业配置更新
- 结合作业描述和脚本中指定的参数和属性
- 将作业描述保存到文件系统
- 在Groovy沙箱中执行脚本
- 代理要求整个工作或一个步骤
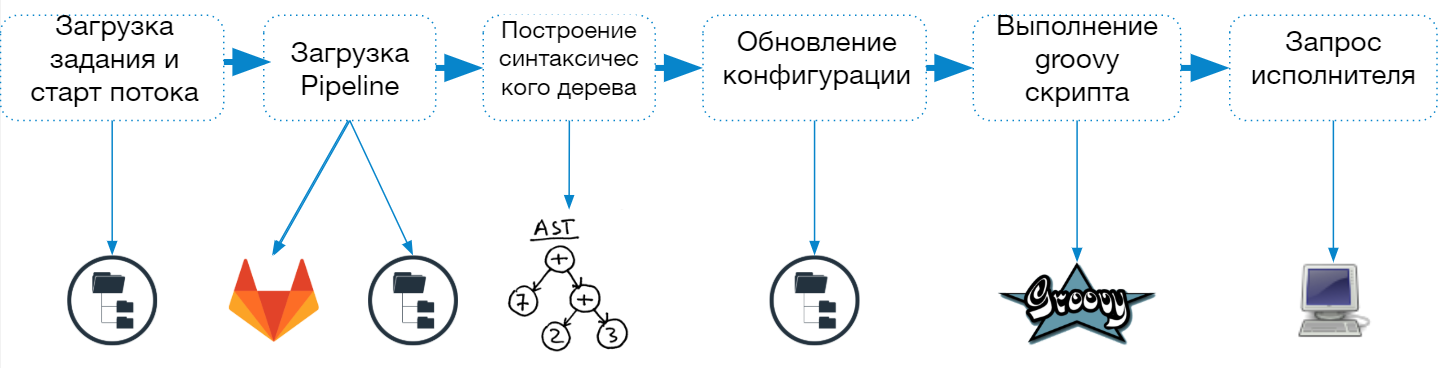
当管道作业开始时,Jenkins创建一个单独的线程并将该作业发送到队列以执行,并在加载脚本之后确定需要哪个代理来完成任务。
为了支持这种方法,使用了一个特殊的Jenkins线程池(轻量级执行程序)。您可以看到它们在主服务器上执行,但不影响通常的执行程序池:该
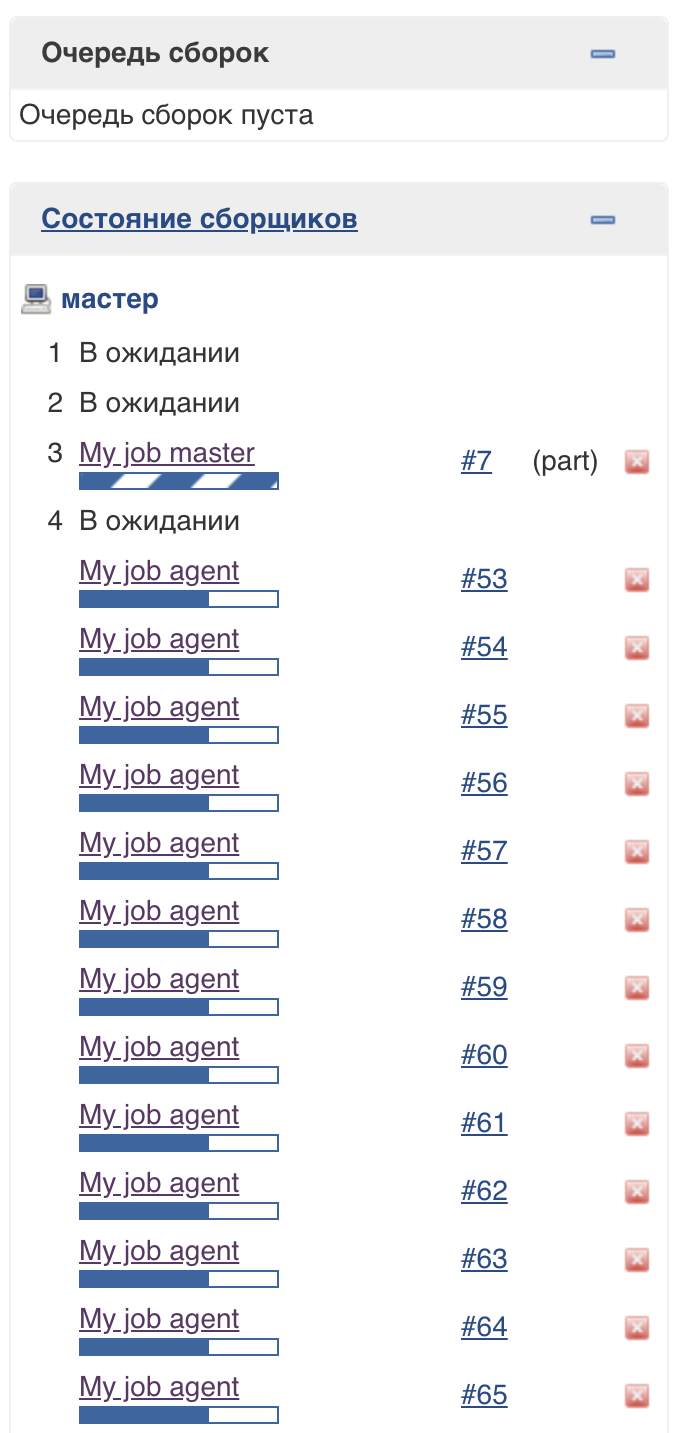
池中的线程数不受限制(在撰写本文时)。
管道中的工作参数。以及触发器和一些选项
参数处理可以用以下公式描述:

从启动时看到的作业参数中,首先删除前一次启动的管道参数,然后才添加当前启动的管道中指定的参数。如果已将参数从管道中删除,则可以从作业中删除参数。
从内到外如何工作?
让我们考虑一个示例config.xml(存储作业配置的文件):
<?xml version='1.1' encoding='UTF-8'?>
<flow-definition plugin="workflow-job@2.35">
<actions>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobAction plugin="pipeline-model-definition@1.5.0"/>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction plugin="pipeline-model-definition@1.5.0">
<jobProperties>
<string>jenkins.model.BuildDiscarderProperty</string>
</jobProperties>
<triggers/>
<parameters>
<string>parameter_3</string>
</parameters>
</org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction>
</actions>
<description></description>
<keepDependencies>false</keepDependencies>
<properties>
<hudson.model.ParametersDefinitionProperty>
<parameterDefinitions>
<hudson.model.StringParameterDefinition>
<name>parameter_1</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_2</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_3</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
</parameterDefinitions>
</hudson.model.ParametersDefinitionProperty>
<jenkins.model.BuildDiscarderProperty>
