
自1999年发明第一款GPU以来,NVIDIA一直处于3D图形和GPU加速计算的最前沿。每种NVIDIA架构均经过精心设计,可提供革命性的性能和效率。
A100是首款采用NVIDIA Ampere架构的GPU,于2020年5月发布。它为AI培训,HPC和数据分析提供了极大的加速。 A100基于GA100芯片,该芯片纯粹是计算性的,与GA102不同,尚未上市。
GA10x GPU基于NVIDIA Turing GPU架构。Turing是世界上第一个在一个设备中提供高性能实时光线跟踪,AI加速图形和专业图形渲染的体系结构。
在本文中,我们将分析与新NVIDIA视频卡相比,新NVIDIA视频卡的体系结构的主要变化。

图1. Ampere GA10x架构
GA102的主要特点
GA102使用NVIDIA专有的8nm技术-8N NVIDIA Custom制造。该芯片在628.4 mm2的管芯上包含283亿个晶体管。与所有GeForce RTX一样,GA102基于包含三种不同类型计算资源的处理器:
- 用于可编程着色的CUDA内核;
- RT-, (BVH) ;
- , .
Ampere
GPC, TPC SM
与其前代产品一样,GA102由图形处理群集(GPC),纹理处理群集(TPC),流式多处理器(SM),光栅运算符ROP(ROP)和内存控制器组成。完整的芯片具有七个GPC单元,42个TPC和84个SM。
GPC是包含所有关键图形的主要高级块。每个GPC都有专用的光栅引擎,现在还具有两个ROP部分,每个部分八个块,这是Ampere体系结构的一项创新。此外,GPC包含六个TPC,每个TPC包含两个多处理器和一个PolyMorph引擎。
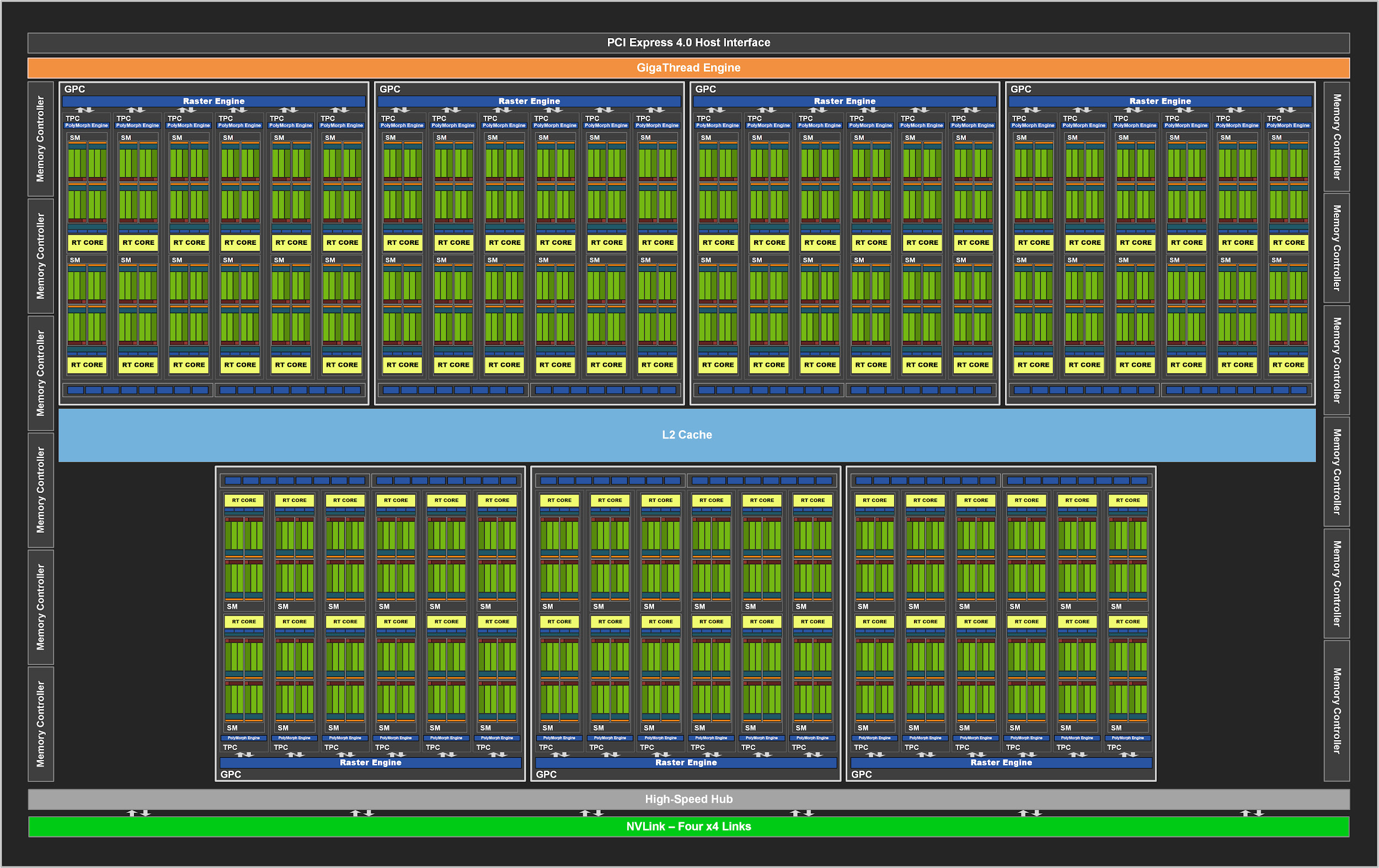
图2.带有84个SM模块的完整GPU GA102
反过来,GA10x中的每个SM包含128个CUDA内核,四个第三代张量内核,一个256 KB寄存器文件,四个纹理单元,一个第二代射线跟踪内核和128 KB L1 /共享内存,可以针对不同的容量进行配置根据计算或图形任务的需要。
ROP优化
在以前的NVIDIA GPU中,ROP与内存控制器和L2缓存绑定在一起。从GA10x开始,它们是GPC的一部分,它通过增加ROP的总数来提高栅格性能。
总共,每个GPC中有七个GPC和16个ROP,GA102 GPU包括112个ROP,而不是TU102中的96个ROP。所有这些都对多样本抗锯齿,像素填充率和混合产生积极影响。
NVLink第三代
GA102 GPU支持第三代NVIDIA NVLink接口,该接口包含四个x4通道,每个通道在两个GPU之间沿任一方向提供14.0625 GB / s的带宽。四个通道在每个方向上的总带宽为56.25 GB / s,两个GPU之间的总带宽为112.5 GB / s。因此,使用NVLink,可以连接两个RTX 3090 GPU。
PCIe第4代
GA10x GPU配备了PCI Express 4.0,其提供两倍于PCIe 3.0的带宽,传输速率高达每秒16GTransfers,并且由于具有x16 PCIe 4.0插槽,峰值带宽达到了64GB / s。
GA10x多处理器架构
Turing多处理器体系结构是NVIDIA第一个拥有独立内核以加快光线跟踪操作的体系结构。然后,Volta引入了第一个张量内核,Turing引入了改进的第二代张量内核。Turing和Volta的另一项创新是能够同时执行FP32和INT32操作。GA10x中的多处理器支持上述所有功能,并且也有许多自身的改进。
与具有八个第二代张量内核的TU102不同,GA10x多处理器具有四个第三代张量内核,每个GA10x张量内核的功能是Turing的两倍。
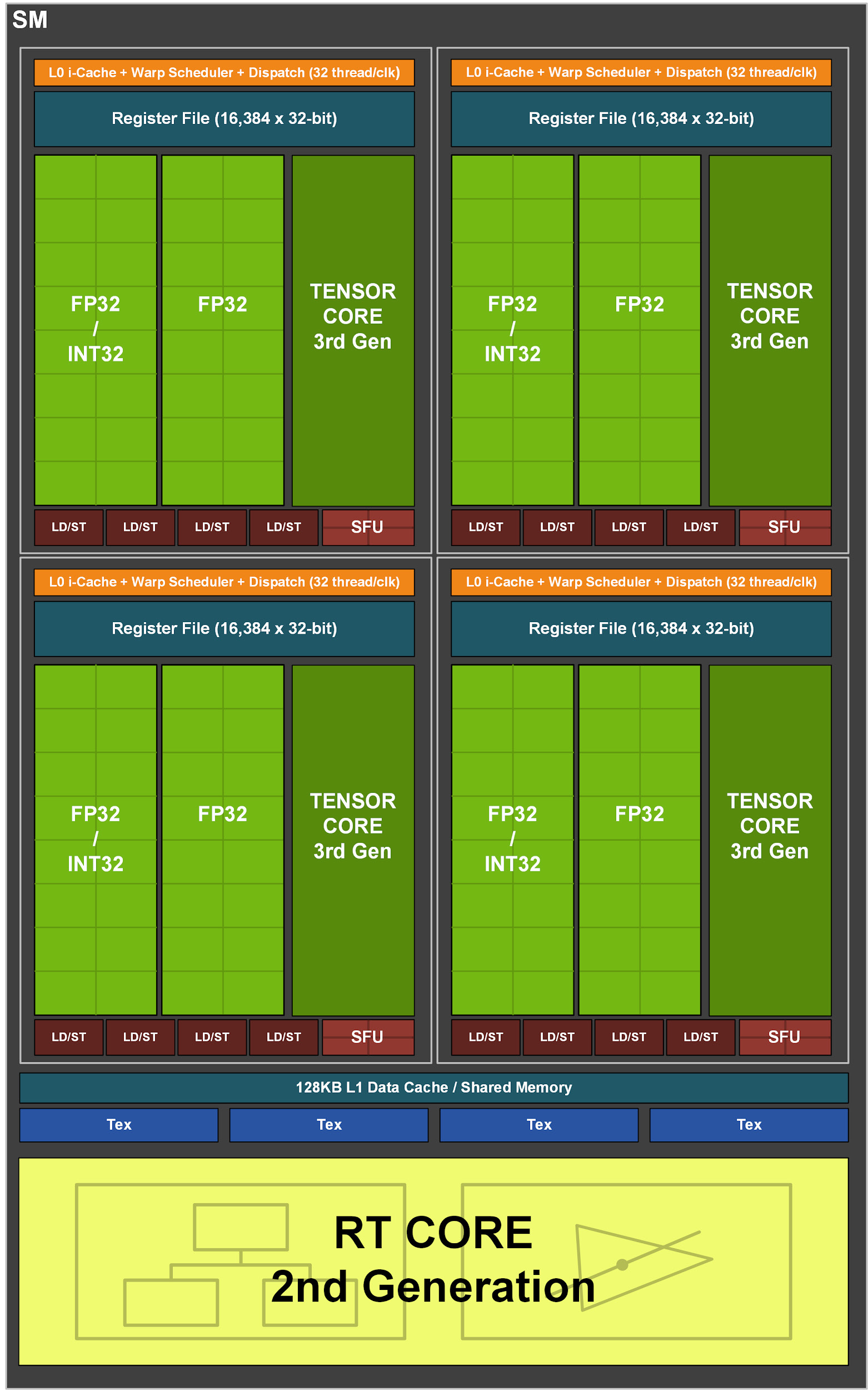
图3. GA10x流式多处理器
FP32计算速度翻倍
大多数图形计算是32位浮点(FP32)操作。 Ampere GA10x流式多处理器在两个数据通道上的速度都是FP32操作的两倍。结果,在FP32的情况下,GeForce RTX 3090提供了超过35 teraflops,是Turing的2倍以上。
GA10X可以每个时钟执行128个FP32操作或64个FP32操作和64个INT32操作,这是图灵计算速度的两倍。
现代游戏任务具有广泛的处理需求。许多计算需要一堆FP32操作(例如FFMA,浮点加法(FADD)或浮点乘法(FMUL)),以及许多更简单的整数计算。
GA10x多处理器继续支持双速FP16(HFMA)操作,图灵也支持该操作。并且,类似于TU102,TU104和TU106 GPU,在GA10x中,标准FP16操作也由张量内核处理。
共享内存和L1数据缓存
GA10x具有用于共享内存,L1数据缓存和纹理缓存的统一体系结构。可以根据工作量和需求修改此统一设计。
GA102芯片包含10,752 KB的L1缓存(相比之下,TU102中为6912 KB)。除此之外,与图灵相比,GA10x的共享内存带宽也翻了一番(128字节/周期与64字节/周期)。GeForce RTX 3080的总L1带宽为219 GB / s,而GeForce RTX 2080 Super的116 GB / s。
每瓦性能
从逻辑,内存,电源和散热管理到PCB设计,软件和算法,所有NVIDIA Ampere架构都旨在提高效率。在相同的性能水平下,Ampere GPU的能源效率比同等的Turing设备高1.9倍。