<strategy class="org.jenkinsci.plugins.BuildRotator.BuildRotator" plugin="buildrotator@1.2">
<daysToKeep>30</daysToKeep>
<numToKeep>10000</numToKeep>
<artifactsDaysToKeep>-1</artifactsDaysToKeep>
<artifactsNumToKeep>-1</artifactsNumToKeep>
</strategy>
</jenkins.model.BuildDiscarderProperty>
<com.sonyericsson.rebuild.RebuildSettings plugin="rebuild@1.28">
<autoRebuild>false</autoRebuild>
<rebuildDisabled>false</rebuildDisabled>
</com.sonyericsson.rebuild.RebuildSettings>
</properties>
<definition class="org.jenkinsci.plugins.workflow.cps.CpsScmFlowDefinition" plugin="workflow-cps@2.80">
<scm class="hudson.plugins.filesystem_scm.FSSCM" plugin="filesystem_scm@2.1">
<path>/path/to/jenkinsfile/</path>
<clearWorkspace>true</clearWorkspace>
</scm>
<scriptPath>Jenkinsfile</scriptPath>
<lightweight>true</lightweight>
</definition>
<triggers/>
<disabled>false</disabled>
</flow-definition>
属性 部分包含将用于启动作业的参数,触发器和选项。附加部分DeclarativeJobPropertyTrackerAction用于存储仅在管道中设置的参数。
从管道中删除参数后,它将同时从DeclarativeJobPropertyTrackerAction和properties中删除,因为Jenkins知道该参数仅在管道中定义。
添加参数时,情况相反,将仅在管道执行时添加参数DeclarativeJobPropertyTrackerAction和properties。
这就是为什么如果仅在管道中设置参数,那么它们首次启动时将不可用。
詹金斯管道执行
一旦下载并编译了流水线脚本,执行过程就会开始。但是,此过程不仅仅涉及常规操作。我已经强调了执行作业时
执行的主要重量级操作:执行Groovy代码
管道脚本始终在主服务器上执行-我们一定不要忘记这一点,以免对Jenkins造成不必要的负担。在代理程序上仅执行与代理程序的文件系统或系统调用交互的步骤。
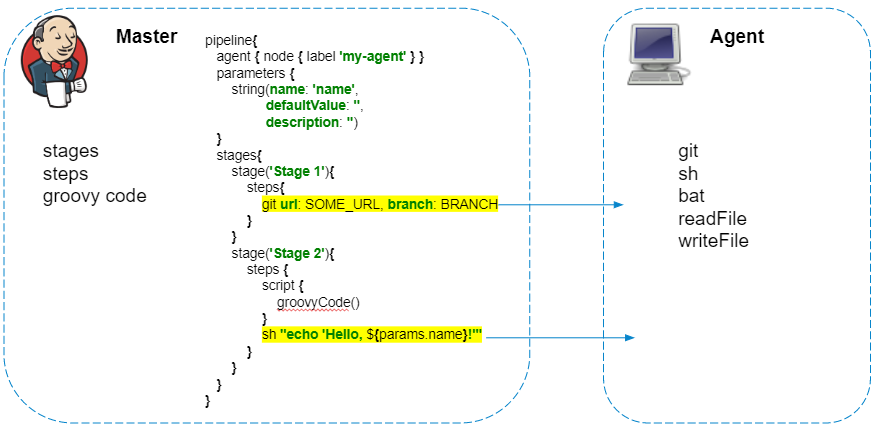
管道有一个很棒的插件,可让您发出HTTP请求。另外,答案可以保存到文件中。
httpRequest url: 'http://localhost:8080/jenkins/api/json?pretty=true', outputFile: 'result.json'