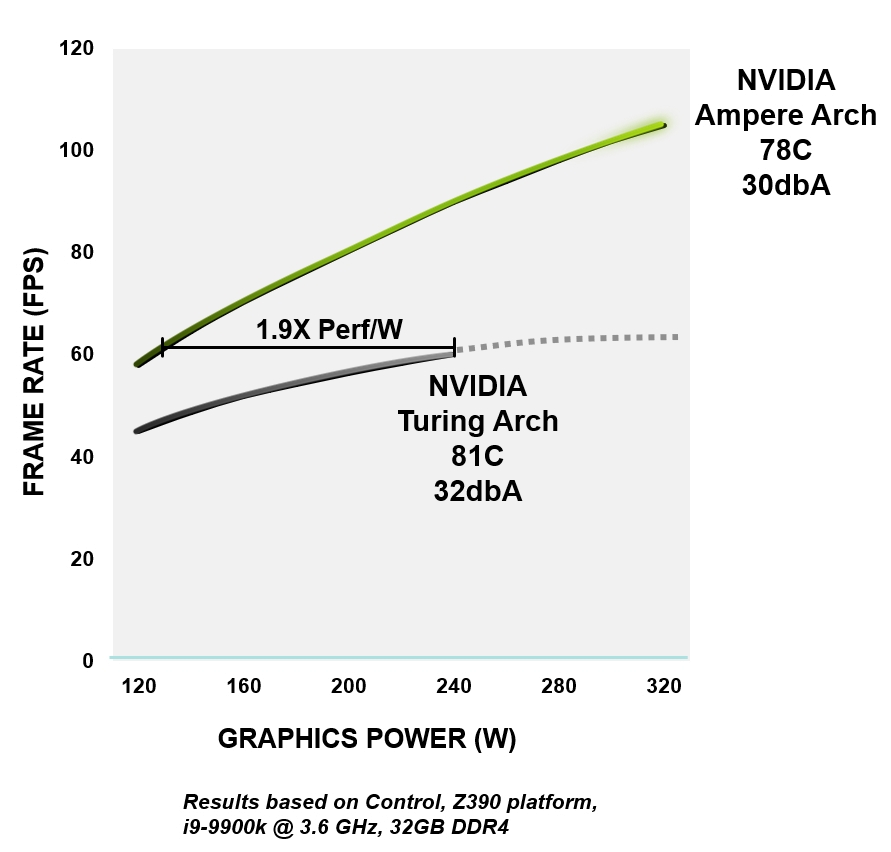
图4. RTX 3080的电源效率与GeForce RTX 2080超级架构
第二代RT核
新的RT内核具有许多增强功能,当与更新的缓存系统结合使用时,可使Ampere处理器的光线跟踪性能比Turing有效提高一倍。此外,GA10x允许其他进程与RT计算同时运行,从而大大加快了许多任务。
GA10x中的第二代光线追踪
基于Turing架构的GeForce RTX是首批在电影中实现电影般的光线追踪的GPU。GA10x配备了第二代射线追踪技术。与图灵一样,GA10x的多处理器具有专门的硬件模块,可检查与BVH和三角形的射线相交。同时,与Turing相比,Ampere多处理器的核心具有两倍于测试光线和三角形相交的速度。
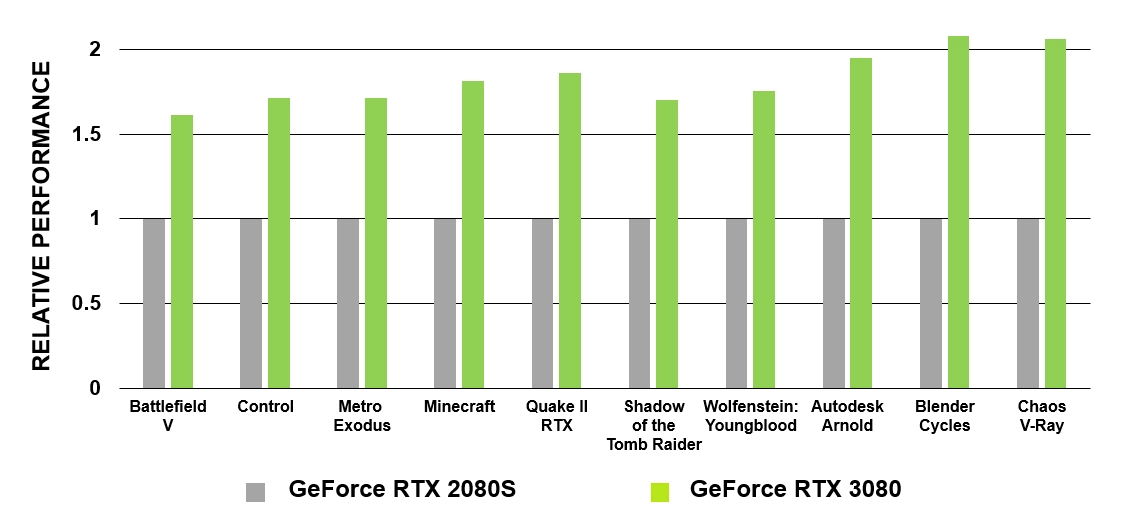
图5. GeForce RTX 3080和GeForce RTX 2080 Super的RT内核的性能比较
GA10x多处理器可以同时执行操作,并且不限于计算和图形,就像前几代GPU一样。因此,例如,在GA10x中,降噪算法可以与光线跟踪同时执行。

图6. GA10x GPU中的第二代RT内核
请注意,RT密集型工作负载不会显着增加多处理器内核的负载,因此可以将多处理器处理能力用于其他任务。与其他没有专用RT内核的竞争体系结构相比,这是一个很大的优势,因此必须将其构造块用于图形和光线跟踪。
运行中的Ampere RTX处理器
光线跟踪和着色器的计算量很大。但是,仅使用CUDA内核运行所有内容就会更加昂贵,因此包含张量和RT内核有助于显着加快处理速度。图7显示了在各种情况下启用了光线跟踪的Wolfenstein:Youngblood游戏的示例。
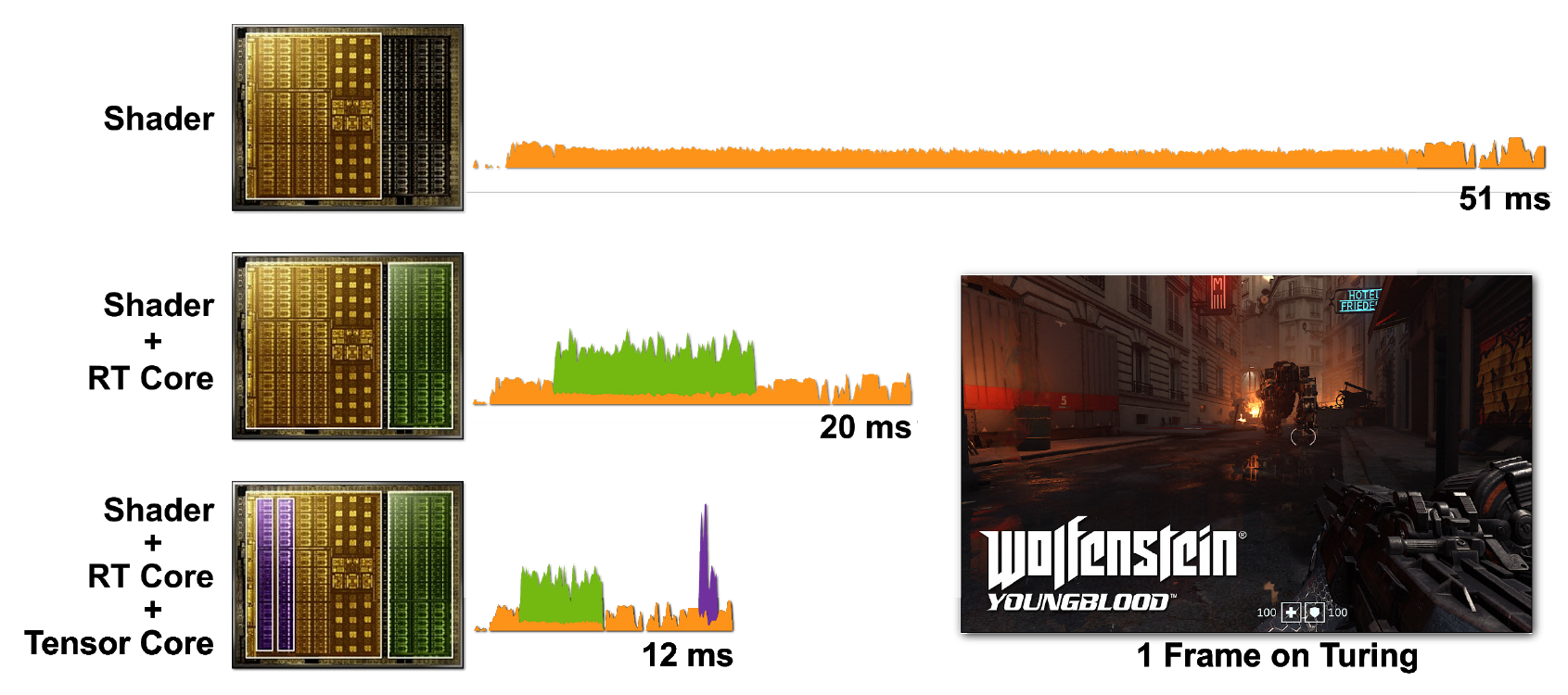
图7.渲染单帧Wolfenstein:使用a)着色器核心(CUDA),b)着色器核心和RT核心,c)着色器核心,张量核心和RT核心在RTX 2080 Super GPU上渲染Youngblood。请注意,随着增加各种RTX处理器内核的功能,帧时间逐渐减少。
在第一种情况下,开始一帧需要51 ms(〜20 fps)。打开RT核心时,帧渲染速度更快-20毫秒(50 fps)。在张量核心上使用DLSS可将帧时间减少到12 ms(〜83 fps)。
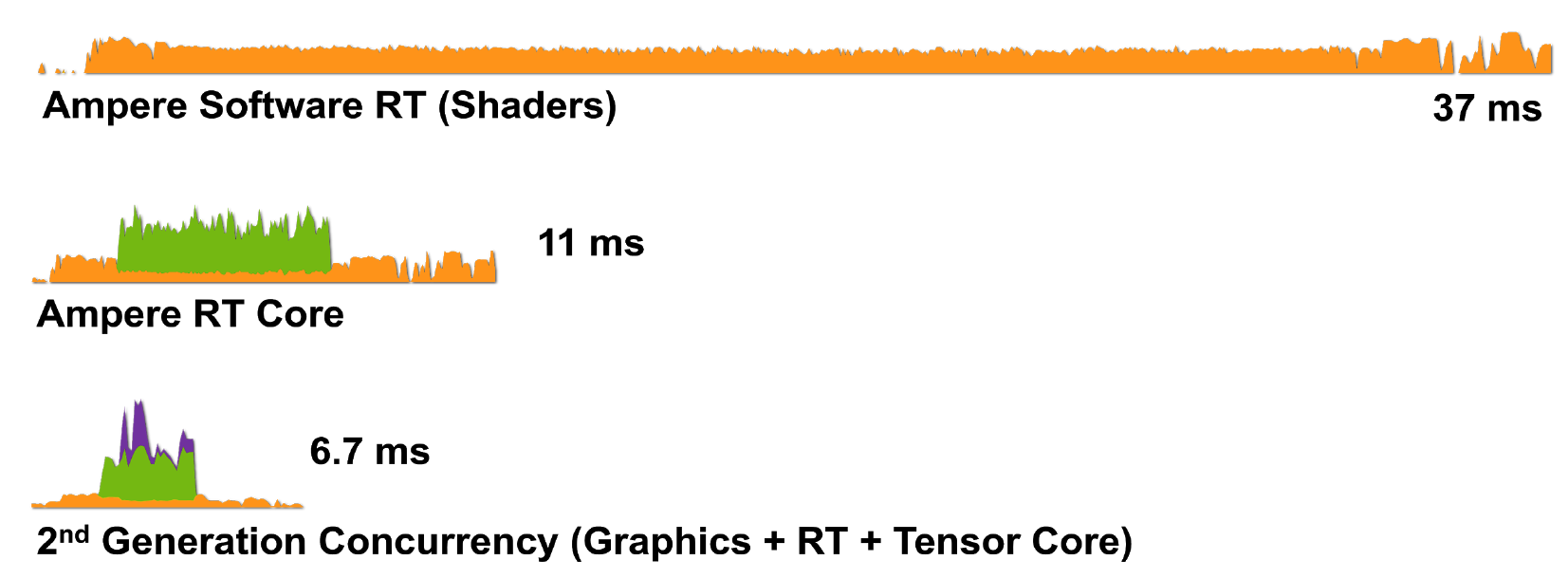
图8.使用a)着色器核心(CUDA),b)着色器核心和RT核心,c)着色器核心,张量核心和RT核心在RTX 3080上渲染Wolfenstein:Youngblood的单个框架。
因此,具有Ampere架构的RTX技术在处理渲染任务方面更加高效:RTX 3080以6.7毫秒(150 fps)的速度渲染帧,这是对RTX 2080的巨大改进。
使用运动模糊进行硬件加速的光线跟踪
运动模糊是计算机图形学中经常使用的一种动作。摄影图像不是立即创建的,而是通过在有限的时间内将胶卷曝光来创建的。与相机的曝光时间相比,移动得足够快的被摄对象将在照片中显示为条纹或斑点。为了让GPU在场景中的对象在静态相机之前快速移动时创建逼真的运动模糊,它必须能够模拟相机和胶片在此类场景中的工作方式。运动模糊在电影制作中尤为重要,因为电影以每秒24帧的速度播放,并且没有运动模糊的场景会显得清晰动荡。
图灵GPU通常在加速运动模糊方面做得很好。但是,在移动几何体的情况下,任务可能会更加困难,因为有关BVH的信息会随着对象在空间中的位置而变化。
如图9所示,Turing RT内核执行BVH层次结构的硬件遍历,检查光线与BBox和三角形的交点。 GA10x可以完成所有操作,但除此之外,它还具有一个新的“插值三角形位置”块,该块可加速光线跟踪中的运动模糊。
Turing和GA10x RT内核均实现了多指令多数据(MIMD)架构,该架构允许同时处理多束光束。
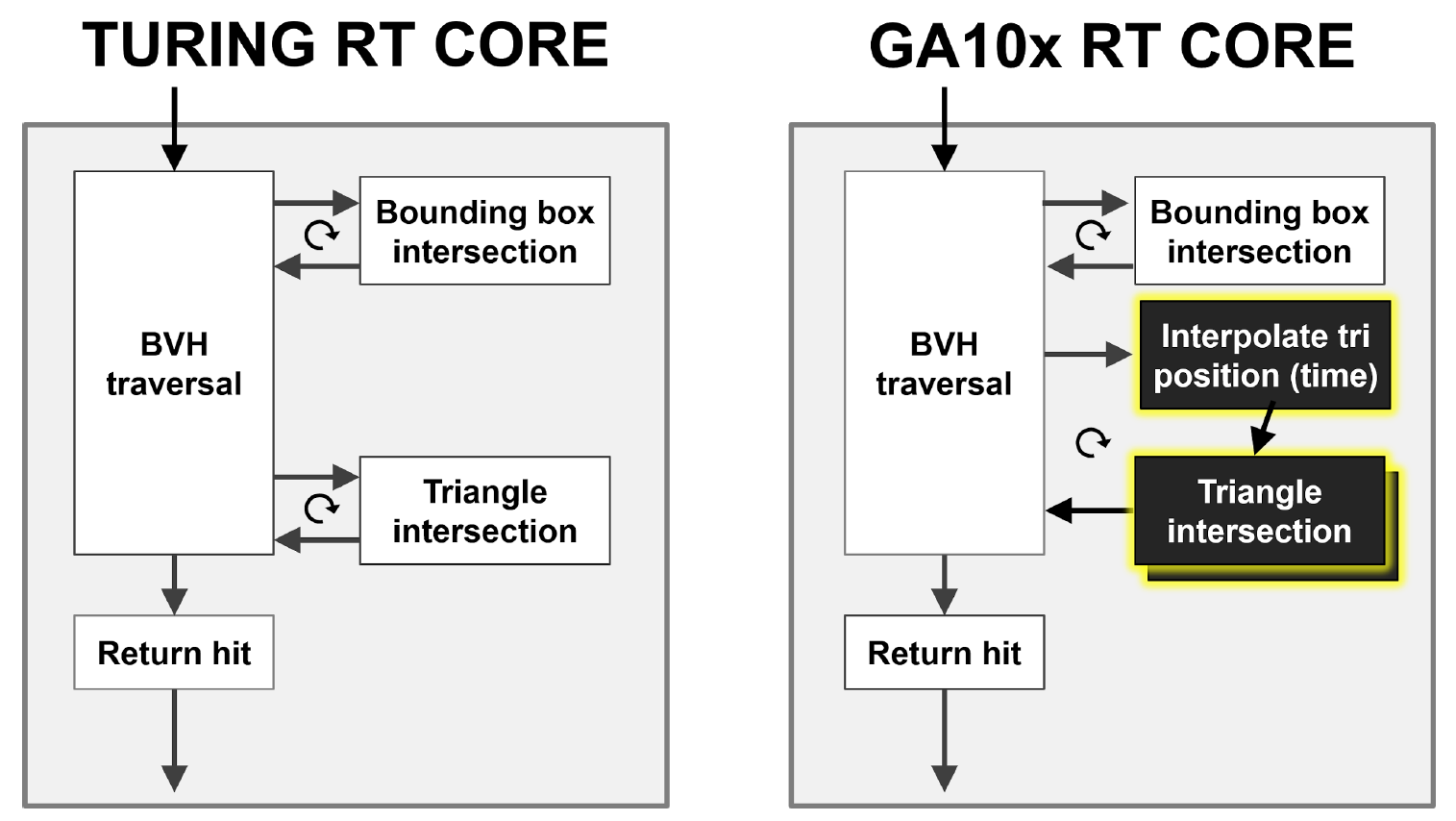
图9.图灵和安培情况下硬件加速运动模糊的比较运动模糊
的主要问题是场景中的三角形没有及时固定。在基本光线跟踪中,将执行静态相交测试,并且当光线撞击三角形时,将返回有关该撞击的信息。如图10所示,在运动模糊的情况下,没有一个三角形具有固定的坐标。每条射线都加上时间戳记以指示其跟踪时间,并且三角形的位置和射线的交点由BVH公式确定。
如果不通过硬件来加速此过程,则可能会导致很多问题,包括非线性。
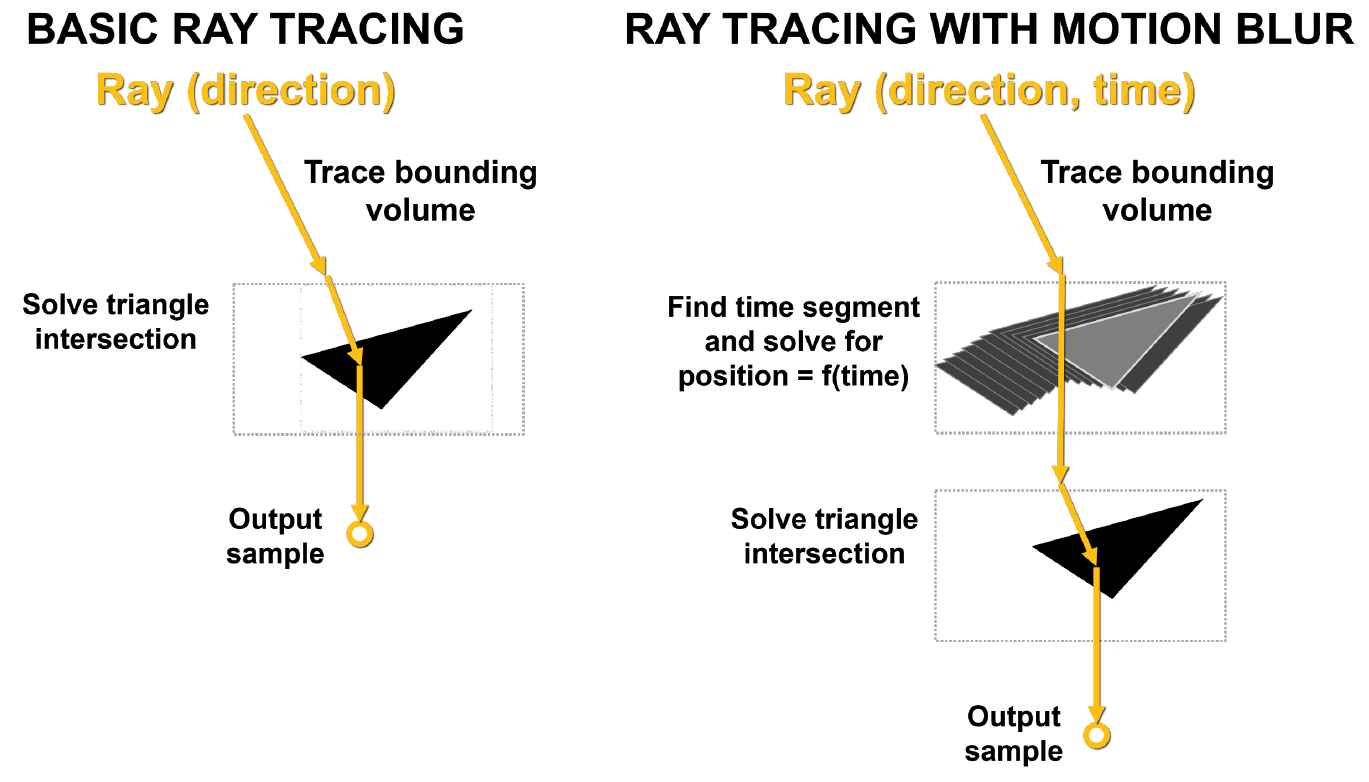
画画。 10.基本光线跟踪和带有运动模糊的光线跟踪
在图11的左侧,发送到静态场景的光线同时击中了同一三角形。白点表示影响的位置,此结果将返回。在运动模糊的情况下,每条射线都会在其自己的时刻存在。每个波束被随机分配一个不同的时间戳。例如,橙色射线尝试同时穿过橙色三角形,然后绿色射线和蓝色射线执行相同的操作。最后,将样本混合,以产生数学上更正确的模糊结果。
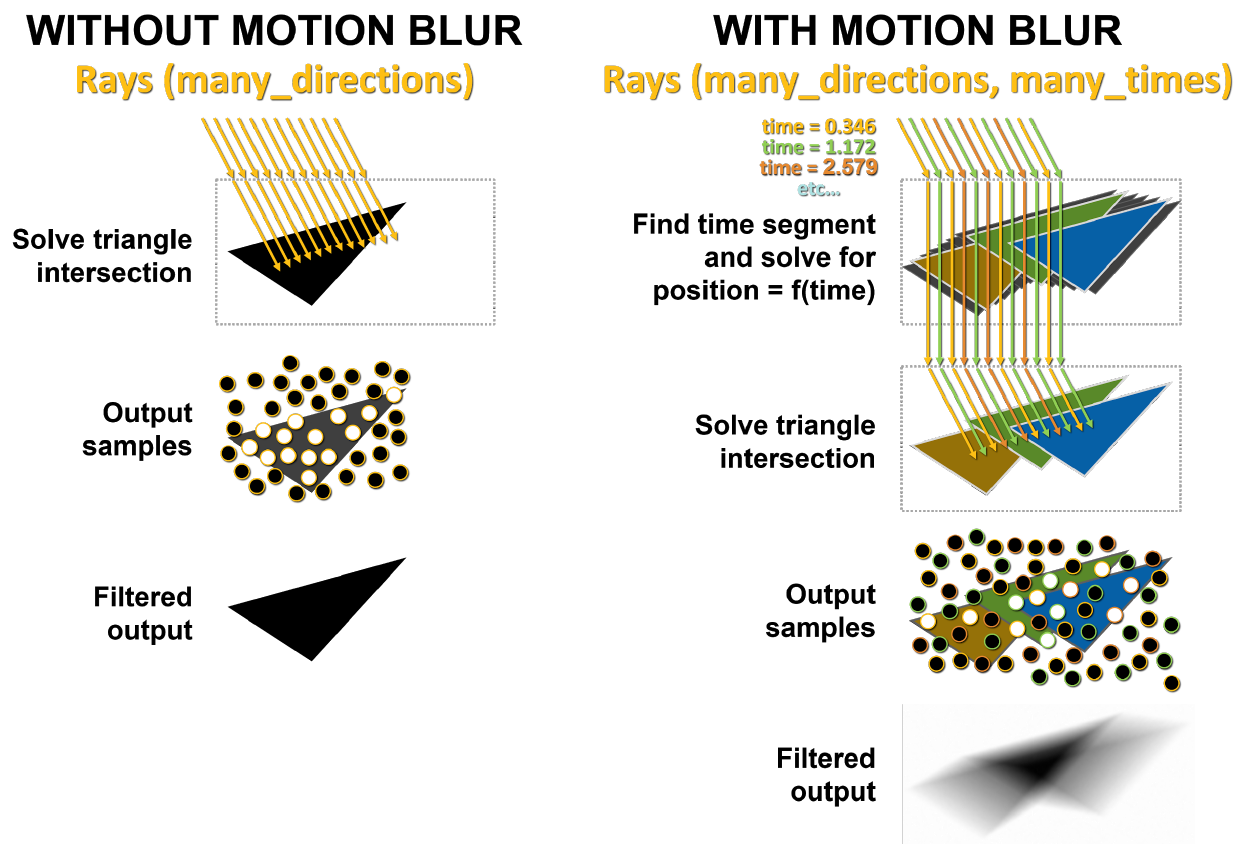
图11. GA10x中没有运动模糊和模糊的渲染