最初,似乎应该在代理上完全执行此代码,从代理发送请求,然后将响应保存到result.json文件。但是一切都以相反的方式发生,并且请求由詹金斯本人执行,并将保存的文件内容复制到代理。如果不需要在管道中对响应进行其他处理,那么我建议您用curl替换此类请求:
sh 'curl "http://localhost:8080/jenkins/api/json?pretty=true" -o "result.json"'
使用日志和工件
不管在哪个代理上执行命令,都会实时处理日志和工件并将其保存到主文件系统中。
如果在管道中使用了机密(凭证),那么在保存日志之前,还要在主服务器上过滤日志。
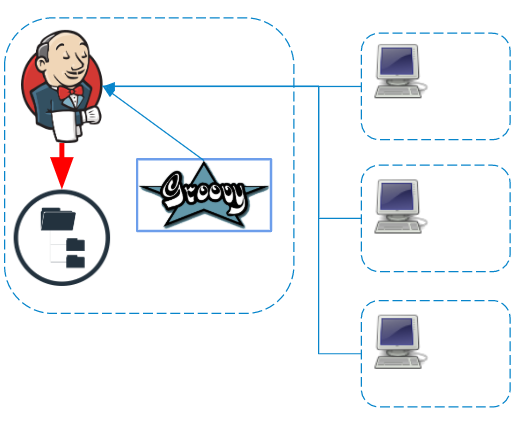
节省步骤(管道耐久性)
Jenkins Pipeline将自身定位为一项任务,该任务由独立的独立组件组成,并且可以在主服务器崩溃时进行复制。但是您必须为此付出额外的写入磁盘的费用,因为根据任务的设置,具有不同详细程度的步骤会被序列化并保存到磁盘。
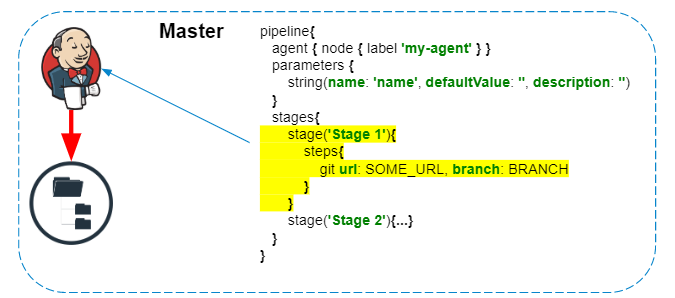
根据流水线的耐用性,流水线图中的步骤将存储在每个作业运行的一个或多个文件中。文档摘录:
用于存储步骤的工作流支持插件(FlowNode)使用FlowNodeStorage类及其SimpleXStreamFlowNodeStorage和BulkFlowNodeStorage实现。
- FlowNodeStorage使用内存缓存来聚合磁盘写入。缓冲区在运行时自动写入。通常,您不必担心这一点,但是请记住,保存FlowNode并不能保证立即将其写入磁盘。
- SimpleXStreamFlowNodeStorage为每个FlowNode使用一个小的XML文件-尽管我们为节点使用软引用内存中缓存,但是这在第一次遍历FlowNode时导致性能大大降低。
- BulkFlowNodeStorage使用一个更大的XML文件,其中包含所有FlowNode。此类在PERFORMANCE_OPTIMIZED活动模式下使用,这种模式的写入频率要低得多。这通常效率更高,因为一个大的流记录比一堆小记录要快,并且可以最大程度地减少OS上管理所有微小文件的负载。
原版的
Storage: in the workflow-support plugin, see the 'FlowNodeStorage' class and the SimpleXStreamFlowNodeStorage and BulkFlowNodeStorage implementations.
- FlowNodeStorage uses in-memory caching to consolidate disk writes. Automatic flushing is implemented at execution time. Generally, you won't need to worry about this, but be aware that saving a FlowNode does not guarantee it is immediately persisted to disk.