插值三角形位置块根据对象的运动在已存在的三角形之间插值BVH中的三角形,以使射线将在射线时间戳指定的时刻在期望的位置与它们相交。这种方法可以精确渲染光线跟踪的运动模糊,速度比图灵快八倍。
使用NVIDIA OptiX 7.0 API的Blender 2.90,Chaos V-Ray 5.0,Autodesk Arnold和Redshift Renderer 3.0.X支持GA10x硬件加速运动模糊。
与RTX 2080 Super相比,RTX 3080的运动模糊渲染速度高达5倍。
GA10x GPU中的第三代Tensor内核
GA10x集成了新的第三代NVIDIA Tensor Core,具有对新数据类型的支持,更高的性能,效率和编程灵活性。新的稀疏性功能使Tensor Core的性能比上一代Turing高出一倍。诸如用于AI超分辨率的NVIDIA DLSS(现已支持8K),用于语音和视频处理的NVIDIA Broadcast和用于绘制的NVIDIA Canvas等AI功能也更快。
Tensor内核是专门用于执行张量/矩阵运算的专门执行单元-深度学习中的主要计算功能。它们需要通过DLSS(深度学习超级采样),基于AI的降噪,使用RTX语音消除游戏内语音聊天中的背景噪声来提高图形质量。
将Tensor Core引入GeForce游戏GPU中,首次使游戏应用程序能够进行实时深度学习。GA10x GPU中的第三代张量核心设计进一步提高了原始性能,并利用了TF32和BFloat16等新的计算精度模式。这在基于AI的NVIDIA NGX神经服务应用程序中发挥了重要作用,以改善图形,渲染和其他功能。
图灵和安培张量铁心的比较
在Turing上对Ampere Tensor Core进行了重组,以提高效率并降低功耗。Ampere SM内核体系结构具有较少的张量内核,但每个内核都更强大。
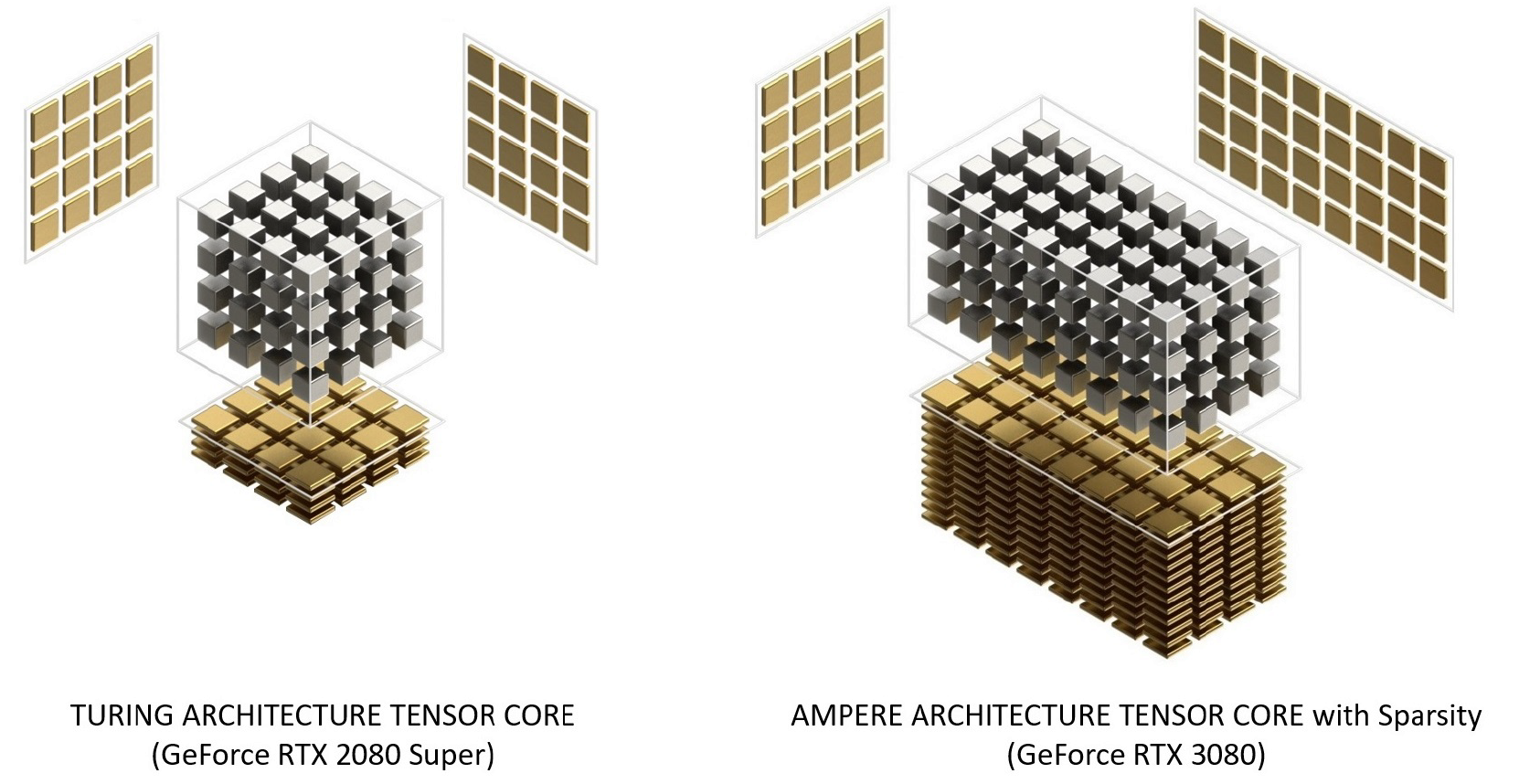
图12.具有Turing和Ampere架构的Tensor核心。GeForce RTX 3080提供的FP16 Tensor Core峰值带宽比GeForce RTX 2080 Super快2.7倍
细粒度的结构性稀疏
NVIDIA通过A100 GPU推出了细粒度结构稀疏性,这是一种将深度神经网络的计算带宽增加一倍的新方法。 GA10x GPU也支持此功能,并有助于加快某些基于AI的图形渲染操作。
由于深度学习网络可以通过反馈学习来调整权重,因此,一般而言,结构约束不会影响训练后模型的准确性。
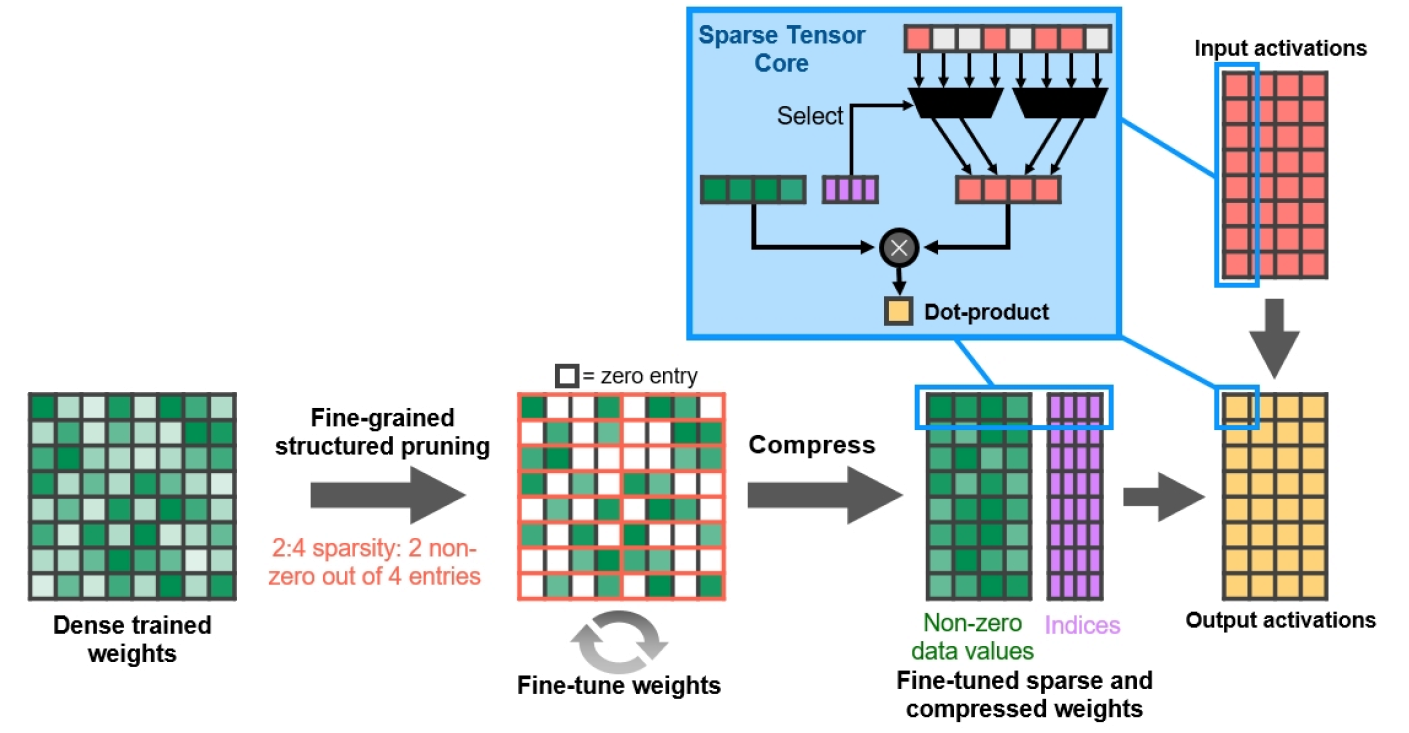
图13.细粒度的结构化稀疏
NVIDIA使用结构化的2:4稀疏模式开发了一种简单而通用的深度神经网络稀疏算法。首先使用密集的权重训练网络,然后进行细粒度的结构化修剪,然后可以丢弃零值,并对剩余的数学进行压缩以增加吞吐量。该算法不会影响经过训练的推理网络的准确性,只会加快速度。
NVIDIA DLSS 8K
以高帧速率使用光线跟踪渲染图像在计算上极其昂贵。相信在NVIDIA Turing出现之前,它的实施将花费数年时间。为解决此问题,NVIDIA创建了深度学习超级采样(DLSS)。

图14.看门狗:具有DLSS的1080p,4K和8K军团。请注意,
通过使用第三代Tensor Core和9x超分辨率缩放因子,DLSS在8K中提供的更清晰的文字和细节仅在NVIDIA Ampere上变得更好,这首次使它有可能以60 fps的速度在8K下运行光线追踪游戏。
15. GeForce RTX 3090 60 fps 8K DLSS . , . Core i9-10900K
GDDR6X
现代PC游戏和创意应用程序需要更多的内存带宽来处理日益复杂的场景几何,更精细的纹理,光线追踪,AI推理,当然还有阴影和超采样。
GDDR6X是第一个超过900 GB / s的图形内存。为此,采用了创新的信号技术和四级脉冲幅度调制(PAM4),共同革新了数据在内存中的移动方式。借助PAM4算法,GDDR6X可以以更快的速率传输更多数据,一次移动两位数据,这使以前的PAM2 / NRZ方案的I / O数据速率提高了一倍。
GDDR6X当前为GeForce RTX 3090支持19.5 Gbps,为GeForce RTX 3080支持19 Gbps。因此,GeForce RTX 3080的存储性能是其前身RTX 2080 Super的1.5倍。 ...
图16显示了GDDR6(左)和GDDR6X(右)的结构比较。 GDDR6X以GDDR6频率的一半传输相同的数据。或者,GDDR6X可以在保持相同频率的同时将其有效带宽增加一倍。

图16.使用PAM4信号的GDDR6X显示出比GDDR6更好的性能和效率
为了解决与PAM4信令相关的SNR问题,已经开发了一种新的MTA(最大防止过渡)编码方案。MTA防止高速信号从最高到最低,反之亦然。

图17. GDDR6X中的新编码GDDR6X
在GA10x芯片上支持高达19.5 Gbps的数据速率,可提供高达936 GB / s的峰值内存带宽,比GeForce RTX中使用的TU102 GPU高出52%。 2080钛。GDDR6X在GeForce 200系列GPU之后,是十年来最大的带宽跃升。
RTX IO
现代游戏包含着巨大的世界。随着摄影测量学等技术的发展,它们越来越多地模仿现实,结果,它们被包含在体积越来越大的文件中。最大的游戏项目占用了200 GB以上的内存,是四年前的三倍,而且这个数字只会随着时间的推移而增长。