- The SimpleXStreamFlowNodeStorage uses a single small XML file for every FlowNode — although we use a soft-reference in-memory cache for the nodes, this generates much worse performance the first time we iterate through the FlowNodes (or when)
- The BulkFlowNodeStorage uses a single larger XML file with all the FlowNodes in it. This is used in the PERFORMANCE_OPTIMIZED durability mode, which writes much less often. It is generally much more efficient because a single large streaming write is faster than a bunch of small writes, and it minimizes the system load of managing all the tiny files.
保存的步骤可以在目录中找到:
$JENKINS_HOME/jobs/$JOB_NAME/builds/$BUILD_ID/workflow/
示例文件:
<?xml version='1.1' encoding='UTF-8'?>
<Tag plugin="workflow-support@3.5">
<node class="cps.n.StepStartNode" plugin="workflow-cps@2.82">
<parentIds>
<string>4</string>
</parentIds>
<id>5</id>
<descriptorId>org.jenkinsci.plugins.workflow.support.steps.StageStep</descriptorId>
</node>
<actions>
<s.a.LogStorageAction/>
<cps.a.ArgumentsActionImpl plugin="workflow-cps@2.82">
<arguments>
<entry>
<string>name</string>
<string>Declarative: Checkout SCM</string>
</entry>
</arguments>
<isUnmodifiedBySanitization>true</isUnmodifiedBySanitization>
</cps.a.ArgumentsActionImpl>
<wf.a.TimingAction plugin="workflow-api@2.40">
<startTime>1600855071994</startTime>
</wf.a.TimingAction>
</actions>
</Tag>
结果
我希望这些材料很有趣,并有助于更好地了解什么是管道以及它们从内部如何工作。如果您还有问题,请在下面分享,我将很乐意回答!
在本文的第二部分,我将考虑一些单独的案例,这些案例将帮助您发现Jenkins Pipeline的问题并加快您的工作速度。我们将学习如何解决并发启动问题,研究生存能力选项,并讨论为什么要分析Jenkins。