越来越多的游戏玩家开始使用SSD来减少游戏加载时间:虽然硬盘限制为50-100MB / s的带宽,但最新的M.2 PCIe Gen4 SSD读取数据的速度高达7GB / s。
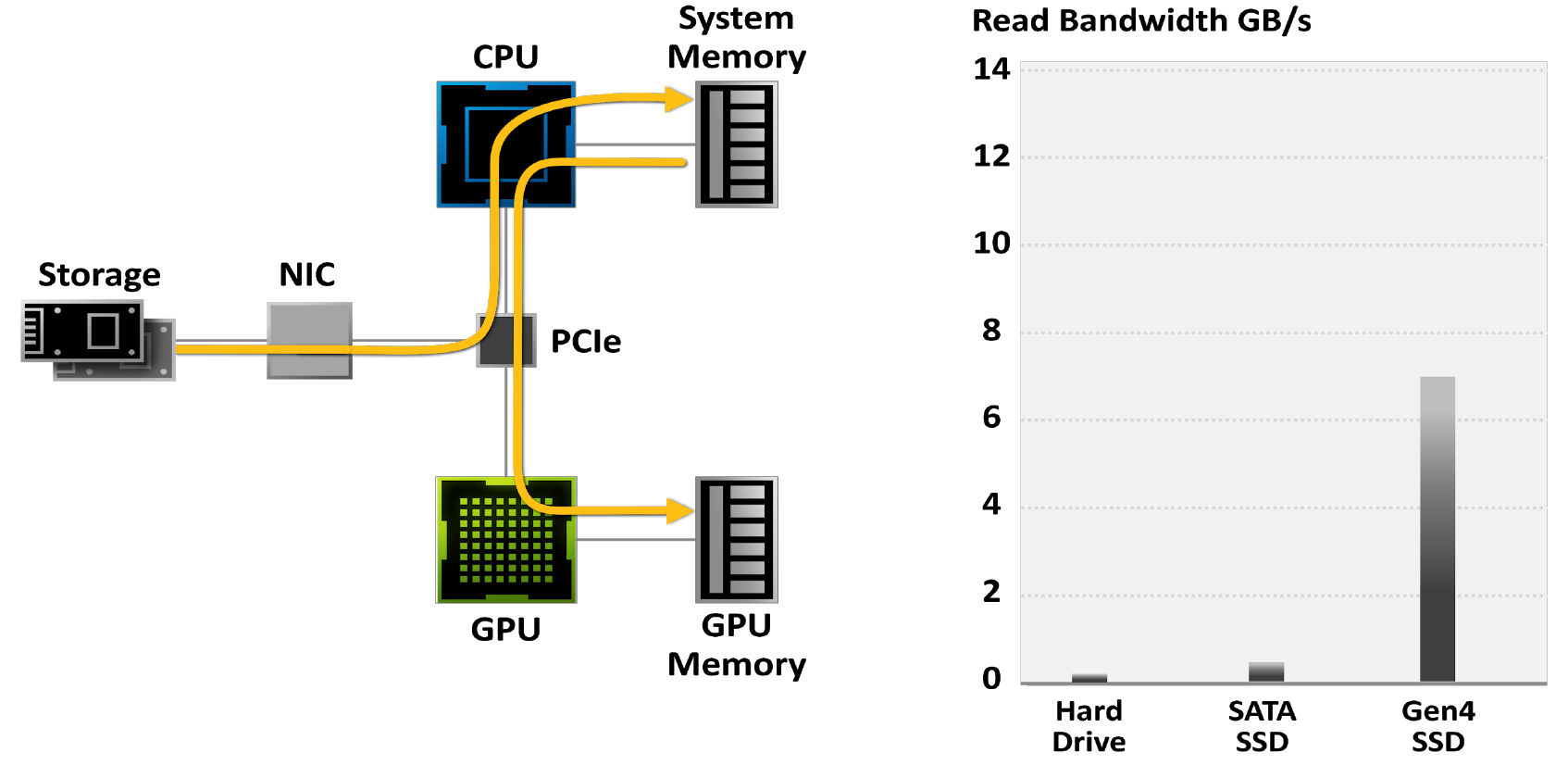
图18.受传统I / O系统限制的游戏

图19.使用传统的存储模型,解压缩游戏可以占用全部24个处理器核心。现代游戏引擎已经超越了传统存储API的功能。这就是为什么需要新一代I / O架构的原因。此处,灰色条表示数据传输速率,黑色和蓝色块表示为此所需的CPU核心。
NVIDIA RTX IO是一套技术,可快速加载和解压缩基于GPU的资产,并提供比硬盘驱动器和传统存储API快100倍的I / O性能。
NVIDIA RTX IO与Microsoft DirectStorage API结合使用,后者是专门为当今的NVMe SSD游戏PC设计的下一代存储。NVIDIA RTX IO可以进行无损解压缩,从而可以通过DirectStorage以压缩形式读取数据并将其传送到GPU。通过以更有效的压缩形式将数据从存储设备移至GPU并使I / O性能提高一倍,可以减轻CPU的负担。

图20. RTX IO提供100倍的带宽和20倍的CPU利用率。灰色和绿色条表示波特率,此CPU内核需要黑色和蓝色块。
显示和视频引擎
带有DSC 1.2a的DisplayPort 1.4a
向更高的分辨率和更高的帧速率迈进的步伐仍在继续,并且NVIDIA Ampere GPU正在努力保持在业界最前沿同时提供这两种产品。游戏玩家现在可以在120Hz的4K(3820 x 2160)显示屏上以60Hz的频率在8K(7680 x 4320)显示屏上玩-像素数是4K的四倍。
Ampere体系结构引擎旨在支持当今最快的显示界面中包含的许多新技术。其中包括DisplayPort 1.4a,可通过VESA显示流压缩(DSC)1.2a提供8K @ 60Hz。新的Ampere GPU可以连接到两个8K 60Hz显示器,每个显示器只需一根电缆。
带DSC 1.2a的HDMI 2.1
NVIDIA Ampere架构首次为独立GPU添加了对HDMI 2.1的支持,HDMI 2.1是HDMI规范的最新更新。HDMI已将最大带宽增加到48 Gbps,这也允许动态HDR格式。要使用HDR支持8K @ 60Hz,需要DSC 1.2a压缩或4:2:0像素格式。
第五代NVDEC-硬件加速视频解码
NVIDIA GPU包括第五代硬件加速视频解码(NVDEC),可为各种流行的编解码器提供完整的硬件视频解码。

图21. GA10x
GPU支持的视频编码和解码格式GA10x中的第五代NVIDIA解码器在Windows和Linux平台上支持以下视频编解码器的硬件加速解码:MPEG-2,VC-1,H.264(AVCHD),H.265 (HEVC),VP8,VP9和AV1。
NVIDIA是第一家为AV1解码提供硬件支持的GPU制造商。
AV1硬件解码
尽管AV1在压缩视频方面非常有效,但对其解码需要大量计算。现代软件解码器导致较高的CPU使用率,并且很难播放超高清视频。在NVIDIA测试中,Intel i9 9900K处理器在8K60 HDR上在YouTube上平均每秒28帧,CPU利用率超过85%。GA10x GPU可以通过将解码传递给NVDEC来播放AV1,该NVDEC能够以非常低的CPU使用率(在与之前测试相同的CPU上约为4%)播放8K60 HDR内容。
第七代NVENC-硬件加速视频编码
对视频进行编码可能是一项复杂的计算任务,但是如果将其上传到NVENC,则可以释放图形引擎和CPU进行其他操作。例如,当使用Open Broadcaster Software(OBS)将游戏流式传输到Twitch.tv时,将视频编码卸载到NVENC将允许分配GPU引擎来渲染游戏,分配CPU来执行其他用户任务。
NVENC允许:
- 无需使用CPU即可进行高质量的超低延迟编码以及游戏和应用程序流传输;
- 用于存档,OTT流,网络视频的高质量编码;
- 每个流的超低功耗编码(W /流)。
借助Twitch和YouTube的共享流设置,GA10x GPU中基于NVENC的硬件编码在使用Fast快速预设方面优于x264软件编码器,并且与x264 Medium(通常需要两台计算机的强大功能)相提并论。这极大地消除了CPU利用率。对于典型的CPU配置而言,4K编码工作量太大,但是GA10x NVENC编码器提供了无缝的高分辨率编码,在H.264中甚至高达4K,在HEVC中甚至高达8K。
结论
对于每种新的处理器体系结构,NVIDIA都致力于为下一代产品提供革命性的性能,同时推出可提高图像质量的新功能。 Turing是第一个引入硬件加速光线跟踪的GPU,该功能曾经被视为计算机图形学的圣杯。如今,许多新型AAA PC游戏中都添加了令人难以置信的逼真和物理上精确的光线追踪效果,并且GPU加速的光线追踪被认为是大多数PC游戏玩家所必须的。全新的NVIDIA GA10x Ampere GPU提供您享受这些全新的光线追踪游戏所需的功能和性能,其帧速率比当前产品快2倍。Turing的另一个功能-改进的CPU加速AI处理功能,可改善噪声消除,渲染和其他图形应用程序-由于采用了Ampere架构,因此也可以提升到一个新的水平。
最后,是完整文档的链接。